要求:
1.將待分析的檔案(不少于10000英文單詞)上傳到HDFS,
2.呼叫MapReduce對檔案中各個單詞出現的次數進行統計,
3.將統計結果下載本地,
作業分析:
我們需要實作的是呼叫MapReduce對檔案中各個單詞出現的次數進行統計,要求在Linux系統中實作上述操作,首先要安裝Ubuntu系統,然后要配置Java環境,安裝JDK,Ubuntu提供了一個健壯,功能豐富的計算環境,
簡述操作步驟:
1、在eclipse中創建專案
2、匯入所需要的jar包
3、創建JAVA檔案,并允許,檢測功能
4、建立myapp目錄,匯出jar檔案到這個目錄下
5、建立wordcout工程,并匯入所需的jar包
6、創建JAVA檔案,運行,并匯出包到myapp目錄下
7、啟動Hadoop,首先洗掉HDFS中與當前Linux用戶hadoop對應的input和output目錄
8、新建input目錄,并把需要分析的檔案傳到該目錄下
9、使用hadoop jar命令運行程式,查看分析結果
10、最后,.將統計結果下載至本地
詳細步驟:
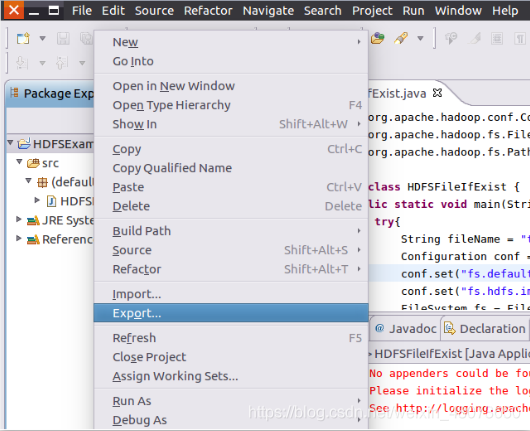
一:首先在eclipse中創建檔案,開始創建一個JAVA工程,單機“NEXt”
二:如圖匯入工程所需要的JAR包,把剩余的其他JAR包都添加進來,需要注意的是,當需要選中某個目錄下的所有JAR包時,可以使用“Ctrl+A”組合鍵進行全選操作,全部添加完畢以后,就可以點擊界面右下角的“Finish”按鈕,完成Java工程HDFSExample的創建,
1、在新建好的工程中,右鍵選擇new->Class,如圖創建名為“HDFSFileIfExist”的源代碼檔案
2、在新建的源代碼中,輸入圖上代碼并運行
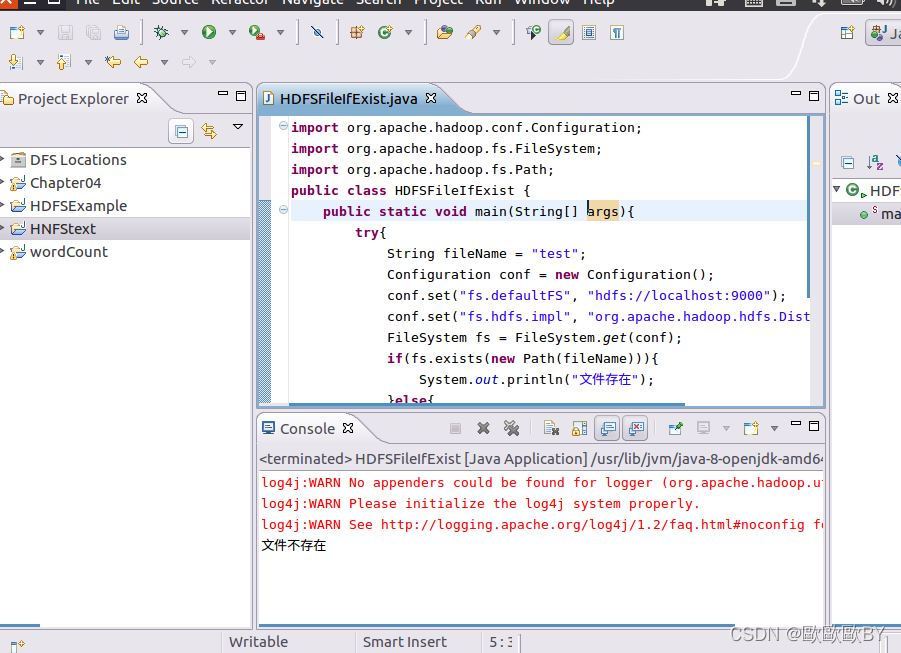
代碼如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {undefined
public static void main(String[] args){undefined
try{undefined
String fileName = “test”;
