機器學習05:SVM支持向量機的學習和應用SVM解決貓狗影像分類問題
文章目錄
- 機器學習05:SVM支持向量機的學習和應用SVM解決貓狗影像分類問題
- 前言
- 1.從二維線性模型說起
- 2. 如何求解SVM的相關變數
- 3.資料集介紹
- 4. 資料集處理
- 5.使用SVM解決影像分類問題并統計平均錯誤率
- 結語
前言
svm作為深度學習提出前曾經風靡一段時間的機器學習方法,廣泛被應用在資料分類,資料處理上,它以巧妙的演算法(巧妙到對我來說真的有點復雜了😫😫😫,,,),速度快,分類正確率高而著稱,我們本篇博客則重點介紹svm支持向量機的具體原理,以及他具體如何來處理分類問題,
1.從二維線性模型說起
讓我們先來看這個問題,假設我們有給出一系列資料:
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
.
.
.
(
x
n
,
y
n
)
{(x_1,y_1),(x_2,y_2),(x_3,y_3)...(x_n,y_n)}
(x1?,y1?),(x2?,y2?),(x3?,y3?)...(xn?,yn?)
假設我們已經知道了他們中存在兩個聚類,那么現在我們想要利用這一系列訓練樣本,訓練出一個能夠劃分的這兩個聚類的方法,使得接下來我們隨機輸入的點都能被正確的劃分聚類,可視化問題就是下面這一張圖:
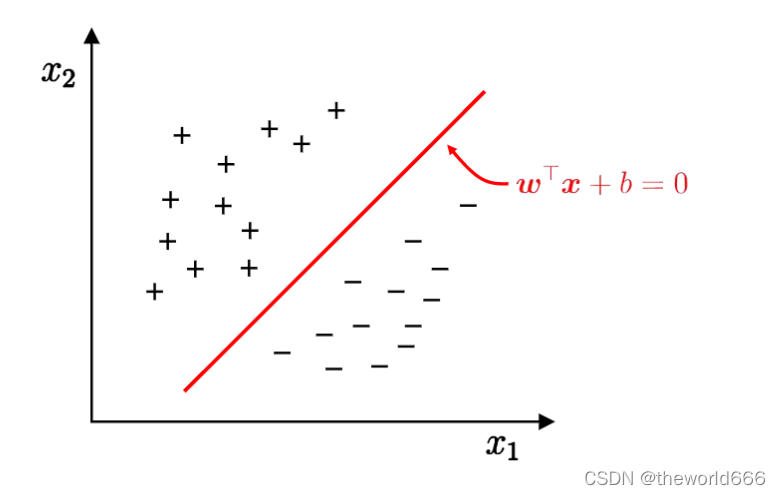
我們對此的目標就是尋找到出一個分割直線 wx + b =0,能夠正確劃分這兩個聚類(之后我們使用正樣本和負樣本來代稱),使用數學問題來表述就是尋找到出一系列點使得對于所有正樣本代入式子wx+b得到值為正,所有負樣本代入式子wx+b值為負,
當然這里又出現問題了,就是其實根據訓練資料樣本的不同我們可以找到這樣的分割向量其實理論上來說是可以無限種的(限制一段空間,我們依然能繪畫出無數條直線),那么選擇哪一條最好呢?
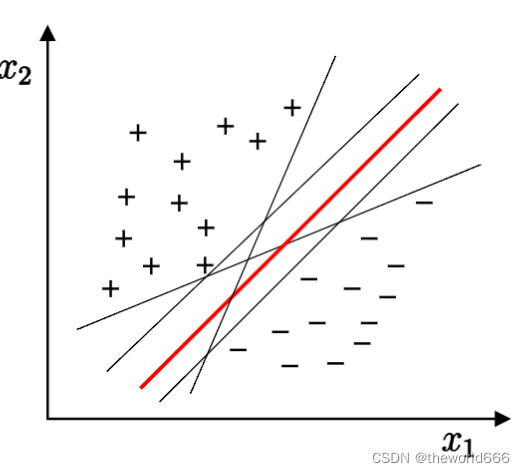
當然這里學者們依然給出了一個選擇分隔直線的方法,我們選擇能夠能夠使分隔間距最大的直線也就是圖中紅色這一條,為什么呢?因為我們生成出來的模型其實非常嚴重依賴當前訓練集的資料,如果我們不選擇間隔最大化的這條直線可能出現因為分隔平面與正樣本區域距離的不夠遠導致一些原本屬于負樣本的點卻被分類到負樣本去了,
那么通過這上面的敘述,我們的問題就轉化到下面這個問題上來了:

這些被圓圈圈住的點,我們就稱之為支持向量(support vector)根據我們的假設這些支持向量代入直線計算只有可能為1或-1這兩種值(至于如果你想了解為什么是1和-1而不是其他的數,這里推薦大家去看這位大佬的博客【機器學習演算法】支持向量機入門教程及相關數學推導_SESESssss的博客-CSDN博客 ,這里我就不詳細敘述了),那么我們現在就是要尋找出一個最大間隔,這里我們使用數學表示就是:
對
于
正
樣
本
,
負
樣
本
中
最
靠
近
分
隔
直
線
的
向
量
存
在
以
下
參
數
w
,
b
使
得
w
?
