
零,起因
我為什么要造redis這個輪子?
1,破除對redis神秘感,
2,“基礎服務中臺”的同事們在開會討論redis云,以及redis代理,
3,開一個redis資源并不是容易事,為什么不可以不可以寫成java直接推送到未來云上,簡單方便,
以這個思路我開始使用業余時間研究了redis的tcp通訊原理與redis命令,出發點是寫一個redis云代理之類的云管理軟體,但是還是忍不住寫成了java版的redis,本文章主要分享redis的撰寫心路歷程,
復制代碼一,redis通訊與Netty
1,tcp
連到Redis服務器的客戶端建立了一個到6379埠的TCP連接,
雖然RESP在技術上不特定于TCP,但是在Redis的背景關系中,該協議僅用于TCP連接(或類似的面向流的連接,如unix套接字),
使用netty作為通訊框架,
2,協議
Redis客戶端和服務器端通信使用名為 RESP (REdis Serialization Protocol) 的協議,雖然這個協議是專門為Redis設計的,它也可以用在其它 client-server 通信模式的軟體上, RESP 協議在Redis1.2被引入,直到Redis2.0才成為和Redis服務器通信的標準,這個協議需要在你的Redis客戶端實作,
RESP 是一個支持多種資料型別的序列化協議:簡單字串(Simple Strings),錯誤( Errors),整型( Integers), 大容量字串(Bulk Strings)和陣列(Arrays),
RESP在Redis中作為一個請求-回應協議以如下方式使用:
客戶端以大容量字串RESP陣列的方式發送命令給服務器端, 服務器端根據命令的具體實作回傳某一種RESP資料型別, 在 RESP 中,資料的型別依賴于首位元組:
單行字串(Simple Strings): 回應的首位元組是 "+" 錯誤(Errors): 回應的首位元組是 "-" 整型(Integers): 回應的首位元組是 ":" 多行字串(Bulk Strings): 回應的首位元組是"$" 陣列(Arrays): 回應的首位元組是 "*" 另外,RESP可以使用大容量字串或者陣列型別的特殊變數表示空值,下面會具體解釋,RESP協議的不同部分總是以 "\r\n" (CRLF) 結束, 字串 "foobar" 編碼如下:
"$6\r\nfoobar\r\n"
