前言
本文介紹了MySQL的索引和事務,如果你恰好對這方面的知識不了解的話,那么來看看本文吧!!
一、索引
1.1 概念
索引是一種特殊的檔案,包含著對資料表里所有記錄的參考指標,可以對表中的一列或多列創建索引,并指定索引的型別,各類索引有各自的資料結構實作,(具體細節在后續的資料庫原理課程講解)
通俗的講:我們一本書,最開始有目錄,通過目錄可以看見相關的情況,比如可以看見有多少個章節,每個章節的大概內容,mysql 的索引也是差不多的,
1.2 索引的作用及核心思想
- 資料庫中的表、資料、索引之間的關系,類似于書架上的圖書、書籍內容和書籍目錄的關系,
- 索引所起的作用類似書籍目錄,可用于快速定位、檢索資料,
- 索引對于提高資料庫的性能有很大的幫助,
那這個索引有什么用呢??
我們都知道mysql查找主要是select
select基本執行程序,遍歷表,依次取出每個記錄,根據where字句的條件,決定這個記錄要保留還是過濾,像這樣的遍歷操作,本身是比較低效的(尤其是資料量很大的時候)
為什么特別低效呢?因為把資料存盤在硬碟上的,取出每個記錄(這個操作都意味訪問硬碟) 相比之下,我們更希望訪問硬碟的次數盡量少,
怎么樣才可以更高效的訪問呢?如何提高查找速度,這里就要提到資料結構了,資料庫本質上也是基于資料結構來實作的,想要提高查找速度,就需要一些的資料結構來輔助:那么我們要來挑選一個
1.二叉搜索樹
二叉搜索樹,時間是O(N),因為要一個個遍歷,還是比較低效的,雖然說可以提高速度,但是具體提高多少還是要看那一顆樹了,也有可能是單支樹,為了進一步改進引入AVL樹
2.AVL樹
AVL本質上是一顆二叉平衡搜索樹,什么叫做平衡呢?
平衡:對于這個樹的任意節點來說,左子樹的高度減去右子樹的高度絕對值小于等于1
避免出現單支樹,保證了查找效率
但是這里會有新的問題出現: 如果這樣設定的話,意味著隨著插入/洗掉的元素的進行,這個AVL樹規則就可能被破壞掉,就隨時的調整樹的結構~,保證這個樹始終符合AVL樹的要求,
(調整操作就非常頻繁了,此時這個樹插入洗掉操作就低效了)
3 .紅黑樹
為什么進一步的改進AVL樹,讓查找,插入,洗掉能比較均衡又引入了紅黑樹,
本質上是一個放松規則的AVL樹,也要求讓這個二叉搜索樹平衡,但是沒有要求的那么嚴格,(這里的規則更寬松,從而就能保證觸發調整的情況沒有那么頻繁) ,雖然查找可能比AVL樹稍微遜色一點,但是差異不大,同時能夠保證插入和洗掉效率更高,在之間取得一個平衡的點,因為它的插入查找洗掉都是O(logN)
4.哈希表
哈希表相對于上面介紹的資料結構,還是要強一點的,它的插入查找洗掉時間復雜度,都是O(1),主要是借助了,陣列去下標的“隨機訪問能力”(非常高效),把保存的key轉換成陣列下標,保存到對應的位置上,下次查找也是先把key轉成下標,直接去下標就可以了~
- 雖然說哈希表有哈希沖突問題但是我們也有解決辦法:
- 1)掛鏈表的方式
- 2)往后找一個空位的方式(線性探測 / 二次探測)
如果索引使用哈希表來做,可以行嗎?
