1 模型簡介
Selfie2anime模型:動漫風格,訓練集主要針對人物頭像;對應論文為:U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation
Hayao模型:日本漫畫;
Shinkai模型:日本漫畫;
CartoonGan模型:tensorflow hub 開源模型:https://systemerrorwang.github.io/White-box-Cartoonization/,對應論文為:Learning to cartoonize using white-box cartoon representations
2 模型輸入
Selfie2anime模型:
256
?
256
256*256
256?256,原始模型為4.7G,google實作版本為10.2M;
Hayao模型:
256
?
256
256*256
256?256;
Shinkai模型:
384
?
384
384*384
384?384;
CartoonGan模型:
512
?
512
512*512
512?512,經過量化(資料格式 float32-> unit8)后部署的模型,其模型檔案大小為 2M,預測時間也最短,
3 測驗結果
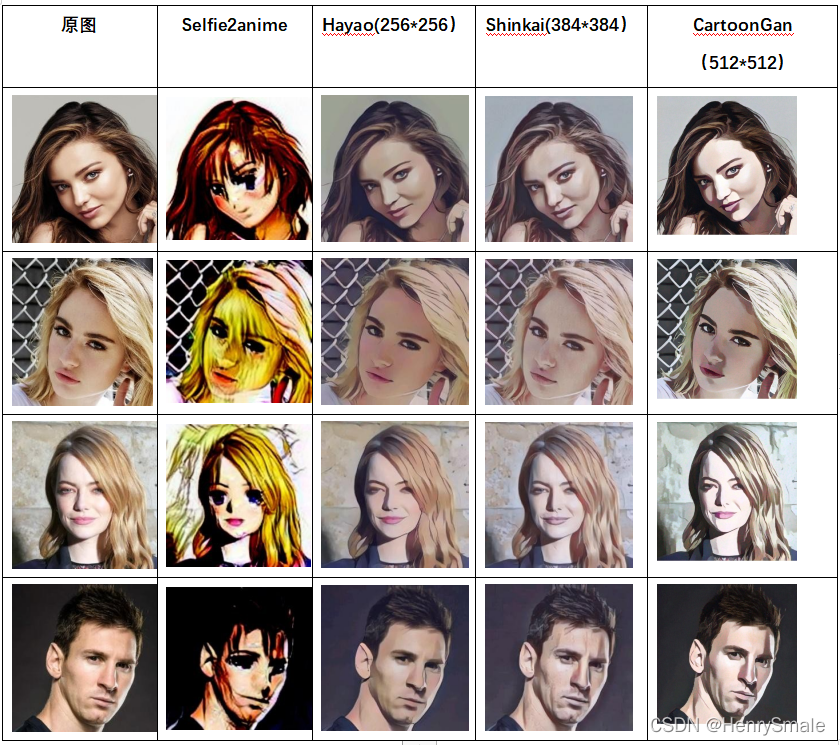
3.1 人物頭像
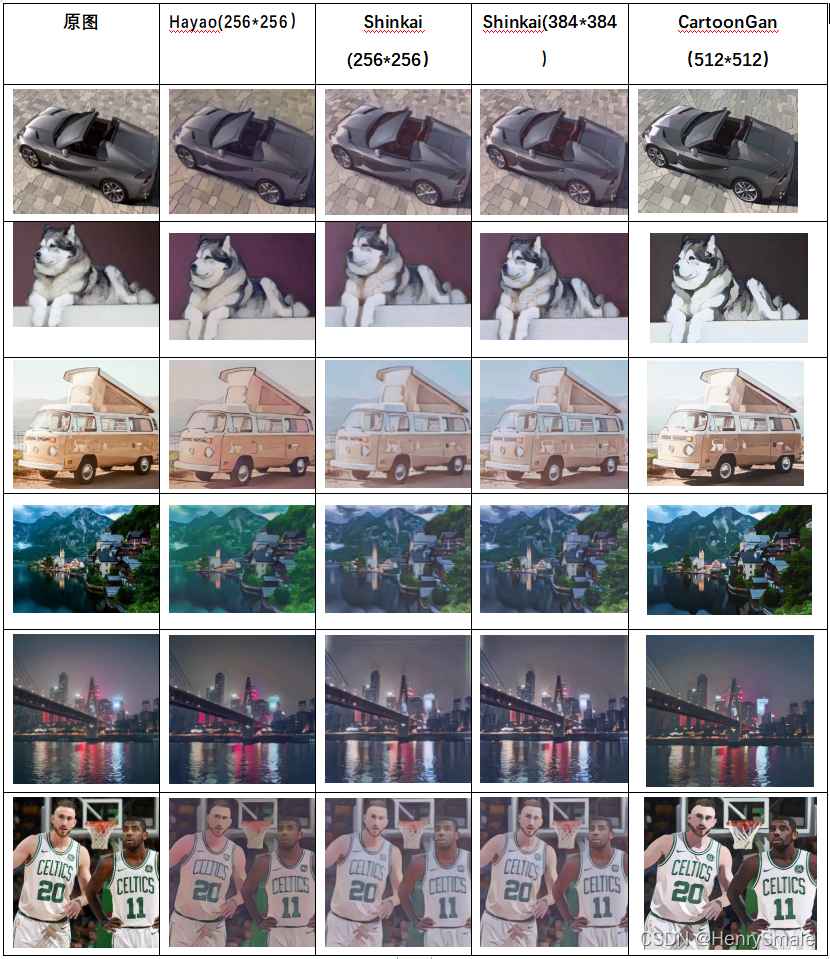
3.2 其他影像
3.3 分析
256 ? 256 256*256 256?256 兩種模型之間的相差并不大,差異表現在生成圖片的整體顏色不同; 256 ? 256 256*256 256?256 與 384 ? 384 384*384 384?384 的模型之間整體差異不大,具體差異體現在細節上,例如人臉面部器官“眼睛”、“鼻子”上,在風景圖片中相差并不大,
由于輸入圖片的長寬通常在 800 像素值以上,而網路的輸入是固定的,因此在輸入網路時需要將圖片進行壓縮、將圖片縮小到目的尺寸(256 或者 384), 因此在縮小的程序中,難免會損失原圖的細節資訊,因此輸入為 384 ? 384 384*384 384?384 的模型效果理所當然會好很多,但 384 ? 384 384*384 384?384 的影像同時也存在一定的弊端,即記憶體消耗較大,
