第十二章 CPU結構和功能
1、處理器內部結構,了解就行
2、暫存器組織,暫存器分類、用戶可見和控制狀態暫存器,通用暫存器能存什么,資料和地址暫存器是否區分,長度如何確定,條件代碼用來干什么,存在哪里
3、控制和狀態暫存器了解就行
4、指令周期,包括哪幾個部分,子周期關系,前后關系,哪些必須,哪些可能
5、流水線
為什么要采用流水線,流水策略有哪些,分段,?? 指令流水操作時序圖
哪些因素影響流水線性能、流水線性能衡量標準:加速比與吞吐量要掌握
5、指令流水線處理條件轉移指令的幾種方式
12.1 CPU組成
CPU執行指令的步驟:
取指令
解釋指令
取資料
處理資料
寫資料
為了執行指令,CPU必須包括ALU和CU,同時,CPU需要臨時存盤一些資料,包括下一條指令的位置,因此,CPU需要一個小的內部記憶體——暫存器
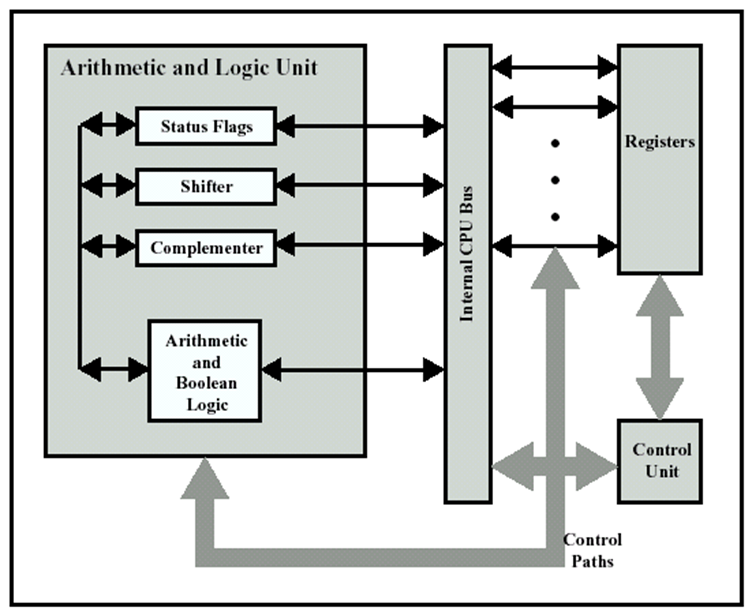
12.2 暫存器組織
暫存器:CPU中用于暫存的一小塊作業空間(I/O中也有)
是CPU設計需要考慮的一個重要因素
1?? 用戶可見暫存器User-visible registers
允許機器語言或匯編語言的編程人員通過優化暫存器的使用而減少對主存的訪問
2?? 控制和狀態暫存器Control and status registers
由控制器來控制CPU的操作,并由擁有特權的作業系統來控制程式的執行
用戶可見暫存器
通用目的暫存器general purpose register
也許真的是通用的
可能是受限制的
可能有用于浮點和堆疊操作的專用暫存器
可用于資料或尋址
資料暫存器
累加器
地址暫存器
段指標、堆疊指標
條件碼暫存器
由CPU硬體設定的位,作為最后一次操作的結果
COAPZS
正,負,零,溢位,等等,
在存盤最后一個操作的結果之后,還會設定一個條件代碼,這個代碼可以用于條件分支
可以被程式隱式地讀取、通常不能被程式設定
對程式員部分可見
采用更多的通用暫存器/專用暫存器?
