一. 面試題及剖析
1. 今日面試題
ConcurrentHashMap的底層原理是什么?
ConcurrentHashMap中涉及到了哪些資料結構?
ConcurrentHashMap為什么是執行緒安全的?
為什么ConcurrentHashMap的讀操作不需要加鎖?
2. 題目剖析
壹哥在上一篇文章中,開始給大家介紹ConcurrentHashMap,重點介紹了ConcurrentHashMap的通用功能、特點等內容,文章鏈接如下:
高薪程式員&面試題精講系列45之你熟悉ConcurrentHashMap嗎?
但因為ConcurrentHashMap在JDK 7與JDK 8兩個不同的版本中,改動較大,所以我們需要分版本來進行分析,本文先從JDK 7開始分析ConcurrentHashMap的底層原理,請各位童鞋拿出筆記做好記錄哦!
二. JDK 7中ConcurrentHashMap的設計原理【重點】
本節相關面試題:
ConcurrentHashMap的底層原理是什么?
ConcurrentHashMap中涉及到了哪些資料結構?
雖然JDK 7及其之前版本的API,我們現在開發時已經很少用了,但有些面試官就喜歡問一些古董問題,并且也有些古董級的專案在使用這種陳舊的API,所以基于這種現實,壹哥 還是帶大家來了解一下JDK 7中的ConcurrentHashMap,
1. 概述
在JDK 7版本中,ConcurrentHashMap和HashMap的設計思路其實是差不多的,但為了支持并發操作,做了一定的改進,比如ConcurrentHashMap中的資料是一段一段存放的,我們把這些分段稱之為Segment分段,在每個Segment分段中又有 陣列+鏈表 的資料結構,默認情況下ConcurrentHashMap把主干分成了 16個Segment分段,并對每一段都單獨加鎖,我們把這種設計策略稱之為 "分段鎖", ConcurrentHashMap就是利用這種分段鎖機制進行并發控制的,JDK 7中ConcurrentHashMap的基本資料結構如下圖所示:
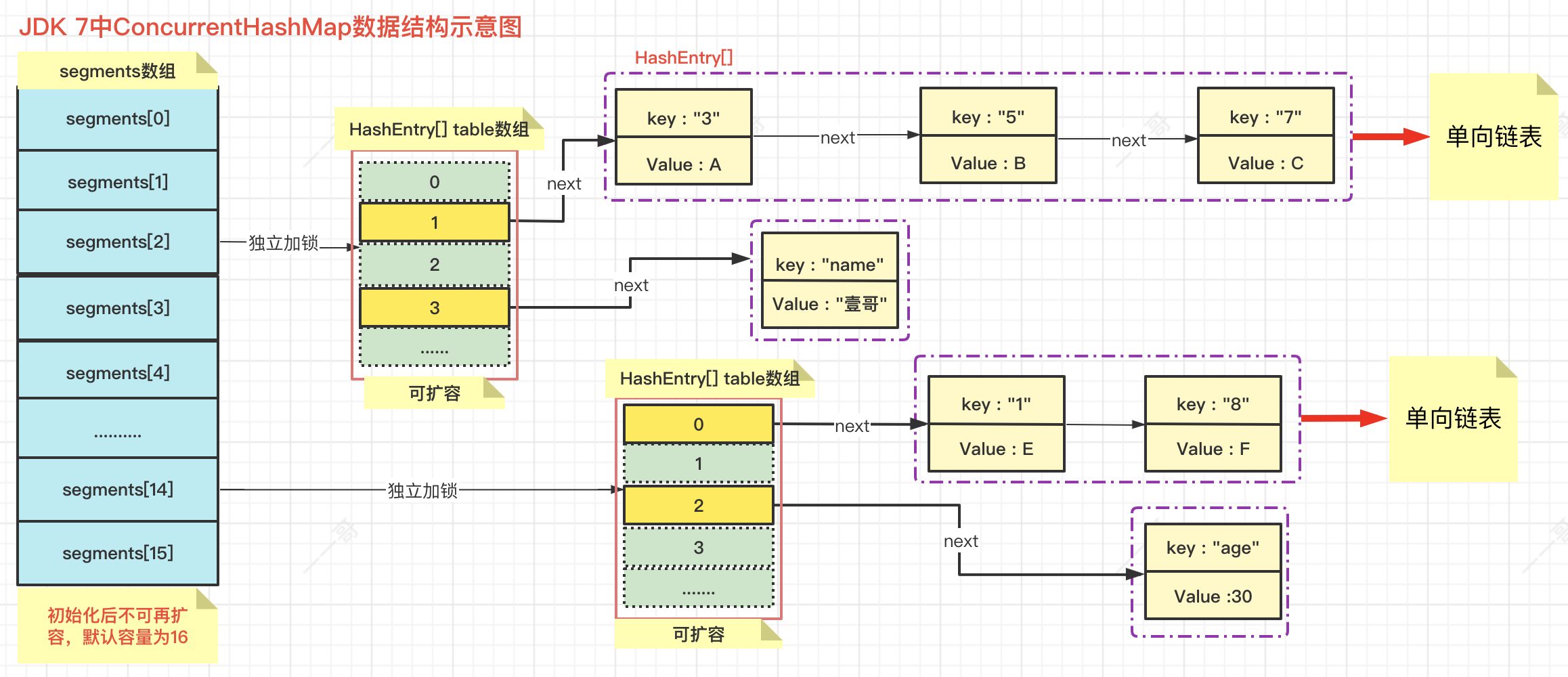
在理想狀態下,ConcurrentHashMap可以 同時支持16個執行緒 執行并發寫操作,以及任意數量的執行緒進行并發讀操作,在寫操作時,通過分段鎖技術,只對所操作的段加鎖而不會影響其它分段,且在讀操作時(幾乎)不需要加鎖,
2. Segment分段
上文給大家提到了Segment分段的概念,接下來 壹哥 再對其做個詳細的介紹,
Segment翻譯過來是 片段、部分 的意思,我們一般稱之為 段 或者 槽,默認情況下一個ConcurrentHashMap中有16個Segment分段,每個分段都可以獨立加鎖,我們可以認為這個ConcurrentHashMap的ConcurrentLevel并發等級是16,那么理論上就允許16個執行緒并發執行,在多執行緒并發環境下,對不同Segment分段里的資料進行操作是不用考慮鎖競爭的,所以,對同一個Segment的操作才需要考慮執行緒同步,不同的Segment則無需考慮,
