一、前言
Zookeeper是一個分布式協調框架,提供分布式鎖、配置項管理、服務注冊與集群管理等功能,
為了保證Zookeeper的高可用,一般都會以集群的模式部署,
這個時候需要考慮各個節點的資料一致性,那么集群在啟動時,需要先選舉出一位Leader,再由Leader完成向其他節點的資料同步作業,
本文將是Zookeeper系列的第一篇文章,從原始碼角度講述Zookeeper的選舉演算法,
二、準備作業
博主是在windows安裝了docker desktop,使用docker-compose啟動zk集群的,docker-compose.yml內容如下:
version: '2.2'
services:
zoo1:
image: zookeeper:3.4.14
restart: always
hostname: zoo1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
zoo2:
image: zookeeper:3.4.14
restart: always
hostname: zoo2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
zoo3:
image: zookeeper:3.4.14
restart: always
hostname: zoo3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888其中2181是用于客戶端連接的埠,這里分別映射到了主機的三個埠上
ZOO_MY_ID代表節點id,需要手動指定
ZOO_SERVERS代表集群內的節點,格式為server.{節點id}={ip}:{資料同步埠}:{集群選舉埠}
到該檔案所處的目錄下,執行 docker-compose up -d
這樣我們的zk集群就啟動好了

PS:如果下載鏡像太慢,可以到Docker Engine的tab頁中新增一些鏡像源:
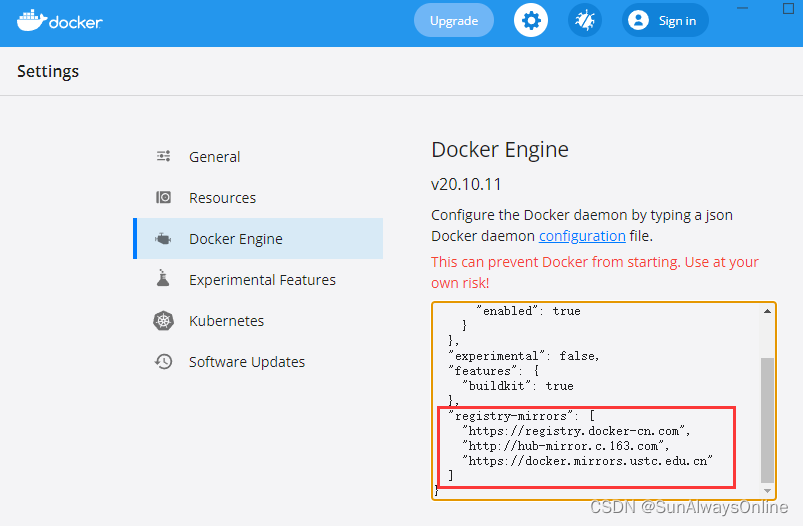
內容也貼一下:
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
]三、基本概念
節點的角色
- Leader,領導者,又稱主節點,負責處理客戶端的寫請求,并將資料同步到各個子節點
- Follower,跟隨者,又稱子節點,用于處理客戶端的讀請求,擁有投票權,
- Observer,觀察者,也可以用于處理客戶端的讀請求,但沒有投票權,也不會參與選舉與晉升,
如何查看節點的角色
使用 docker exec -it zk_zoo3_1 /bin/bash 進入該容器中
接著執行 ./bin/zkServer.sh status 查看當前節點的狀態

可以看到,zoo3為leader角色,
可以推測出,zoo3容器肯定是第2個啟動完成的,那這個推測是怎么來的?稍后進入原始碼中一探究竟,
節點的狀態
每個節點,都會有一個狀態,狀態被定義在QuorumPeer#ServerState列舉類中
public enum ServerState {
LOOKING,
FOLLOWING,
LEADING,
OBSERVING
}如果一個節點處于LOOKING的狀態,會去檢查集群中存不存在Leader,如果不存在,則進行選舉,此時ZK集群無法對外提供服務,
另外的三種狀態,就和節點角色相對應,
myid
前文已經說過,是節點id,手動指定,需要全域唯一,
zxid
全稱為Zookeeper Transaction Id,即zk事務id,寫請求到達Leader時,Leader會為該請求分配一個全域遞增的事務id,
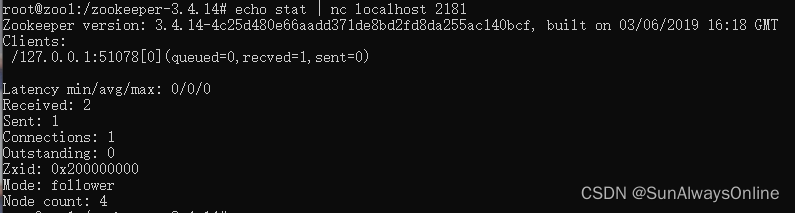
使用 docker exec 容器名 /bin/bash 進入該容器,再使用 echo stat | nc localhost 2181 查看節點的狀態,
其中兩個Follower的狀態為:
Leader的狀態為:
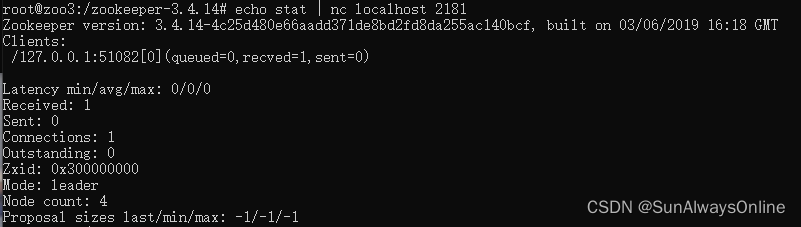
可以看到zxid欄位
zxid是一個64位的標識,前32位表示epoch(年代,紀元的意思),后32位主鍵遞增計數,
每一個Leader就像皇帝一樣,有自己的年號,這一點和Raft協議中的term任期一致(PS:對Raft協議感興趣的同學,可以參考我的另外一篇博客 22張圖,帶你入門分布式一致性演算法Raft)
如果當前Leader宕機后,下一任Leader的zxid中的epoch就會+1,然后低32位變為0,
查看當前epoch,可以使用 cat /data/version-2/currentEpoch
四、原始碼分析
QuorumPeerMain
是zk的啟動類,main方法如下:
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
//初始化
main.initializeAndRun(args);
}
protected void initializeAndRun(String[] args) throws ConfigException, IOException {
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
//args[0]為/conf/zoo.cfg
config.parse(args[0]);
}
//以集群模式啟動,畢竟當前servers的長度為3
if (args.length == 1 && config.servers.size() > 0) {
runFromConfig(config);
} else {
//以單機模式啟動
ZooKeeperServerMain.main(args);
}
}initializeAndRun主要是根據讀取到的配置,決定是以集群還單機模式啟動,
runFromConfig
