目錄
- 引言
- 模型介紹
- 1. 輸入格式
- 2. 實驗結果
- 總結
引言
問答任務有多種形式,常見的有抽取式問答(EX)、摘要式問答(AB)、多選題式問答(MC)、判斷式問答(YN),

一般的解決方案是針對不同形式的問答任務設計不同的模型,例如,抽取式問答、多選題式問答、判斷式問答可以轉化為分類任務,摘要式問答可以轉換為生成任務,
盡管任務形式不同,但模型所需的語意理解和推理能力是共通的,或許不需要 format-specialized models,基于這種直覺,Allen 研究所聯合華盛頓大學于2020年11月在 EMNLP 上提出首個可以處理多種形式的預訓練問答模型 UnifiedQA,成為多個問答任務的新 SOTA,所有 NLP 任務都能轉換為 seq2seq 任務,基于同樣的思想,UnifiedQA 是一個 text-to-text 的預訓練問答模型,編碼器接收用“\n”拼接起來的問題,解碼器生成回答,Table 1 展示了四個問答任務的樣例,
論文名稱:UNIFIEDQA: Crossing Format Boundaries with a Single QA System
論文鏈接:https://aclanthology.org/2020.findings-emnlp.171
論文代碼:https://github.com/allenai/unifiedqa
主要貢獻:
- 構建了與形式無關的預訓練問答系統,效果可以媲美甚至超過 format-specialized models,證明模型的推理能力是共通的,不受形式限制;
- 對沒見過的資料集(zero-shot)泛化能力強;
- 微調 UnifiedQA 在十個問答資料集上可以達到新 SOTA,

模型介紹
T5 是一個前綴prompt加持下的多任務 transfomer 預訓練模型,對于不同的任務會在輸入序列的最前面加上任務的描述;BART 是 BERT 和 GPT 的結合,兩個模型都是 text-to-text 模型,非常適用于統一不同的形式,因此,UnifiedQA 用 11B 引數的 T5 和 BARTlarge 作為起始點進行預訓練,
1. 輸入格式
作者收集了四個類別的 20 個英文問答資料集,選取其中 8 個資料集作為訓練集,編碼過的輸入在每個 batch 中均分分布,
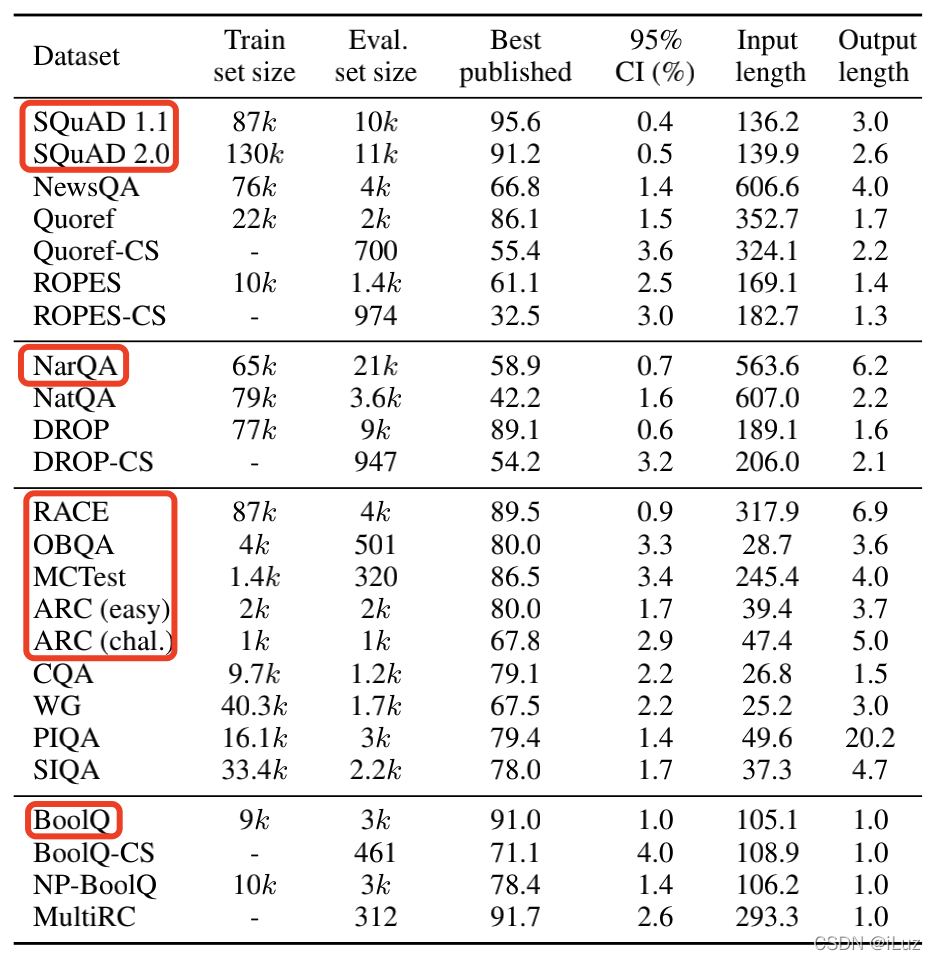
訓練集至少包括問題和回答,還有的包括回答問題所需的背景關系 context 或選項,編碼過的輸入是問題放在最前面,其次是選項,最后放背景關系,三個部分用 “\n” 連接,如 Table 1 所示,