另外Segment分段的數量一旦被初始化分配完畢,就不可再被擴容,而在每個Segment分段里面都維護了一個HashEntry陣列,這個陣列是可以被擴容的,所以每個Segment分段其實都類似于是一個HashMap,另外Segment類繼承自ReentrantLock類,這是一種可重入鎖(ReentrantLock),其原始碼如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry<K,V>[] table;
final float loadFactor;
}在Segment類中,有5個重要的成員變數,其具體含義如下:
- count:代表Segment中存盤的資料元素數量;
- modCount:記錄會對table陣列中元素數量造成影響的操作次數,比如記錄put()、remove()等方法的執行次數;
- threshold:閾值,如果Segment中元素的數量超過該值就會對table陣列進行擴容;
- table:HashEntry陣列,陣列中的每一個元素都是鏈表中的一個節點;
- loadFactor:負載因子,用于確定threshold閾值進行擴容,與HashMap中的負載因子作用一樣,
經過 壹哥 這么一描述,你會發現,其實ConcurrentHashMap就類似于是一個“大倉庫”,為了高效的利用這個“大倉庫”,默認情況下我們可以把這個“大倉庫”分成16個“區域”,而每個“區域”內部又可以再劃分成若干個“小房間”,我們可以對每個“區域”加鎖,這并不會影響其他“區域”貨物的“進出”,
3. 分段鎖的優劣
從上面的原始碼中,我們知道Segment繼承了一個可重入鎖ReentrantLock,由此獲取了鎖的能力,每個Segment分段鎖控制的都是一小段,但當每個Segment越來越大時,鎖的粒度也就變大了,
分段鎖的優勢在于可以確保操作不同Segment分段時的并發執行,而操作同一個Segment分段時需要進行鎖的競爭和等待,這相對于對整個HashMap進行synchronized同步鎖操作是有優勢的,
但分段鎖的缺點在于會把一個Map分成很多段(默認是16段),容易造成記憶體空間浪費(容易不連續、碎片化),另外操作Map時,如果競爭同一個分段鎖的概率較小,分段鎖反而會造成更新等操作的長時間等待;而當某個段很大時,分段鎖的性能又會下降,
4. segments[]陣列
上面說了,在默認情況下,一個ConcurrentHashMap會被拆分成固定的16個Segment分段,這16個Segment分段就組成了一個segments[]陣列,其原始碼如下:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
final Segment<K,V>[] segments;
...
