1 研究背景
人工智能是研究開發能夠模擬、延伸和擴展人類智能的理論、方法、技術及應用系統的一門新的技術科學,研究目的是促使智能機器會聽(語音識別、機器翻譯等)、會看(影像識別、文字識別等)、會說(語音合成、人機對話等)、會思考(人機對弈、定理證明等)、會學習(機器學習、知識表示等)、會行動(機器人、自動駕駛汽車等),
人工智能充滿未知的探索道路曲折起伏,如何描述人工智能自1956年以來60余年的發展歷程,學術界可謂仁者見仁、智者見智,通過查閱資料將人工智能的發展歷程劃分為以下6個階段:
一是起步發展期:1956年—20世紀60年代初,人工智能概念提出后,相繼取得了一批令人矚目的研究成果,如機器定理證明、跳棋程式等,掀起人工智能發展的第一個高潮,
二是反思發展期:20世紀60年代—70年代初,人工智能發展初期的突破性進展大大提升了人們對人工智能的期望,人們開始嘗試更具挑戰性的任務,并提出了一些不切實際的研發目標,然而,接二連三的失敗和預期目標的落空(例如,無法用機器證明兩個連續函式之和還是連續函式、機器翻譯鬧出笑話等),使人工智能的發展走入低谷,
三是應用發展期:20世紀70年代初—80年代中,20世紀70年代出現的專家系統模擬人類專家的知識和經驗解決特定領域的問題,實作了人工智能從理論研究走向實際應用、從一般推理策略探討轉向運用專門知識的重大突破,專家系統在醫療、化學、地質等領域取得成功,推動人工智能走入應用發展的新高潮,
四是低迷發展期:20世紀80年代中—90年代中,隨著人工智能的應用規模不斷擴大,專家系統存在的應用領域狹窄、缺乏常識性知識、知識獲取困難、推理方法單一、缺乏分布式功能、難以與現有資料庫兼容等問題逐漸暴露出來,
五是穩步發展期:20世紀90年代中—2010年,由于網路技術特別是互聯網技術的發展,加速了人工智能的創新研究,促使人工智能技術進一步走向實用化,1997年國際商業機器公司(簡稱IBM)深藍超級計算機戰勝了國際象棋世界冠軍卡斯帕羅夫,2008年IBM提出“智慧地球”的概念,以上都是這一時期的標志性事件,
六是蓬勃發展期:2011年至今,隨著大資料、云計算、互聯網、物聯網等資訊技術的發展,泛在感知資料和圖形處理器等計算平臺推動以深度神經網路為代表的人工智能技術飛速發展,大幅跨越了科學與應用之間的“技術鴻溝”,諸如影像分類、語音識別、知識問答、人機對弈、無人駕駛等人工智能技術實作了從“不能用、不好用”到“可以用”的技術突破,迎來爆發式增長的新高潮,
2 OCR文字識別
2.1什么是OCR?

圖 自然場景OCR文字識別
OCR英文全稱是Optical Character Recognition,中文叫做光學字符識別,它是利用光學技術和計算機技術把印在或寫在紙上的文字讀取出來,并轉換成一種計算機能夠接受、人又可以理解的格式,文字識別是計算機視覺研究領域的分支之一,而且這個課題已經是比較成熟了,并且在商業中已經有很多落地專案了,比如漢王OCR,百度OCR,阿里OCR等等,很多企業都有能力都是拿OCR技術開始掙錢了,其實我們自己也能感受到,OCR技術確實也在改變著我們的生活:比如一個手機APP就能幫忙掃描名片、身份證,并識別出里面的資訊;汽車進入停車場、收費站都不需要人工登記了,都是用車牌識別技術;我們看書時看到不懂的題,拿個手機一掃,APP就能在網上幫你找到這題的答案,太多太多的應用了,OCR的應用在當今時代確實是百花齊放,
2.2 OCR的分類
如果要給OCR進行分類分為兩類:手寫體識別和印刷體識別,
這兩個可以認為是OCR領域兩個大主題了,當然印刷體識別較手寫體識別要簡單得多,也能從直觀上理解,印刷體大多都是規則的字體,因為這些字體都是計算機自己生成再通過列印技術印刷到紙上,在印刷體的識別上有其獨特的干擾:在印刷程序中字體很可能變得斷裂或者墨水粘連,使得OCR識別例外困難,當然這些都可以通過一些影像處理的技術幫他盡可能的還原,進而提高識別率,總的來說,單純的印刷體識別在業界已經能做到很不錯了,但說100%識別是肯定不可能的,但是說識別得不錯那是沒毛病,

