1. 演算法思想
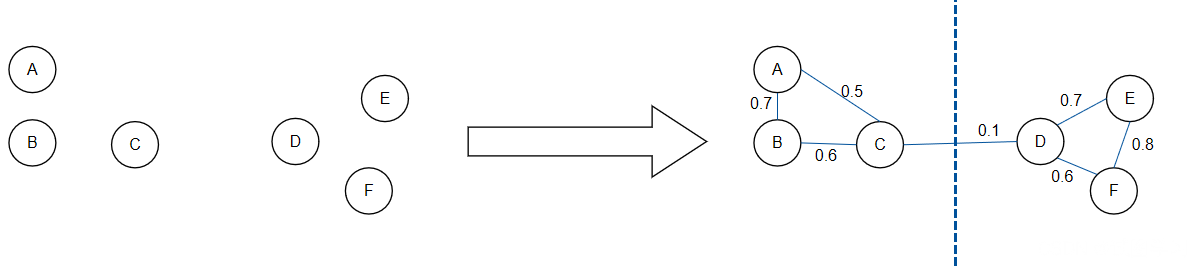
- 將所有的資料看成空間中的點,這些點之間可以用邊連接起來,距離較遠的點之間邊的權重低,距離較近的點間邊的權重高,然后對原圖進行切圖,使得不同子圖間邊的權重之和盡可能低,子圖內邊的權重之和盡可能高,迭代的洗掉最長的邊,從而達到聚類的目的(如下圖),
- 簡而言之,譜聚類先降維(特征分解),然后在低維空間用其它聚類演算法(如KMeans、模糊聚類)進行聚類,
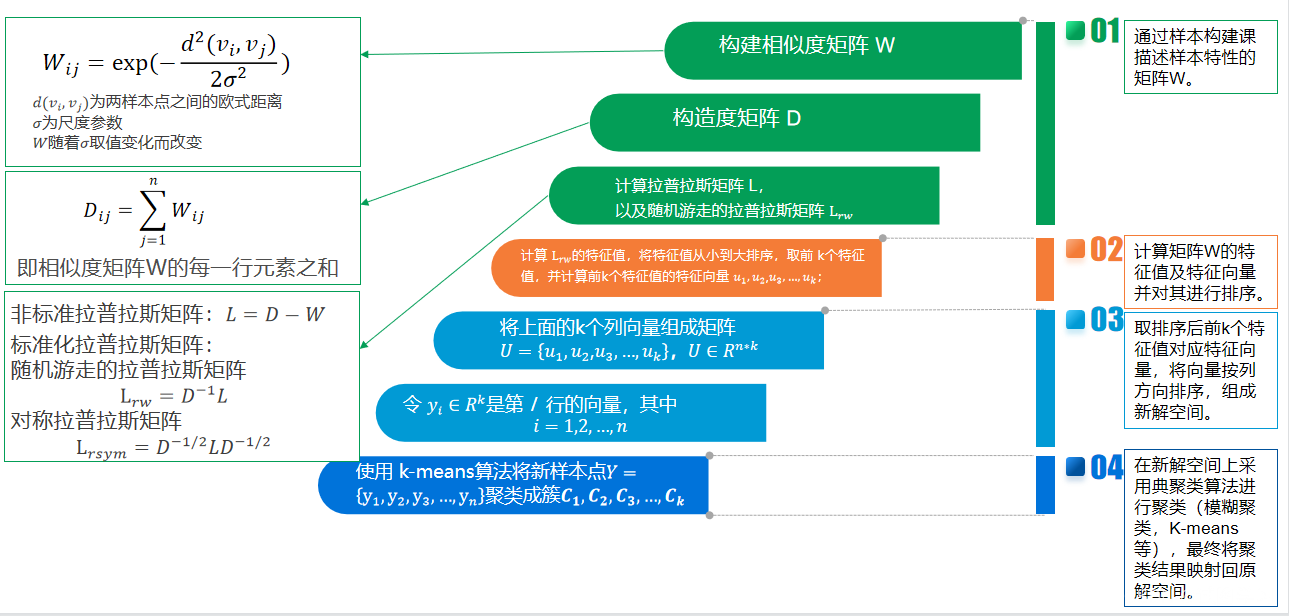
2. 演算法流程
- 輸入:樣本集D=(x1,x2,…,xn),相似矩陣的生成方式, 降維后的維度k1, 聚類方法,聚類后的維度k2
- 輸出:簇劃分C(c1,c2,…ck2).
(1)構建相似度矩陣(鄰接矩陣)W
(2)構建度矩陣D
(3)計算拉普拉斯矩陣L、標準化后的拉普拉斯矩陣Lrm
(4)特征分解:計算Lrm最小的k1個特征值所各自對應的特征向量
(5)將各自對應的特征向量組成的矩陣按行標準化,最終組成n×k1維的特征矩陣
(6)對每一行作為一個k1維的樣本,用輸入的聚類方法進行聚類,聚類維數為k2,
(7)得到簇劃分C(c1,c2,…ck2).
