參考大佬文章,收益匪淺
實驗目的
- 掌握AES演算法能量跡構造;
- 掌握AES演算法CPA攻擊基本原理,
實驗人數
每組1人
系統環境
Windows
實驗原理
CPA是利用密碼芯片的假設模型,預測其加解密時的功耗大小,然后和實際測量的功耗大小進行相關性分析推測密鑰,CPA攻擊通常采用漢明重量模型,所謂漢明權重就是一個碼字中1碼元的總數目,漢明權重越大,芯片運算時的功耗就越大,
實驗內容
-
Readfile-student.py:AES 能耗波形檔案讀入與存盤,“Save2Npy”函式輸出能量跡trace資料,
- 分析程式讀入的pts、pcts、pns分別是什么資料,型別是什么,維數是多少
-
CPA-student.py:根據漢明重量模型恢復16個位元組密鑰,
- 補充相關系數的計算代碼,并取最大值記為maxcpa
- 解釋每個生成影像的含義(橫縱坐標、波形、尖峰等)
- 列印輸出恢復的所有正確密鑰bestguess
-
分析能量跡對密鑰恢復的影響:10、50、100、150、200、240條能量跡能夠恢復的正確密鑰的位元組數和位置分別是什么,并分析其原因,
實驗步驟
pts、pcts、pns分別是什么資料、型別、維數
pts

資料:明文
型別:陣列
維數:二維(250,16)
pcts

資料:明文,密文
型別:陣列
維數:三維(250,2,16)
pns

資料:能量跡縱坐標
型別:陣列
維數:二維(250,10000)
完善相關系數的計算代碼
hwlist = np.zeros(numtraces)陳述句之前的代碼是程式自帶的,最外層的for回圈的目的是遍歷密鑰的位元組位置,第二層的for回圈是遍歷所有密鑰的可能性,本次實驗需要使用能量跡的明文和密鑰異或運算并執行后續代碼,所以還需要設定一層回圈,使得對應設定數量的能量跡明文可以和密鑰進行運算,求得漢明重量,代碼如下,
hwlist = np.zeros(numtraces) #初始化陣列
for tnum in range(0, numtraces):
hwlist[tnum] = HW[intermediate(pt[tnum][bnum], kguess)]
注意一點pt二維陣列(程式另有設定明文陣列為pt)的取值,pts明文陣列中250表示明文數量,而16是明文的size,所以明文陣列長度為16,
因為是漢明重量模型,按照以往實驗的思路,下一步是根據相關系數計算公式
r
i
,
j
=
∑
d
=
1
D
[
(
h
d
,
i
?
h
i
 ̄
)
(
t
d
,
j
?
t
j
 ̄
)
]
∑
d
=
1
D
(
h
d
,
i
?
h
i
 ̄
)
2
∑
d
=
1
D
(
t
d
,
j
?
t
j
 ̄
)
2
{r_{i,j}} = \frac{{\sum\nolimits_{d = 1}^D {\left[ {\left( {{h_{d,i}} - \overline {{h_i}} } \right)\left( {{t_{d,j}} - \overline {{t_j}} } \right)} \right]} }}{{\sqrt {\sum\nolimits_{d = 1}^D {{{\left( {{h_{d,i}} - \overline {{h_i}} } \right)}^2}} \sum\nolimits_{d = 1}^D {{{\left( {{t_{d,j}} - \overline {{t_j}} } \right)}^2}} } }}
ri,j?=∑d=1D?(hd,i??hi??)2∑d=1D?(td,j??tj??)2
?∑d=1D?[(hd,i??hi??)(td,j??tj??)]?
推匯出邏輯代碼,
這部分代碼我之前有寫過,不過那時公式邏輯代碼組成的函式輸入物件雖然也是陣列(準確來說應該說是串列),但是體量沒有這次仿真實驗做的大,而且numpy函式生成的陣列在型別上就和串列就不一樣,所以代碼需要重新撰寫,為了代碼流程顯得模塊化,我將上述計算公式模塊化如下:
r
i
,
j
=
m
o
l
e
s
u
m
d
e
n
s
u
m
1
×
d
e
n
s
u
m
2
{r_{i,j}} = \frac{molesum}{\sqrt{densum1 \times densum2}}
ri,j?=densum1×densum2
?molesum?