圖 手寫字體展示
印刷體已經識別得不錯了,那么手寫體呢?手寫體識別一直是OCR界一直想攻克的難關,但是時至今天,感覺這個難關還沒攻破,還有很多學者和公司在研究,為什么手寫體識別的難度在于因為人類手寫的字往往帶有個人特色,每個人寫字的風格基本不一樣,印刷體一般都比較規則,字體都基本就那幾十種,機器學習這幾十種字體并不是一件難事,但是手寫體,每個人都有一種字體的話,那機器該學習大量字體,這就是難度所在,
2.3 OCR流程
假如輸入系統的影像是一頁文本,那么識別時的第一件事情是判斷頁面上的文本朝向,因為得到的這頁檔案往往都不是很完美的,很可能帶有傾斜或者污漬,那么要做的第一件事就是進行影像預處理,做角度矯正和去噪,然后要對檔案版面進行分析,進每一行進行行分割,把每一行的文字切割下來,最后再對每一行文本進行列分割,切割出每個字符,將該字符送入訓練好的OCR識別模型進行字符識別,得到結果,但是模型識別結果往往是不太準確的,需要對其進行識別結果的矯正和優化,比如可以設計一個語法檢測器,去檢測字符的組合邏輯是否合理,比如,考慮單詞Because,設計的識別模型把它識別為8ecause,那么就可以用語法檢測器去糾正這種拼寫錯誤,并用B代替8并完成識別矯正,這樣子,整個OCR流程就走完了,從大的模塊總結而言,一套OCR流程可以分為:

從上面的流程圖可以看出,要做字符識別并不是單純一個OCR模塊就能實作的(如果單純的OCR模塊,識別率相當低),都要各個模塊的組合來保證較高的識別率,上面的流程分的比較粗,每個模塊下還是有很多更細節的操作,每個操作都關系著最終識別結果的準確性,做過OCR的童鞋都知道,送入OCR模塊的影像越清晰(即預處理做的越好),識別效果往往就越好,那現在對這流程中最為重要的字符識別技術做一個總結,
2.4 OCR的簡單應用

圖 瓶蓋的生產日期識別
在一些簡單環境下OCR的準確度已經比較高了(比如電子檔案),但是在一些復雜環境下的字符識別,在當今還沒有人敢說自己能做的很好,現在大家都很少會把目光還放在如何對電子檔案的文字識別該怎么進一步提高準確率了,因為他們把目光放在更有挑戰性的領域,OCR傳統方法在應對復雜圖文場景的文字識別顯得力不從心,越來越多人把精力都放在研究如何把文字在復雜場景讀出來,并且讀得準確作為研究課題,用學界術語來說,就是場景文本識別(文字檢測+文字識別),

圖 人工智能課本識別圖
3文本檢測CTPN
2016年出了一篇很有名的文本檢測的論文:《Detecting Text in Natural Image withConnectionist Text Proposal Network》,這個深度神經網路叫做CTPN,直到今天這個網路框架一直是OCR系統中做文本檢測的一個常用網路,極大地影響了后面文本檢測演算法的方向,
回顧一下Faster RCNN做目標檢測的一個缺點就是,沒有考慮帶文本自身的特點,文本行一般以水平長矩形的形式存在,而且文本行中每個字都有間隔,針對這個特點,CTPN剔除一個新奇的想法,把文本檢測的任務拆分,第一步檢測文本框中的一部分,判斷它是不是一個文本的一部分,當對一幅圖里所有小文本框都檢測之后,將屬于同一個文本框的小文本框合并,合并之后得到一個完整的、大的文本框了,也就完成了文本的檢測任務,這個想法很有創造性,有點像“分治法”,先檢測大物體的一小部分,等所有小部分都檢測出來,大物體也就可以檢測出來了,

