作者
呂亞霖,2019年加入作業幫,作業幫架構研發負責人,在作業幫期間主導了云原生架構演進、推動實施容器化改造、服務治理、GO微服務框架、DevOps的落地實踐,
莫仁鵬,2020年加入作業幫,作業幫高級架構師,在作業幫期間,推動了作業幫云原生架構演進,負責作業幫服務治理體系的設計和落地、服務感知體系建設以及自研mesh、MQproxy研發作業,
摘要
日志是服務觀察的主要方式,我們依賴日志去感知服務的運行狀態、歷史狀況;當發生錯誤時,我們又依賴日志去了解現場,定位問題,日志對研發工程師來說例外關鍵,同時隨著微服務的流行,服務部署越來越分散化,所以我們需要一套日志服務來采集、傳輸、檢索日志
基于這個情況,誕生了以 ELK 為代表的開源的日志服務,
需求場景
在我們的場景下,高峰日志寫入壓力大(每秒千萬級日志條數);實時要求高:日志處理從采集到可以被檢索的時間正常 1s 以內(高峰時期 3s);成本壓力巨大,要求保存半年的日志且可以回溯查詢(百 PB 規模),
ElasticSearch 的不足
ELK 方案里最為核心的就是 ElasticSearch, 它負責存盤和索引日志, 對外提供查詢能力,Elasticsearch 是一個搜索引擎, 底層依賴了 Lucene 的倒排索引技術來實作檢索, 并且通過 **shard **的設計拆分資料分片, 從而突破單機在存盤空間和處理性能上的限制
