人工智能導論期末復習合集
AI導論知識點目錄
- 人工智能導論期末復習合集
- 〇、緒論
- 一、知識的概念
- 練習題
- 二、基本搜索
- 2.1 狀態空間法
- 2.2 無資訊搜索
- 2.2.1 寬度優先搜索【佇列】
- 2.2.2 深度優先搜索【堆疊】
- 2.2.3 一致代價搜索【優先佇列】
- 練習題
- 2.3 啟發式搜索
- 2.3.1 貪婪搜索【優先佇列】
- 2.3.2 A*搜索【優先佇列】
- 總結
- 練習題
- 三、約束滿足問題
- 3.1 回溯法
- 3.2 排序策略
- 3.2.1 最少可取值
- 3.2.2 度啟發式
- 3.2.3 最少約束值
- 3.3 推理策略
- 3.3.1 約束傳播-區域相容性
- 3.3.2 智能回溯
- 3.3.3 前向檢查
- 3.4 問題結構特性
- 3.4.1 樹狀約束滿足問題-圖轉樹
- 練習題
- 3.5 區域搜索
- 3.5.1 爬山法
- 改進爬山法
- 3.5.2 模擬退火
- 3.5.3 區域束搜索
- 3.5.4 遺傳演算法
- 練習題
- 四、對抗搜索
- 4.1 Minimax
- 4.2 Alpha-Beta剪枝
- 4.3 優化
- 練習題
- 五、貝葉斯推理
- 5.1 推理(參考離散數學)
- 5.2 貝葉斯推理(概率論與數理統計回顧)
- 練習題
- 六、專家系統
- 6.1 基本概念
- 練習題
- 七、機器學習
- 7.1 機器學習概述
- 7.2 相關問題
- 7.3 研究內容
- 有監督學習
- 無監督學習
- 半監督學習
- 研究內容
- 7.4 基本概念
- 假設空間
- 模型評估與選擇
- 資料集的劃分
- 性能度量
- 練習題
- 八、維度約簡
- 8.1 概述
- 8.2 特征選擇(不考)
- 過濾式
- 包裹式
- 嵌入式
- 8.3 互資訊特征選擇
- 練習題
- 九、深度學習緒論
- 9.1 神經網路基礎
- 9.2 經典神經網路
- 9.3 卷積神經網路
- 十、集成學習
- 10.1 集成學習基礎
- 10.2 個體生成