可行:確實可以提高查找速度
不可行:其實還存在很大的局限性
為什么說不可行:
一個哈希表要想查詢,有一個關鍵的事情,必須要比較“相等”,哈希表的查詢時候,只能查某個key==具體值,這樣的情況~但是我們SQL中存在很多的查詢, 比如一些條件,正因如,我們在標準庫的HashMap的時候,要求key的型別,必須提供"比較相等(equals)”這樣的方法實作,
5.紅黑樹
紅黑樹就是普通二叉樹的升級版,其實也不太可行,紅黑樹查找效率直接就是由樹的高度決定的~(高度也就相當于比較次數),由于樹是二叉的,當元素增加很多之后,高度也會隨之增加不少,紅黑樹壞事就在于它是二叉樹,拋開二叉樹不說進行范圍比較還是可以的
其實,mysql的索引最常用的資料結構,其實就是一個N叉搜索樹!! 每一個有很多子節點,使用N叉的目的就是能減少高度~ 高度低了,此時查找時候的比較次數就少了,磁盤io也少了,效率就高了 ,
6.B樹
MySQL中的索引,其中最常用的結果是B+樹(B+樹就是一種特殊的N叉搜索樹)
要想理解b+樹,先了解B樹(B樹是B加樹的前身,B+樹就是改進版的B樹)
B樹也是一個N叉搜索樹~(B樹在有的資料叫做 B-樹,就是B樹,不叫B減樹)
來大概看看B樹是什么樣的:
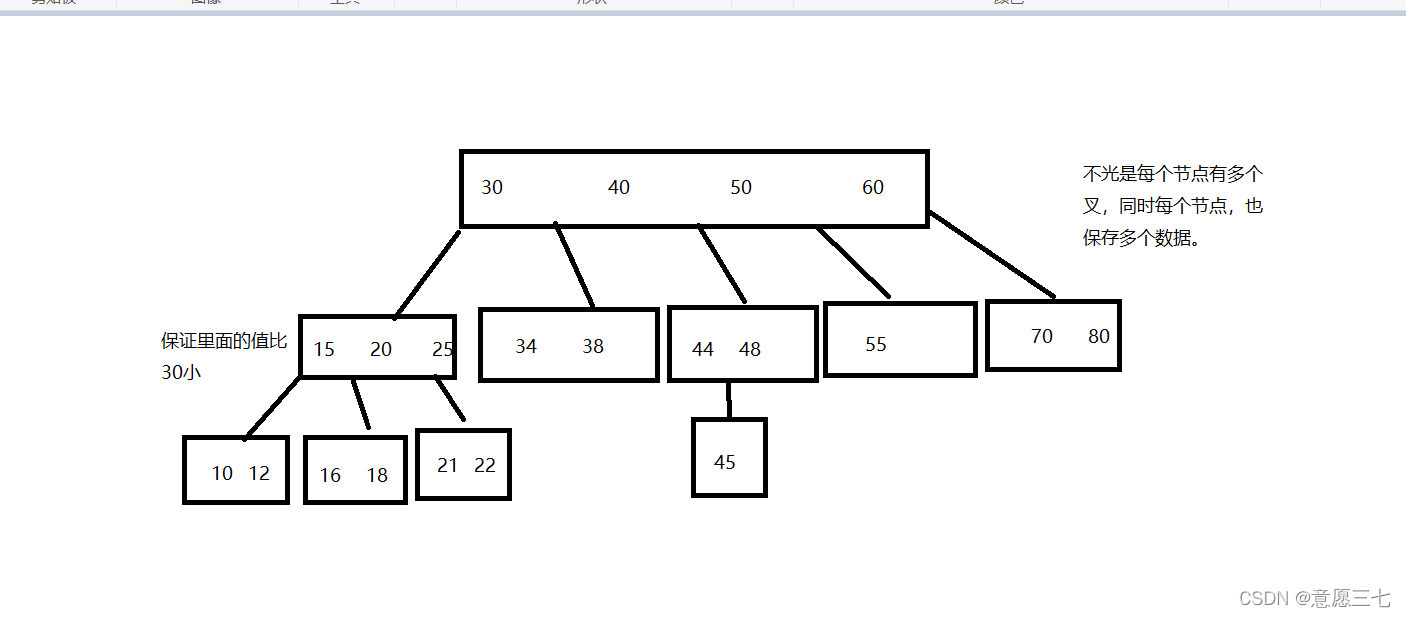
B樹的特點:
- N叉搜索樹,每個節點可能會包含N個子樹
- 每個節點上存在多個值
- 保證類似“二叉搜索樹”一樣的規則(左子樹,小于根節點,小于右子樹)
