當把Transformer中的LSA替換為DwConv/動態濾波器時仍可取得相近,甚至更優的性能 ,但是背后的根因一直未得到探索與挖掘,到底是什么導致LSA性能平庸呢 ?本文對此進行了深入挖掘并得到了影響LSA性能的兩個關鍵因素,

論文鏈接:https://arxiv.org/pdf/2112.12786.pdf
代碼鏈接:https://github.com/damo-cv/ELSA
近期多篇研究表明:當把Transformer中的LSA替換為DwConv/動態濾波器時仍可取得相近,甚至更優的性能 ,但是背后的根因一直未得到探索與挖掘,到底是什么導致LSA性能平庸呢 ?本文對此進行了深入挖掘并得到了影響LSA性能的兩個關鍵因素,基于所得發現提出了增強版ELSA,當其與SwinT、VOLO搭配時,在ImageNet分類、COCO檢測以及ADE20K分割任務上均表現出了顯著的性能提升,
Abstract
自注意力機制具有長距離建模能力,但區域細粒度特征學習是其弱勢,區域自注意力(Local Self-Attention, LSA)的性能僅與卷積相當,弱于動態濾波器卷積,這為研究員帶來了困惑:要不要使用LSA呢?哪一種更好呢?什么原因使其LSA平庸呢?
為澄清上述疑惑,我們從兩個角度(channel setting與spatial processing)對LSA進行系統性挖掘,我們發現:空域注意力的生成與應用是其根因,即相對位置嵌入與近鄰濾波器應用是關鍵因素 ,基于上述發現,我們采用Hadamard注意力與Ghost頭提出了增強版區域自注意力ELSA ,Hadamard注意力通過引入Hadamrd乘積以更高效的生成注意力,同時保持高階映射關系;而Ghost頭則對注意力與靜態矩陣進行組合以提升通道容量,
實驗結果表明:采用ELSA直接替換SwinTransformer中的LSA即可取得1.4%的性能提升,ELSA同樣有助于VOLO性能提升,其中ELSA-VOLO-D5取得了87.2%的top1精度且無需額外訓練資料 ,此外,在下游任務方面,ELSA可以提升基線模型在COCO資料集的性能1.9boxAP/1.3maskAP,在ADE20K資料集的性能1.9mIoU,
StartPoint
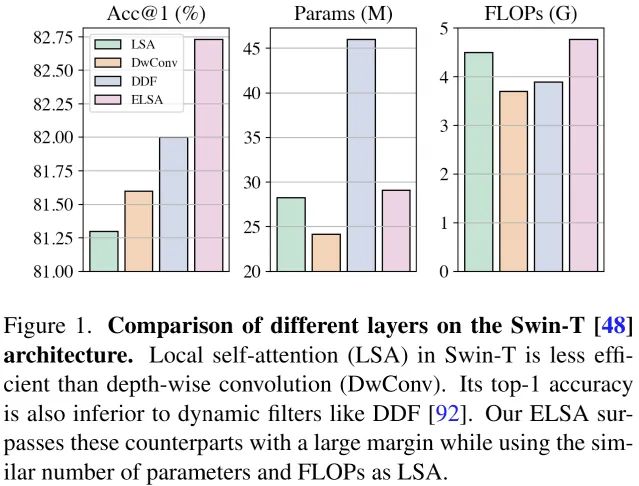
已有研究表明:當將SwinTransformer中的LSA替換為DwConv(Depth-wise Convolution)或動態卷積DDF后,LSA與DwConv的性能相當并弱于DDF (見上圖),該現在已有在近期多篇文章中得到發現,但并無關于其背后原因的深入分析,那么,是什么使得LSA變得如此平庸呢 ?
為更好的回答上述問題,我們從以下兩個角度對LSA、DwConv以及動態濾波器進行了系統反思:
-
Channel Setting ,DwConv與LSA的最直接差異就在于通道配置:DwConv對不同通道采用不同的濾波器,而LSA則采用了多頭策略且濾波器共享,DwConv可以視作一種特殊的多頭策略,即頭數等于通道數,我們猜測:DwConv的多頭是其性能與LSA相當的原因所在,但實驗發現:把DwConv的頭數設定于LSA相當時,兩者仍具有相似進度;反之亦然,也就是說:我們需要一種新的通道策略以進一步提升LSA的性能 ,
-
Spatial Processing ,如何得到濾波器并對空域資訊聚合是DwConv、LSA以及動態濾波器的另一個差異,DwConv采用靜態濾波器,而其他兩者則采用動態濾波器,我們將上述三種方式進行統一并從引數量、規范化以及濾波器應用方面進行公平比對,我們發現:相對位置嵌入與近鄰濾波器應用是影響性能的關鍵因素 ,此外,query與key的點乘是一種計算不友好操作,因此,我們需要一種更高效的濾波器生成機制以替代點乘,同時保持性能 ,
Channel Setting
為更好刻畫讓LSA平庸的原因,我們首先聚焦于DwConv與LSA的第一個差異:通道配置,DwConv對不同通道采用不同的濾波器,而LSA通過多頭策略將通道拆分為多組并在組內共享濾波器,我們認為DwConv是多頭策略的一種特例,即頭數等于通道數,
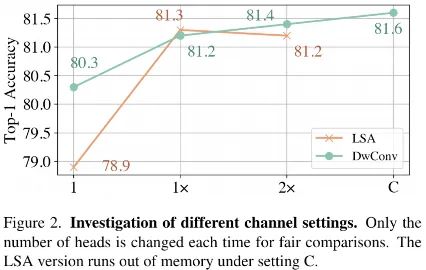
上圖給出了以SwinT為基線,采用不同的頭數時的性能,可以看到:
-
在相同通道配置下(如1x、2x),DwConv版本仍與LSA版本具有相似性能;
-
在1x配置下,DwConv甚至具有比LSA版本更優的性能,這就說明:通道配置并非導致前述奇異現象的主要原因 ,
-
當頭數配置大于1x時,LSA性能反而下降,這意味著:直接提升頭數并不能改善通道容量與性能 ,
-
上述結果表明:我們需要一種新的策略以進一步提升通道容量和性能 ,
Spatial Processing
既然通道配置并非關鍵原因,那么我們將從空域處理角度尋求答案,DwConv、動態濾波器以及LSA采用不同的策略聚合空域資訊,我們將其進行統一并從三個角度進行公平比對,
DwConv采用的是靜態濾波器,其計算程序如下:
動態濾波器通過一個單獨的分支網路生成空域相關濾波器,可描述如下(注:w表示濾波器生成分支網路引數):
LSA采用區域視窗的注意力圖,計算程序可描述如下:
我們將上述三種策略統一成如下統一架構:
DwConv、動態濾波器以及LSA均為上式的特例,比如,當僅使用引數時,上式退化為DwConv;當僅使用時,上式退化為動態濾波器;類似的,我們可以將其退化為LSA,因此,影響LSA的因素主要包含:引數形式、規范化以及濾波器應用方式 ,接下來,我們將對各個因素進行對比分析,