寫入性能
? ElasticSearch 寫入資料需要對日志索引欄位的倒排索引做更新,從而能夠檢索到最新的日志,為了提升寫入性能,可以做聚合提交、延遲索引、減少 refersh 等等,但是始終要建立索引, 在日志流量巨大的情況下(每秒 20GB 資料、千萬級日志條數), 瓶頸明顯,離理想差距過大,我們期望寫入近乎準實時,
運行成本
? ElasticSearch 需要定期維護索引、資料分片以及檢索快取, 這會占用大量的 CPU 和記憶體,日志資料是存盤在機器磁盤上,在需要存盤大量日志且保存很長時間時, 機器磁盤使用量巨大,同時索引后會帶來資料膨脹,進一步帶來成本提升,
對非格式化的日志支持不好
? ELK需要決議日志以便為日志項建立索引, 非格式化的日志需要增加額外的處理邏輯來適配,存在很多業務日志并不規范,且有收斂難度,
總結:日志檢索場景是一個寫多讀少的場景, 在這樣的場景下去維護一個龐大且復雜的索引, 在我們看來其實是一個性價比很低的事情,如果采用 ElasticSearch 方案,經測算我們需要幾萬核規模集群,仍然保證不了寫入資料和檢索效率,且資源浪費嚴重,
日志檢索設計
面對這種情況, 我們不妨從一個不同的角度去看待日志檢索的場景, 用一個更適合的設計來解決日志檢索的需求, 新的設計具體有以下三個點:
日志分塊
同樣的我們需要對日志進行采集,但在處理日志時我們不對日志原文進行決議和索引,而是通過日志時間、日志所屬實體、日志型別、日志級別等日志元資料對日志進行分塊,這樣檢索系統可以不對日志格式做任何要求,并且因為沒有決議和建立索引(這塊開銷很大)的步驟, 寫入速度也能夠達到極致(只取決于磁盤的 IO 速度),
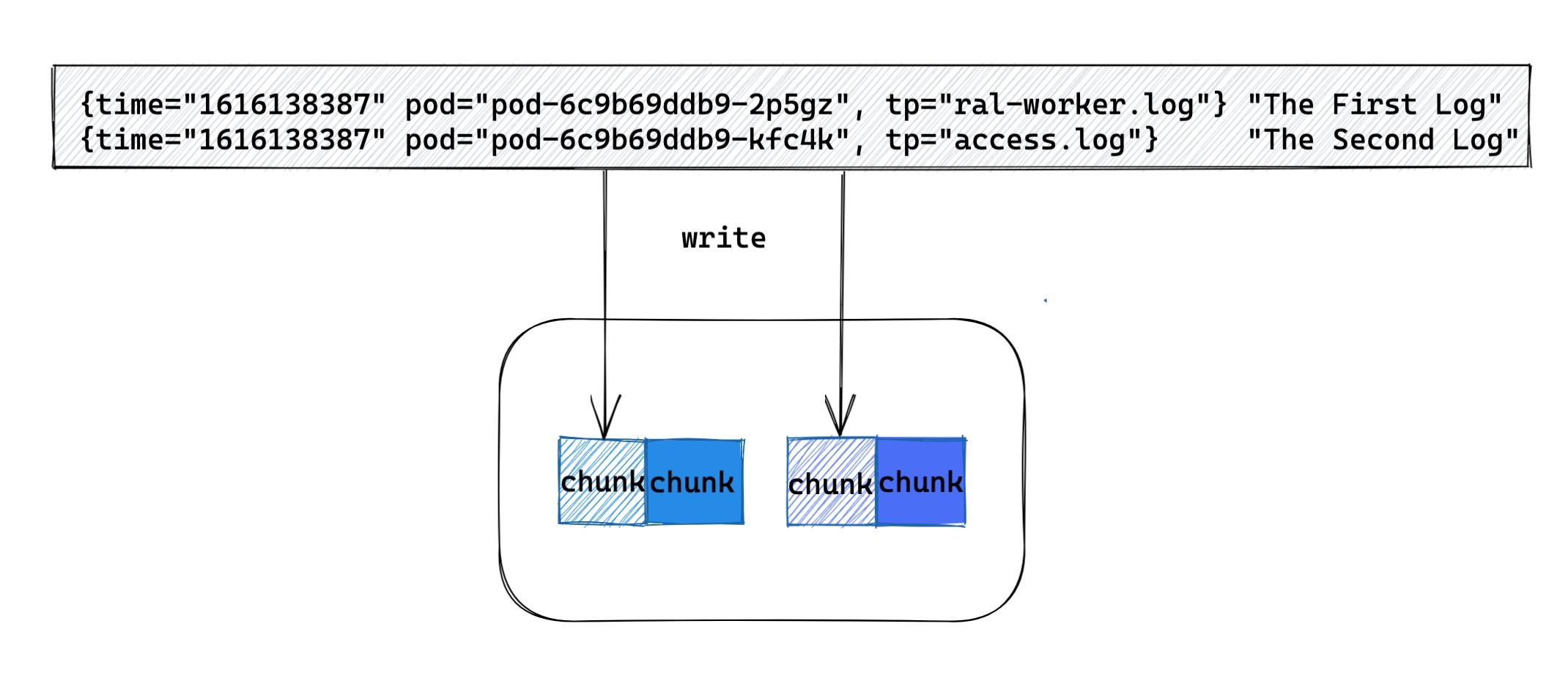
簡單來說, 我們可以將一個實體產生的同一類日志按時間順序寫入到一個檔案中, 并按時間維度對檔案拆分. 不同的日志塊會分散在多臺機器上(我們一般會按照實體和型別等維度對日志塊的存盤機器進行分片), 這樣我們就可以在多臺機器上對這些日志塊并發地進行處理, 這種方式是支持橫向擴展的. 如果一臺機器的處理性能不夠, 橫向再擴展就行,
那如何對入日志塊內的資料進行檢索呢?這個很簡單, 因為保存的是日志原文,可以直接使用 grep 相關的命令直接對日志塊進行檢索處理,對開發人員來說, grep 是最為熟悉的命令, 并且使用上也很靈活, 可以滿足開發對日志檢索的各種需求,因為我們是直接對日志塊做追加寫入,不需要等待索引建立生效,在日志刷入到日志塊上時就可以被立刻檢索到, 保證了檢索結果的實時性,
元資料索引
