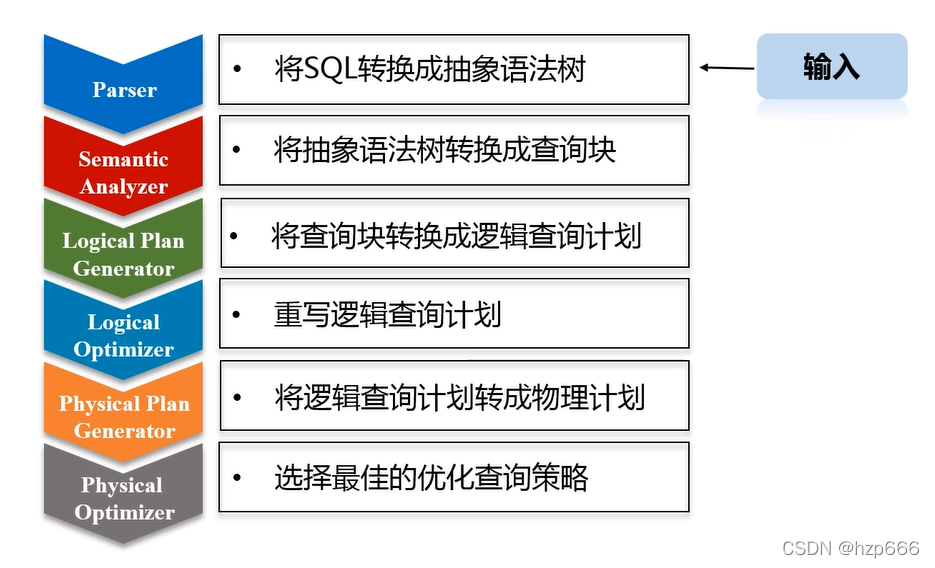
1.spark SQL是什么?
spark SQL類似 hive 的功能,
hive 是把SQL轉譯成 查詢hadoop的語法,
而spark SQL是把 SQL轉譯成 查詢spark的語法,

并且,spark SQL的前身 shark(也叫hive on spark) 就是借鑒的hive的 前幾個步驟,即除了最后的轉譯成 查詢spark的代碼,之前都借鑒了,
2.為什么用spark SQL?
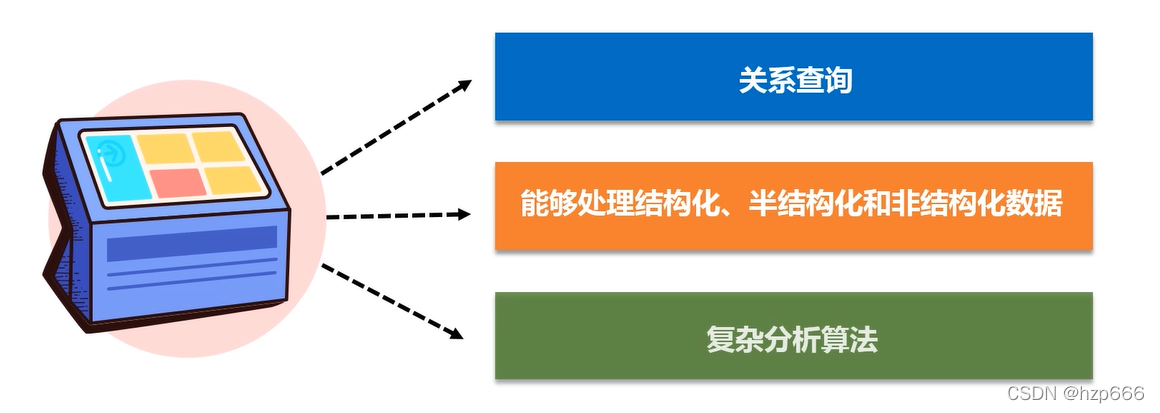
2.1關系型資料庫在大資料時代的不足
根源還是因為關系型資料庫不能滿足目前資料存讀需求,
大資料時代,90%的資料都是非結構化和半結構化的,