- 集成學習主要問題
- 個體生成
- AI導論總結
〇、緒論
重點:人工智能定義、人工智能研究內容(了解、理解即可)
一、知識的概念
重點:知識的概念、知識的表示
知識是人們在長期的生活及社會實踐中、在科學研究及實驗中積累起來的對客觀世界的認識與經驗,
知識的形式:事實、因果關聯
知識的特性:相對正確性(明確前提)、不確定性(真偽之外)、可表示性(形式描述)、可利用性(學以致用)
練習題
- 知識的概念

二、基本搜索
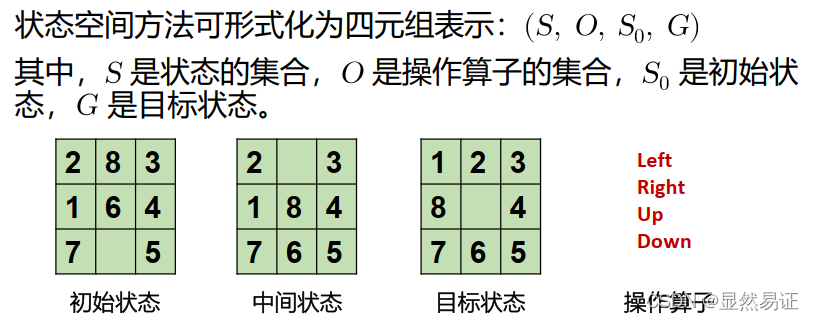
2.1 狀態空間法
· 狀態:表示問題解法中每一步問題狀況的資料結構
· 操作:狀態變換的手段
· 狀態空間:表示問題全部可能狀態及其關系的圖
· 狀態空間的解:從初始狀態到目標狀態的操作算子序列
2.2 無資訊搜索
只按預定的控制策略進行搜索,在搜索程序中獲得的中間資訊不會用來改進控制策略,
每個節點的分支數為b,最淺解位于第s層,搜索空間共m層,
2.2.1 寬度優先搜索【佇列】
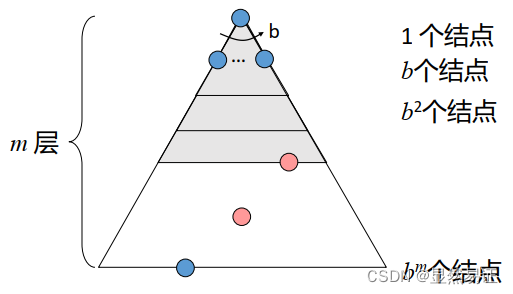
時間復雜度:O( b s b^s bs)
空間復雜度:O( b s b^s bs)
具有完備性、最優性
2.2.2 深度優先搜索【堆疊】
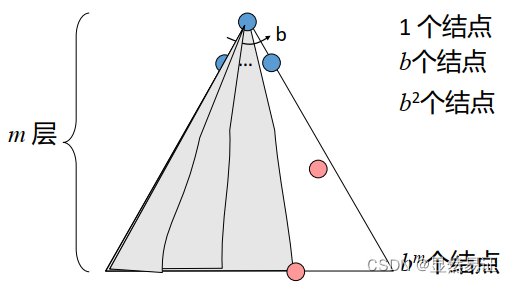
時間復雜度:O( b m b^m bm)
空間復雜度:O( b m bm bm)
可能不具有完備性(圖有環時需進行約束)、不具有最優性(最左的解)
2.2.3 一致代價搜索【優先佇列】
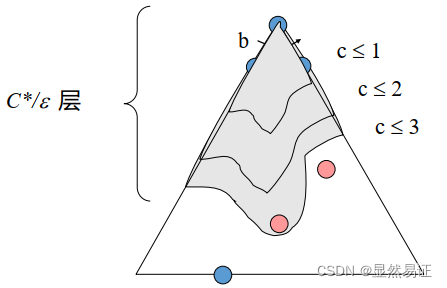
解代價為
C
?
C^*
C?,邊最小代價為
ε
ε
ε
時間復雜度:O( b C ? / ε b^{C^*/ε} bC?/ε)
空間復雜度:O( b C ? / ε b^{C^*/ε} bC?/ε)
具有完備性、最優性
練習題
- 一致代價搜索的終止條件:
- 無資訊搜索
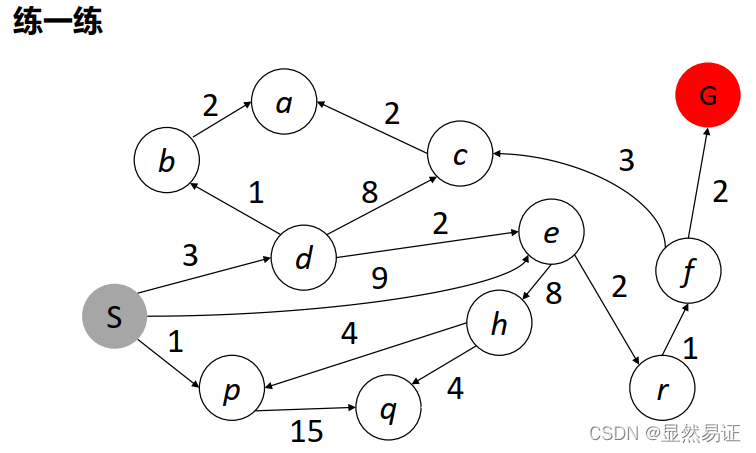