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”, “hdfs://localhost:9000”);
conf.set(“fs.hdfs.impl”, “org.apache.hadoop.hdfs.DistributedFileSystem”);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){undefined
System.out.println(“檔案存在”);
}else{undefined
System.out.println(“檔案不存在”);
}
運行后結果為:
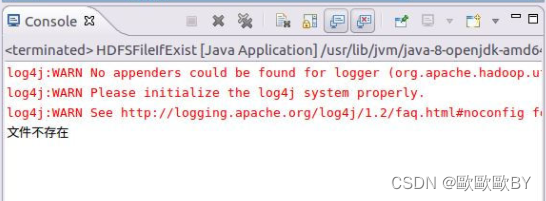
3、在Hadoop安裝目錄下,新建一個myapp檔案夾,用來存放自己撰寫的Hadoop程式
如下圖:
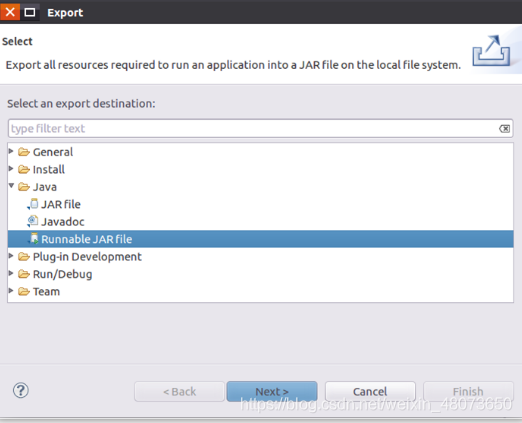
4、選擇相對應的路徑
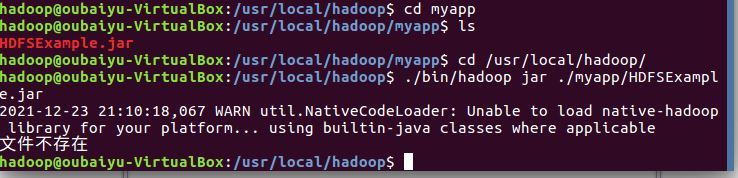