1.需要一個工具能夠滿足, 結構化和非結構化的資料處理需求,
2.關系型資料庫,只能做一些簡單的聚合操作(求和、平均值等),
無法滿足一些高級分析需求,比如 機器學習、圖計算等,
spark SQL的優勢:
1.有個資料抽象 叫dataframe,可以把結構化和 非結構化的資料融合起來,
2.可以應用于處理高級分析 機器演算法、圖形計算等,MLlib 的機器學習演算法中,底層的資料結構就是是sparkSQL的 dataframe
2.2shark的缺陷
spark SQL的前身 shark(也叫hive on spark) 照搬hive的 前幾個步驟,
存在2個致命問題,
1. 執行計劃優化環節,無法添加新的優化策略
hive 是專門把SQL轉為對hadoop的查詢 ,即MapReduce程式,
對spark的程式的優化并不好,
2.spark是執行緒級的程式,而hadoop是行程級的程式,
導致shark 一開始就存在 執行緒安全問題,
所以,sparkSQL除了參考 hive 中第一個parase模塊 (該模塊是把SQL轉為語法樹)外,其他模塊,查詢計劃、查詢優化....完全面向spark應用自己研發,
3.spark SQL的使用
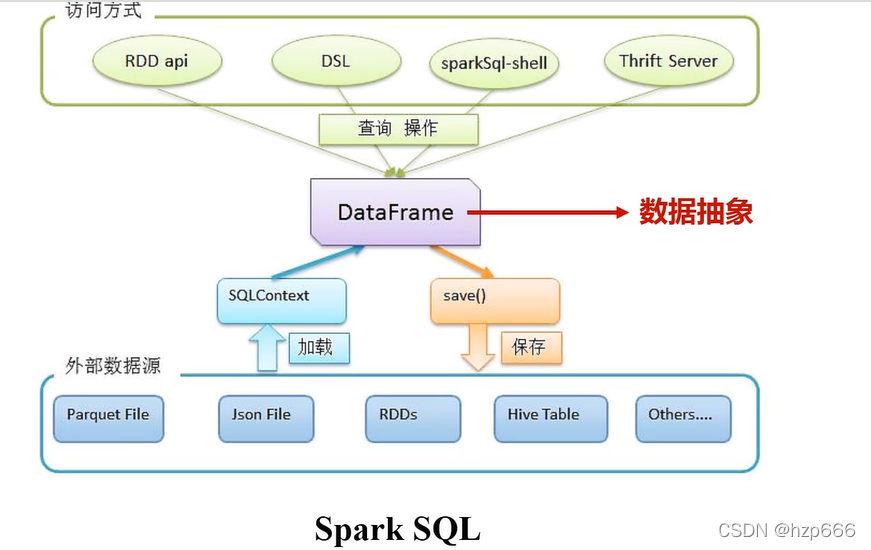
3.1 spark dataframe
sparkSQL新增了一個 資料抽象,dataframe
dataframe 相較RDD 多了一個結構化存盤,
3.2 RDD 和 sparkSQL 的dataframe 的區別
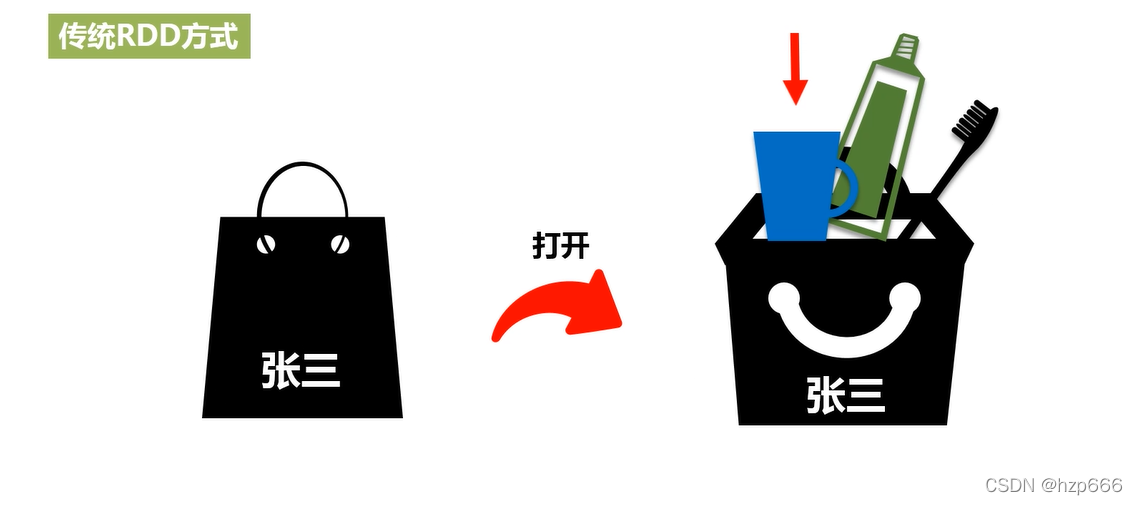
傳統的RDD是將資料存盤為一個個物件,然后資料的值相當于物件的一個屬性,