}5. ConcurrentHashMap構造方法核心引數
我們要想使用ConcurrentHashMap,肯定要先構造出其物件,ConcurrentHashMap為我們提供了5個構造方法,其中最重要的一個是帶有3個引數的構造方法,原始碼如下:
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
......
}該構造方法中的3個核心引數含義如下:
- initialCapacity: 初始總容量,默認16;
- loadFactor: 負載因子,默認0.75;
- concurrencyLevel: 并發級別,默認16,代表集合內部Segment的數量,concurrencyLevel一經指定,不可改變,
這里我們一定要注意,concurrencyLevel并發級別 是用來控制Segment數量的,在ConcurrentHashMap創建后,Segment的數量是不會再變的,即Segment本身無法再擴容,擴容改變的是每個Segment中table陣列的大小,這樣做的好處是擴容程序不需要對整個ConcurrentHashMap做rehash,只需要對Segment里面的元素做一次rehash就可以了,
對ConcurrentHashMap進行初始化還是很簡單的,先是根據concurrencyLevel數量來new出一個Segment陣列,這里Segment的數量必須是2的整數倍,且<=concurrencyLevel中最大的那個,這樣的好處是方便通過移位操作來進行hash,加快hash的程序,另外intialCapacity用于指定Segment內部的容量大小,也必須是2的整數倍,這同樣是為了加快hash的程序,
6. HashEntry簡介
在每個Segment分段中,都持有一個HashEntry<K,V>[] table陣列,這個陣列類似于HashMap中的Node<K,V>[] table陣列,所以HashEntry與Node類相似,也是K-V結構,并且帶有一個next節點,其原始碼如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
}
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}我們從原始碼中可以看出,HashEntry<K,V>[] table陣列中存盤的是一個一個的HashEntry物件,該物件是key-value結構的存盤單元,在HashEntry中,除了value屬性以外,其他的幾個屬性都是final修飾的,這樣做是為了防止鏈表結構被破壞,出現ConcurrentModificationException的情況,另外HashEntry可以通過next屬性來關聯下一個HashEntry物件,其結構如下圖所示:
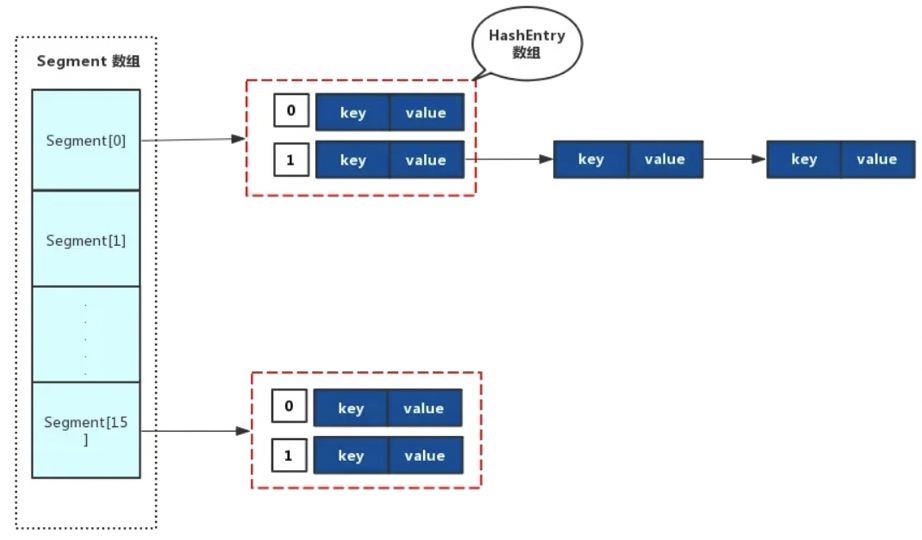
從上圖可以看出,ConcurrentHashMap由一個 segments[]陣列 組成,該陣列的每一個元素都是一個 Segment分段,而在每個Segment分段中,又是一個由 HashEntry陣列+鏈表 組成的結構,由此可見,Segment類似于一個小型的HashMap,我們可以把ConcurrentHashMap理解為HashMap的集合,
7. ConcurrentHashMap的并發操作
本節相關面試題:
ConcurrentHashMap為什么是執行緒安全的?