2.3 啟發式搜索
在搜索中加入了與問題有關的啟發性資訊,用于指導搜索朝著最有希望的方向進行,加速問題的求解程序并找到最優解,
2.3.1 貪婪搜索【優先佇列】
搜索策略: 拓展看起來離目標最近的節點
評估函式:
f
(
n
)
=
h
(
n
)
f(n)=h(n)
f(n)=h(n)【
h
(
n
)
h(n)
h(n)表示從
n
n
n節點到目標節點最佳路徑的估計代價】
最壞情況下退化為DFS,時間復雜度為O( b m b^m bm)
空間復雜度:O( b m b^m bm)【存盤所有節點的資訊】
不具有完備性和最優性
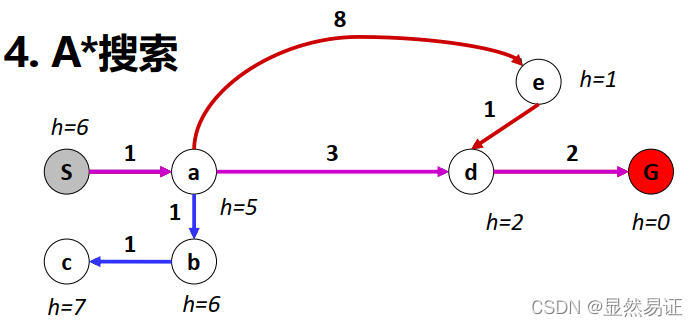
2.3.2 A*搜索【優先佇列】
搜索策略: 避免拓展耗費已經很大的路徑
評估函式:
f
(
n
)
=
g
(
n
)
+
h
(
n
)
f(n)=g(n)+h(n)
f(n)=g(n)+h(n)【g(n)表示初始節點到n節點的實際代價、h(n)表示估計代價】
- 可納性
如果對任意節點 𝑛 𝑛 n, h ( n ) ≤ h ? ( n ) h(n)≤h^*(n) h(n)≤h?(n)成立, 則啟發式函式是可納的(admissible), 其中, h ? ( n ) h^*(n) h?(n)是結點 𝑛 𝑛 n到目標狀態的真實代價,
定理:若 h ( n ) h(n) h(n)可納,則A*搜索演算法具有最優性,
- 一致性(一致->可納)
若對于任意節點 n n n和通過操作 a a a生成的后續節點 n ′ n' n′,則 h ( n ) ≤ c o s t ( n , a , n ′ ) + h ( n ′ ) h(n)≤cost(n,a,n')+h(n') h(n)≤cost(n,a,n′)+h(n′)成立,則啟發式函式是一致的
定理:若 h ( n ) h(n) h(n)一致,則A*搜索演算法具有最優性,
-
優勢性