上表比較了不同引數形式的性能對比,從中可以看到:
-
動態濾波器的引數策略要比標準LSA策略具有更優的性能(Net2 vs Net1);
-
動態濾波器變種策略(Net6)具有與SwinT相當的性能;
-
LSA引數策略與動態濾波器引數策略的組合(Net7)可以進一步提升模型性能,

上表比較了不同規范化方式對于性能的影響,從中可以看到:
-
當采用Net7的引數形式組合Identity時,模型訓練崩潰;
-
相比FilterNorm,Softmax規范化具有更優的性能;
-
這里結果表明:規范化方式并非LSA并平庸的原因 ,
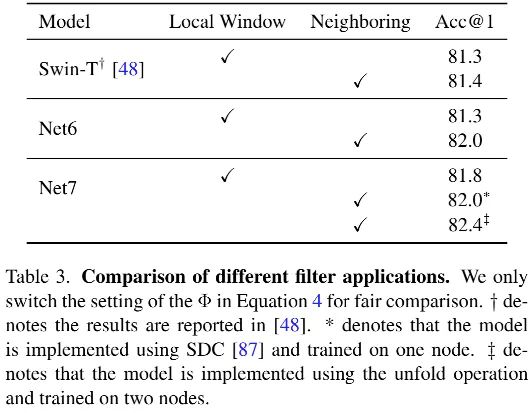
上表對比了不同濾波器使用方式(非重疊視窗 vs 滑動視窗)的性能影響,從中可以看到:當將濾波器用于近鄰區域(即滑動視窗形式)時,Net6與Net7均得到了顯著性能提升 ,這意味著:近鄰處理方式是空域處理的關鍵 ,
Discussion
基于上述實驗,使LSA變平庸的因素可以分為兩個因素:
-
相對位置嵌入是影響性能的一個關鍵因素;
-
另外一個關鍵因素是濾波器使用方式,即滑動視窗 vs 非重疊視窗,
DwConv能夠與LSA性能相媲美的原因在于:它采用了滑動視窗處理機制,當其采用非重疊視窗機制時,性能明顯弱于LSA(見Table1中的Net4),
動態濾波器性能優于LSA的原因在于相對位置嵌入與近鄰濾波器使用方式,兩者的集成(Net7)取得了最佳的性能,
對比非重疊區域視窗與滑動視窗,區域重疊的峰值性能要弱于滑動視窗,區域視窗的一個缺點在于:視窗間缺乏資訊互動,限制了其性能;而滑動視窗的缺陷在于低吞吐量,那么,如何避免點乘同時保持高性能就成了新的挑戰 ,
Enhanced Local Self-attention
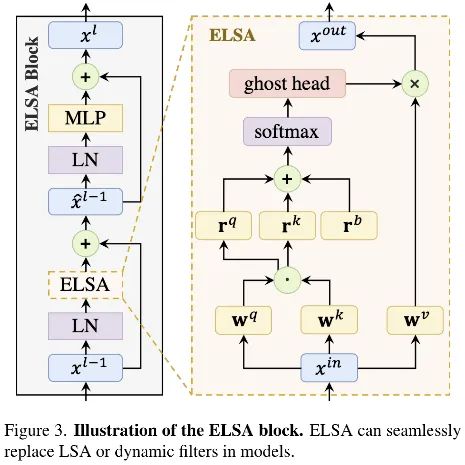
我們提出了一種的新的區域自注意力模塊ELSA(見上圖),超越了SwinT中的LSA與動態濾波器,ELSA的關鍵技術為Hadamard注意力與Ghost頭模塊,ELSA的處理程序可描述如下:
其中,與分別表示Hadamard注意力與Ghost頭映射模塊,
Hadamard注意力可以描述如下:
該公式的實作極為高效,偽代碼如下:

