圖解
巨恐怖的問題
搞懂這些問題 == spark批處理(入門)【狗頭】
– 什么是實時計算
– 衡量標準
– 舉例幾個用到實時計算的例子
– 實時計算有哪幾種實作技術
– 單臺計算的壓力在哪兒
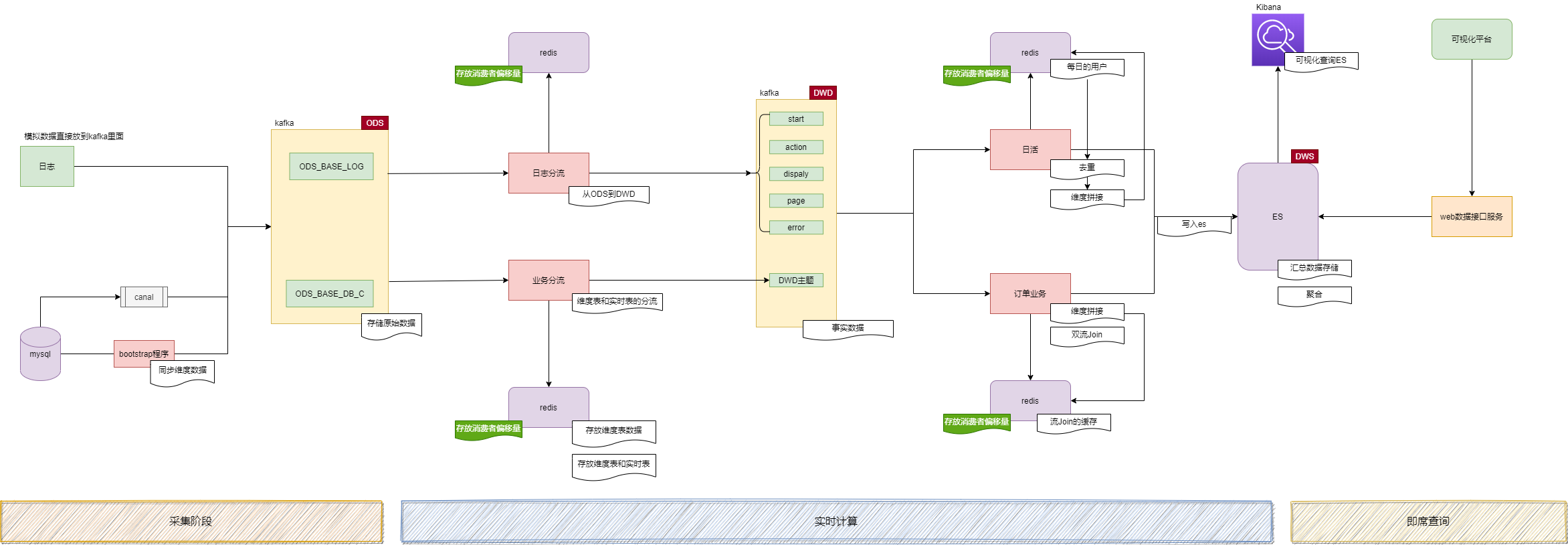
– 實時計算的架構
1、采集階段
1.1 業務資料如何采集?
1.2 業務資料如何確保不丟失資料?
1.3 日志采集為什么會這樣設計?不會丟失資料嗎?如果考慮到丟資料的情況怎么設計
1.4 為什么要選擇kafka來存放資料?別的框架可以嗎?
1.5 既然是實時計算,為什么不直接拿資料進行計算呢?
1.6 為什么會有一個全量匯入的程序?
1.7 canal再這里的作用?是否有其他可以替代
1.8 資料在kafka里面格式?
1.9 采集程序種還有哪些要注意的點?
1.10 kafka資料保留的時間?
2、實時計算
2.1 主流的計算方式?
2.2 為什么不直接計算出結果?還需要采用分層的結構?
ODS-》DWD
2.3 從ODS層到DWD層,不同的資料是如何處理的?
2.4 作為kafka的消費者和生產者,是如何保證不丟失資料的呢?
2.5 作為kafka的消費者和生產者,是如何保證不重復資料的呢?