接下來我們看看要如何對這么一大批的日志塊進行檢索,
首先我們當日志塊建立時, 我們會基于日志塊的元資料資訊搭建索引, 像服務名稱、日志時間, 日志所屬實體, 日志型別等資訊, 并將日志塊的存盤位置做為 value 一起存盤,通過索引日志塊的元資料,當我們需要對某個服務在某段時間內的某類日志發起檢索時,就可以快速地找到需要檢索的日志塊位置,并發處理,
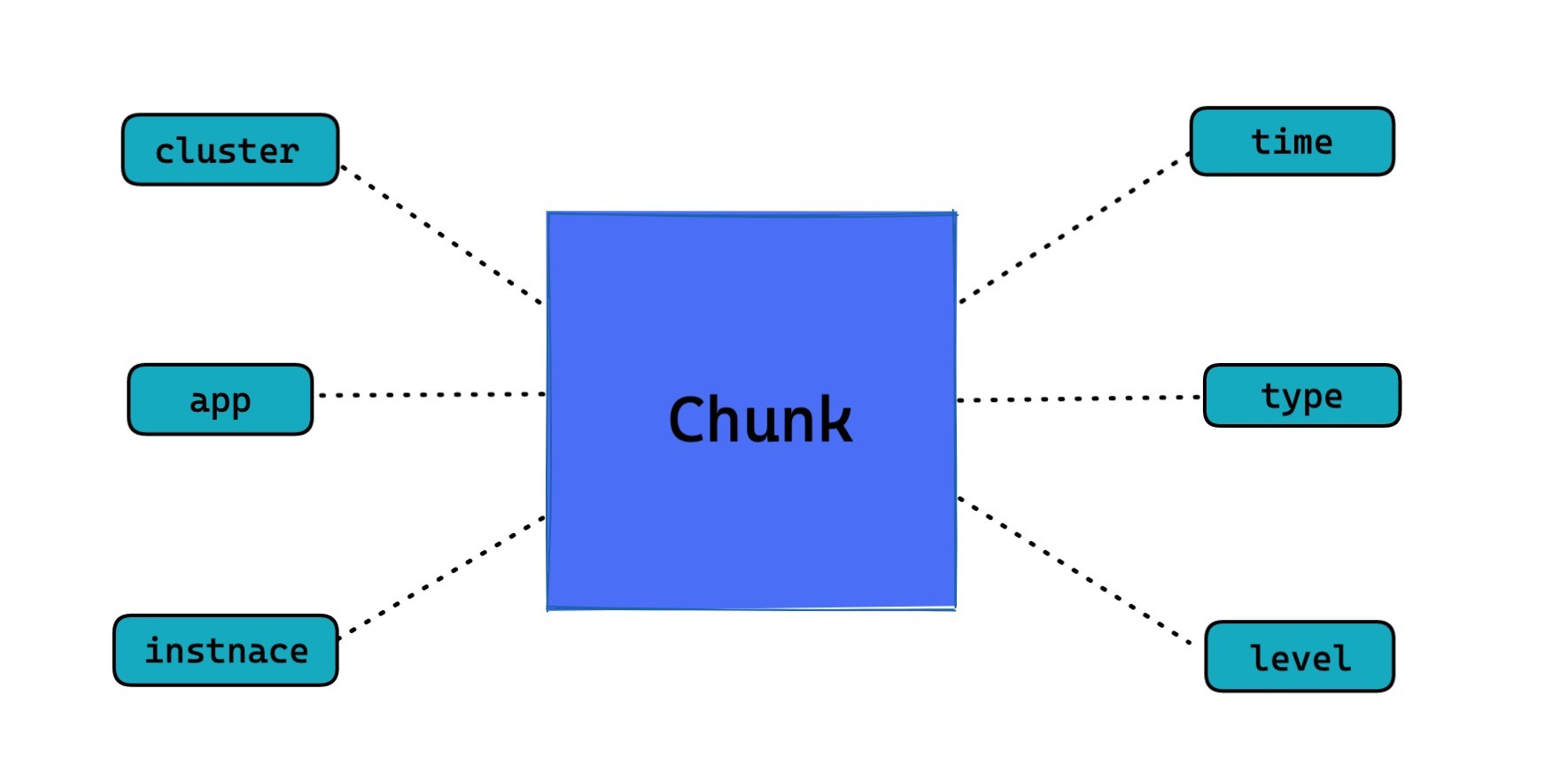
索引的結構可以按需構建, 你可以將你關心的元資料資訊放入到索引中, 從而方便快速圈定需要的日志塊,因為我們只對日志塊的元資料做了索引, 相比于對全部日志建立索引, 這個成本可以說降到了極低, 鎖定日志塊的速度也足夠理想,
日志生命周期與資料沉降
日志資料以時間維度的方向可以理解為一種時序資料, 離當前時間越近的日志會越有價值, 被查詢的可能性也會越高, 呈現一種冷熱分離的情況,而且冷資料也并非是毫無價值,開發人員要求回溯幾個月前的日志資料也是存在的場景, 即我們的日志需要在其生命周期里都能夠對外提供查詢能力,
對于這種情況,如果將生命周期內的所有日志塊都保存在本地磁盤上, 無疑是對我們的機器容量提了很大的需求,對于這種日志存盤上的需求,我們可以采用壓縮和沉降的手段來解決,
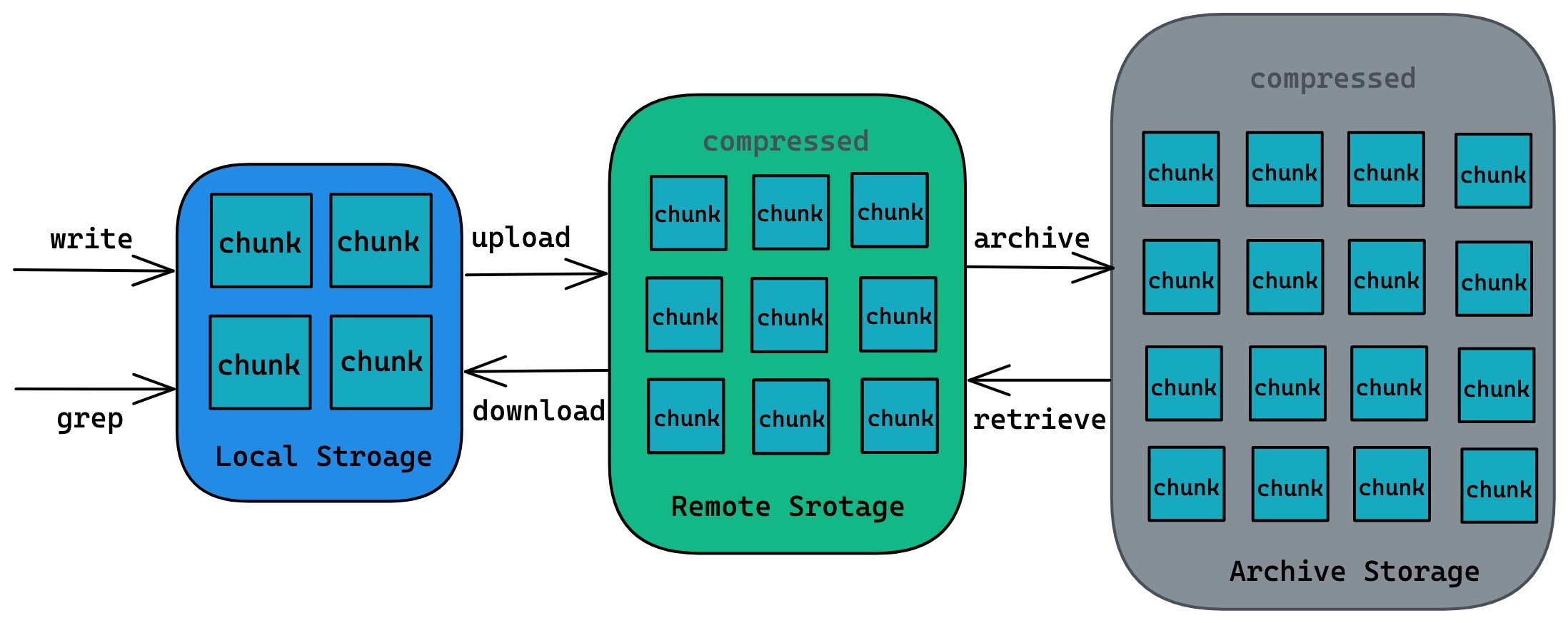