復制代碼實際redis命令是什么樣的,比如 SET lhjljh lhjkjhkh
*3\r\n$3\r\nSET\r\n$6\r\nlhjljh\r\n$8\r\nlhjkjhkh
復制代碼3,編解碼
由于RESP天然是面向處理命令的,所以沒辦法直接把redis訊息像grpc或者dubbo那樣直接序列化和反序列化訊息,并且每個內容限定了長度,很適合做成及時序列化、零拷貝,直接針對輸入流做反序列化和序列化,這一點與Protostuff序列化協議的設計很類似, 所以序列化直接將服務端接收的流直接轉成值,
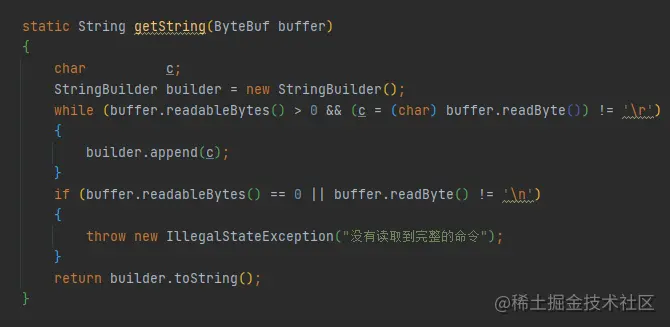
編解碼的物體類直接加入redis server 的處理某一個長連接tcp客戶端的管道上,

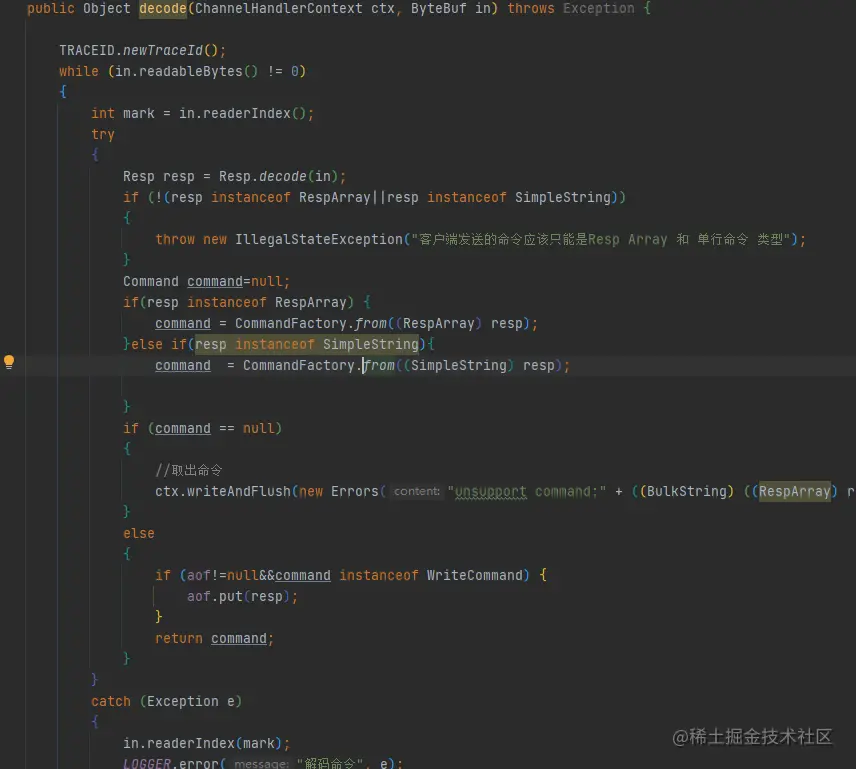
4,命令處理
將訊息解碼成RESP,還需要將RESP轉為Command物件,這里因為是java語言,方法與類系結,撰寫上和理解上會更加容易,但是會增加一些開銷,
二,redis 的資料結構
1,底層主結構