來一個流程:
例如:查找一個元素,22
先拿22去跟根節點比較,根節點之間,發現22比30小,于是從最左側第一個叉出來,繼續往下找
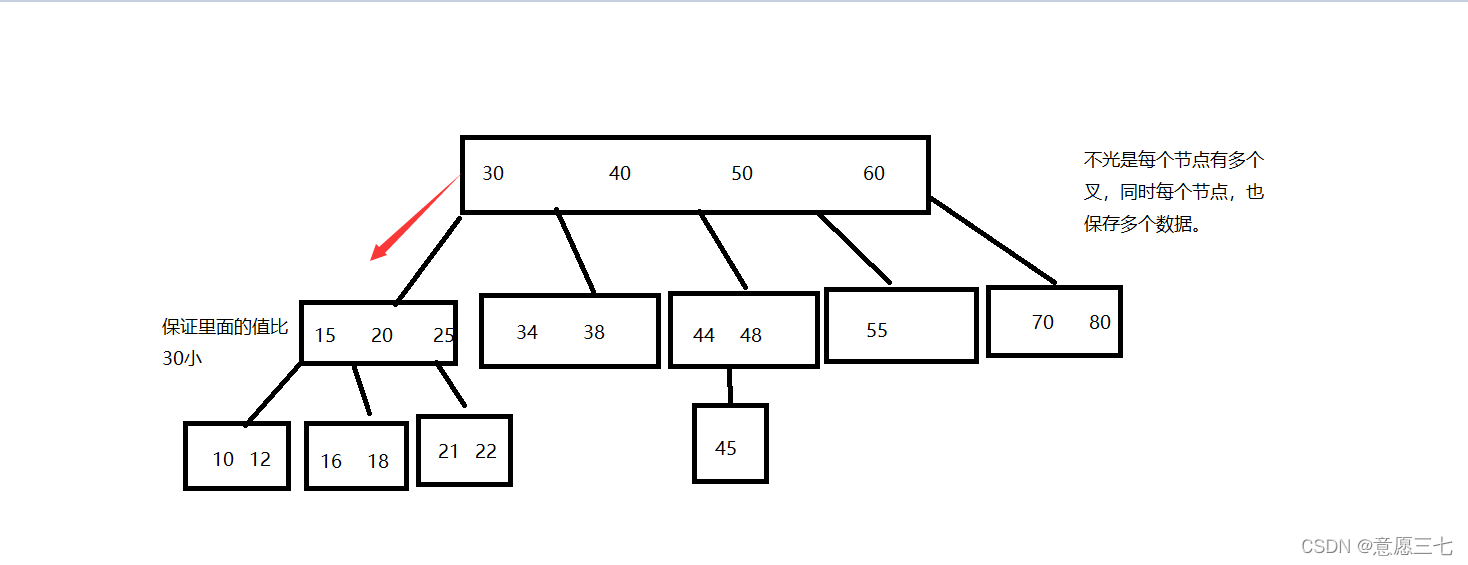
在拿22去和15,20,25這個節點對比,我們就知道22在20 和25之間
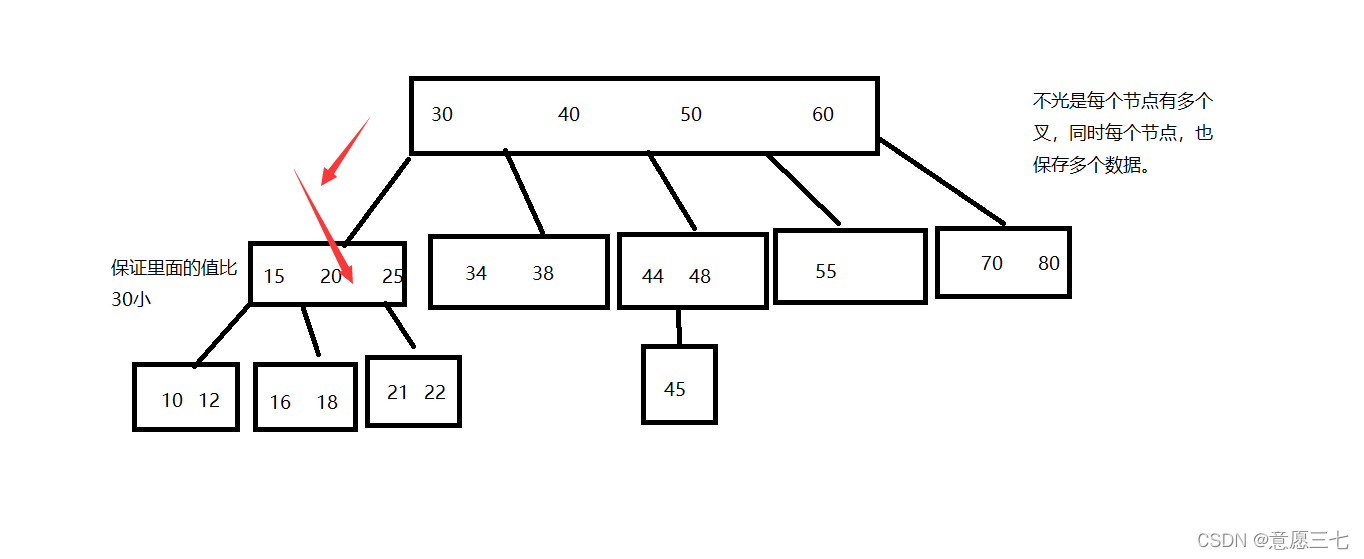
因此就從這個節點的第三個叉,繼續往下走,接下來拿22去和“21 ,22 ” 這個節點進行比較,查找和二叉搜索樹差不多,不過我們把高度變低了,B樹當我們的索引其實挺合適的,不過我們還可以改進空間,引入B+樹,
7.B+樹
B+樹做出的改變:這里大家看見看見重復了最后也是一個8,大家別急著說浪費空間,可能也是一個改進