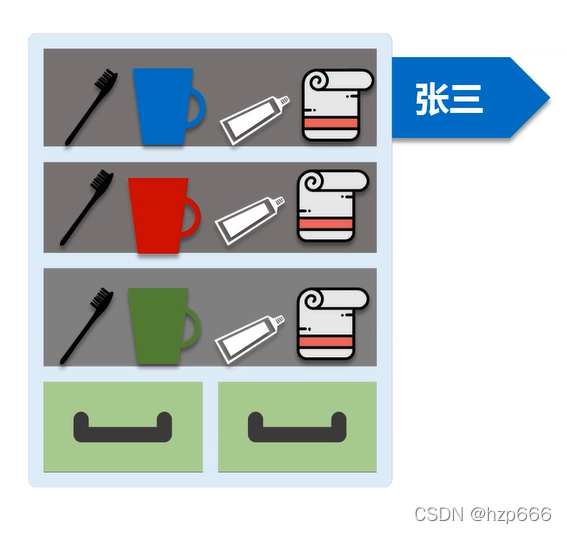
eg:RDD 需要找到張三的刷牙杯,第一步,先找到張三 這個物件,然后再從張三物件中 取刷牙杯的屬性,
dataframe 是相當于 把RDD做了結構化的存盤,
3.3創建 dataframe 物件
3.3.1 就像創建RDD一樣,需要先創建一個sparkSession 物件
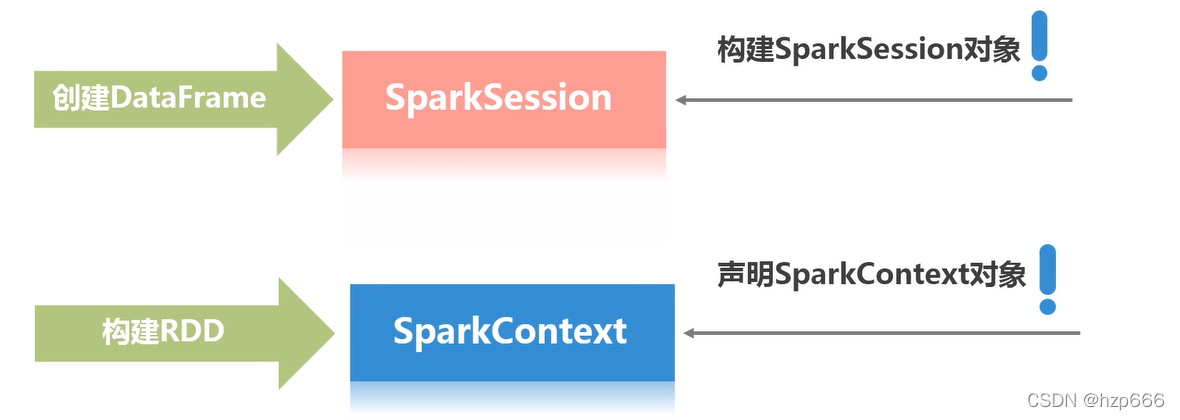
ps:spark-shell 環境中會 自動生成兩個物件, sparkContext物件 :sc 和 sparkSession物件:spark
但是如果在 自己的編程環境中,需要手動生成 sparkSession物件
ps:在idea中 ,如果沒有sparkSQL的依賴,需要現在pom.xml 中添加依賴,