1?? 采用更多的通用暫存器
增加靈活性,給程式員提供了更大的自由,尋址方式也可以更豐富
增加指令的長度和復雜度
2?? 采用更多地專用暫存器
更短的指令
靈活性變差
控制和狀態暫存器
程式暫存器PC:存有待取指令地地址
指令暫存器IR:存有最近取來的指令
存盤器地址暫存器MAR:存有存盤器位置的地址
存盤緩沖暫存器MBR:存有將被寫入存盤器的資料字或最近被存盤器讀出的字
很多CPU設計都包括程式狀態字PSW的一個或一組暫存器,一般含有條件碼和其他狀態資訊,大多對程式員不可見
符號sign
進位carry
等于equal
溢位overflow
中斷允許\禁止
監管supervisor(CPU處在監管模式還是用戶模式)
子程式呼叫,不需要保存現場,就是一段代碼的替換
設計控制暫存器時要考慮兩個因素
1?? 作業系統支持
CPU設計與作業系統設計是緊密聯系在一起的,二者應該相互配合
2?? 控制資訊分配在記憶體和暫存器
控制資訊也可以存盤在主存的前幾百個字中,設計者必須決定有多少在暫存器中,有多少在記憶體中
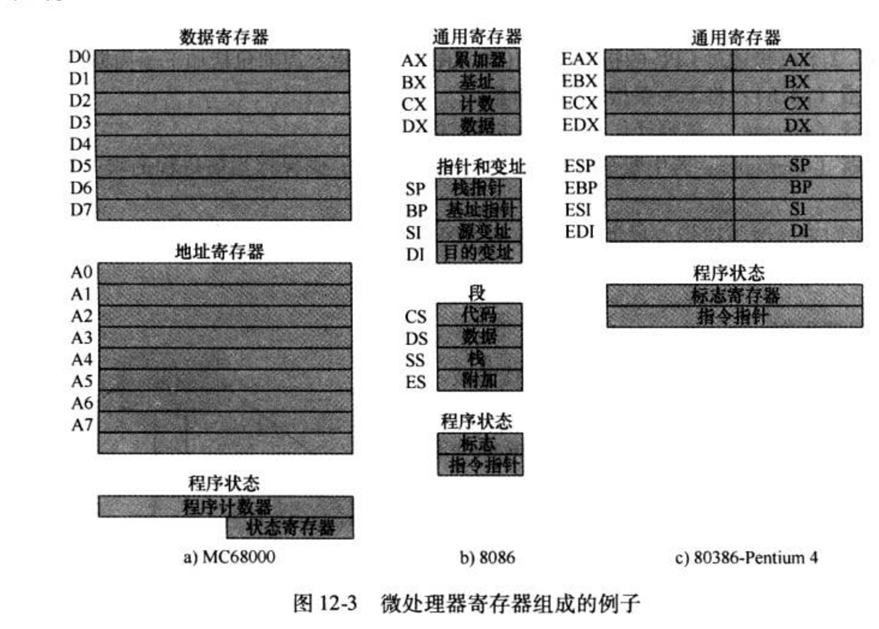
微處理器暫存器舉例
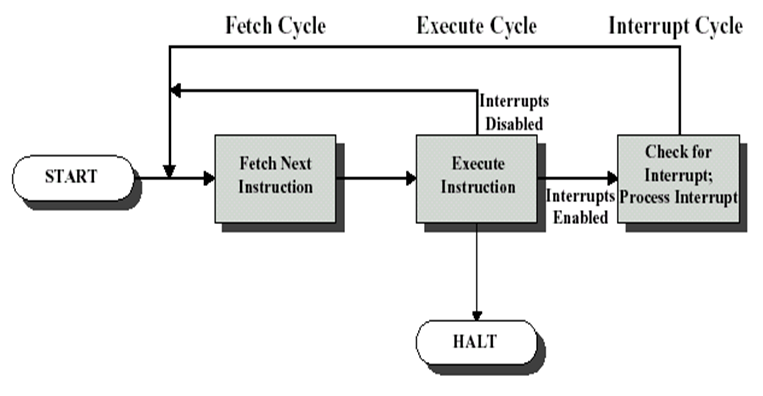
12.3 指令周期
間接尋址周期
可能需要記憶體訪問才能獲取操作
間接處理需要更多的記憶體訪問
可視為附加指令子周期
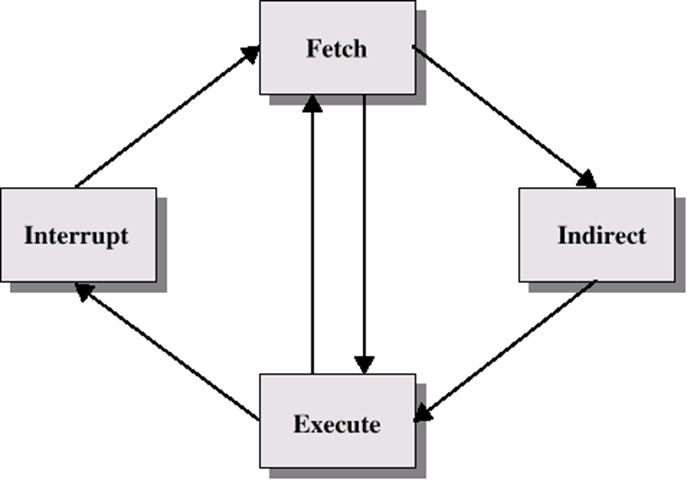
