什么是Kafka
Kafka是最初由Linkedin公司開發,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源專案,也是一個開源【分布式流處理平臺】,由Scala和Java撰寫,(也當做MQ系統,但不是純粹的訊息系統)
目前 Kafka 已經定位為一個分布式流式處理平臺,它以高吞吐、可持久化、可水平擴展、支持流資料處理等多種特性而被廣泛使用,目前越來越多的開源分布式處理系統如 Cloudera、Storm、Spark、Flink 等都支持與 Kafka 集成
生產者與消費者機制
在Kafka中,生產者(producer)將訊息發送給Broker,Broker將生產者發送的訊息存盤到磁盤當中,而消費者(Consumer)負責從Broker訂閱并且消費訊息,消費者(Consumer)使用pull這種模式從服務端拉取訊息,而zookeeper是負責整個集群的元資料管理與控制器的選舉,具體如下圖所示,
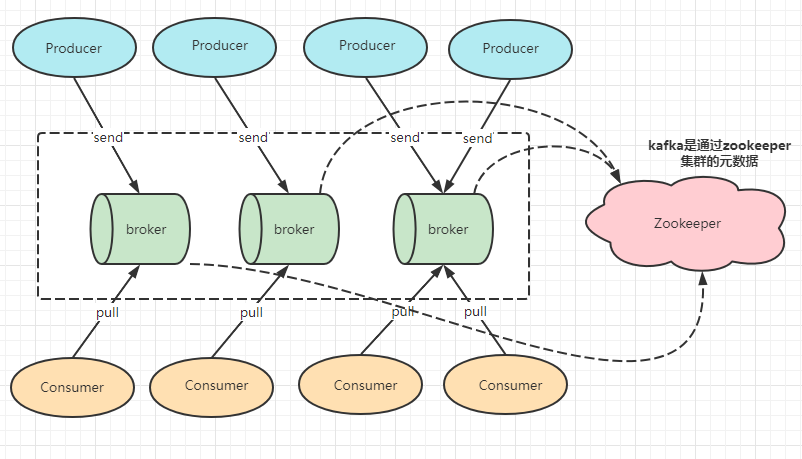
Kafka的producer生產者發送到Broker磁區策略
發布訂閱的物件是主題(Topic),生產者將訊息發送到指定的主題,消費者再對負責訂閱的主題來進行消費,在Kafka里的磁區機制是怎么樣的呢?它是將主題劃分成了多個磁區(partition),每一個磁區又有多個副本,在同一個主題下的不同磁區里的訊息也是不一樣的,在生產者生產出來的每一條訊息都只會發送到一個磁區里,Kafka里的磁區編號都是從0開始的,如果生產者向兩個磁區的主題發送一條訊息,那么這條不是在磁區0里,就是在磁區1里,
那么如何指定訊息到指定的磁區里呢?
這時候就可以看看生產者的發送邏輯了,在此之前我們需要知道一個叫ProducerRecord的玩意,這個是什么?
ProducerRecord就是發送給Broker的Key/value鍵值對,封裝基礎資料資訊,簡稱為PR,
內部結構
Topic(名字)
PartitionID(可選)
Key(可選)
Value
生產者發送邏輯
1、如果指定了Partition ID的話,那么PR就會被發送到指定的Partition里,
2、如果沒有指定Partition ID,但是指定了Key,那么PR就會按照hash(key)發送到相對應的Partition里
3、如果沒有指定Partition ID,也沒有指定Key,PR就會使用默認的round-robin輪訓發送到每一個Partition里(消費者消費partition磁區默認是range模式)
4、如果同時指定了Partition ID與Key的話,PR只會發送到指定的Partition(這時候的Key不起作用,代碼邏輯決定)
注意:Partition有多個副本,但是的話只有一個replicationLeader來負責這個Partition和生產者消費者互動
生產者到Broker的發送流程
kafka的客戶端發送資料到服務器里(并不是來一條發一條),會經過記憶體的緩沖區,在通過KafkaProducer發送出去的訊息都是先進入到客戶端的本地快取里,然后再把訊息收集到Batch里,再一次性的發送到Broker上去的,這樣的性能才可能提高,
生產者常見的配置
#kafka地址,即broker地址
bootstrap.servers
?
#當producer向leader發送資料時,可以通過request.required.acks引數來設定資料可靠性的級別,分別是0, 1,all,
acks
?