在上面的小節中,壹哥 跟大家說過,ConcurrentHashMap的擴容,指的是Segment分段中 HashEntry table[]陣列 的擴容,并不是指segments[]陣列的擴容,如下圖所示:
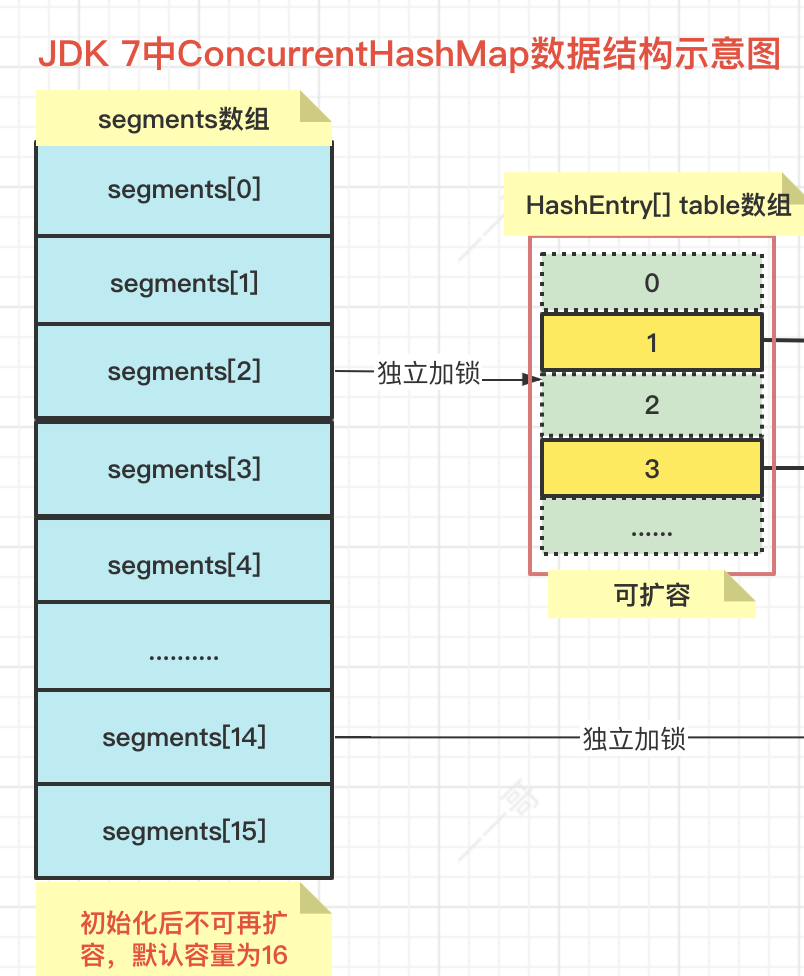
我們在操作ConcurrentHashMap時,一般就是在操作某一個具體的Segment,而在多執行緒環境下,不同的執行緒會操作不同的Segment,所以當我們對ConcurrentHashMap進行并發操作時,只要鎖住一個 Segment,其余的Segment依然可以操作,這樣只要保證每個 Segment 是執行緒安全的,就實作了全域的執行緒安全,彼此互不影響,以此實作了并發操作,
但是當多個執行緒想要操作同一個分段時,是需要先獲取鎖的,所有的put()、get()、remove()等方法都會先根據key的 hash值 找到相應的分段,然后再嘗試獲取鎖進行訪問,
比如當ConcurrentHashMap進行put()操作時,會先根據key找到某個承載資料的具體的Segment分段,然后再競爭獲取到Segment的獨占鎖,獲取鎖的邏輯很簡單,就是進行tryLock(),如果獲取鎖失敗了,就再去執行scanAndLockForPut()方法,scanAndLockForPut()方法的實作邏輯也是比較簡單的,就是通過 