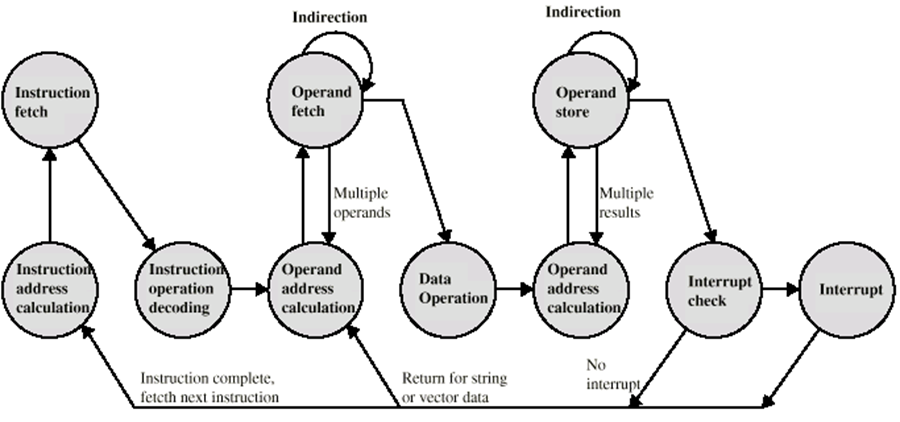
一旦取來一個指令,它的運算元指定符必須被識別,然后讀取存盤器中的每個運算元,這個程序可能要求間接尋址,暫存器運算元不需要從存盤器讀取,一旦操作完成,可能需要一個類似的程序將結果存入主存,
資料流
假定一個CPU中有一個MAR、一個MBR、一個PC、一個IR
取指周期
PC存有待取的下一條指令的地址
地址被送到MAR
地址放在地址總線中
控制器發出一個存盤器讀的請求
存盤器將結果放在資料總線中,CPU將其復制到MBR,然后傳送到IR
同時,PC+1
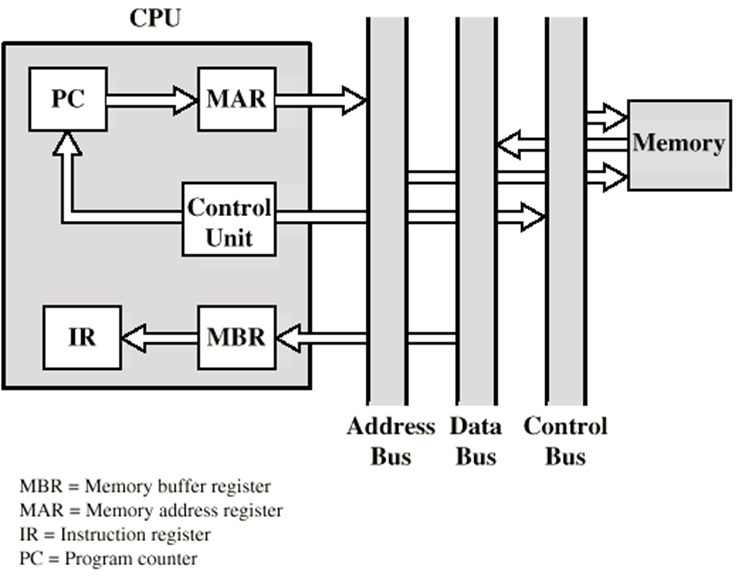
一旦經歷過取指周期,控制器會檢查IR中的內容
間接周期
一旦經歷取指周期,檢查器檢查IR的內容,確定是否有一個使用間接尋址的運算元指定符,若是則進入間接周期
MBR最右邊的N位是一個地址參考,被送入MAR
控制器發一個存盤器讀,得到運算元地址
送入MBR
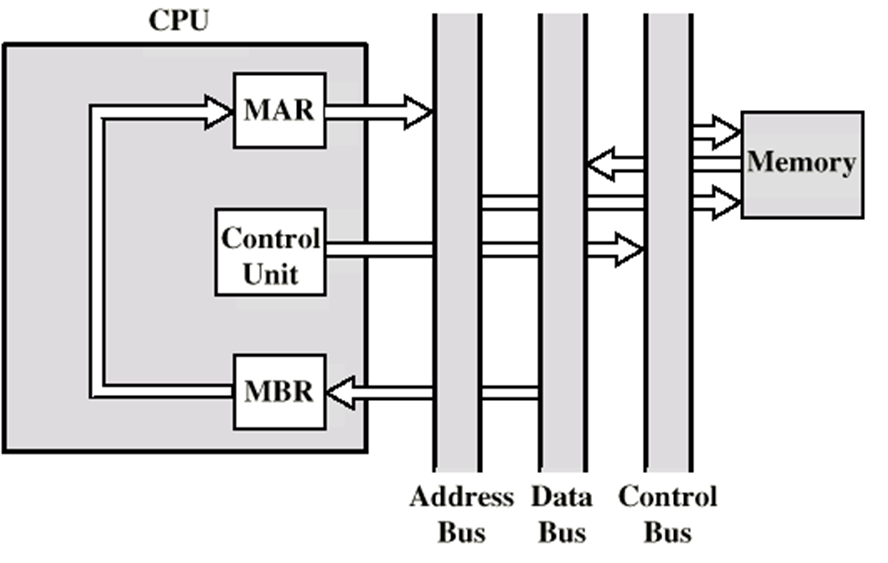
執行周期
沒有固定地形式,取決于實際執行的指令
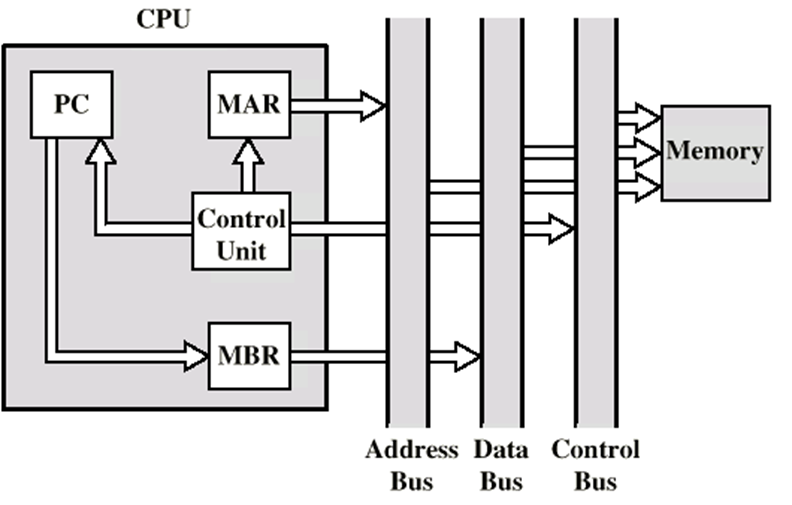
中斷周期
PC的當前的內容被保存,以便在中斷之后CPU能恢復先前的動作
PC的內容被送到MBR,寫入存盤器
一個專門的存盤器位置被控制器裝入MAR(可能是一個堆疊指標)
中斷子程式的地址裝入PC