2.6 redis在這里的作用?有其他組件可以替代嗎?
2.7 不同場景下,組件的選擇
2.8 redis在這里的優點和缺點?
2.9 如果redis崩了,資料會丟失嗎?
2.10 如果redis崩了,資料會重復嗎?
2.11 如果程式崩了,資料會丟失嗎?
2.12 如果程式崩了,資料會重復嗎?
2.13 如果kafka某個節點崩了,資料會重復嗎?
2.14 如果kafka某個節點崩了,資料會丟失嗎?
2.15 如果redis崩了,是如何處理的?
2.16 如何提高這部分的運行效率?舉例說明
2.17 能承受的最大計算量跟什么相關?
2.18 運行效率跟什么相關?
2.19 這部分有哪些可以優化的點?
2.20 kafka作為DWD層的存盤介質,存盤了什么主題?跟什么相關?
kafka-》程式-》kafka能否保證訊息有序?
DWD-》DWS
2.21 資料已經到了DWD,后續為什么不直接放到OLAP種分析?
2.22 這當中程式起到了什么作用?跟什么相關?
2.23 根據業務如何設計這部分程式?
2.24 為什么要寫入ES,這部分不能直接處理嗎?
2.25 針對兩個業務,分別做了哪些操作?
存盤的時序問題?
kafka-》程式-》redis,能否保證訊息有序
2.26 這部分需要考慮什么樣的問題?
2.27 資料丟失的情況?
2.28 資料重復的情況?
2.29 程式崩了,重啟是否會對業務產生影響?
2.30 這個階段redis的作用,能否替換成其他的?
2.31 寫入ES的時候會不會有資料丟失?采取的策略是什么?
2.32 寫入ES的時候會不會有資料重復?采取的策略是什么?
2.33 如何進行的維度拼接?
2.34 維度拼接可能產生的問題?
2.35 為什么要采用雙流join?
2.36 雙流join是如何實作的?
2.37 雙流join是否存在資料丟失的情況?如何避免?
2.38 雙流join是否存在資料重復的情況?如何避免?
2.39 雙流join采用快取策略時,如何選擇組件?
2.40 雙流jon種還有哪些注意事項?
2.41 寫入ES時,如何確保資料精確一次?
2.42 在寫入ES時發生了故障,已經提交到redis記錄的用戶的資料會不會丟失,如何處理的?
2.43 處理的細節?
2.44 如何規劃資料在ES的存盤?
2.45 資料存盤到ES后,實時計算結束了嗎?
3、即席查詢
3.1 為什么選擇OLAP作為流處理的最后一層
3.2 OLAP的選擇,除ES還有其他選擇嗎?
3.3 簡述以下ES的結構?特點(倒排索引)列式存盤?
3.4 ES存盤的資料是什么?有什么特點?
3.5 即席查詢的意義?
3.6 ES作為即席查詢的存盤層,負責哪些作業?
3.7 BI工具和可視化工具的區別?
3.8 舉例幾個統計的指標,ES具體是怎么實作的?
3.9 es讀程序
3.10 es的寫程序
3.11 es的段合并程序?
3.12 es檔案的修改和并發控制
3.13 es默認分詞和中文分詞的區別?
3.14 es的搜索流程?
– 進階
spark種的資料傾斜怎么處理?
spark的shuffle程序?
Spark有哪些聚合類的算子,我們應該盡量避免什么型別的算子?
spark on yarn 作業執行流程,yarn-client 和 yarn cluster 有什么區別
Spark為什么快,Spark SQL 一定比 Hive 快嗎
spark是流處理嗎?
RDD, DAG, Stage怎么理解?
RDD 如何通過記錄更新的方式容錯
寬依賴、窄依賴怎么理解?
Job 和 Task 怎么理解
Spark 血統的概念
Spark 粗粒度和細粒度
Transformation和action是什么?區別?舉幾個常用方法
Spark作業提交流程是怎么樣的
簡單描述快取cache、persist和checkpoint的區別
描述repartition和coalesce的關系與區別
Spark中的廣播變數與累加器
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396126.html
標籤:其他
下一篇:搭建kafka集群詳細步驟