x
+
b
=
1
w
?
x
+
b
=
?
1
我
們
計
算
這
兩
條
直
線
到
直
線
w
?
x
+
b
=
0
的
距
離
計
算
可
得
:
γ
=
2
∥
w
∥
對于正樣本,負樣本中最靠近分隔直線的向量存在以下引數w,b使得\\ \boldsymbol{w}^{\top} \boldsymbol{x}+b=1 \\ \boldsymbol{w}^{\top} \boldsymbol{x}+b=-1\\ 我們計算這兩條直線到直線\boldsymbol{w}^{\top} \boldsymbol{x}+b=0 的距離計算可得:\\ \gamma=\frac{2}{\|\boldsymbol{w}\|}
對于正樣本,負樣本中最靠近分隔直線的向量存在以下參數w,b使得w?x+b=1w?x+b=?1我們計算這兩條直線到直線w?x+b=0的距離計算可得:γ=∥w∥2?
這里在計算的時候使用了點到直線距離的計算公式有疑問的同學可以百度一下補充知識偶😘😘,到這里我們支持向量的最終目標就很明顯了尋找到一個使得分隔最大的直線(對于高維的點是尋找分隔平面)來劃分正樣本和負樣本,而為了尋找到這樣的直線,我們其實并不需要利用所有樣本,只需要這些距離分隔平面最近的向量來計算即可,所以這也是SVM(support vector machine)支持向量機名字的由來,他并不跟一般機器學習方法依賴資料集中的所有點來決定,他實際上只依賴于部分支持向量從而構建分類器,
那么又到了扯公式的時候了,如何尋找到這樣的w,b呢?來讓我們繼續往下計算取:
arg
?
max
?
w
,
b
2
∥
w
∥
s.t.
y
i
(
w
?
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
.
\begin{aligned} \underset{\boldsymbol{w}, b}{\arg \max } & \frac{2}{\|\boldsymbol{w}\|} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m . \end{aligned}
w,bargmax? s.t. ?∥w∥2?yi?(w?xi?+b)≥1,i=1,2,…,m.?
這個式子不夠方便計算,為了計算方便我們進行轉換,求原始值倒數的最小值等同于求原始值的最大值,所以我們做如下轉換:
arg
?
min
?
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
?
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
\begin{aligned} \underset{w, b}{\arg \min } & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m \end{aligned}
w,bargmin? s.t. ?21?∥w∥2yi?(w?xi?+b)≥1,i=1,2,…,m?
式子展開到現在其實已經知道怎么解決很明顯了,相信如果是對學習過高等數學非常深刻的同學一定記得:舉個例子:
給定一個約束條件F(x,y,z) = 0需要求解f(x,y,z)的最大值的方法,使用拉格朗日乘子方法可以輕松解決這個問題:
設
方
程
為
f
(
x
,
y
,
z
)
+
α
F
(
x
,
y
,
z
)
=
0
然
后
分
別
對
x
,
y
,
z
,
α
求
導
即
可
以
確
定
當
取
得
極
值
時
x
,
y
,
z
的
值
設方程為 f(x,y,z) + α F(x,y,z)=0\\ 然后分別對x,y,z,α求導即可以確定當取得極值時x,y,z的值
設方程為f(x,y,z)+αF(x,y,z)=0然后分別對x,y,z,α求導即可以確定當取得極值時x,y,z的值
但是這里可能有同學又要問了?但是你這里約束條件是不等式啊?不是等式這也能直接使用拉格朗日乘子方法來求解嗎?那么接下來我們就來詳細探究在不等式情況下我們需要如何求解呢?(接下來涉及很多數學公式的推導,限于博主的知識水平不足,可能推導程序中存在一些錯誤,希望大家能夠在評論區指正😥😥😥
2. 如何求解SVM的相關變數
這里我們先來說明拉格朗日函式是否能解決不等式約束問題,其實拉格朗日函式原本的公式是:對于帶約束條件的優化問題,如果滿足以下形式,我們就可以使用拉格朗日函式進行轉化:
min
?