對于輸入中提及的相似矩陣的生成方式, 說明如下:
(為什么單獨說名這一點,見后文缺點分析)
- 相似矩陣的生成方式
(1)?-近鄰法
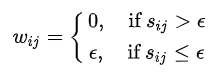
(2)k-近鄰法(本文實驗所用)
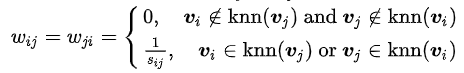
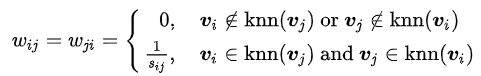
(3)全連接法
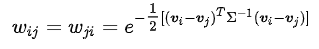
3. 實體展示
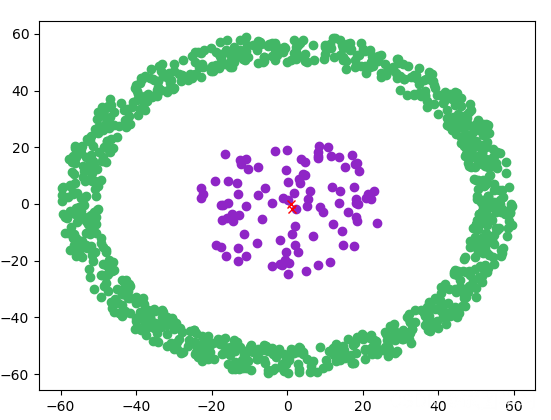
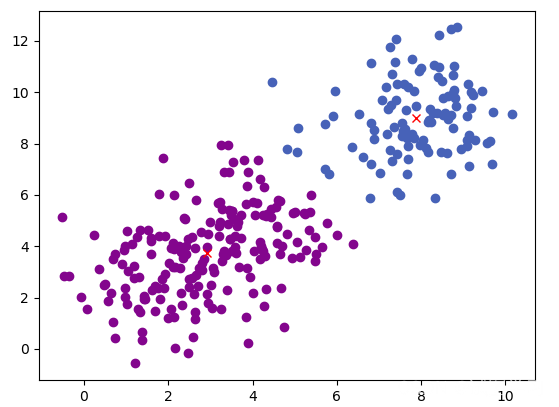
- 資料集:ringData.mat、GaussianData.mat
(以下僅展示能說明流程部分的核心代碼,如需要完整版含資料集請聯系作者) - 實作:
if __name__ == '__main__':
cluster_num = 2 #聚類個數
KNN_k = 5 #計算鄰接矩陣W會用到
data = loaddata() #讀取資料
W = getWbyKNN(data,KNN_k) #相似矩陣
D = getD(W) #度矩陣
L = D-W #拉普拉斯矩陣
Lrm = (np.matrix(D))*L #標準化拉普拉斯矩陣
eigval,eigvec = getEigVec(L,cluster_num) #特征值、特征向量
print(eigval,eigvec)
clf = KMeans(n_clusters=cluster_num) #KMeans聚類
s = clf.fit(eigvec)
C = s.labels_
centers = getCenters(data,C) #聚類中心
plot(data,s.labels_,centers,cluster_num)
- 聚類效果
4. 優缺點
- 回憶:譜聚類可以理解為先降維,再聚類,
- 優點:
(1)無需事先指定簇的數量(但如果采用kmeans進行聚類,需要指明簇的個數,正如我們下邊的實體那里,手動選擇簇數為2),當聚類的類別個數較小的時候,譜聚類的效果會很好;
(2)譜聚類演算法使用了降維的技術,所以更加適用于高維資料的聚類;
(3)譜聚類只需要資料之間的相似度矩陣(鄰接矩陣),因此對于處理稀疏資料的聚類很有效,
(4)與傳統的聚類演算法相比,它具有能在任意形狀的樣本空間上聚類且收斂于全域最優解 - 缺點:
(1)譜聚類對相似矩陣的改變和聚類引數的選擇非常的敏感;
(2)譜聚類適用于均衡分類問題,對于簇之間點個數相差懸殊的聚類問題,譜聚類則不適用;
(3)時間和空間復雜度大,
小結:
- 譜聚類的演算法原理的確簡單,代碼實作比較容易,但是要完全理解,需要對圖論中的無向圖,線性代數和矩陣分析都有一定的了解,更多細節推導見參考,
參考:
劉建平博客園
b站白板推導
譜聚類–無需指明簇數量的聚類
sklearn譜聚類Spectral Clustering引數及演算法原理
Graph特征提取方法–譜聚類
譜聚類拉普拉斯降維
深入淺出地搞懂譜聚類
譜聚類python實作
A Tutorial on Spectral Clustering
聚類演算法總結
KNN和K-Means
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395020.html
標籤:AI
上一篇:Matplotlib可視化散點圖、配置X軸為對數坐標、并使用線條(line)連接散點圖中的資料點(Simple Line Plot with Data points in Matplotlib)
下一篇:R語言基于可視化進行多變數離群(Mulltivariate outliers)點檢測識別:散點圖可視化多變數離群點、模型平滑多變數例外檢測、使用平行坐標圖查看鉆石資料集中的例外值