我們繼續完成這樹:下面使用鏈表連接
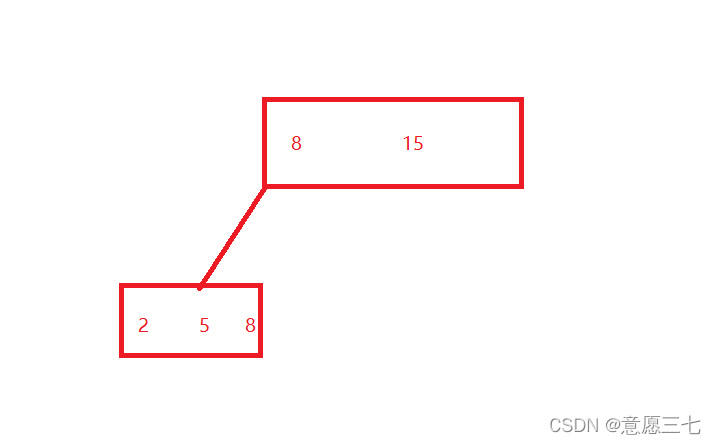
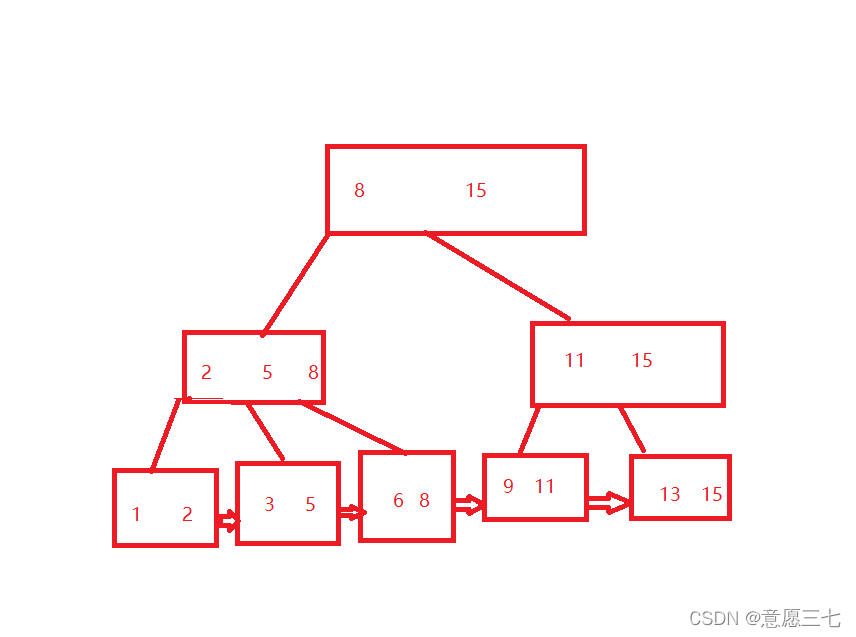
這個B+樹和B樹相比,最明顯的變化就是兩個方面:
- 非葉子節點的值,可能會存在重復的,就可以保證最終的葉子節點的一層,就是完整的資料集合~
- 通過類似于鏈表這樣的方式,把所有的葉子節點按照順序,連接起來~
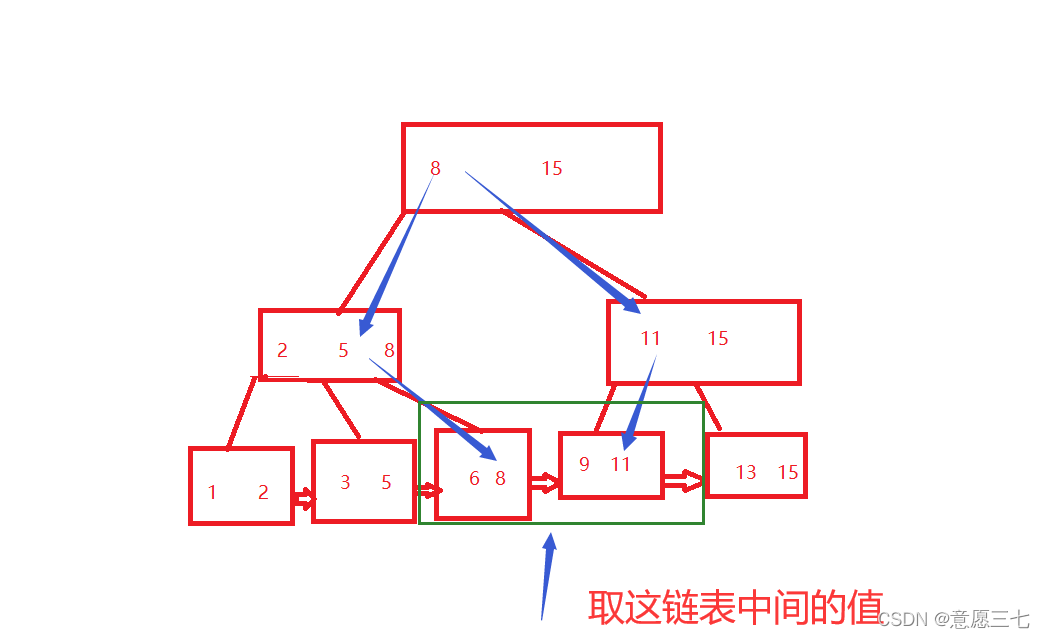
B+樹的優勢:
-
非常擅長“范圍查找” 例如查一個ID<=11 and ID >=6