x
∈
R
n
f
(
x
)
s.t.
c
i
(
x
)
?
0
,
i
=
1
,
2
,
?
?
,
k
h
j
(
x
)
=
0
,
j
=
1
,
2
,
?
?
,
l
\begin{aligned} &\min _{x \in \mathbb{R}^{n}} f(x) \\ &\text { s.t. } \\ &\begin{array}{l} c_{i}(x) \leqslant 0, \quad i=1,2, \cdots, k \\ h_{j}(x)=0, \quad j=1,2, \cdots, l \end{array} \end{aligned}
?x∈Rnmin?f(x) s.t. ci?(x)?0,i=1,2,?,khj?(x)=0,j=1,2,?,l??
對于上面這個式子,我們就可以轉化為一個拉格朗日函式:
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
k
α
i
c
i
(
x
)
+
∑
j
=
1
l
β
j
h
j
(
x
)
L(x, \alpha, \beta)=f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x)
L(x,α,β)=f(x)+i=1∑k?αi?ci?(x)+j=1∑l?βj?hj?(x)
從而再進行求偏導聯立方程等一系列操作來進行x變數的求解,而我們的svm其實是沒有等式條件,所以我們可以把等式條件視為0=0,那么我們依然可以使用拉格朗日函式解決在不等式約束下的優化問題,
說明了能夠使用拉格朗日函式方法求解在不等式約束下的極值優化問題那么我們現在就來從頭到尾重新說明一下我們的求解變數步驟:
首先我們定義我們的問題如下
arg
?
min
?
w
,
b
1
2
∥
w
∥
2
s.t.
y
i
(
w
?
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
…
,
m
.
\begin{aligned} \underset{\boldsymbol{w}, b}{\arg \min } & \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } & y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) \geq 1, i=1,2, \ldots, m . \end{aligned}
w,bargmin? s.t. ?21?∥w∥2yi?(w?xi?+b)≥1,i=1,2,…,m.?
對此我們引入拉格朗日乘子使得式子如下:
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
?
∑
i
=
1
m
α
i
(
y
i
(
w
?
x
i
+
b
)
?
1
)
(
α
大
于
等
于
0
)
L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2}\|\boldsymbol{w}\|^{2}-\sum_{i=1}^{m} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right)-1\right) ({\alpha}大于等于0)
L(w,b,α)=21?∥w∥2?i=1∑m?αi?(yi?(w?xi?+b)?1)(α大于等于0)
然后我們令函式L(w,b,α)對w和b的偏導為0,即可計算出最終的結果,但是這樣的計算仍然是十分復雜的,所以我們這里使用一點小技巧將我們要計算出的最小結果(證明程序可以查看:不簡單的SVM - 知乎 (zhihu.com))轉化為:
min
?
w
,
b
1
2
w
T
w
=
min
?
w
,
b
max
?
α
L
(
w
,
b
,
α
)
=
max
?
α
min
?
w
,
b
L
(
w
,
b
,
α
)
\min _{w, b} \frac{1}{2} w^{T} w=\min _{w, b} \max _{\alpha} L(w, b, \alpha)=\max _{\alpha} \min _{w, b} L(w, b, \alpha)
w,bmin?21?wTw=w,bmin?αmax?L(w,b,α)=αmax?w,bmin?L(w,b,α)
也就是說我們最終求解w,b需要拉格朗日函式L的參與,那么我們接下來就直接在這個前提下進行推導,對于函式L我們令他對w,b的偏導都能為0得:
w
=
∑
i
=
1
m
α
i
y
i
x
i
,
∑
i
=
1
m
α
i
y
i
=
0
\boldsymbol{w}=\sum_{i=1}^{m} \alpha_{i} y_{i} \boldsymbol{x}_{i}, \quad \sum_{i=1}^{m} \alpha_{i} y_{i}=0
w=i=1∑m?αi?yi?xi?,i=1∑m?αi?yi?=0
將這樣求解出來的公式代入原式可得:
min
?