底層主樹使用跳表ConcurrentSkipListMap實作,沒用hash類map的原因是服務端是集群后,客戶端可能使用hash路由,會導致服務端嚴重的hash沖突,性能大打折扣
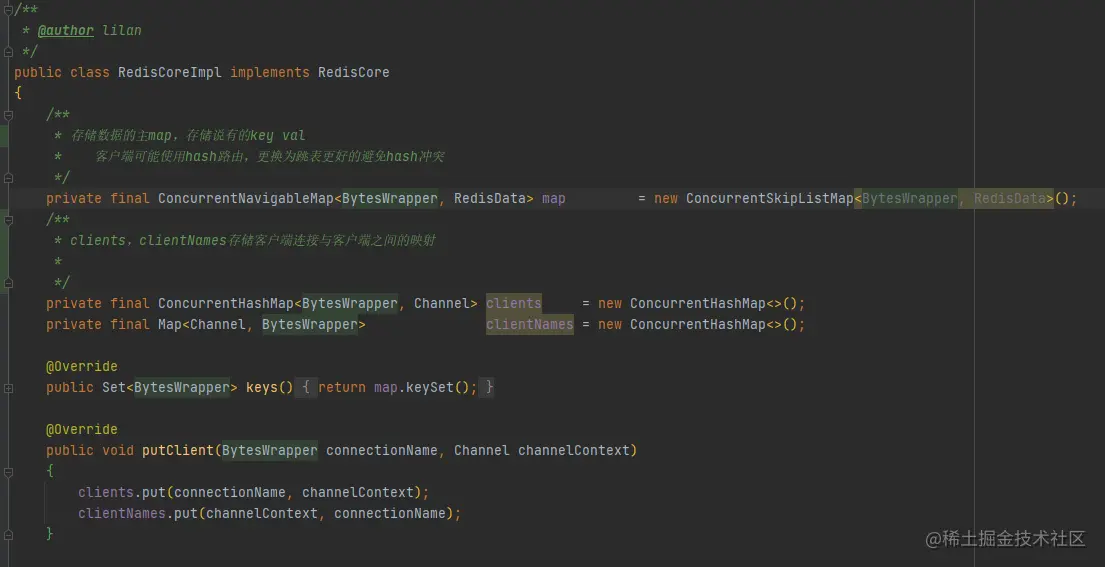
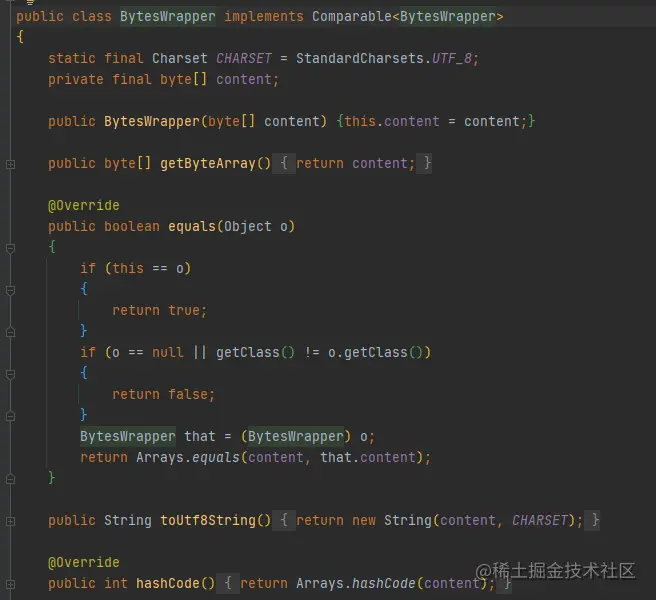
key為封裝的“String”,重寫了equals方法避免相同的key但是在jvm中指標不同
value是一個介面,實作類是redis的五大基本型別,所有資料型別都包含超時時間
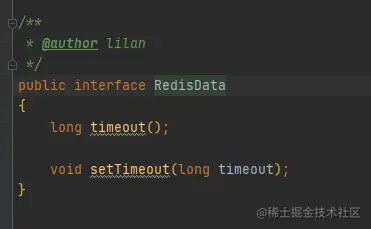
2,key
用封裝的值做value的原因是方便統一管理
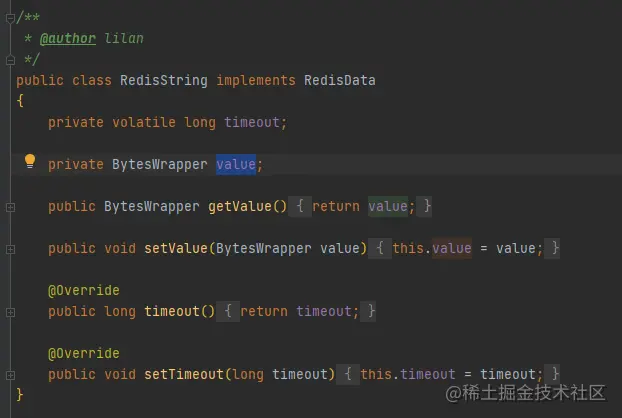
3,list
底層使用LinkedList的原因是LinkedList實作了多種介面,實作各種命令直接呼叫其現成實作的方法即可
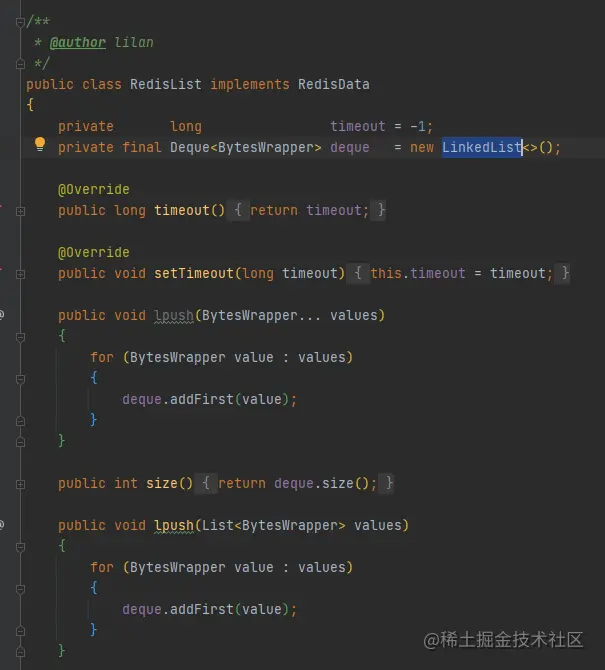
4,set
底層使用HashSet,redis里的set沒有多特殊
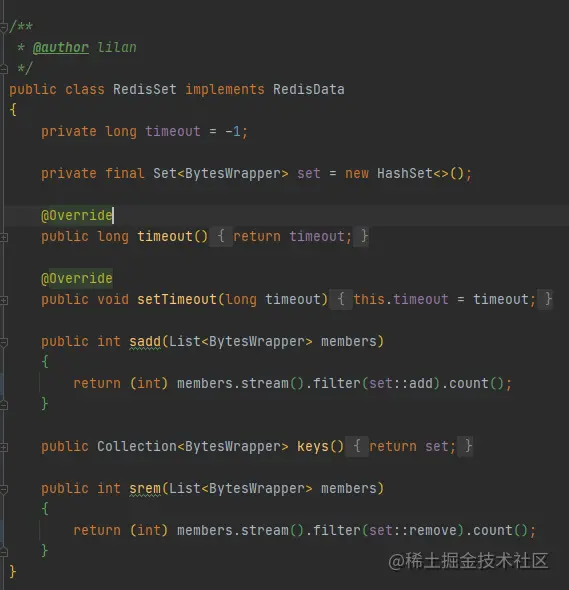