我們拿著這兩個邊界值去,分別去找兩個邊界值的位置比如 6 9,然后遍歷鏈表比較方便 :
那么我們和B樹相比,我們來看看B樹的弊端: 比如我們兩個數,我們不知道哪里是中間元素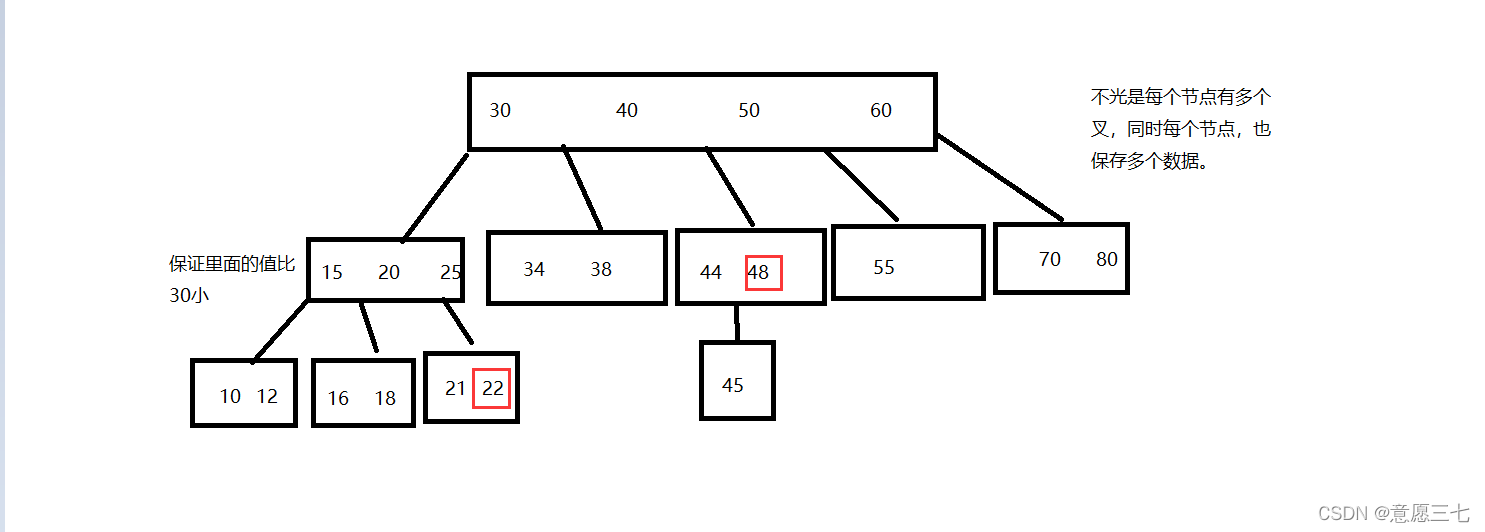
-
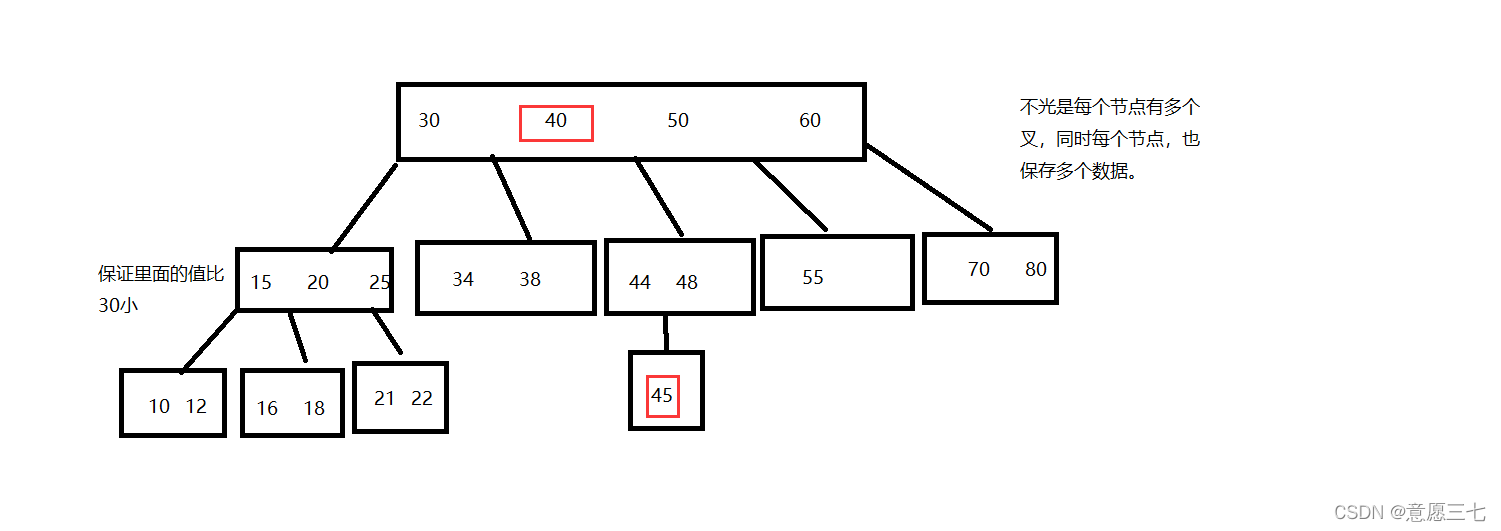
所有的查詢最終都是落在葉子節點上,查詢速度是比較穩定的.
比如B樹,我們找找40 45 一個40 一開始馬上找到,一個45還要遍歷就比40要慢,所以不太穩 定,我們B+樹的查詢還是比較穩定的,
-
由于葉子節點是資料的全集,因此可以把葉子節點存在硬碟上,非葉子節點直接存在記憶體中,又大大降低了讀取硬碟的次數嗎,怎么理解這個話呢?