對于任意節點 n n n,可納啟發式函式 h 1 ( n ) < h 2 ( n ) h_1(n)<h_2(n) h1?(n)<h2?(n) ,稱 h 2 h_2 h2?優于 h 1 h_1 h1? -
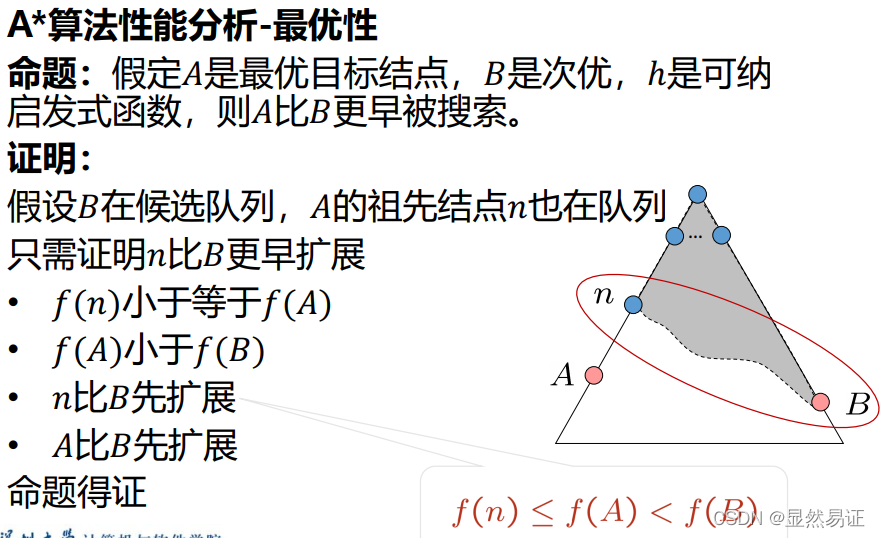
最優性
假設A是最優目標節點,B是次優節點,則A比B更早被搜索,
-
A*演算法性能分析
b b b表示每個節點的后繼節點數, d d d表示解的深度, ε ε ε表示相對誤差 h ? ? h h ? \frac{h^*-h}{h^*} h?h??h? , h ? h^* h?為真實代價, h h h為估計代價
最壞時間復雜度:O( b ε d b^{εd} bεd)
空間復雜度:O( b m b^m bm) -存盤所有節點的資訊
啟發式函式設計
- 問題松弛化
八數碼問題:棋子可以從方格A->方格B,如果A與B水平或豎直相鄰且B為空,
去掉相關條件,形成松弛問題:
A與B相鄰,棋子可從A移到B(距離)
如果B空,棋子可從A移動B
棋子可從A移動到B(不在位)
-
子問題分解
原問題分解為多個子問題,考慮子問題的解代價, -
模式資料庫
存盤子問題模式解代價,從目標反向搜索計算模式代價,針對子問題,查找模式資料庫, -
從經驗中學習
總結
- A * 演算法綜合了后向路徑代價和前向估計代價;
- 如果啟發式函式可納/一致, A*是最優的;
- 啟發式函式設計是關鍵,應選具有優勢的啟發式函式,
練習題
- A*搜索
- 修道士問題(M-C問題)

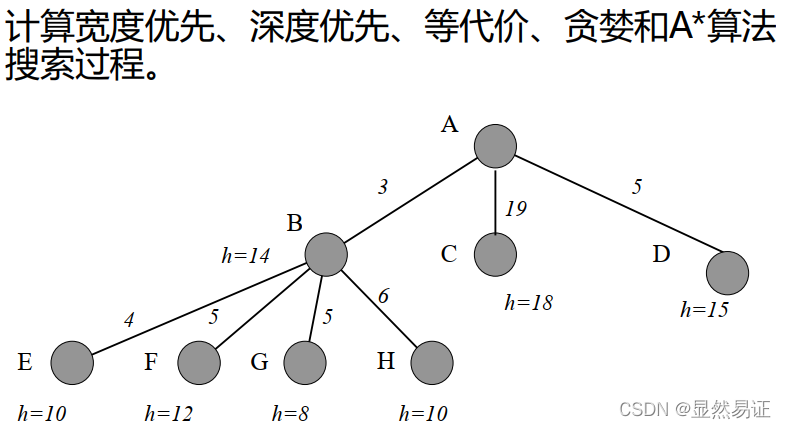
- 各種搜索演算法的搜索程序
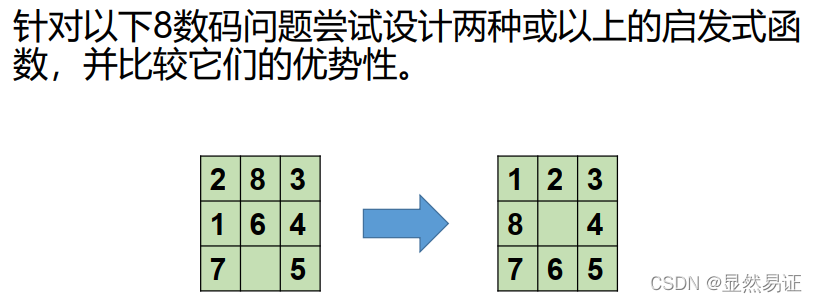
三、約束滿足問題
3.1 回溯法
以N皇后問題為例,從初始狀態開始,按行逐一擺放皇后,遇到矛盾時回傳上一狀態,重新擺放皇后,
由此,搜索空間是一棵搜索樹,直至搜索至第N層即可找到可行解,
回溯搜素 = DFS + 變數分配【每次一個變數】 + 約束檢查【考慮與前面分配不沖突的變數值】
具有完備性
具有最優性
時間復雜度:O(N!)