5,hash
底層使用HashMap,這里和開頭說的HashMap不沖突,為什么不用跳表?壓縮串列很巧妙,大抵的意思就是將通信收到的陣列直接填充到list中,將list直接按照次序直接當map使用,主要是0拷貝的思想,無需創建新資源,性能極高,但注意壓縮串列與壓縮無關,
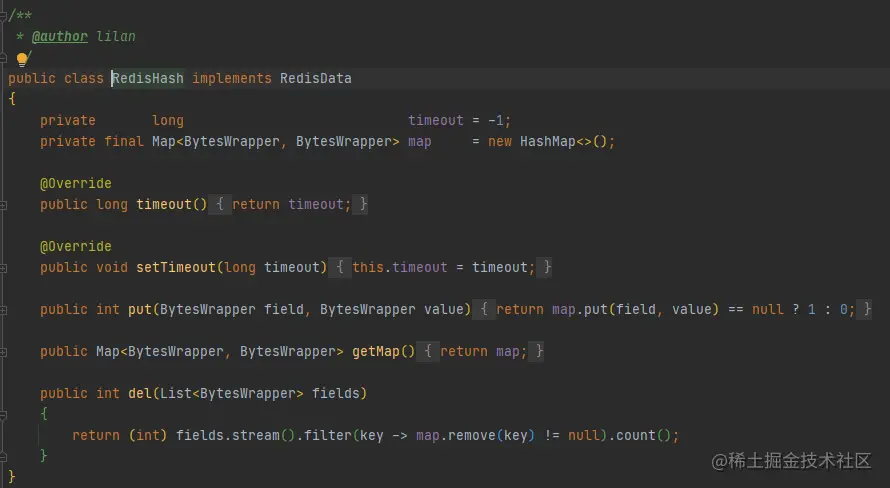
6,zset
首先需要封裝一個帶有值和分值的物件
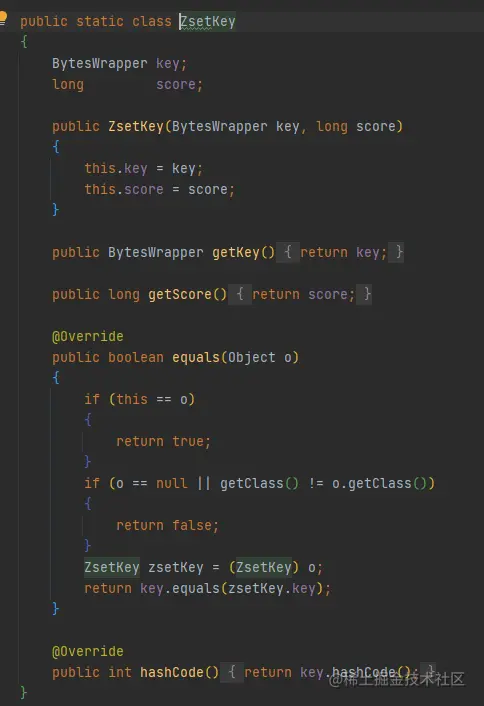
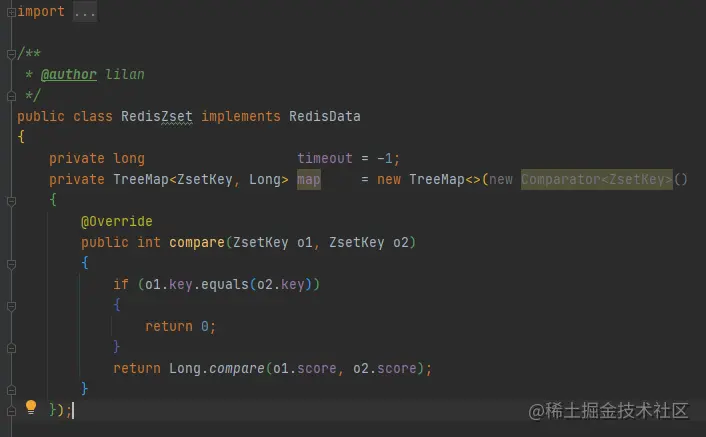
再用TreeMap重寫compare方法即可,使用TreeMap原因是他天然有良好的排序功能,很多hash一致路由的演算法都用的TreeMap二開,
三,redis AOF 持久化
1,aof執行緒與tcp執行緒解耦,即寫緩沖
再決議redis命令時,將redis寫命令添加到寫aof日志的佇列中
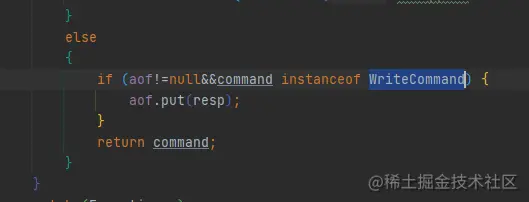
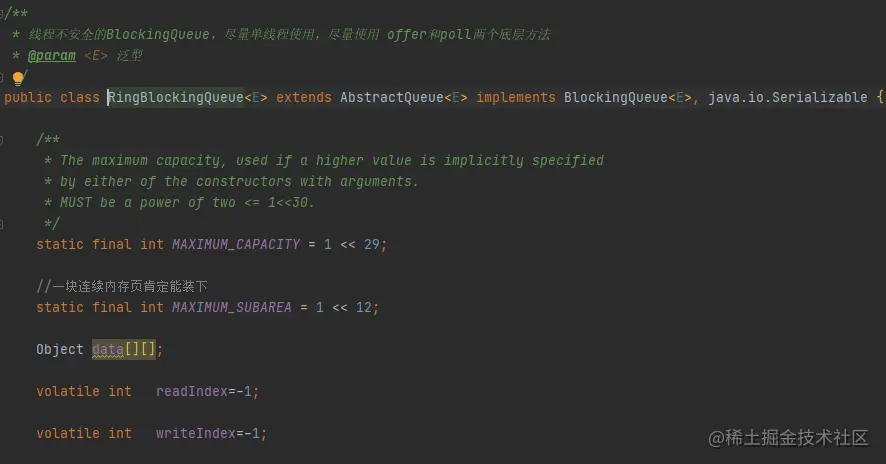