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
?
x
j
?
∑
i
=
1
m
α
i
s.t.
∑
i
=
1
m
α
i
y
i
=
0
,
α
i
≥
0
,
i
=
1
,
2
,
…
,
m
.
\begin{array}{ll} \min _{\alpha} & \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\top} \boldsymbol{x}_{j}-\sum_{i=1}^{m} \alpha_{i} \\ \text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0, \alpha_{i} \geq 0, i=1,2, \ldots, m . \end{array}
minα? s.t. ?21?∑i=1m?∑j=1m?αi?αj?yi?yj?xi??xj??∑i=1m?αi?∑i=1m?αi?yi?=0,αi?≥0,i=1,2,…,m.?
而這個就是我們支持向量機的基本形式,我們利用這個來求的使當前函式取得最小值時的α值,然后再利用上面求導朱來的公式求得我們的w值,
那么介紹完了這么多公式相信大家也昏昏欲睡了吧😂😂,那么我們接下來實戰一下,在影像分類資料集上來嘗試我們利用支持向量機svm的分類效果,
3.資料集介紹
SVM對于二分類問題有著非常好的效果,所以我們這里也使用一個非常著名的二分類資料集貓狗分類資料集,該資料集含有上萬張的貓狗影像,他被經常使用于影像分類模型的測驗和各式各樣分類方法的測驗,(依稀記得兩年前被學長用貓狗分類資料集考核人工智能協會期末考試的噩夢時光)關于他的詳細介紹和如何轉化為向量,我在我之前的博客中有詳細的介紹過(機器學習03:使用logistic回歸方法解決貓狗分類問題_theworld666的博客-CSDN博客),這里就不再詳細介紹了,


4. 資料集處理
對于該資料集處理,為了加快速度我們這里會統一的將影像縮小為(64,64)的大小,同時也是為了方便處理,我們統一將貓狗標簽使用-1,1進行劃分:
import numpy as np
import random
import cv2
import glob
def path_to_data(all_img_path): #回圈讀取所有圖片的路徑
train_set = []
for path in all_img_path:
img = cv2.imread(path) #讀取圖片
mat = np.array(cv2.resize(img,(64,64))) #將圖片大小調整為64*64
mat = mat/255 #影像像素值為0-255使用這樣的方法歸一化資料使得計算速度更快
train_set.append(mat.flatten())#使用ndarray自帶的flatten方法進行壓平
return train_set #回傳存盤所有像素資料的矩陣
if '__name__' == '__main__':
train_image_path = glob.glob("test/*.jpg")
# 使用串列推導式獲得滿足條件的圖片
train_cat_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "cat"]
train_dog_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "dog"]
# 準備測驗集資料,為了分類均勻貓和狗的影像選取一樣多的資料量
test_dog_path = train_cat_path[500:650]
test_cat_path = train_cat_path[500:650]
test_cat_path.extend(test_dog_path)
test_label = [s.split('\\')[-1].split('.')[0] for s in test_cat_path]
test_data = path_to_data(test_cat_path)
label_to_index = {'dog': -1, 'cat': 1} # 標簽替換字典
test_labels_nums = [label_to_index.get(l) for l in test_label] # 將貓和狗標簽使用數字表示
#####準備訓練集資料
train_cat_path = train_cat_path[:500]
train_dog_path = train_dog_path[:500]
train_cat_path.extend(train_dog_path)
train_image_path = train_cat_path
random.shuffle(train_image_path) ##訓練集打亂資料加強訓練模型泛化能力
train_label = [s.split('\\')[-1].split('.')[0] for s in train_image_path]
train_labels_nums = [label_to_index.get(l) for l in train_label]
dataArr = path_to_data(train_image_path)
在我們對測驗集和訓練集選擇中,訓練集抽取1000張圖,測驗集300張圖片,其中訓練集和測驗集圖片中的貓狗圖片數量是一樣多的,那么資料準備好了接下來我們就直接上硬菜:使用SVM代碼解決影像分類問題并統計平均錯誤率,
5.使用SVM解決影像分類問題并統計平均錯誤率
def testRbf(dataArr, labelArr, testDataArr,testLabelArr,k1=1.3):
# 加載訓練集
# dataArr, testDataArr, labelArr, testLabelArr = loadCSVfile2()
# 根據訓練集計算b, alphas
print(np.shape(dataArr))
print(np.shape(labelArr))
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 100, ('rbf', k1))