回圈呼叫tryLock() 進行多次獲取,如果回圈的次數retries大于事先設定好的MAX_SCAN_RETRIES,就執行lock()方法,此方法會進行阻塞等待,直到成功地拿到Segment鎖為止,
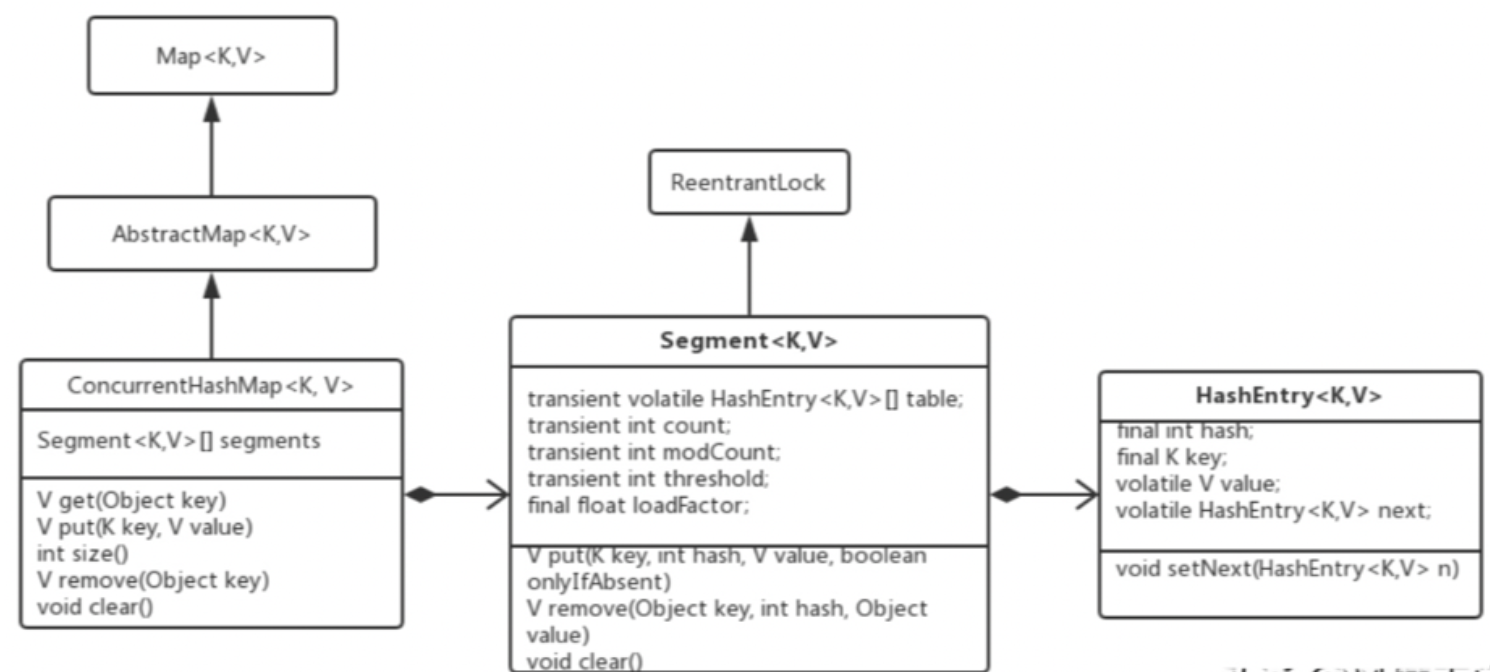
8. ConcurrentHashMap的類關系
以上就是JDK 7中的ConcurrentHashMap,最后 壹哥 再給大家簡單總結一下,JDK 7 中的ConcurrentHashMap采用了 Segment分段鎖(ReentrantLock) + HashEntry陣列 +鏈表 的技術,整個Map被分成了多個段,每個分段中都有自己的Segment分段鎖,段與段之間可以實作多執行緒環境下的并發訪問,我們可以用下圖來歸納一下,JDK 7中ConcurrentHashMap的類關系:
三. 結語
本篇文章,壹哥 講解了JDK 7版本的ConcurrentHashMap的底層原理,各位至少需要掌握以上內容,請認真背下來吧,接下來 壹哥 會再通過另一篇文章,給大家講解 JDK 8中的ConcurrentHashMap原理,請做好準備哦,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/396543.html
標籤:其他
上一篇:演算法復習之分治與貪心(1)
下一篇:會話跟蹤技術