這里自己封裝了一個堵塞佇列,單執行緒吞吐量可以達到3000W /s是LinkedBlockingQueue的6到10倍,完全可以勝任此場景
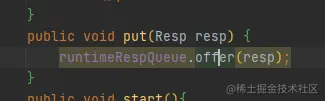
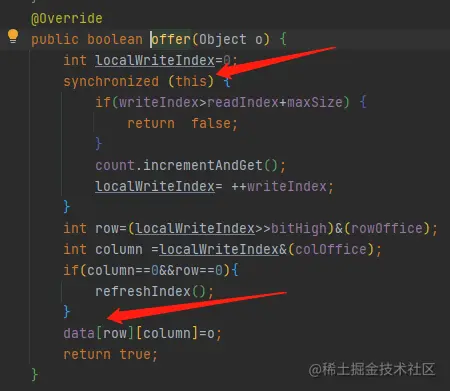
RingBlockingQueue吞吐量非常高的原因是使用了記憶體連續頁的機制,
2,aof持久化協議
aof協議一句話概括就是將寫命令,追加到日志中,開始時將命令讀取,當作收到網路的命令執行即可,由于協議過于簡單,這里就不貼鏈接了, aof之日格式如下圖:
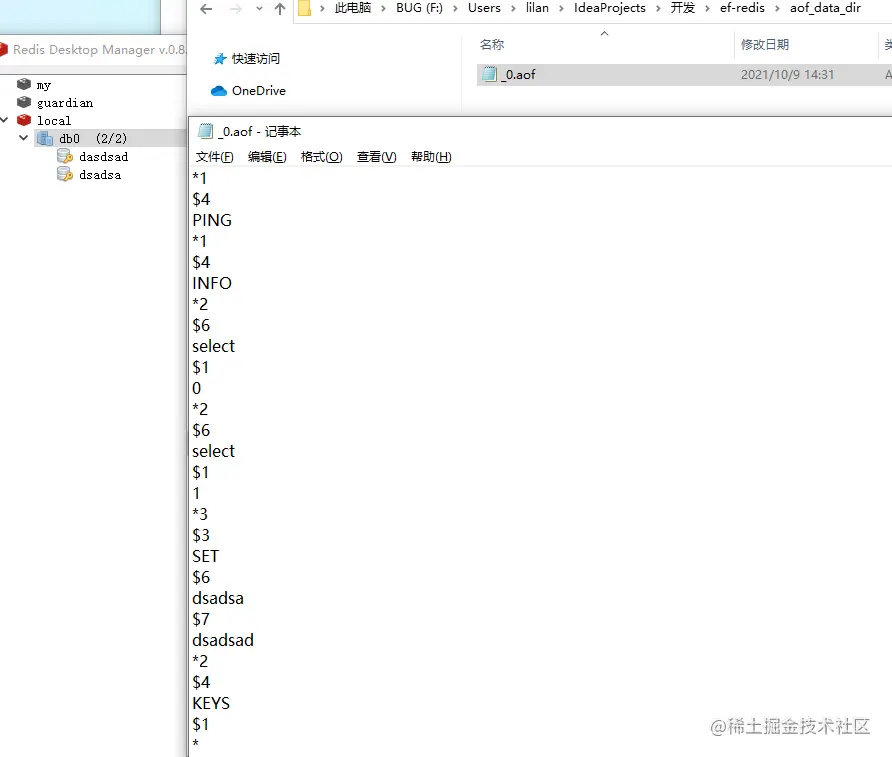
3,aof的加載與存盤實作
這里讀寫記憶體都是用的記憶體檔案映射,好處是讀寫性能好,壞處是可能會出現記憶體泄漏,除錯期間比較麻煩,
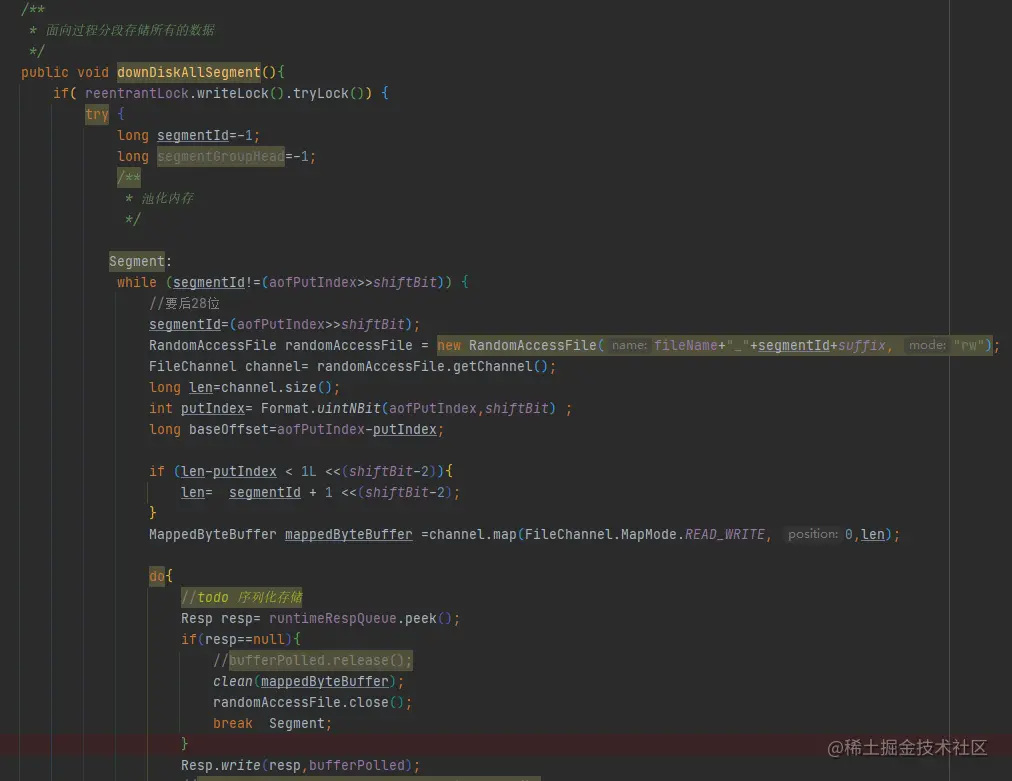
4,記憶體檔案映射與面向物件