2. 實驗結果
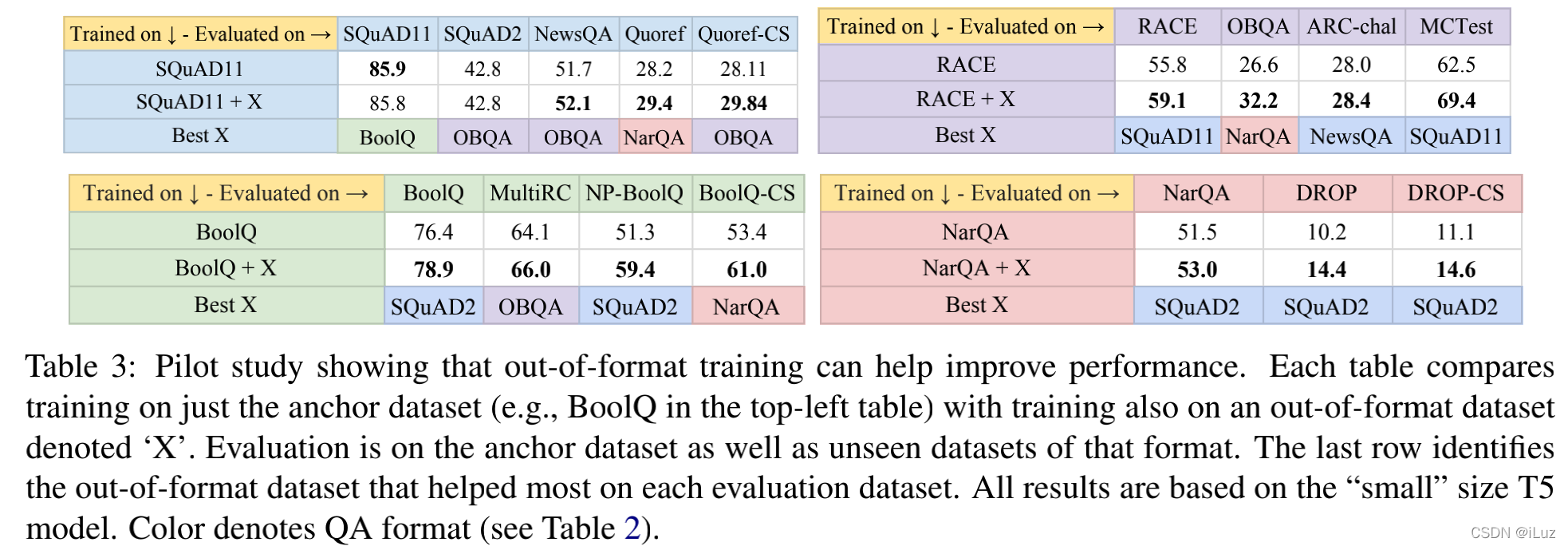
- 作者證明了多任務是有效的:對比單型別任務的性能和多型別任務的性能,發現抽取式問答和摘要式問答相輔相成,單類別任務在訓練集上加上其他類別的資料集就能帶來增益,
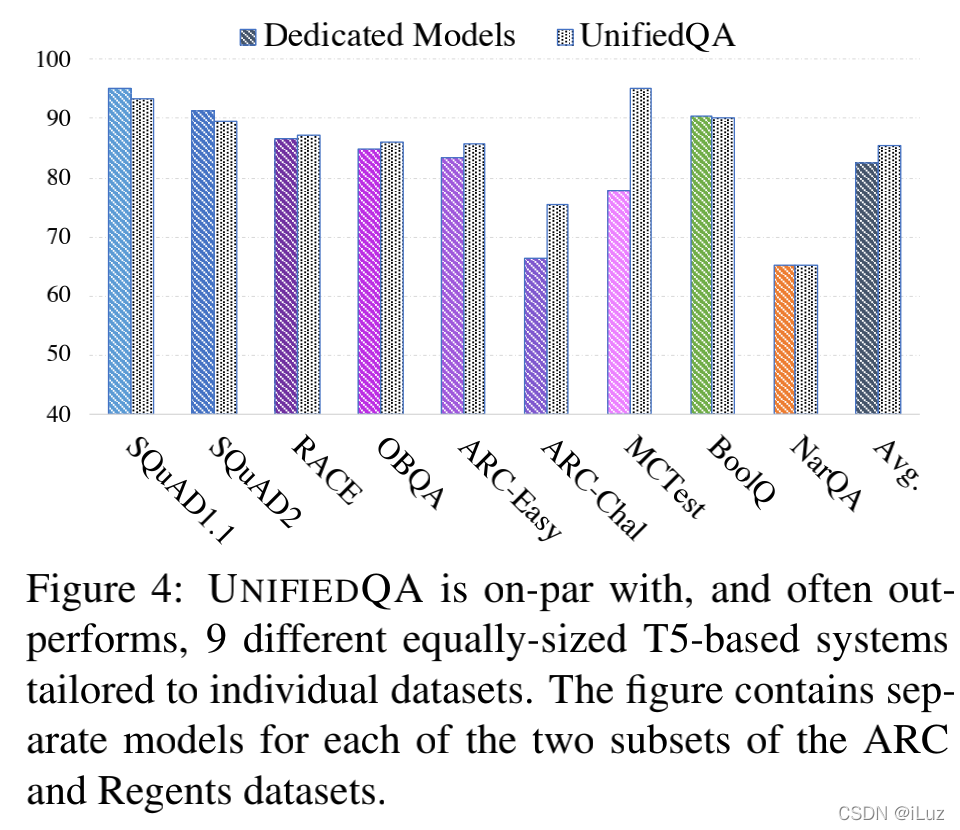
- UnifiedQA 可以媲美甚至超過單獨訓練的模型:在 8 個資料集上分別微調 T5 進行對比
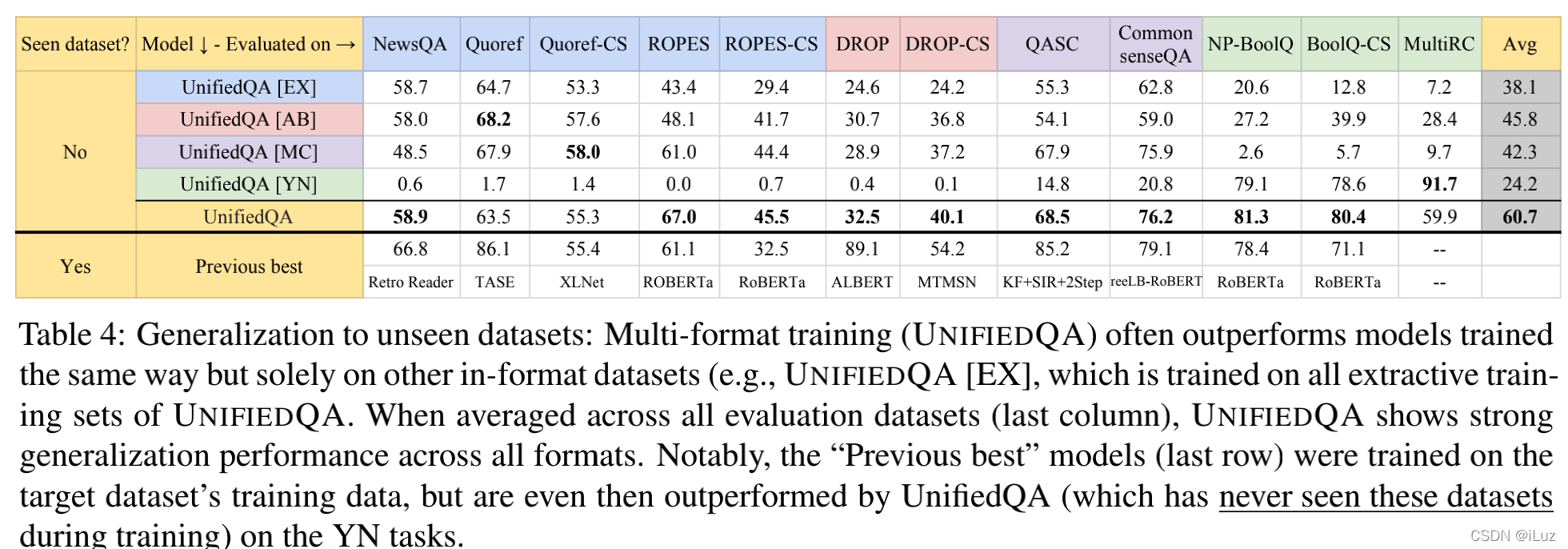
- UnifiedQA 對于沒見過的資料集泛化性好:作者對比了在單型別任務上訓練的模型和多型別任務模型的泛化性,發現還是多型別任務的泛化性好,筆者認為實驗結論也證明了形式不一的任務提高了模型的推理能力,所謂“見多識廣”,比專攻單型別的模型表現要好,
- UnifiedQA 微調后效果更上一層樓:作者對比了 UnifiedQA、T5、BART各自在沒見過的資料集上微調,發現基于 T5 的 UnifiedQA 表現最好,同時也重繪了SOTA
- 最后作者證明了訓練集的選取也很重要:缺少BoolQ, SQuAD 2.0, OBQA, NarQA任意一個都會對模型性能帶來較大的損害
總結
UnifiedQA 和 T5 的區別:
- UnifiedQA 僅用于問答任務,而 T5 的適用范圍更廣;
- UnifiedQA 由于只用于問答任務,不需要顯式地添加指示任務型別的前綴 prompt,需要模型在訓練程序中自己學會“要干什么”,增大了訓練難度,不需要指示任務型別的前綴 prompt 也是作者倡導的賣點,因此,作者并沒有探究顯式加上描述任務的 prompt 對訓練有什么影響,
UnifiedQA 為什么有效:
UnifiedQA 的成功歸功于多資料+多任務+生成模型,缺一不可,多任務還能成功的關鍵在于任務之間有本質的聯系,都是問答任務,不是區別很大的任務(例如問答+翻譯),本質上 UnifiedQA 也用到了 prompt 的思想,對不同型別的問答任務設計了相同的模版,這篇論文也證明了不需要多么復雜的模型,只需要合理地組合更豐富的資料就能帶來提升(資料依然是提點關鍵),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395008.html
標籤:AI
上一篇:讀論文七步走,CV資深博客專家長文:一篇論文需要讀4遍
下一篇:Linux的FTP的深度學習