圖 RPN和CTPN對比
如圖所示,左邊的圖是直接使用Faster RCNN中的RPN來進行候選框提取,可以看出,這種候選框太粗糙了,效果并不好,而右圖是利用許多小候選框來合并成一個大文本預測框,可以看出這個演算法的效果非常不錯,需要說明的是,紅色框表示這個小候選框的置信度比較高,而其他顏色的候選框的置信度比較低,可以看到,一個大文本的邊界都是比較難預測的,那怎么解決這個邊界預測不準的問題呢?后面會提到,
剛提到CTPN的其中一個閃光點,即檢測小框代替直接檢測大文本框,除了這個新意,CTPN還提出了在文本檢測中應加入RNN來進一步提升效果,為什么要用RNN來提升檢測效果?文本具有很強的連續字符,其中連續的背景關系資訊對于做出可靠決策來說很重要,RNN常用于序列模型,比如事件序列,語言序列等等,那CTPN演算法中,把一個完整的文本框拆分成多個小文本框集合,其實這也是一個序列模型,可以利用過去或未來的資訊來學習和預測,所以同樣可以使用RNN模型,而且,在CTPN中,用的還是BiLSTM(雙向LSTM),因為一個小文本框,對于它的預測,不僅與其左邊的小文本框有關系,而且還與其右邊的小文本框有關系!這個解釋就很有說服力了,如果僅僅根據一個文本框的資訊區預測該框內含不含有文字其實是很草率的,應該多參考這個框的左邊和右邊的小框的資訊后(尤其是與其緊挨著的框)再做預測準確率會大大提升,

圖 CTPN候選框
如上圖所示,如果單純依靠1號框內的資訊來直接預測1號框中否存在文字(或者說是不是文本的一部分),其實難度相當大,因為1號框只包含文字的很小一部分,但是如果把2號框和3號框的資訊都用上,來預測1號框是否存在文字,那么就會有比較大的把握來預測1號框確實有文字,還可以看看為什么邊緣的文本框的置信度會較中間的低呢?個人認為很大一部分原因就在于因為這些框都位于總文本的邊緣,沒有辦法充分利用左右相鄰序列的資訊做預測(比如位于最左的文本框丟失了其右邊的資訊),這就是雙向LSTM的作用,把左右兩個方向的序列資訊都加入到學習的程序中去,
CTPN借助了Faster RCNN中anchor回歸機制,使得RPN能有效地用單一尺寸的滑動視窗來檢測多尺寸的物體,當然CTPN根據文本檢測的特點做了比較多的創新,比如RPN中anchor機制是直接回歸預測物體的四個引數(x,y,w,h),但是CTPN采取之回歸兩個引數(y,h),即anchor的縱向偏移以及該anchor的文本框的高度,因為每個候選框的寬度w已經規定為16個像素,不需要再學習,而x坐標直接使用anchor的x坐標,也不用學習,所以CTPN的思路就是只學習y和h這兩個引數來完成小候選框的檢測!跟RPN相類似,CTPN中對于每個候選框都使用了K個不同的anchors(k在這里默認是10),但是與RPN不同的是,這里的anchors的width是固定的16個像素,而height的高度范圍為11~273(每次對輸入影像的height除以0.7,一共K個高度),當然CTPN中還是保留了RPN大多數的思路,比如還是需要預測候選框的分數score(該候選框有文本和無文本的得分),
文本行構建很簡單,通過將那些text/no-text score > 0.7的連續的text proposals相連接即可,文本行的構建如下,首先,為一個proposal Bi定義一個鄰居(Bj):Bj?>Bi,其中,Bj在水平距離上離Bi最近,該距離小于50 pixels它們的垂直重疊(vertical overlap) > 0.7,另外,如果同時滿足Bj?>Bi和Bi?>Bj,會將兩個proposals被聚集成一個pair,接著,一個文本行會通過連續將具有相同proposal的pairs來進行連接來構建,
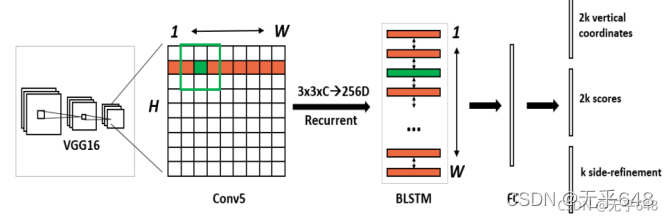
圖 CTPN網路架構
首先CTPN的基礎網路使用了VGG16用于特征提取,在VGG的最后一個卷積層CONV5,CTPN用了3×3的卷積核來對該feature map做卷積,這個CVON5 特征圖的尺寸由輸入影像來決定,而卷積時的步長卻限定為16,感受野被固定為228個像素,卷積后的特征將送入BLSTM繼續學習,最后接上一層全連接層FC輸出要預測的引數:2K個縱向坐標y,2k個分數,k個x的水平偏移量,看到這里大家可能有個疑問,這個x的偏移到底是什么,為什么需要回歸這個引數?如果需要X的引數,為什么不在候選框引數回歸時直接預測成(x,y,h)三個引數呢,而要多此一舉把該引數單獨預測,這個X的作用作者提到這也是他們論文的一大亮點,稱之為Side-refinement,可以理解為文本框邊緣優化,回顧一下上面提到的一個問題,文本框檢測中邊緣部分的預測并不準確,那么改咋辦,CTPN就是用這個X的偏移量來精修邊緣問題,這個X是指文本框在水平方向的左邊界和右邊界,通過回歸這個左邊界和右邊界引數進而可以使得對文本框的檢測更為精準,在這里想舉個例子說明一下回歸這個x引數的重要性,
通過觀察下圖,第一幅圖張看到有很多小候選框,位于左邊的候選框我標記為1、2、3、4號框,1號框和2號框為藍色,表明得分不高就不把這兩個框合并到大文本框內,對于3號框和4號框那就比較尷尬了,如果取3號框作為文本框的邊緣框,那么顯然左邊邊緣留白太多,精準度不夠,但如果去掉3號框而使用4號框作為左邊緣框,則有些字體區域沒有檢測出來,同樣檢測精度不足,這種情況其實非常容易出現,所以CTPN采取了Side-refinement 思路進一步優化邊緣位置的預測即引入回歸X引數,X引數直接標定了完整文本框的左右邊界,做到精確的邊界預測,第二幅圖中的紅色框就是經過Side-refinement后的檢測結果,可以看出檢測準確率有了很大的提升, side-refinement確實可以進一步提升位置準確率,在SWT的Multi-Lingual datasets上產生2%的效果提升,