這里存盤和加載aof檔案的代碼都是面向程序的,看起來非常復雜,實際上之前是按照面向物件寫的,封裝成了行物件,呼叫落盤符和拾起方法就可以寫入和讀取aof中的命令,但是TPS僅為10w/s,后來權衡后改為面向程序,吞吐量提升到了100W的TPS以上,
四,redis 的集群特性
1,主從
這里很容易聯想到mysql的只從,很多場景下會使用基于mysql主從的讀寫分離,或者zk的主從, 但實際上redis的主從是不保證一致性的,個人認為redist的主從主要考慮的是cap的分布式容錯性, 因為redis主從不保證一致性,所以使用redis讀寫分離,可能造成一些不一致的問題,寫寫是一致的,但是讀是不一致的,可以根據專案需要做取舍,
2,主從復制
redis的主從復制這里作者沒看懂(可能也是一致性上有坑沒動力去看),所以沒寫出來,
3,分片集群
redis集群主要分為幾個唯獨: 主從、磁區集群、代理, 一般在redis客戶端的視角下,主要是磁區集群,根據發送給redis的key做hash、md5等操作,取一個所有客戶端的共識值,將key和value發送,也就是客戶端路由分布式軟體的集群實作方式京東的redis集群設計到redis具體一個分片,
五,redis 的壓測與調優
1,aof記憶體泄漏