3.4 記憶體分析
由于Shinkai 模型公布了網路結構,我們以這個模型為例來分析記憶體占用情況,Shinkai 模型中間最大的卷積層的圖片通道數為 512,像素點的值為 float 型別,占用 4 個位元組,因此這個卷積層占用的記憶體為: 384 ? 384 ? 512 ? 4 = 301 , 989 , 888 384*384*512*4=301,989,888 384?384?512?4=301,989,888 位元組,約為 302M 的記憶體,而 256 ? 256 256*256 256?256 的圖片只需要申請 134M 的記憶體, 600 ? 600 600*600 600?600 的圖片需要 737M 的記憶體,且在模型中包含多個卷積層,因此圖片尺寸的增長會消耗更加大量的記憶體,
4 進一步說明
- 記憶體分析后可知,如果模型已經固定,增加輸入圖片的大小,就會增加記憶體空間,
- 現有的模型對接近“正方形”的圖片處理效果最佳,長寬差距過大的圖片則會影響生成圖片的質量,因此在網路輸入時,可以考慮通過設計一個裁剪框,讓用戶裁剪圖片長寬為 1:1 的影像,最后再縮小到 384 ? 384 384*384 384?384 的大小,輸入網路得到結果后再放大,
- 當不得不對“長方形”的圖片進行處理時,可以考慮將長方形進行切割,切割后分別進行風格遷移,將得到的結果進行拼接,回傳原影像的遷移結果,
- 模型的記憶體與網路的卷積層結構引數有關,因此也可以從模型設計上進行改進,設計更小的網路,缺點:資料集較大,訓練時間較長,對訓練設備要求較高,且訓練出的模型能減少記憶體占用量,卻不能保證風格遷移的“效果” 會比現有的模型更好,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394094.html
標籤:其他
上一篇:語音排隊叫號系統原始碼
下一篇:OpenCV影像識別技術介紹