可獲取下一個指令(中斷處理程式的第一個指令)
12.4 指令流水線(重點)
指令預取
可以將指令處理分為兩個階段:取指令和執行指令,在指令執行程序中,主存可能沒有存取操作,可以在解碼和執行當前指令時獲取下一個指令,
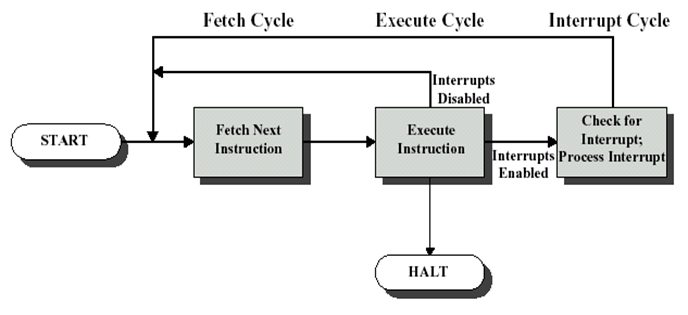
這種方式需要指令快取,需要更多的暫存器
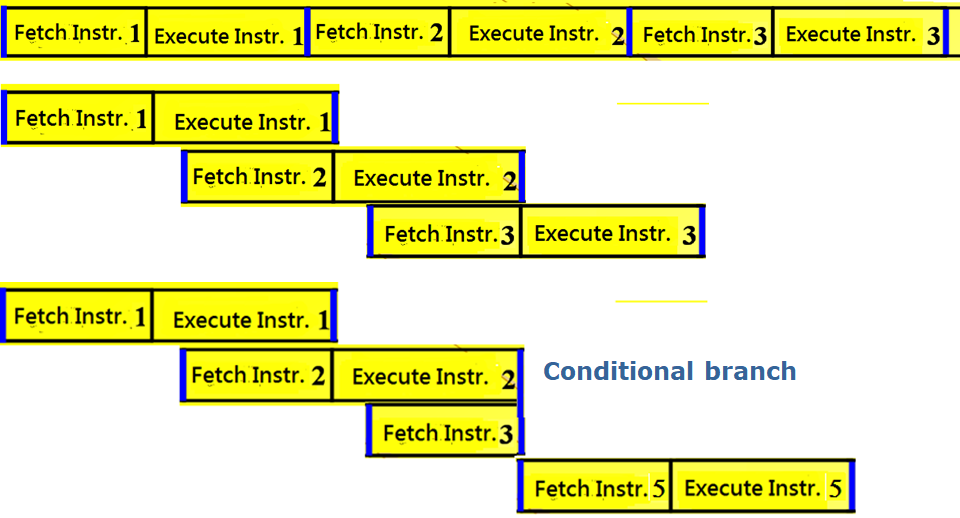
預取可以提速,但是速度不會翻一番,若指令之間有關系,會造成無效快取以及速度降低
指令流水線instruction pipelining
處理相關任務時,資源能錯開使用,不均等分段會降低流水線的效率
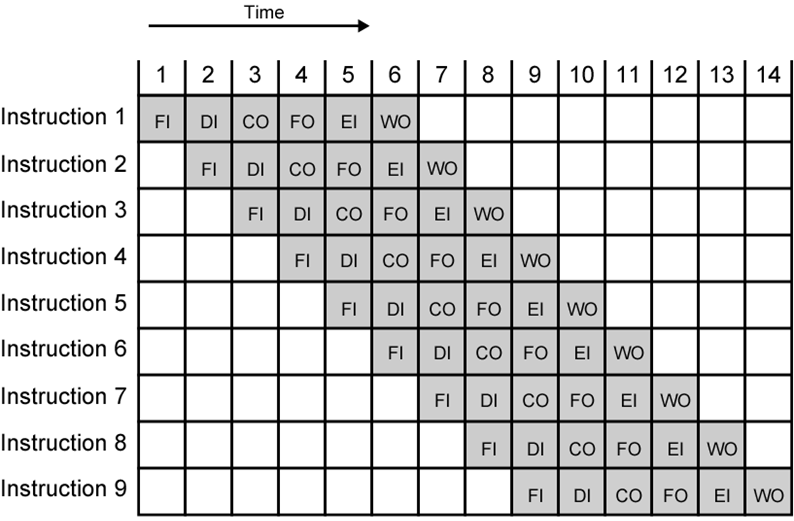
指令流水線可將指令處理分解如下:
取指令FI:從cache中讀下一條指令
譯碼指令DI:decode instruction
計算運算元CO:計算每個源運算元的有效地址,涉及偏移尋址、暫存器間接尋址等
取運算元FO:從存盤器中取出運算元,暫存器中的數不需要取
執行指令EI
寫運算元WO
實際運行中,指令之間肯定會有依賴,條件轉移也會降低速度,有條件轉移是在執行階段知道轉還是不轉
C語言中的goto是無條件轉移、for回圈是條件轉移
流水線性能
指令流水線的周期
τ
\tau
τ,是在流水線中將一組指令推進一段所需的時間,表示公式如下(掌握定義):
τ
=
m
a
x
i
[
τ
i
]
+
d
=