簡單來說,我們將日志塊存盤分為本地存盤(磁盤)、遠程存盤(物件存盤)、歸檔存盤三個級別; 本地存盤負責提供實時和短期的日志查詢(一天或幾個小時), 遠程存盤負責一定時期內的日志查詢需求(一周或者幾周), 歸檔存盤負責日志整個生命周期里的查詢需求,
現在我們看看日志塊在其生命周期里是如何在多級存盤間流轉的, 首先日志塊會在本地磁盤創建并寫入對應的日志資料, 完成后會在本地磁盤保留一定時間(保留的時間取決于磁盤存盤壓力), 在保存一定時間后, 它首先會被壓縮然后被上傳至遠程存盤(一般是物件存盤中的標準存盤型別), 再經過一段時間后日志塊會被遷移到歸檔存盤中保存(一般是物件存盤中的歸檔存盤型別).
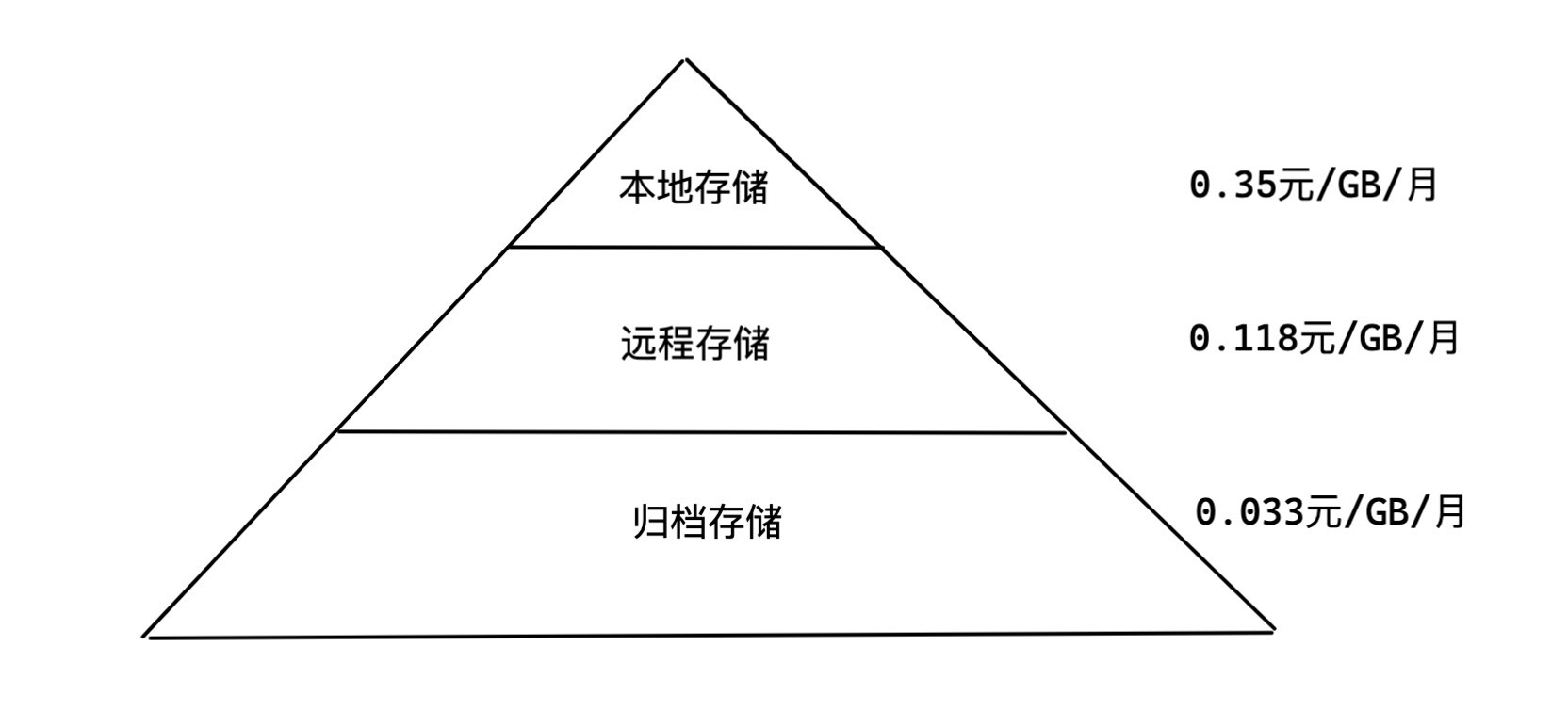
這樣的存盤設計有什么好處呢? 如下面的多級存盤示意圖所示, 越往下存盤的資料量越大, 存盤介質的成本也越低, 每層大概為上一層的 1/3 左右, 并且資料是在壓縮后存盤的, 日志的資料壓縮率一般可以達到10:1, 由此看歸檔存盤日志的成本能在本地存盤的1%的左右, 如果使用了 SSD 硬碟作為本地存盤, 這個差距還會更大,
價格參考:
| 存盤介質 | 參考鏈接 |
|---|---|