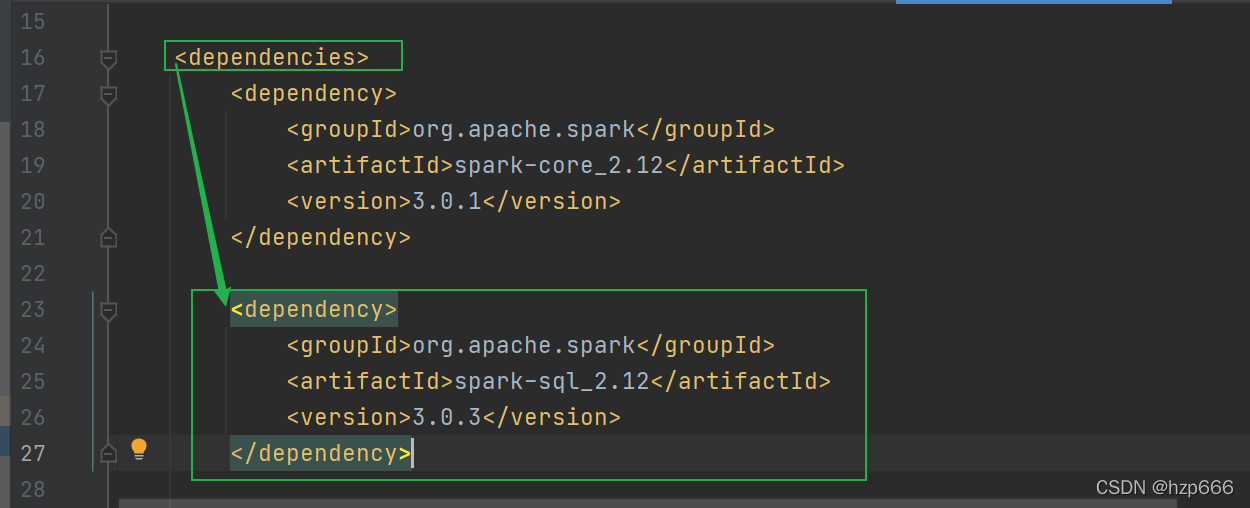
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.3</version>
</dependency>
如果不確定下載哪個版本,Apache可以查看對應的 版本,
下載鏈接: Downloads | Apache Spark
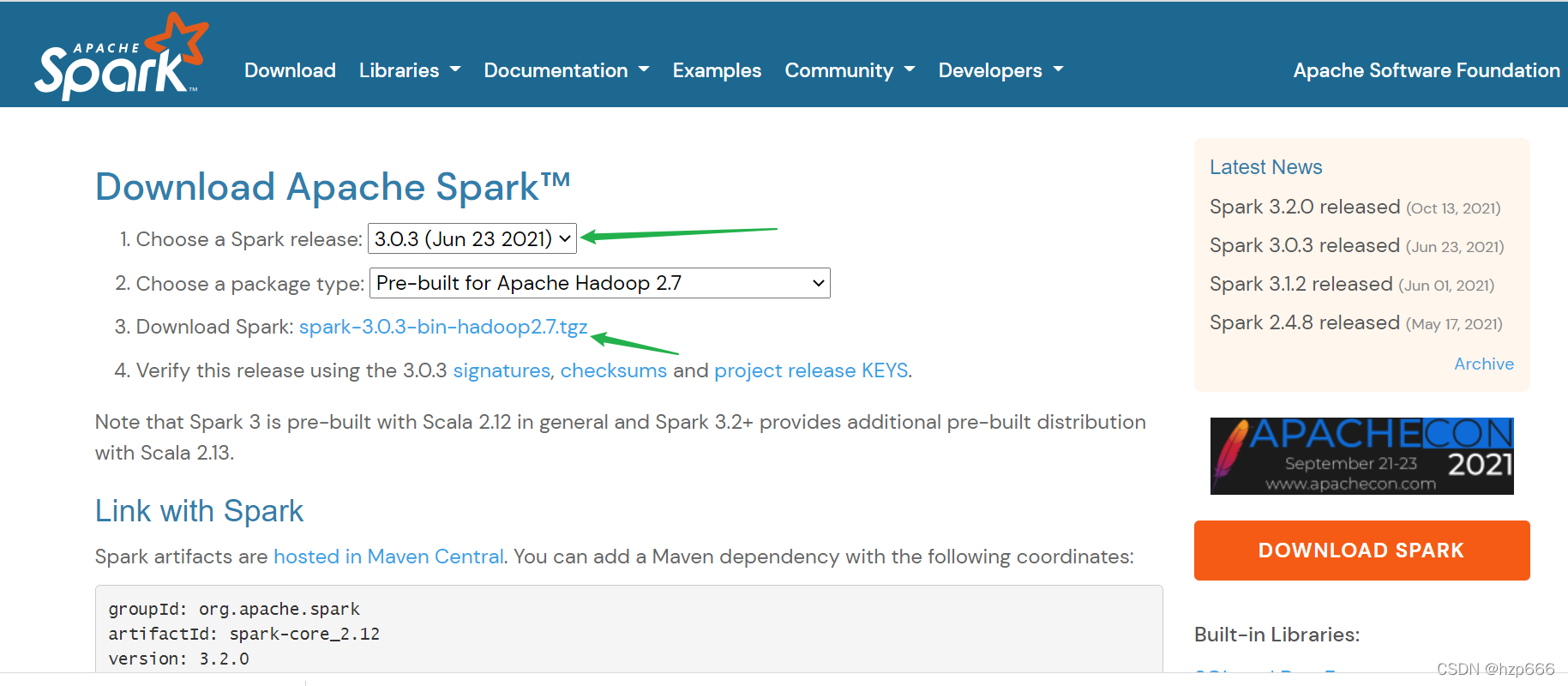
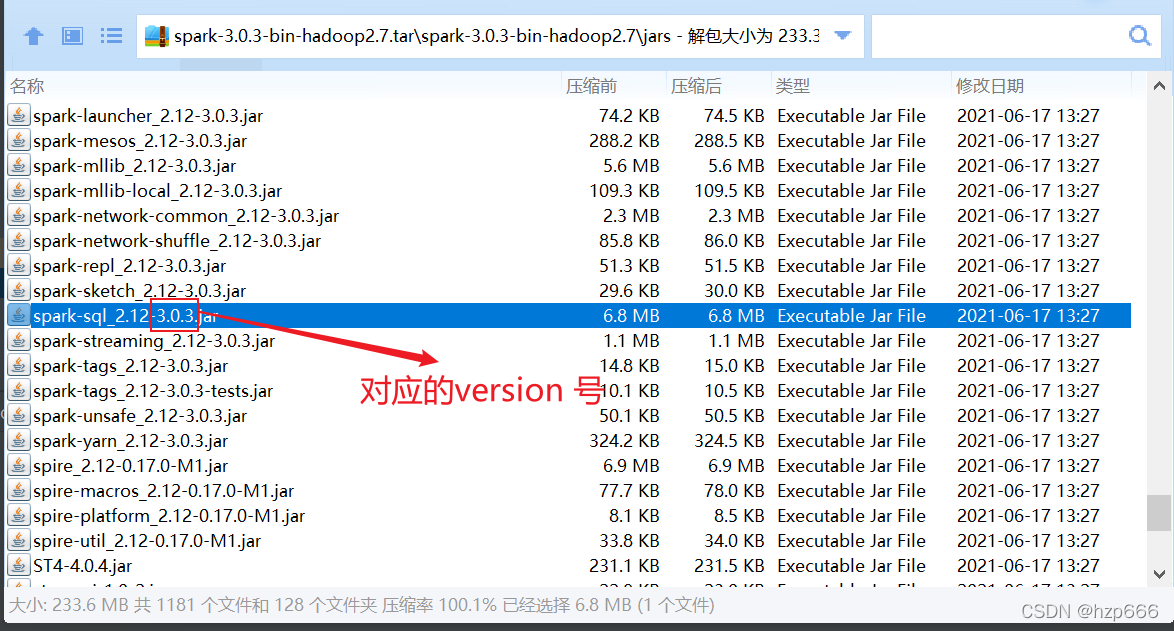
第一個框選對應的 spark版本,
第3個可以直接下載 全部依賴,
下載好后,可以解壓看下 jars 檔案夾內,對應的 各個組件版本,
3.3.2創建dataframe
1.