τ
m
+
d
1
≤
i
≤
k
\tau=max_i[\tau_i]+d=\tau_m+d\qquad 1\le i\le k
τ=maxi?[τi?]+d=τm?+d1≤i≤k
其中:
τ i = 流 水 線 第 i 段 的 電 路 延 遲 時 間 \tau_i=流水線第i段的電路延遲時間 τi?=流水線第i段的電路延遲時間
τ m = 最 大 段 延 遲 \tau_m=最大段延遲 τm?=最大段延遲
k = 指 令 流 水 段 數 k=指令流水段數 k=指令流水段數
d = 鎖 存 延 時 d=鎖存延時 d=鎖存延時
通常延時d等于時鐘脈沖的寬度而且 τ m > > d \tau_m>>d τm?>>d
假設現有n條指令在進行,無轉移發生,令
T
k
,
n
T_{k,n}
Tk,n?為k階段流水線執行所有n條指令所需的總時間,則有:
T
k
,
n
=
[
k
+
(
n
?
1
)
]
τ
T_{k,n}=[k+(n-1)]\tau
Tk,n?=[k+(n?1)]τ
提速比
s
k
=
n
k
τ
[
k
+
(
n
?
1
)
]
τ
=
n
k
k
+
(
n
?
1
)
s_k=\frac{nk\tau}{[k+(n-1)]\tau}=\frac{nk}{k+(n-1)}
sk?=[k+(n?1)]τnkτ?=k+(n?1)nk?
吞吐率
T
p
T_p
Tp?:流水線單位時間內產生的指令數(掌握定義)
T
p
=
n
[
k
+
(
n
?
1
)
]