#請求失敗,生產者會自動重試,指定是0次,如果啟用重試,則會有重復訊息的可能性
retries
?
#每個磁區未發送訊息總位元組大小,單位:位元組,超過設定的值就會提交資料到服務端,默認值是16KB
batch.size
?
# 默認值就是0,訊息是立刻發送的,即便batch.size緩沖空間還沒有滿,如果想減少請求的數量,可以設定 linger.ms 大于#0,即訊息在緩沖區保留的時間,超過設定的值就會被提交到服務端
# 通俗解釋是,本該早就發出去的訊息被迫至少等待了linger.ms時間,相對于這時間內積累了更多訊息,批量發送 減少請求
#如果batch被填滿或者linger.ms達到上限,滿足其中一個就會被發送
linger.ms
?
# buffer.memory的用來約束Kafka Producer能夠使用的記憶體緩沖的大小的,默認值32MB,
# 如果buffer.memory設定的太小,可能導致訊息快速的寫入記憶體緩沖里,但Sender執行緒來不及把訊息發送到Kafka服務器
# 會造成記憶體緩沖很快就被寫滿,而一旦被寫滿,就會阻塞用戶執行緒,不讓繼續往Kafka寫訊息了
# buffer.memory要大于batch.size,否則會報申請記憶體不足的錯誤,不要超過物理記憶體,根據實際情況調整
buffer.memory
?
# key的序列化器,將用戶提供的 key和value物件ProducerRecord 進行序列化處理,key.serializer必須被設定,即使
#訊息中沒有指定key,序列化器必須是一個實作org.apache.kafka.common.serialization.Serializer介面的類,將#key序列化成位元組陣列,
key.serializer
value.serializer
Kafka的Consumer消費者機制和磁區策略講解
消費者根據什么模式從broker獲取資料的?為什么是pull模式,而不是broker主動push?
答案可以看文章一開始的圖,消費者是采用Pull拉取方式從broker的partition獲取資料,那為什么是pull模式而不是push呢?pull模式可以根據消費者的消費能力來進行自己調整,不同的消費者性能不一樣,如果broker沒有資料的話,消費者可以配置timeout的世界,進行阻塞等待一段時間后再回傳,但如果是broker主動Push,push的優點是可以快速的處理訊息,但是容易對消費者處理不過來,造成訊息的堆積和延遲,
消費者從哪個磁區進行消費?
我們知道一個topic有多個partition,一個消費者組里面就有多個消費者,那是怎么分配的呢?一個主題topic可以有多個消費者,因為里面有多個partition磁區(leader磁區),一個partition leader可以由一個消費組里的一個消費者來消費,
那么消費者從哪個磁區來進行消費呢?
策略一、round-robin (RoundRobinAssignor非默認策略)輪訓,按照消費者組來進行輪訓分配,同個消費者組監聽不同的主題也是一樣,是把所有的partition和所有的consumer都列出來,所以的話消費者組里面的訂閱主題是一樣的才可以,主題不一樣的話會出現分配不均勻的問題,比如下面這個例子:
#有七個磁區,同組里有兩個消費者
topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5/topic-p6 (磁區)