再看多幾幅圖,體驗一下Side-refinement后的效果,

最后總結一下CTPN這個流行的文本檢測框架的三個閃光點:
- 將文本檢測任務轉化為一連串小尺度文本框的檢測;
- 引入RNN提升文本檢測效果;
- Side-refinement(邊界優化)提升文本框邊界預測精準度,
當然,CTPN也有一個很明顯的缺點:對于非水平的文本的檢測效果并不好,CTPN論文中給出的文本檢測效果圖都是文本位于水平方向的,顯然CTPN并沒有針對多方向的文本檢測有深入的探討,
4總結
通過查閱相關資料學習什么是OCR并且查閱了如何實作OCR文字識別中的文字檢測,并且通過理論實作流程并且用代碼對CPTN文字檢測進行復現,通過對文字資料預處理并且進行文字字符分割,看似簡單,做起來其實很難做得很好,我們也對此查閱了很多論文,發現其實很多論文也談到了,漢字確實很那做到一個高正確率的分割,直至現在還沒有一統江湖的解決方案,漢字切割的失敗,就會直接導致了后面OCR識別的失敗,這也是當前很多一些很厲害的OCR公司都沒法把漢字做到100%識別的一個原因,所以這個問題就必須得到很好的解決,最后我們解決漢字切割的較好方法是,在OCR識別中再把它修正,并且通過文字分割后對資料進行資料增強生成了大量資料防止模型的過擬合,并且通過學習CPTN論文,學習到了思路上的創新,在檢測水平上的文字置信度很高,但是也有一些弊端對于非水平的文本檢測效果并不好,
5參考文獻
[1] Detecting Text in Natural Image with Connectionist Text Proposal Network.作者: Zhi Tian; Weilin Huang; Tong He; Pan He; Yu Qiao 0001
[2]基于深度學習的漢字識別方法研究[D].任鳳麗.東華大學. 2021
[3]基于深度學習的光學字符識別技術研究[D].馮亞南.南京郵電大學 2020
[4]基于卷積神經網路的手寫數字識別研究與設計[D].劉辰雨.成都理工大學2018
[5]基于CRNN的中文手寫識別方法研究[J]. 石鑫,董寶良,王俊豐.資訊技術. 2019(11)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394134.html
標籤:AI