我們要知道每一個節點不只就一個記錄,可能一行里面有許多資訊,如果像B樹那樣全部存在硬碟上,才存的下,相比B+樹,我們只在它的葉子節點存全部資訊,非葉子節點只存部分資訊,這個時候非葉子節點整體的空間就少了很多了,在記憶體也可以存下來,這個是B+樹的大殺器,我們把ID這樣的重要資訊存在記憶體,把全部資訊存在硬碟,這樣我們的重復還是很有必要的
1.3 使用場景
我們使用索引,最主要的還是來查詢,要考慮對資料庫表的某列或某幾列創建索引,需要考慮以下幾點:
- 資料量較大,且經常對這些列進行條件查詢,
- 該資料庫表的插入操作,及對這些列的修改操作頻率較低,
- 索引會占用額外的磁盤空間
- 當然不是說我們什么時候都可以使用索引,新增洗掉修改多,查找比較少,索引就不太合適,但是這種 查多,修改少的場景我們也是非常常見的,因此索引的用處還是特別多的,像我們去一個論壇,我們大多數是在查看,而不是去進行修改 洗掉操作,
- 索引本身也是占劇一定空間的,如果磁盤空間充裕那還好,如果磁盤空間非常緊張,那就不太適合使用索引了,
- 建立索引,是指定某個列來建立的,就是要求這個索引列,得是“區分度比較大的”,這個時候才適合制作索引~~ 類似于 自增主鍵 ,這種就比較時適合做索引,類似于“性別”這樣的列就不合適做索引 ,因為要么男,要么女,區分度很小,非常不適合做索引
滿足以上條件時,考慮對表中的這些欄位創建索引,以提高查詢效率,
反之, 如果非條件查詢列,或經常做插入、修改操作,或磁盤空間不足時,不考慮創建索引,
1.4 使用
創建主鍵約束(PRIMARY KEY)、唯一約束(UNIQUE)、外鍵約束(FOREIGN KEY)時,會自動創建對應列的索引,
- 查看索引
show index from 表名;
案例:查看學生表已有的索引
show index from student;
-
創建索引
對于非主鍵、非唯一約束、非外鍵的欄位,可以創建普通索引
create index 索引名 on 表名(欄位名);
案例:創建班級表中,name欄位的索引
create index idx_classes_name on classes(name);
- 洗掉索引
drop index 索引名 on 表名;
案例:洗掉班級表中name欄位的索引
drop index idx_classes_name on classes;
其實上面這些沒有太多好講的,我們來看一個其他的知識點
聚簇索引 和 非聚簇索引
主要描述是mysql底層是如何組織資料的
-
聚簇索引: 資料本身就是通過B+樹的方式來組織的,比如B+樹的每一個葉子節點存一個完整的記錄就是聚簇索引
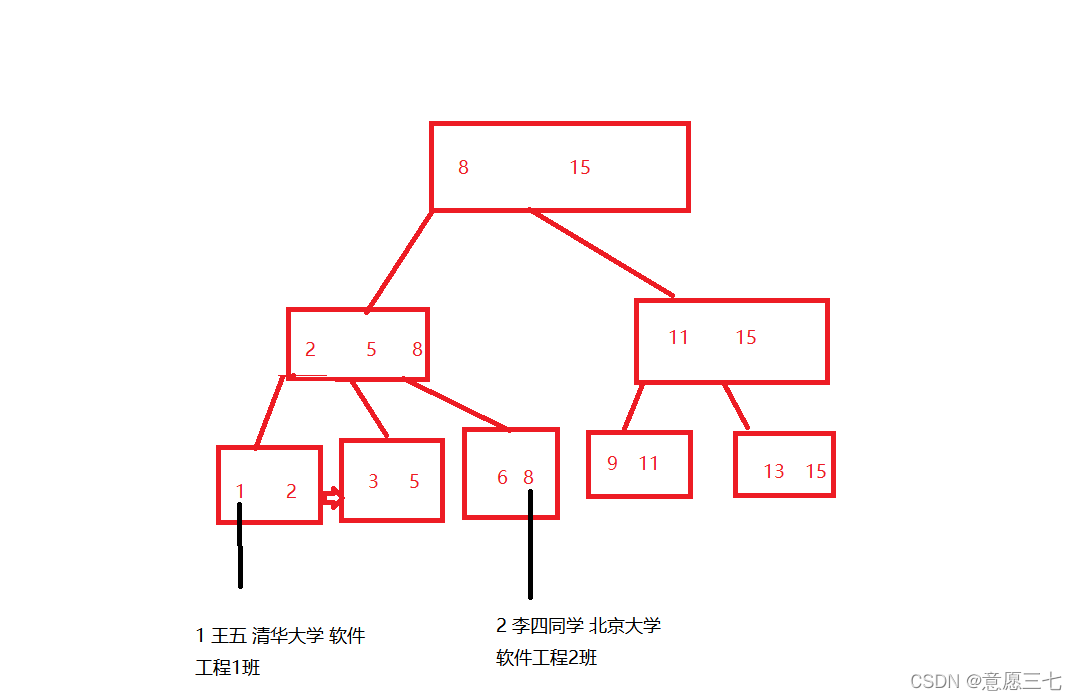