2.匯入隱式轉換包,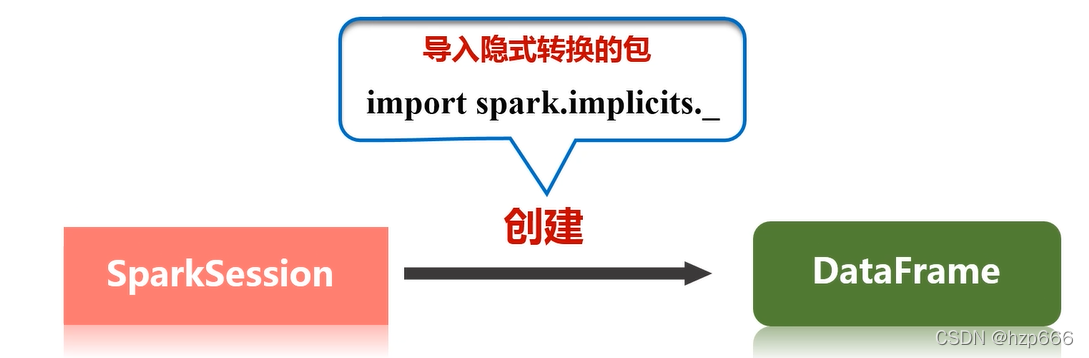
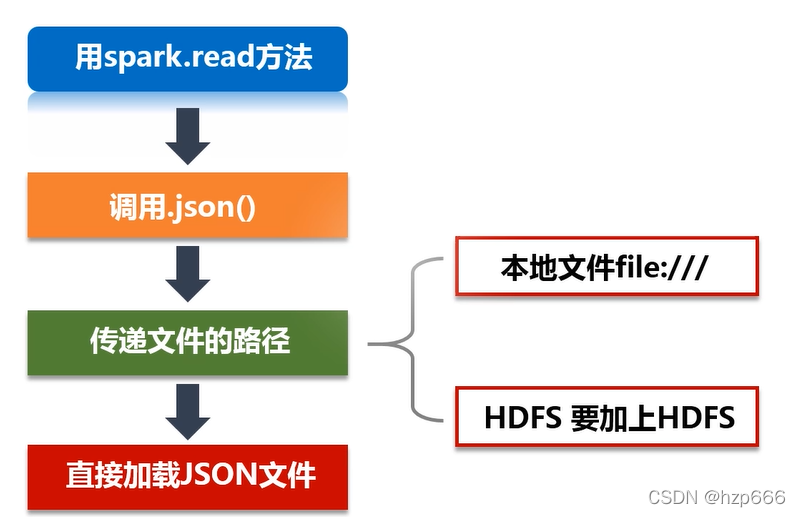
3.讀取資料檔案
讀取json 資料:
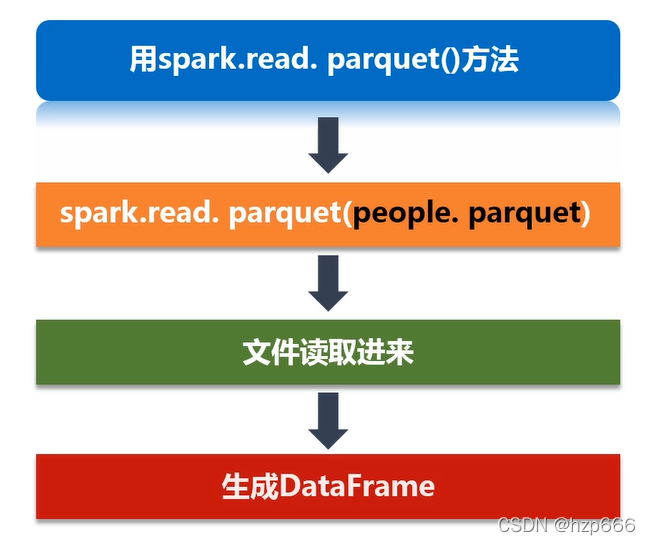
讀取parquet檔案
讀取csv 檔案:
eg1: 讀取一個json檔案

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396122.html
標籤:其他