public void runFromConfig(QuorumPeerConfig config) throws IOException {
//QuorumPeer本身是一個Thread物件
quorumPeer = getQuorumPeer();
//設定選舉方式、myid等一系列引數,沒有就使用默認值
quorumPeer.setMyid(config.getServerId());
//...
quorumPeer.initialize();
quorumPeer.start();
//等待quorumPeer執行完成
quorumPeer.join();
}這里啟動了quorumPeer執行緒,quorumPeer可以理解為集群中的節點,其重寫的start方法會完成當前節點的初始化作業,并且主執行緒需要等待quorumPeer執行完成,
直接進入run方法中
public synchronized void start() {
//從磁盤加載資料到記憶體資料庫中,例如獲取zxid、epoch
loadDataBase();
//準備接受客戶端請求
cnxnFactory.start();
//準備進行Leader選舉的環境
startLeaderElection();
//這里將呼叫本類的run方法
super.start();
}startLeaderElection
其實只是準備了進行選舉的環境,選用FastLeaderElection作為Leader選舉的策略,
該策略會創建一個用于維護集群各個節點之間通信的QuorumCnxManager物件,節點對外的投票,首先會放入FastLeaderElection.sendqueue中,之后由QuorumCnxManager發送到另外一個節點,如果收到其他節點的投票資訊,則由QuorumCnxManager先存入FastLeaderElection.recvqueue中,再由當前節點消費,
這個時候,節點之間還沒有進行相互投票,所以說,startLeaderElection只是初始化了投票環境,
QuorumPeer.run
super.start將會呼叫本類的run方法
while (running) {
switch (getPeerState()) {
case LOOKING:
//剛啟動的節點,默認處于Looking狀態
try {
//尋找leader,下面會細講
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
setPeerState(ServerState.LOOKING);
}
break;
case OBSERVING:
setObserver(makeObserver(logFactory));
observer.observeLeader();
break;
case FOLLOWING:
setFollower(makeFollower(logFactory));
follower.followLeader();
break;
case LEADING:
setLeader(makeLeader(logFactory));
leader.lead();
break;
}
}run方法中是一個while回圈,處于Looking狀態,才會進行Leader選舉,
lookForLeader
startLeaderElection選用了FastLeaderElection作為Leader選舉的策略,因此這里進入FastLeaderElection的lookForLeader方法
lookForLeader方法比較復雜,分階段去理解它,
第一階段:節點先投票給自己
//創建一個投票箱(key為myid,value為投票資訊),用于匯總當前集群內的投票資訊
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
//保存在集群確定leader之后還收到的投票資訊
//即保存所有處于FOLLOWING與LEADING狀態的節點發出的投票資訊
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
//等待其他節點投票的超時時間,默認為200毫秒
int notTimeout = finalizeWait;
synchronized (this) {
//遞增邏輯時鐘,邏輯時鐘可以理解為選舉屆數
logicalclock.incrementAndGet();
//在每次選舉中,節點都會先投自己一票
//當前方式只是更新提議,還未通知到其他節點
//getInitId():myid getInitLastLoggedZxid():日志中最大的zxid getPeerEpoch():節點的epoch
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//將當前提議廣播出去
sendNotifications();第二階段:不斷獲取其他節點的投票資訊,直至找到Leader
分為兩部分:
- 獲取不到投票資訊,選擇重發或者重連
- 獲取到投票資訊,處理投票資訊
//如果當前節點處于LOOKING狀態,則一直獲取其他節點的投票資訊,直到找到leader
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
//從recieve佇列中取出一個投票資訊
//上文我們說過,其他節點的投票資訊,會先由QuorumCnxManager暫存到recvqueue中
Notification n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS);
//獲取不到投票資訊
if (n == null) {
//選擇重發或者重連
//獲取到投票資訊
} else if (validVoter(n.sid) && validVoter(n.leader)) {
//判斷進行投票的節點狀態