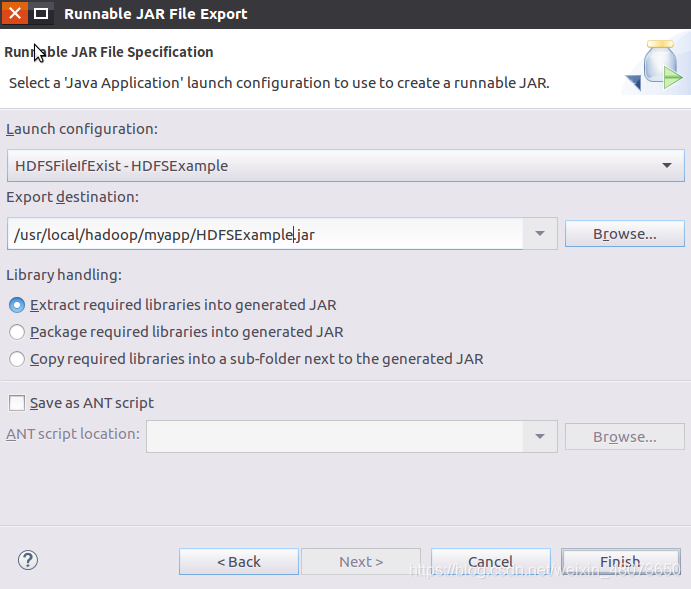 在終端中查看命令,并運行匯出的檔案,是否為“檔案不存在”
在終端中查看命令,并運行匯出的檔案,是否為“檔案不存在”
三、通過Eclipse運行MapReduce
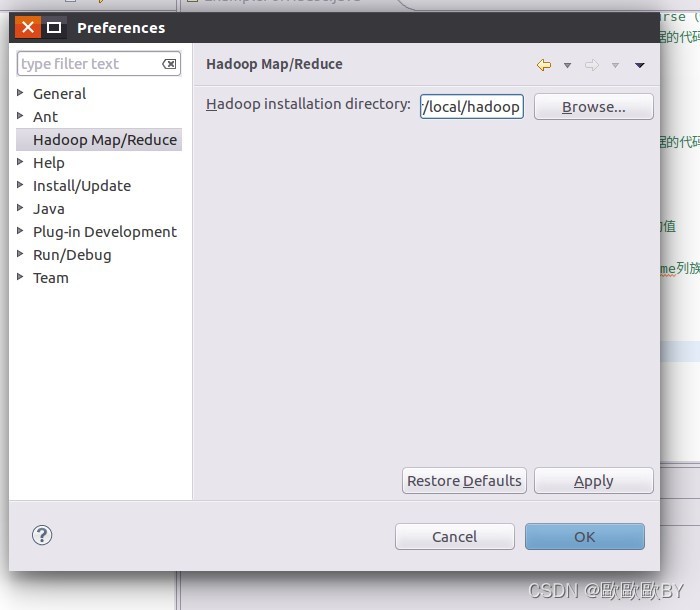
1、MapReduce安裝配置過程,參考林子雨安裝具體步驟:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
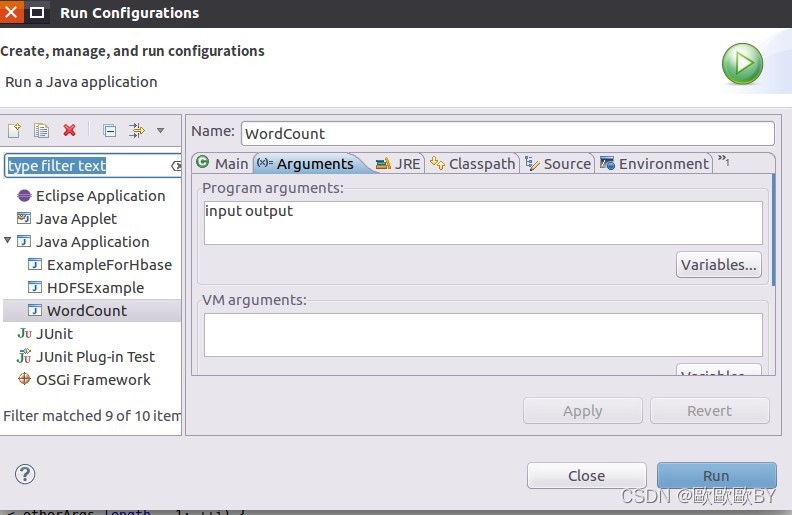
2、新建Wordcout工程,跟上面創建HDFSFileIfExist工程一樣,匯入所需要的JAR包,并復制一下代碼運行程式
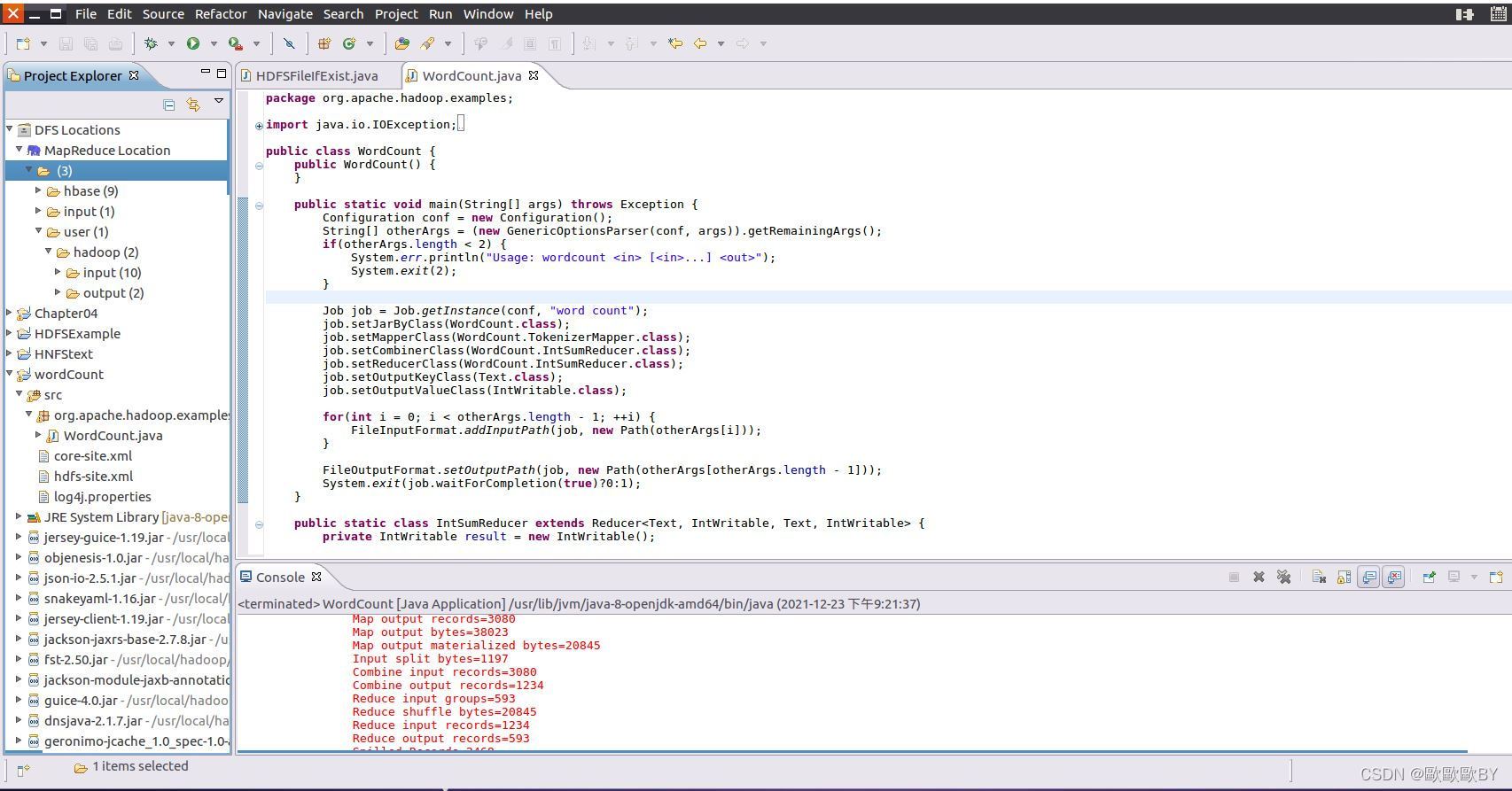
代碼如下:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}3、運行后在左側DFS任務欄中重繪,會出現input與output檔案夾