c-1: topic-p0/topic-p2/topic-p4/topic-p6 (消費者1)
c-2:topic-p1/topic-p3/topic-p5 (消費者2)
這樣會有什么弊端,如果是同一消費者組里,所訂閱的訊息是不相同的,在執行磁區的時候分配不是輪詢分配,這樣可能會導致磁區分配的不均勻,例如現在有三個消費者C0、C1、C2,它們共訂閱了3個主題:t0、t1、t2,這時候t0有1個磁區(p0),t1有2個磁區(p0,p1),t2有3個磁區(p0,p1,p2),消費者C0訂閱了主題t0,消費者C1訂閱主題t0和t1,消費者C2訂閱的是t0,t1,t2,因為是輪詢的機制,當C0訂閱到T0后,C1就訂閱不了到T0了,但是可以訂閱到T1,C2也一樣的訂閱不了T0,但是T1和T2都能訂閱到,這時候T2也就只有C2訂閱,其他的C0與C1是不可見的,這時候T2的的訊息也就給C2這個消費者來消費了,這個情況就是分配不均的問題,
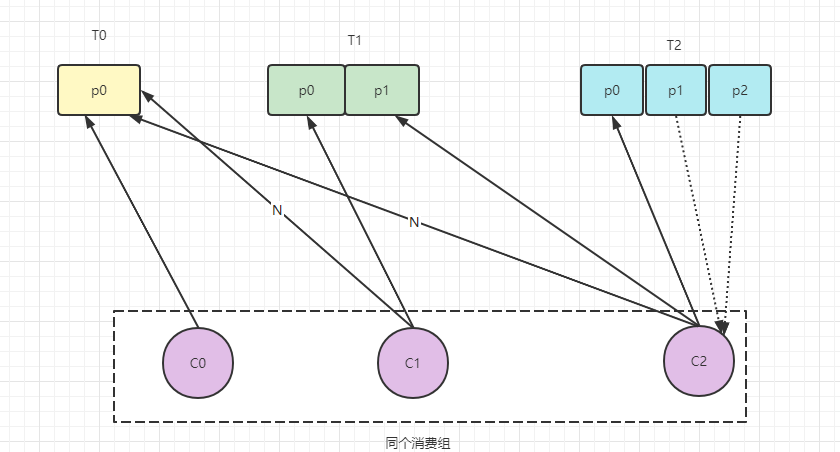
策略二、range(RangeAssignor默認策略)范圍,按照主題來進行分配,如果不平均分配的話,則第一個消費者會分配比較多的磁區,一個消費者監聽不同的主題也不影響,這一種策略有什么弊端呢,只是針對一個topic來說的話,c-1多消費一個磁區的話影響并不大,如果有多個topic,那么針對每一個topic的話,消費者C-1都將多消費1個磁區,topic越多的話那么久消費的磁區也越多,性能會有所下降,
【面試題】Consumer消費者重新分配策略與offset維護機制
什么是Rebalance操作
Kafka怎么均勻的分配某一個topic下所有的partition到各個消費者的呢,從而使得訊息的消費速度達到了最快,這就是平衡,而rebalance(重平衡)其實就是重新進行partition的分配,從而使得partition的分配重新達到了平衡的狀態,如下圖,有兩個Consumer,A和B,當第三個成員C加入時,Kafka就會觸發Rebalance,重新分配策略為A、B、C重新磁區,Rebalance之后的分配依舊還是公平的,每個Consumer實體都獲取了兩個磁區的消費權,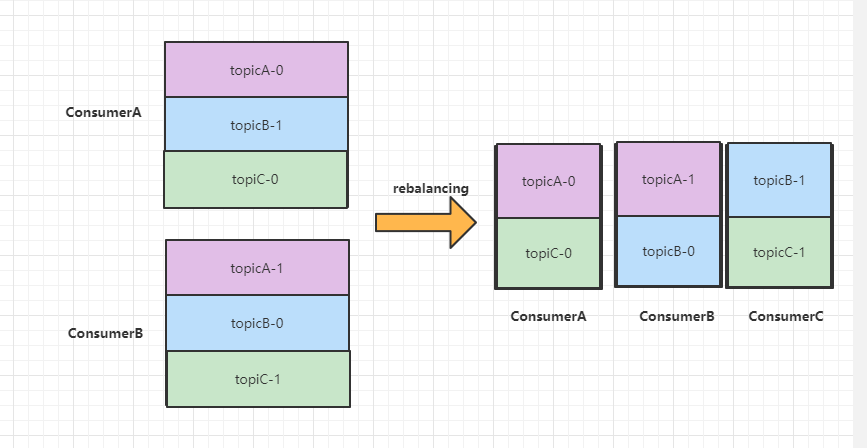
當消費者在消費程序突然宕機了,重新恢復后是從哪里消費,會有什么問題?
消費者會記錄offset,故障恢復后會從這里繼續消費,那么這個offset記錄在哪里呢?記錄在zookeeper和本地,新版的默認將offset保證在kafka的內置topic中,名稱為_consumer_offsets,在這個topic默認會有50個Partition,每一個Partition都有3個副本,磁區數量就是由引數offset.topic.num.partition配置的,通過groupid的哈希值和該引數的取模方式來確定某個消費者組已消費的offset保存到_consumer_offsets主題的哪個磁區中,這個由消費者組名+主題+磁區,來確定唯一的offset的key,從而獲取對應的值,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396133.html
標籤:其他
下一篇:Spark SQL functions.scala 原始碼決議(六)Misc functions (基于 Spark 3.3.0)