| 本地盤 | https://buy.cloud.tencent.com/price/cvm?regionId=8&zoneId=800002 |
| 物件存盤 | https://buy.cloud.tencent.com/price/cos |
| 歸檔存盤 | https://buy.cloud.tencent.com/price/cos |
那在多級存盤間又是如何檢索的呢? 這個很簡單, 對于本地存盤上的檢索, 直接在本地磁盤上進行即可,
如果檢索涉及到遠程存盤上的日志塊, 檢索服務會將涉及到的日志塊下載到本地存盤, 然后在本地完成解壓和檢索,因為日志分塊的設計,日志塊的下載同檢索一樣,我們可以在多臺機器上并行操作; 下載回本地的資料復制支持在本地快取后一定的時間后再洗掉, 這樣有效期內對同一日志塊的檢索需求就可以在本地完成而不需要再重復拉取一遍(日志檢索場景里多次檢索同樣的日志資料還是很常見).
對于歸檔存盤, 在發起檢索請求前, 需要對歸檔存盤中的日志塊發起取回操作, 取回操作一般耗時在幾分鐘左右, 完成取回操作后日志塊被取回到遠程存盤上,再之后的資料流轉就跟之前一致了,即開發人員如果想要檢索冷資料, 需要提前對日志塊做歸檔取回的申請,等待取回完成后就可以按照熱資料速度來進行日志檢索了,
檢索服務架構
在了解上面的設計思路后, 我們看看基于這套設計的日志檢索服務是怎么落地的.