τ
T_p=\frac{n}{[k+(n-1)]\tau}
Tp?=[k+(n?1)]τn?
T p m a x = 1 τ T_{pmax}=\frac{1}{\tau} Tpmax?=τ1?
n > > k , T p ≈ T p m a x n>>k,T_p\thickapprox T_{pmax} n>>k,Tp?≈Tpmax?
舉例
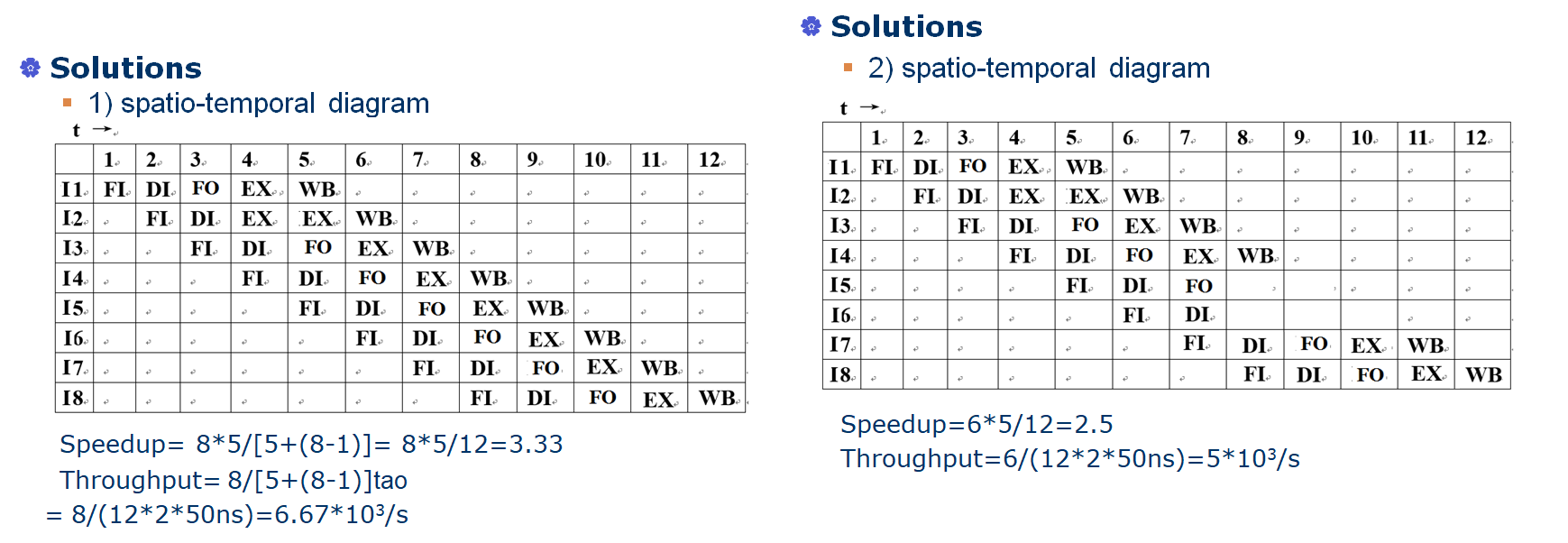
考慮一個時鐘周期為50ns的單流水線處理器有5個流水線階段:FI、DI、FO、EX和WB,假設每個階段的持續時間相等,需要2個時鐘周期,它需要執行8個連續指令,
繪制流水線各功能階段時序圖,計算提速和吞吐量,假設在執行指令期間沒有沖突、依賴或分支,
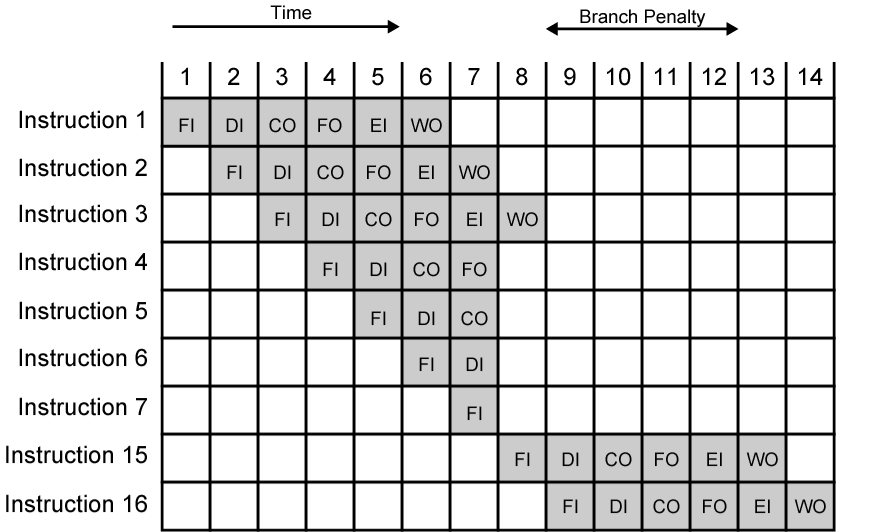
如果指令4是一個條件轉移指令,并且轉移的目標是指令7,在此執行中,結果是進行分支,繪制流水線各功能階段時序圖,計算提速和吞吐量,假設在指令8之后,沒有其他指令要執行,
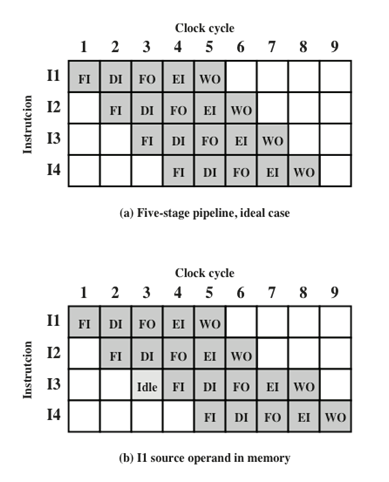
流水線相關性pipeline hazard
流水線相關性發生在流水線,因為某些條件不允許流水線亟需運行,而必須停頓,也稱為流水線空泡pipeline bubble,有三種型別:
結構相關(資源沖突)resource hazard
發生在兩條(或多條)已進入流水線的指令需要使用相同資源的時候