-
非聚簇索引: 先通過 一個"表”這樣的結構,把所有的資料都裝進去~

然后我們B+樹還存在只是這個時候不存全部資料了,而是存行號,我們通過B+樹,1 這條記錄在表中的行號對應的是 王五 清華大學 這個條資料,這就叫做非聚簇索引
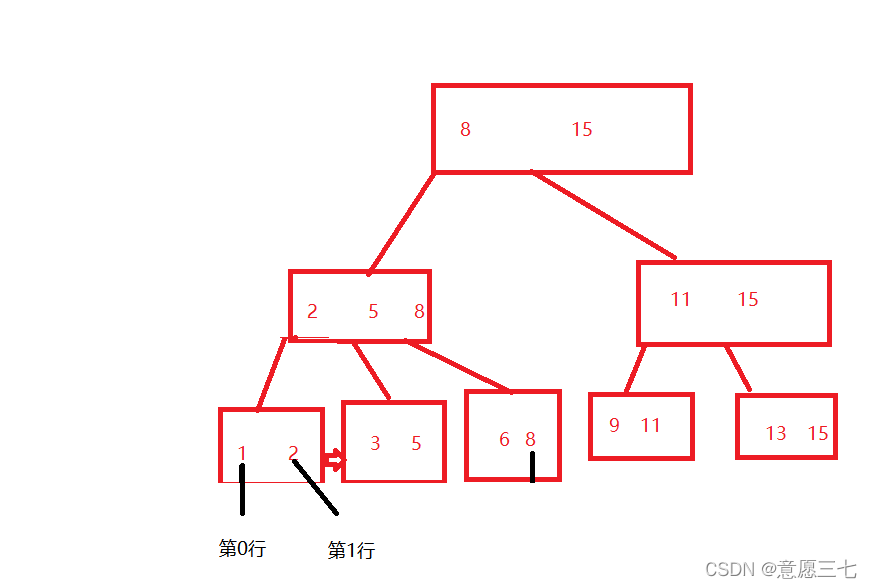
這個兩種索引,不能說誰好誰壞,只能說看應用的場景, 一般聚簇索引要更加高效一點,為什么呢,因為非聚簇索引還要查一次表,不過非聚簇索引產生的硬碟垃圾更少~
索引的結構最主要的還是B+樹,但是不是說只有B+樹,MySQL支持多種不同的“存盤引擎”,組織資料使用的資料結構都會存在差異嗎,同時索引結構也會存在差異~
二、事務
2.1 介紹事務
事務其實不僅僅是資料庫中的概念,是屬于計算機中一個非常廣泛的概念,主流資料庫也是都是對事務是有一定的支持的,
我們來舉個事務的列子,倒垃圾:
家里有垃圾桶 ,套一個塑料袋,垃圾往袋子里面丟,垃圾滿了就可以把這個袋子一拎,就可以丟了,我們的每一步是有程序的
- 把裝滿的袋子拎出來
- 再套一個新袋子
這兩步我們應該一氣呵成,這樣方便我們接下來的使用, 我們把多個動作,打包成為一個整體的操作,就稱為事務!
上面的這樣的操作其實沒有一起完成沒有關系,我們來看一下下面一個 銀行轉賬:
如果這個操作沒有一起,那么會產生尷尬的情況!這樣的打包一起也是事務!
事務特點有下面3個情況:
1.原子性
事務最核心的特點,就是把一系列操作打包在一起 ,構成一個整體,這個整體,要么全部完成,要么一個不做,不會出現“做了一半,另一半沒有做的情況”,這個情況稱為 原子性
思考:這個原子性是如何保證的呢???
A轉賬B 500
- A的賬戶減500
- B的賬戶加500
如果我們在轉賬執行第1步成功了,開始執行第二步的時候,資料庫 或者程式崩潰那么怎么辦呢?
其實我們這里有個叫做回滾(rollback)的一個機制,就是要么一樣不做,指的不是說真的沒做,而是把做了的中間狀態,給偷偷還原回去了, 回滾針對每個進行的操作,都記住干啥了~保證不會出現中間狀態,
2 .一致性
執行事務之前,和 執行事務之后,當前表里面的資料都是合理的狀態~~ 比如不可以出現-400這樣的數字
3.持久性
事務操作的資料都是直接操作硬碟,硬碟的資料都是持久化存盤的.(資料只要改了,那么就會一直存在,就不會說重啟了就沒了)
4.隔離性
一個事務的執行不能被其他的事務執行,即一個事務的內部操作及使用的資料對其他并發事務是隔離的,并發執行的各個事務之間不能互相干擾,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/397344.html
標籤:其他