switch (n.state) {
case LOOKING:
//......
break;
case OBSERVING:
//Observer是沒有投票權的,因此這里不做處理
break;
case FOLLOWING:
case LEADING:
//......
break;
default:
break;
}
}
}獲取不到投票資訊
//獲取不到投票資訊
if (n == null) {
//從else邏輯就可以猜出,haveDelivered方法用于判斷當前節點是否和集群中的其他節點全部失聯
if (manager.haveDelivered()) {
//獲取不到投票資訊,那就再次廣播一次,其他節點也許會進行回應
//之前的回應可能由于網路原因丟失了,因此這里重試一下
sendNotifications();
} else {
//與集群中的所有節點建立連接
manager.connectAll();
}
//由于獲取不到投票資訊,這里將超時時間擴大為兩倍
int tmpTimeOut = notTimeout * 2;
//最長不可以超過60秒
notTimeout = (Math.min(tmpTimeOut, maxNotificationInterval));
}如果能獲取到投票資訊,且發送投票的節點狀態為LOOKING時
case LOOKING:
//如果推薦leader的節點的epoch大于當前邏輯時鐘
if (n.electionEpoch > logicalclock.get()) {
//代表當前節點可能錯過了幾屆選舉,導致自己的邏輯時鐘比其他節點小
//那就沿用別人的邏輯時鐘
logicalclock.set(n.electionEpoch);
//清空投票箱
recvset.clear();
//判斷被推薦的leader與當前節點誰更適合當leader
//判斷的根據,是選舉演算法的核心,稍后會細講
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
//被推薦的leader更適合,因此更新自己的提議
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
//看來還是自己更適合,推薦自己
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//廣播提議資訊
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//如果投票中的epoch小于當前節點的邏輯時鐘,說明該票是無效的
//退出switch,取出下一條投票訊息
break;
//如果處于同一輪選舉中,且投票中的推薦的leader更適合做leader
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新自己的提議,并廣播出去
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
//將發送投票訊息的節點id及它的投票資訊存入recvset中
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//投票箱中推薦的leader,如果和自己推薦的leader一致,且超過節點總數的一半
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
//不斷取出投票資訊,看leader會不會進行變動
while ((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null) {
//如果投票中推薦的leader更適合做leader
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//把該選票重新放回,說明該輪選舉還沒有結束
recvqueue.put(n);
break;
}
}
//如果在限定時間內,沒有取出任何投票資訊,說明選舉即將結束
if (n == null) {
//如果leader是自己,則設定當前狀態為LEADING
//如果不是,屬于PARTICIPANT就設定FOLLOWING,否則設定OBSERVING
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING : learningState());
//選舉收尾動作
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock.get(),
proposedEpoch);
//清空recvqueue
leaveInstance(endVote);
return endVote;
}
}
break;totalOrderPredicate
在totalOrderPredicate方法中,決定了誰更適合做leader,也是zk選舉演算法的核心
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
//判斷外部節點推薦的leader的權重,
if (self.getQuorumVerifier().getWeight(newId) == 0) {
return false;
}
return ((newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
}判斷newId代表的節點(即投票資訊中推薦的節點,以下先稱為新節點)與當前節點更適合做leader,判斷的規則如下:
- 先比較屆數,新節點的選舉屆數大于當前節點,則新節點更適合
- 再比較資料新舊程度,新節點的資料新于當前節點,則新節點更適合
- 最后比較機器id,新節點的myid大于當前節點時,則新節點
判斷當前選舉是否可以結束時,需要先判斷推薦的leader是否大于節點總數的一半:
protected boolean termPredicate(
HashMap<Long, Vote> votes,
Vote vote) {
HashSet<Long> set = new HashSet<Long>();
//搜集投票箱中和自己推薦一致的選票
for (Map.Entry<Long, Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())) {
set.add(entry.getKey());
}
}
return self.getQuorumVerifier().containsQuorum(set);
}
//是否大于節點總數的一半
public boolean containsQuorum(Set<Long> set){
return (set.size() > half);
}如果能獲取到投票資訊,且發送投票的節點狀態為FOLLOWING或LEADING時
case FOLLOWING:
case LEADING:
//如果邏輯時鐘一致
if (n.electionEpoch == logicalclock.get()) {
//存入投票箱中
recvset.put(n.sid, new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch));
//如果外部推薦的leader支持率過半且合法
if (ooePredicate(recvset, outofelection, n)) {
//直接退出選舉,確定自己的狀態
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING : learningState());
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//在加入一個Leader確定的集群中,先確認一下是否是大多數節點都追隨同一個leader
//在確定leader之后收到的投票資訊,全部存入outofelection中
//即保存所有處于FOLLOWING與LEADING狀態的節點發出的投票資訊
outofelection.put(n.sid, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state));
//如果外部節點推薦的leader在outofelection支持率過半且合法
//一般是在選舉完成后,新加入一個節點,才會走該邏輯
if (ooePredicate(outofelection, outofelection, n)) {
synchronized (this) {
//同步當前節點的選舉屆數與狀態
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING : learningState());
}
Vote endVote = new Vote(n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;有兩種情況會走到FOLLOWING與LEADING的case中:
- 集群已經選舉出Leader,但其他節點都未及時通知到當前節點,此時n的邏輯時鐘與當前一致,
- 集群已經選舉出Leader,但后來又加入了一臺機器,此時邏輯時鐘大概率不一致,
以上就是處于LOOKING狀態的選舉流程,當選舉結束后,節點的狀態就會確定下來,QuorumPeer類中un方法的while回圈就會按照狀態進入下一個階段,
Follower執行followLeader,Leader執行lead,Observer則執行observeLeader,
因此,如果一個節點處于選舉中時,則無法對外提供服務,
五、總結
下面以3個節點構成的集群為例,簡要說明一下選舉程序,
3個節點名稱分別為zk1、zk2與zk3,數字對應于他們的myid,
啟動時期選舉
按序啟動這個5個節點,假設它們處于同一輪選舉中,即epoch一致,
- 先啟動zk1,先投自己1票,此時zk1獲得1票,但未超過半數,無法當選Leader,狀態還是處于LOOKING,
- 接著啟動zk2后,zk2也先投自己1票,zk2廣播投票結果后,zk1會發現自己的epoch、zxid都與zk2相同,但myid小于zk2,因此zk1改投zk2,此時zk1獲得0票,zk2獲得2票,還是沒有超過半數節點,zk1與zk2依然處于LOOKING,
- 稍后啟動zk3后,zk3也先投自己1票,zk3廣播投票結果后,zk1與zk2將會改投zk3,此時zk1獲得0票,zk2獲得0票,zk3獲得3票,超過半數節點,當選為Leader,之后將狀態改為LEADING,zk1與zk2則將狀態改為FOLLOWING,
- 然后啟動zk4,zk4也是先投自己1票,通過廣播后,收到其他節點的投票資訊,發現事情已成定局,自己來晚了,于是直接服從多數,直接將狀態改為FOLLOWING,
- 最后啟動zk5,和zk4一樣的結果,狀態改為FOLLOWING,
運行時期選舉
運行時間選舉,指的是在啟動選舉完成后,當選Leader的節點宕機了,此時需要重新進行選舉,在選舉完成前,集群無法對外提供服務,
假設Leader3宕機,其余節點通過心跳機制感應到,將會觸發新一輪選舉,
下面使用(myid,zxid)的形式來表達各個節點的狀態,這里假設它們的epoch是一致的,但由于同步的快慢,導致自身的zxid各不相同,
- zk1(1,5)
- zk2(2,6)
- zk3(3,10)
- zk4(4,8)
- zk5(5,7)
這是簡化后的選舉圖,一圖勝千言:

因此選舉演算法的核心口訣就是:
先比epoch,不行就再比zxid,還是不行那就比myid,且滿足半數以上則當選為Leader,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394114.html
標籤:其他
上一篇:PHM壽命預測內容定稿