就意味著某些指令的處理程序需要停滯
資料沖突data hazard
資料沖突發生在對一個運算元位置的訪問出現沖突的時候,
程式中的兩條指令是依次執行,并且都將訪問同一個記憶體或者暫存器運算元,如果這兩條指令是嚴格執行的,那么沒問題發生,如果在流水線中運行,可能會使運算元不按次序更新,從而產生不正確的結果
舉例:
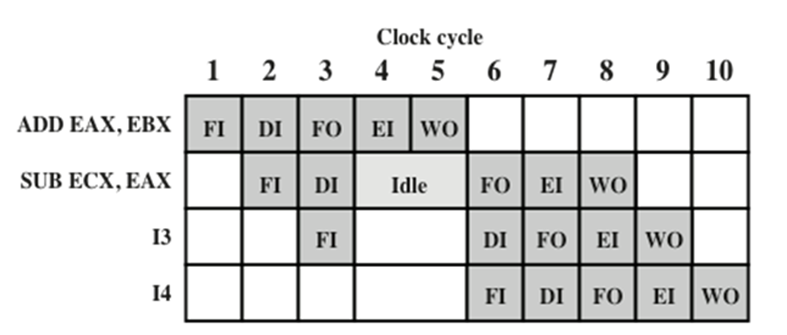
第一條指令將暫存器EAX和EBX中的內容相加,并將結果保存在EAX暫存器;
第二條指令從ECX中減去EAX,并將結果存回ECX;
ADD指令
1?? 寫后讀相關或真實資料相關(RAW)
一條指令改寫一個暫存器或記憶體地址
而后續的指令從所改寫的暫存器或記憶體地址讀取資料
如果在寫操作完成之前,讀操作就開始進行,那么就會發生相關
2?? 讀后寫相關或反相關(WAR)
一條指令讀一個暫存器或記憶體地址
而后續的指令又將改寫該暫存器或記憶體地址的內容
如果在讀操作完成之前,寫操作就開始執行,那么就會發生相關
3?? 寫后寫相關或輸出相關(WAW)
兩條指令要改寫同一個暫存器或記憶體地址
如果這兩條指令的寫操作發生次序與期望的次序相反,那么就會發生相關
在按序流動的流水線中,只可能出現RAW相關
控制沖突Control Hazards
也稱為分支沖突,發生在流水線對分支轉移做出了錯誤的預測,因此讀取了后期必須取消的指令的時候,處理辦法如下:
1?? 多個指令流multiple streams