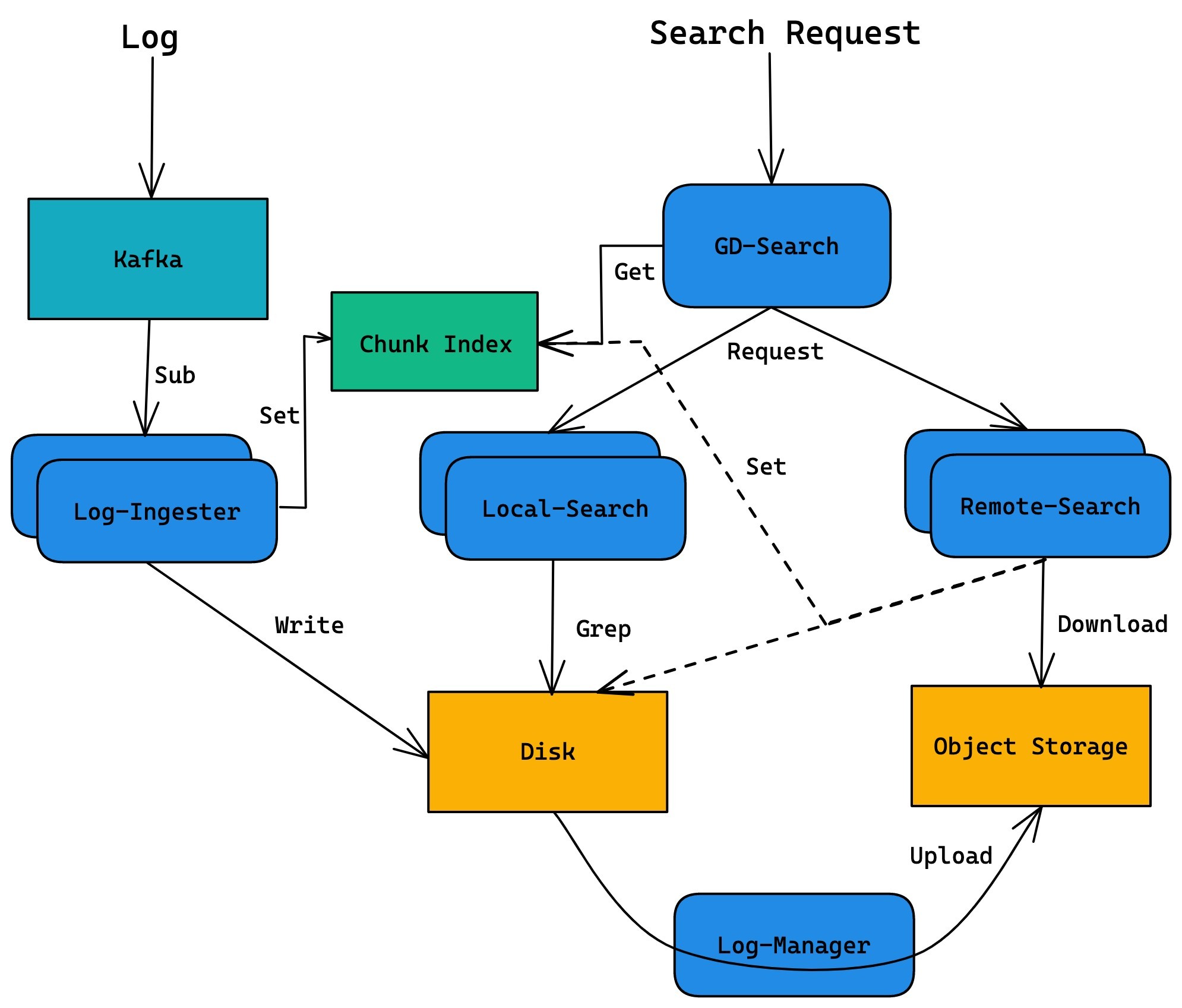
日志檢索服務分為以下幾個模塊:
- GD-Search
? 查詢調度器, 負責接受查詢請求, 對查詢命令做決議和優化, 并從 Chunk Index 中獲取查詢范圍內日志塊的地址, 最終生成分布式的查詢計劃
? GD-Search 本身是無狀態的, 可以部署多個實體,通過負載均衡對外提供統一的接入地址,
- Local-Search
? 本地存盤查詢器, 負責處理 GD-Search 分配過來的本地日志塊的查詢請求,
- Remote-Search
? 遠程存盤查詢器, 負責處理 GD-Search 分配過來的遠程日志塊的查詢請求,
? Remote-Search 會將需要的日志塊從遠程存盤拉取到本地并解壓, 之后同 Local-Search 一樣在本地存盤上進行查詢,同時 Remote-Search 會將日志塊的本地存盤地址更新到 Chunk Index 中,以便將后續同樣日志塊的查詢請求路由到本地存盤上,
- Log-Manager
? 本地存盤管理器,負責維護本地存盤上日志塊的生命周期,
? Log-Manager 會定期掃描本地存盤上的日志塊, 如果日志塊超過本地保存期限或者磁盤使用率到達瓶頸,則會按照策略將部分日志塊淘汰(壓縮后上傳到遠程存盤, 壓縮演算法采用了 ZSTD), 并更新日志塊在 Chunk Index 中的存盤資訊,
- Log-Ingester
? 日志攝取器模塊, 負責從日志 kafka 訂閱日志資料, 然后將日志資料按時間維度和元資料維度拆分, 寫入到對應的日志塊中,在生成新的日志塊同時, Log-Ingester 會將日志塊的元資料寫入 Chunk Index 中, 從而保證最新的日志塊能夠被實時檢索到,
- Chunk Index
? 日志塊元資料存盤, 負責保存日志塊的元資料和存盤資訊,當前我們選擇了 Redis 作為存盤介質, 在元資料索引并不復雜的情況下, redis 已經能夠滿足我們索引日志塊的需求, 并且基于記憶體的查詢速度也能夠滿足我們快速鎖定日志塊的需求,
檢索策略