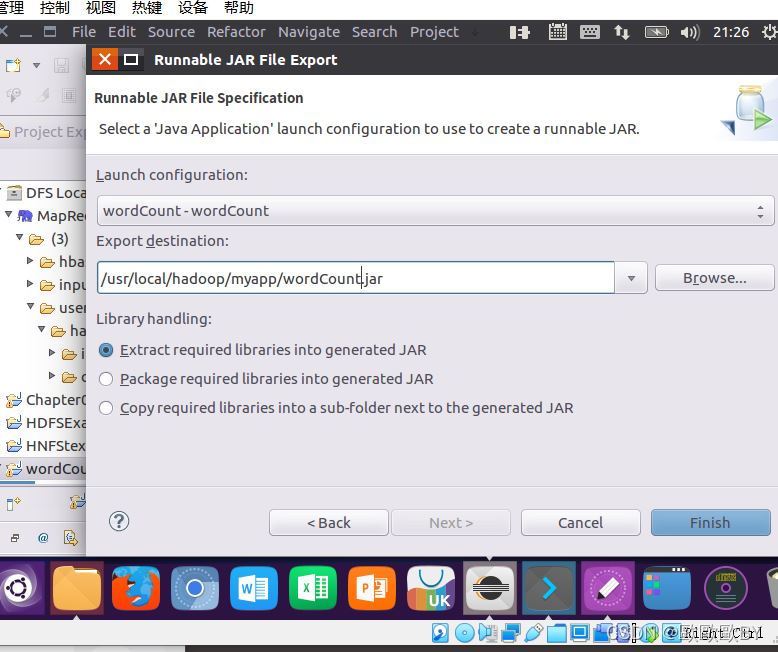
4、匯出wordcout工程到myapp目錄中
四:配置好相關的檔案后,開始在終端進行操作,提前準備好需要檢測的檔案(1W個英語單詞文本,可以在相關英文論文爬下來,拉進后放在/usr/local/hadoop中)
1、進入hadoop安裝目錄,并啟動hadoop,進入myapp檔案夾,使用ls命令查看檔案內容
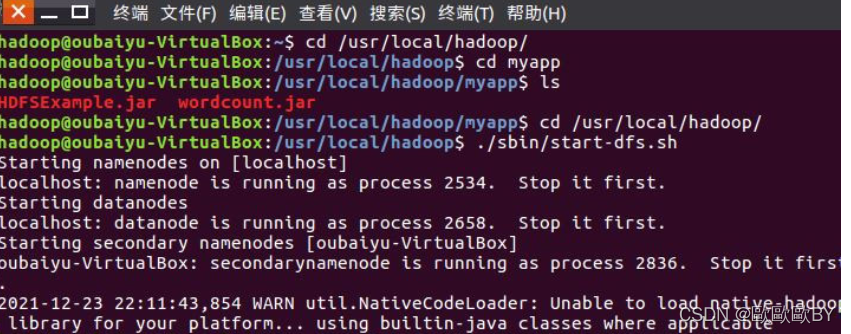
2、首先洗掉HDFS中與當前Linux用戶hadoop對應的input和output目錄(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目錄
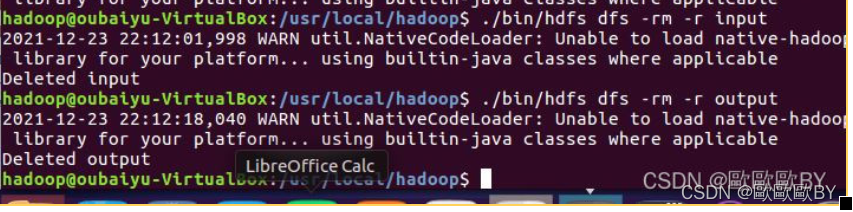
說明:因為之前運行過wordcout程式,所以已經生成了Input 與output,所以需要洗掉重新生成才能運行,否則會報錯,使用mkdir 命令創建新的Input檔案夾
3、通過-put命令,把需要檢測的檔案夾放入input中