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
# 獲得支持向量
svInd = np.nonzero(alphas.A > 0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
print("支持向量個數:%d" % np.shape(sVs)[0])
m, n = np.shape(datMat)
errorCount = 0
for i in range(m):
# 計算各個點的核
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
# 根據支持向量的點計算超平面,回傳預測結果
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
# 回傳陣列中各元素的正負號,用1和-1表示,并統計錯誤個數
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
# 列印錯誤率
print('訓練集錯誤率:%.2f%%' % ((float(errorCount) / m) * 100))
# showDataSet(dataArr, labelMat)
# 加載測驗集
dataArr = testDataArr
labelArr = testLabelArr
errorCount = 0
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
m, n = np.shape(datMat)
for i in range(m):
# 計算各個點的核
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
# 根據支持向量的點計算超平面,回傳預測結果
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
# 回傳陣列中各元素的正負號,用1和-1表示,并統計錯誤個數
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
# 列印錯誤率
print('測驗集錯誤率:%.2f%%' % ((float(errorCount) / m) * 100))
return (float(errorCount) / m) #回傳錯誤率吧
if __name__ == '__main__':
train_image_path = glob.glob("dc/train/*.jpg")
print(train_image_path[:10])
# 使用串列推導式獲得滿足條件的圖片
train_cat_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "cat"]
train_dog_path = [s for s in train_image_path if s.split('\\')[-1].split('.')[0] == "dog"]
# 準備測驗集資料,為了分類均勻貓和狗的影像選取一樣多的資料量
test_dog_path = train_cat_path[500:650]
test_cat_path = train_cat_path[500:650]
test_cat_path.extend(test_dog_path)
test_label = [s.split('\\')[-1].split('.')[0] for s in test_cat_path]
test_data = path_to_data(test_cat_path)
label_to_index = {'dog': -1, 'cat': 1} # 標簽替換字典
test_labels_nums = [label_to_index.get(l) for l in test_label] # 將貓和狗標簽使用數字表示
#####準備訓練集資料
train_cat_path = train_cat_path[:500]
train_dog_path = train_dog_path[:500]
train_cat_path.extend(train_dog_path)
train_image_path = train_cat_path
random.shuffle(train_image_path) ##訓練集打亂資料加強訓練模型泛化能力
train_label = [s.split('\\')[-1].split('.')[0] for s in train_image_path]
train_labels_nums = [label_to_index.get(l) for l in train_label]
dataArr = path_to_data(train_image_path)
errornum=0
for i in range(10):
errornum+= testRbf(dataArr,np.mat(train_labels_nums),test_data,np.mat(test_labels_nums))
print("平均錯誤率是%.2f"%(errornum/10))
這里由于參考機器學習實戰撰寫的SVM代碼實在篇幅太長,所以就不放在博客里了,大家如果需要的話可以上Github下載即可😋😋😋😋,liujiawen-jpg/SVM: 使用支持向量機來解決貓狗分類問題 (github.com)
最終我們運行平均錯誤率吧達到了百分之二十五:

甚至達到了百分之1可以發現我們的效果還是非常不錯的(這里博主多次運行發現實際上svm對于該資料集的隨機性很強)所以建議大家每次訓練完成后都使用numpy保存變數值,最后取最好的變數值即可,
結語
在本篇博客中,我們完成了對于SVM演算法原理的簡要闡釋,以及如何使用SVM來解決一般影像二分類問題,當然由于本人水平有限對于SVM原理的闡述沒有十分完全,有差錯大家可以在評論區指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395013.html
標籤:AI
上一篇:不用等微信官方!微信圣誕帽,我用Python就能搞定!
下一篇:自學Seurat的一點記錄