在檢索策略設計上, 我們認為檢索的回傳速度是追求更快, 同時避免巨大的查詢請求進入系統,
我們認為日志檢索一般有以下三種場景:
-
查看最新的服務日志,
-
查看某個請求的日志, 依據 logid 來查詢,
-
查看某類日志, 像訪問 mysql 的錯誤日志, 請求下游服務的日志等等,
在大部分場景下, 用戶是不需要所有匹配到的日志, 拿一部分日志足以處理問題,所以在查詢時使用者可以設定 limit 數量, 整個檢索服務在查詢結果滿足 limit設定的日志數量時, 終止當前的查詢請求并將結果回傳給前端,
另外 GD-Search 組件在發起日志塊檢索時, 也會提前判斷檢索的日志塊大小總和, 對于超限的大范圍檢索請求會做拒絕,(用戶可以調整檢索的時間范圍多試幾次或者調整檢索陳述句使其更有選擇性)
性能一覽
使用 1KB 每條的日志進行測驗, 總的日志塊數量在10000左右, 本地存盤使用 NVME SSD 硬碟, 遠程存盤使用 S3 協議標準存盤.
? 寫入
? 單核可支持 2W條/S的寫入速度, 1W 條/S的寫入速度約占用 1~2G 左右的記憶體,可分布式擴展,無上限
? 查詢(全文檢索)
? 基于本地存盤的 1TB 日志資料查詢速度可在 3S 以內完成
? 基于遠程存盤的 1TB 日志資料查詢耗時在 10S 間,
成本優勢
在每秒千萬級寫入,百 PB 存盤上,我們使用十幾臺物理服務器就可以保證日志寫入和查詢,熱點資料在本地 nvme 磁盤上,次熱資料在物件存里,大量日志資料存盤在歸檔存盤服務上,
計算對比
? 因為不需要建立索引,我們只需要千核級別就可以保證寫入,同時日志索引是個寫多讀少的服務,千核可以保證百級別 QPS 查詢,
? ES 在這個量級上需要投入幾萬核規模,來應對寫入性能和查詢瓶頸,但是仍不能保證寫入和查詢效率,
存盤對比
? 核心是在保證業務需求下,使用更便宜的存盤介質(歸檔存盤 VS 本地磁盤)和更少的存盤資料(壓縮率 1/10vs 日志資料索引膨脹),能有兩個量級的差距,
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/397188.html
標籤:其他
上一篇:MCU變數加載程序