-
第一步依舊是是初始化,只不過是陣列的初始化;
# 初始化陣列——簡化計算流程 molesum = np.zeros(numpoint) densum1 = np.zeros(numpoint) densum2 = np.zeros(numpoint) -
第二步理論上來說可以直接運算了,不過先計算平均值可以減少代碼冗余,分別計算假設值和軌跡上所有點的漢明重量的平均值,
#當前猜測密鑰參與運算的漢明總量陣列均值 h_mean = np.mean(hwlist, dtype=np.float64) #采集線上的電壓均值,共1000份 t_mean = np.mean(traces, axis=0, dtype=np.float64) -
第三步開始正式計算,累加次數取決于使用的能量跡數量,計算結束后將相關系數的最大絕對值存入maxcpa串列中,
for i in range(0, numtraces): h = (hwlist[i] - h_mean) t = traces[i] - t_mean molesum = molesum + (h * t) densum1 = densum1 + h * h densum2 = densum2 + t * t maxcpa[kguess] = max(abs(molesum / np.sqrt(densum1 * densum2)))可能陌生的地方就是第三行的t值,其實t在這里是個陣列,這一行的代碼運算也是陣列之間的運算,
圖6.5 一維陣列t 
圖6.5 二維陣列traces 第三行代碼還可以替換為
t = traces[i,:] - t_mean -
將256種密鑰遍歷測驗后,將maxcpa串列中的最大值儲存,作為所猜測的當前密鑰位元組數值,
bestguess[bnum] = np.argmax(maxcpa)
完整代碼如下(列印陳述句不放):
for bnum in range(0, 16):#bnum定義所攻擊的位元組位置
maxcpa = [0]*256#記錄cpa最大值的向量
for kguess in range(0, 256):
#補充相關系數的計算代碼,并取最大值記為maxcpa
#計算猜測密鑰參與運算形成的漢明重量
hwlist = np.zeros(numtraces) #初始化陣列
for tnum in range(0, numtraces):
hwlist[tnum] = HW[intermediate(pt[tnum][bnum], kguess)]
# 根據相關系數計算公式推匯出邏輯代碼
# 初始化陣列——簡化計算流程
molesum = np.zeros(numpoint)
densum1 = np.zeros(numpoint)
densum2 = np.zeros(numpoint)
#當前猜測密鑰參與運算的漢明總量陣列均值
h_mean = np.mean(hwlist, dtype=np.float64)
#采集線上的電壓均值,共1000份
t_mean = np.mean(traces, axis=0, dtype=np.float64)
#正式計算
for i in range(0, numtraces):
h = (hwlist[i] - h_mean)
t = traces[i] - t_mean
molesum = molesum + (h * t)
densum1 = densum1 + h * h