Ghost頭則受啟發于GhostNet得到,可以描述如下:

上圖為Ghost頭的實作參考code,為避免過大的GPU顯存占用,作者進行了CUDA實作,
Experiments
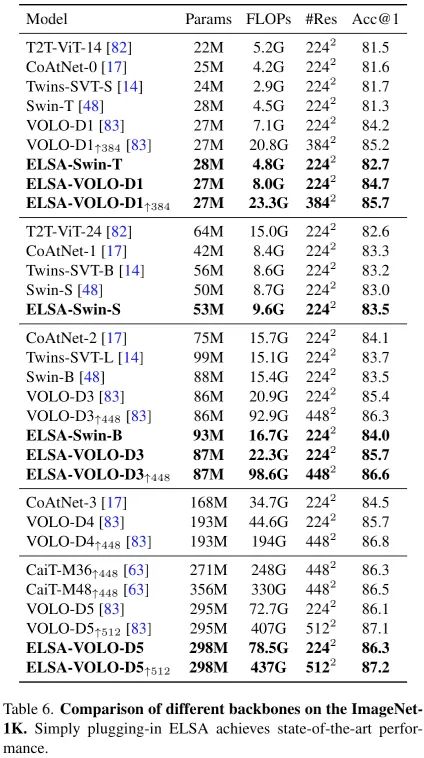
上表給出了所提方案與其他SOTA方案的性能對比,從中可以看到:
-
在不同模型大小下,所提ELSA均優于SwinT與VOLO;
-
ELSA分別優于Swin-T、Swin-S、Swin-B達1.4%、0.5%、0.5%;其中ELSA-Swin-S與原始Swin-B相當,且引數量與FLOPs更少,
-
ELSA-VOLO-D1與ELSA-VOLO-D3分別去了84.7%與85.7%的top1精度,ELSA-VOLO-D3甚至取得了媲美VOLO-D4的性能且引數量減半,
-
ELSA-VOLO-D5甚至取得了87.2%的top1精度,超過了此前最佳87.1%,
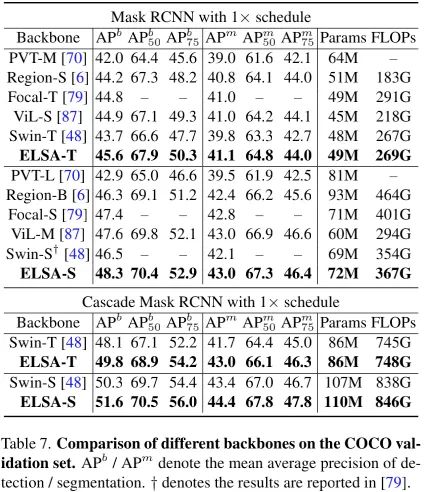
上圖給出了COCO資料上不同方案性能對比,從中可以看到:
-
ELSA-Swin-T 與ELSA-Swin-S分別超出基線模型1.9AP與1.8AP;
-
采用Cascade Mask RCNN時,ELSA-Swin-T與ELSA-Swin-S分別取得了49.8與51.6的AP指標,以1.7和1.3AP指標優于基線模型,
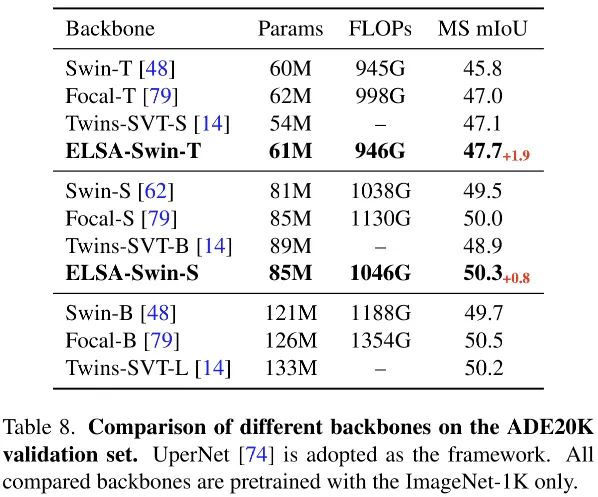
上表給出了ADE20K資料及上的性能對比,從中可以看到:
-
ELSA-Swin-T以1.9mIoU指標優于基線Swin-T;
-
ELSA-Swin-S作為骨干時取得了50.3mIoU指標,以0.8優于Swin-S,甚至優于Swin-B,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394109.html
標籤:其他
上一篇:Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
下一篇:GPS單點定位計算流程