使用兩個流水線
每個分支預取到單獨的流水線中執行
最終依據條件轉移指令結果選擇保留其中一條流水線的結果
問題
導致暫存器和存盤器訪問的競爭延遲
多個分支導致需要更多的流水線
應用
由IBM370,3033使用
2?? 預取分支目標prefetch branch target
除了取條件分支指令之后的指令外,分支目標處的指令也被預取
預取的結果會放到一個特殊的暫存器
目標被保存直到分支指令被執行
應用:IBM 360/91使用
3?? 回圈緩沖器loop buffer
維護一個小的但極高速的存盤器,含有n條最近順序取來的指令
流水線取指階段維護
若一個轉移將要發生,硬體首先檢查轉移目標是否在此緩沖器中
非常適合小的回圈
類似于指令高速快取,不同在于它只保留順序的指令,因而容量較小,成本也較低
應用:CRAY-1使用
4?? 分支預測
包括
預測絕不發生
預測總是發生
依據操作碼
假定對某些條件轉移指令總是預測發生轉移,對另外的一些轉移總是預測不發生轉移
發送/不發生切換
Bits (1~2bits):記錄執行轉移情況
適合回圈和迭代
轉移歷史表
是一個小容量的Cache — BTB/BHT
前三種靜態,后兩種動態:取決于執行的歷史
5?? 延遲轉移
插入NULL操作
阻塞流水線
使用在早期CPU上
重排序指令
亂序執行
目前機器常用
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/395371.html
標籤:其他