densum2 = densum2 + t * t
maxcpa[kguess] = max(abs(molesum / np.sqrt(densum1 * densum2)))
bestguess[bnum] = np.argmax(maxcpa)
程式運行結果
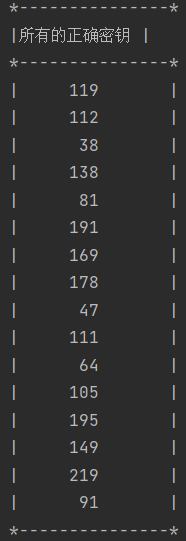
正確密鑰bestguess列印輸出如下(使用能量跡為250條):
生成影像如下:
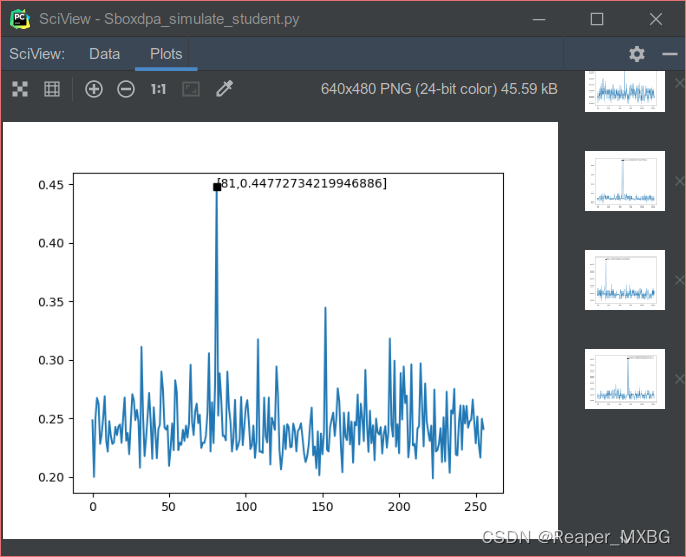
分析影像的含義
以此圖為例:
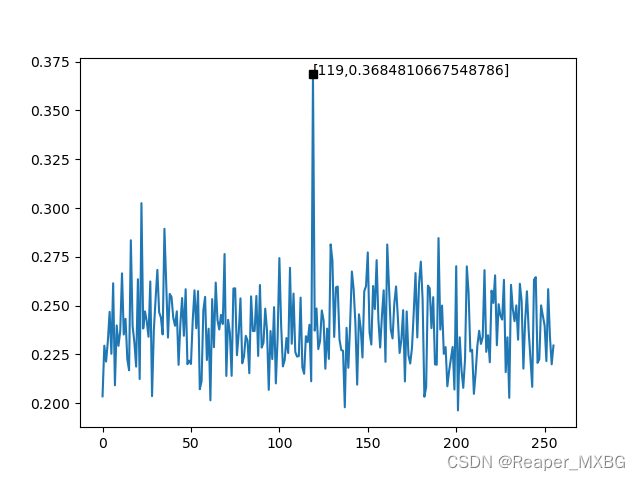
橫坐標:所有可能的密鑰
縱坐標:相關系數絕對值
波形:波形可以反映演算法的處理周期和處理速度
尖峰:在此實驗中,尖峰代表著猜測密鑰和正確結果的相關性,尖峰值越大,相關性越高
分析能量跡對密鑰恢復的影響
分別采用10、50、100、150、200、240條能量跡,
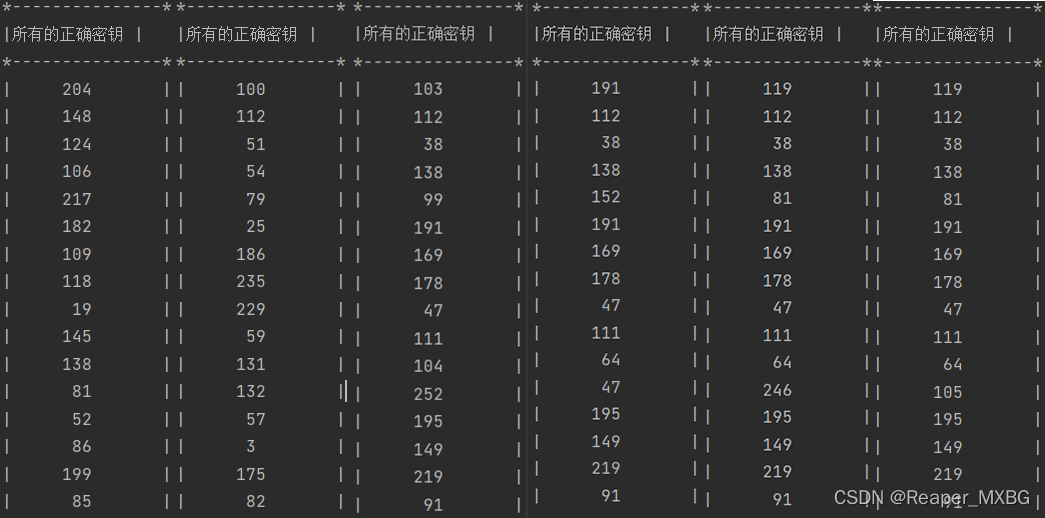
以250條能量跡的正確密鑰輸出為正確標準,對此六種情況下的正確密鑰輸出進行判定,結果如下,
| 能量跡條數 | 恢復正確密鑰位元組數 | 正確密鑰位置(0起始) |
|---|---|---|
| 10 | 0 | 無 |
| 50 | 1 | 1 |
| 100 | 12 | 1,2,3,5,6,7,8,9,12,13,14,15 |
| 150 | 14 | 0,1,2,3,4,5,6,7,8,9,10,12,13,14,15 |
| 200 | 15 | 0,1,2,3,4,5,6,7,8,9,10,12,13,14,15 |
| 240 | 16 | 全部 |
原因簡單來說就是,參考基礎不夠大,無法生成普適規律,參考基數越大,個例對整體判斷的影響越小;反之,越大,
思考問題
如果利用位元模型和漢明距離模型,應該如何進行攻擊?
漢明距離模型
計算數字電路在某個特定時段內,0→1轉換和1-→0轉換的總數,然后,利用轉換的總數來刻畫電路在該時段內的能量消耗,把對整個電路的仿真劃分為小的時間段,就可以生成一-種能量跡,這種能量跡中不包含具體的電壓值,而是包含每個時間段內電路發生轉換的次數,
位元模型
攻擊者通過側信道可以得到密碼演算法中間狀態的某個位元,將該側信道泄露的訊息與立方攻擊相結合從而恢復密鑰資訊,
總結
識訓之一就是明白了在給定能量跡資料集的條件下,如何進行仿真實驗,
之前的仿真實驗都是基于白盒的仿真實驗,S盒的運算公式和盒內部數值都是公開的,所以相對容易,這次實驗比之前的實驗從更正規的方式去做了一遍仿真實驗,看到仿真能量跡畫出來的時候還是很激動的,
代碼邏輯上我覺得重點要理解的就是“兩層回圈嵌套”,即最外層的密鑰16位元組回圈 + 遍歷密鑰回圈,至于剩下的都是小回圈而已,不對整體結構上產生影響,
還有要理解能量跡資料的各個屬性,雖然在代碼中能量跡資料看起來很輕松的就被呼叫使用,但是難點是在將能量跡資料從檔案中提取出來時知道其中是什么資料,怎么用,何時用,
還有關于求平均值的理解,多條明文的前提下,平均值是縱向求,不論漢明重量還是電壓值,千萬不要橫向求平均值,比如求10000個電壓值的平均值,這是錯誤的思想,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395039.html
標籤:其他
上一篇:Sublist3r 報錯處理