 4、使用hadoop jar命令運行程式,命令如下
4、使用hadoop jar命令運行程式,命令如下
cd /usr/local/hadoop
./bin/hadoop jar ./myapp/WordCount.jar input output
得到下圖:
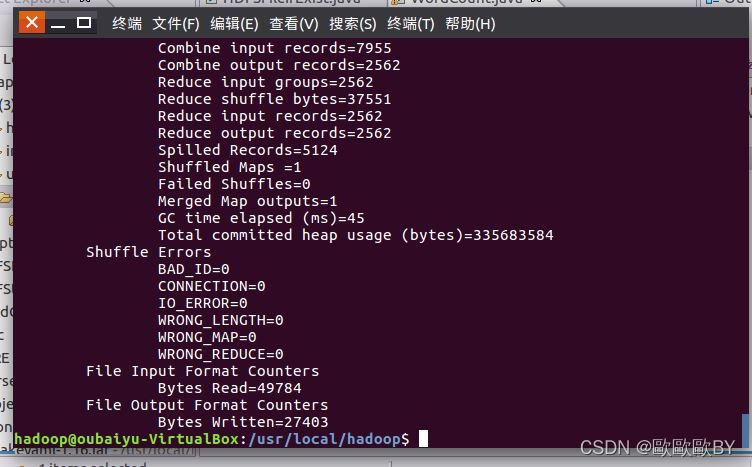
5、使用-cat命令,查看output檔案內容,查看詞頻統計結果

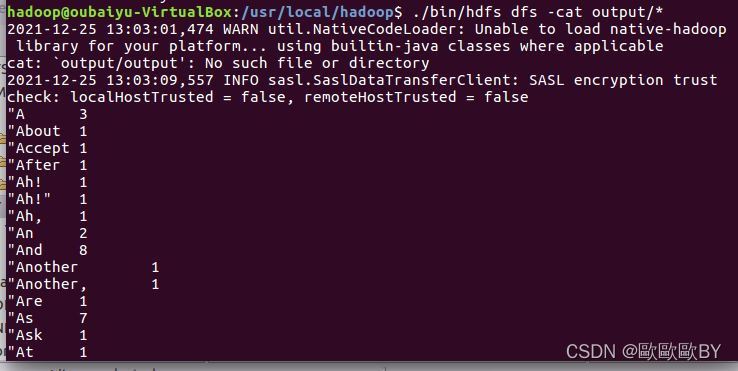
6、最后,.將統計結果下載至本地,如下圖

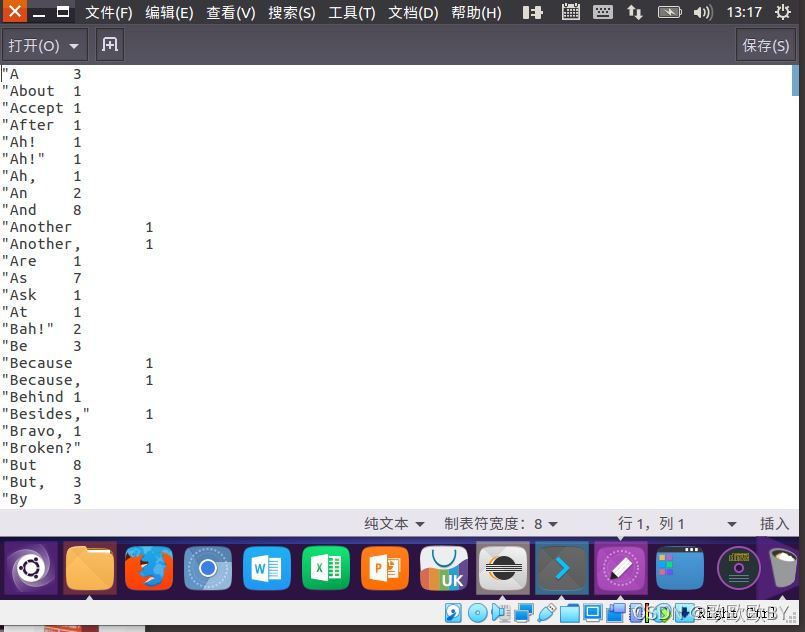
呼叫MapReduce對檔案中各個單詞出現次數進行統計的實驗到這里就結束了,在實驗程序中,有warning警告可以忽略,但是要注意output中是否存在檔案在執行命令,不然會有報錯的可能性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394195.html
標籤:其他