開啟aof壓測發現出現了記憶體泄漏,后來發現是頻繁新建記憶體池而造成的,所以將記憶體池池化,即aof物件中僅存在一個bytebuff記憶體池,
2,記憶體復用提升性能
這里編解碼沒有單獨開辟byte資料接收bytebuff的資料進行編解碼,編解碼直接讀取bytebuff進行編解碼,沒有出現記憶體拷貝,唯獨新建了BytesWrapper物件,但存盤的資料都是使用BytesWrapper物件,對記憶體新建/銷毀的開銷很少,
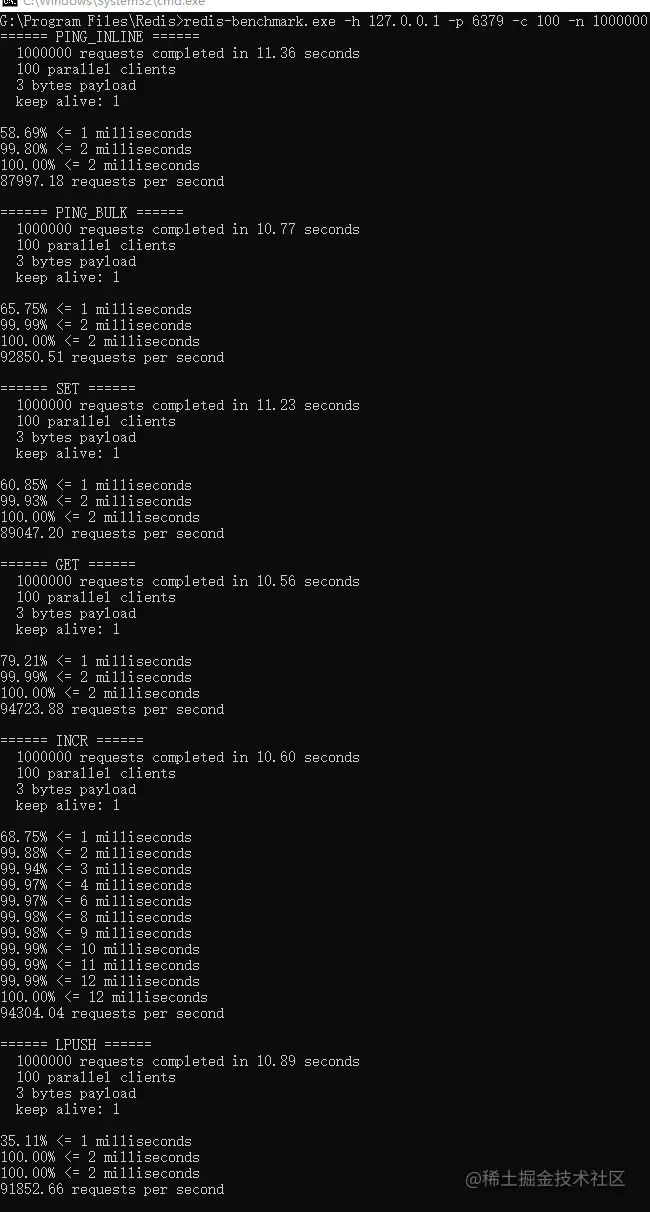
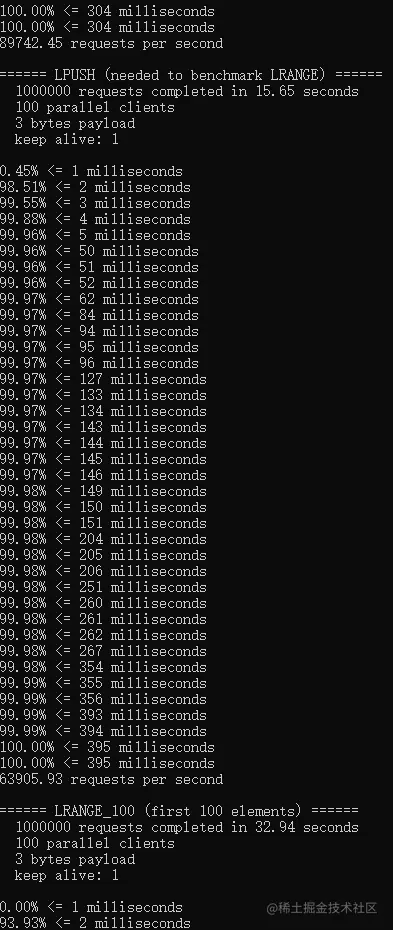
3,0.05%訊息延遲超200ms排查
下圖為c語言版的redis壓測資料:
下圖為java語言版的redis壓測資料:
4,性能表現
redis原版的性能大概是E5系列CPU 4-5w左右,上圖中是使用amd芯片測驗的資料, 使用redis自帶的壓測工具,維持100個客戶端連接,java版性能是c語言原版性能的75-90%左右,性能依然強悍,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394184.html
標籤:其他