空間復雜度:O(N)
3.2 排序策略
3.2.1 最少可取值
(對節點排序,每次選擇值域最少可取值的變數)
3.2.2 度啟發式
(對節點排序,每次選擇度最大的變數)
3.2.3 最少約束值
(對顏色排序,選擇給近鄰變數留下更多選擇的值)
3.3 推理策略
3.3.1 約束傳播-區域相容性
- 節點相容(單個變數值域的所有取值滿足其一元約束)
- 邊相容(滿足所有的二元約束)
- 若X去除某個值,X的近鄰需要再次檢查,邊相容比前向檢查更早檢測出錯誤
- 路徑相容(通過觀察變數得到隱式約束來加強二元約束)
- …k階相容
- 強k階相容(k-1,k-2,…,1也相容,無需回溯就可求解問題)
3.3.2 智能回溯
- 搜索失敗時回傳前一個變數,嘗試另一個值,回溯到哪個變數?
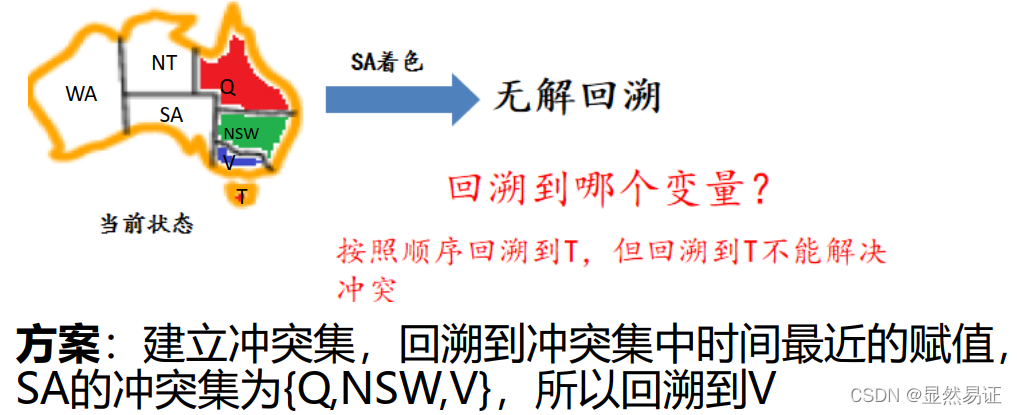
3.3.3 前向檢查
3.4 問題結構特性
極端情況:大問題由獨立子問題構成,獨立子問題可認為是約束圖的連接組件(連通子圖)
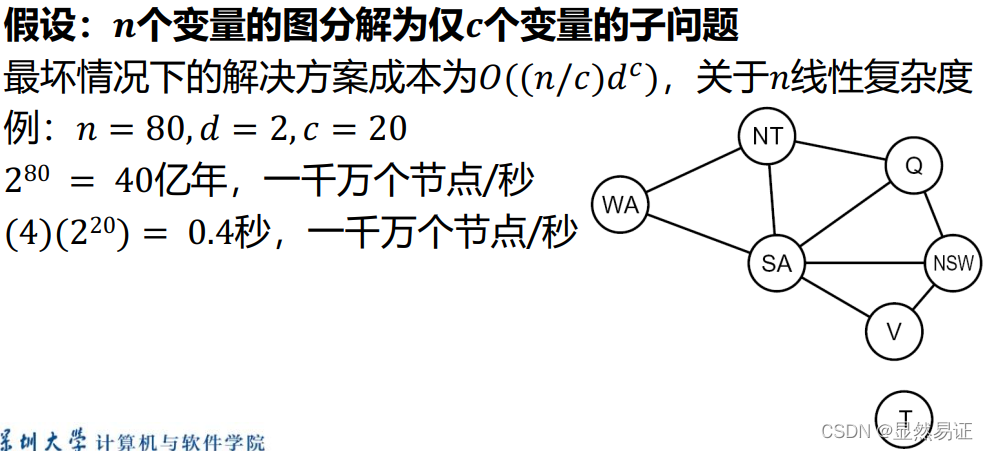
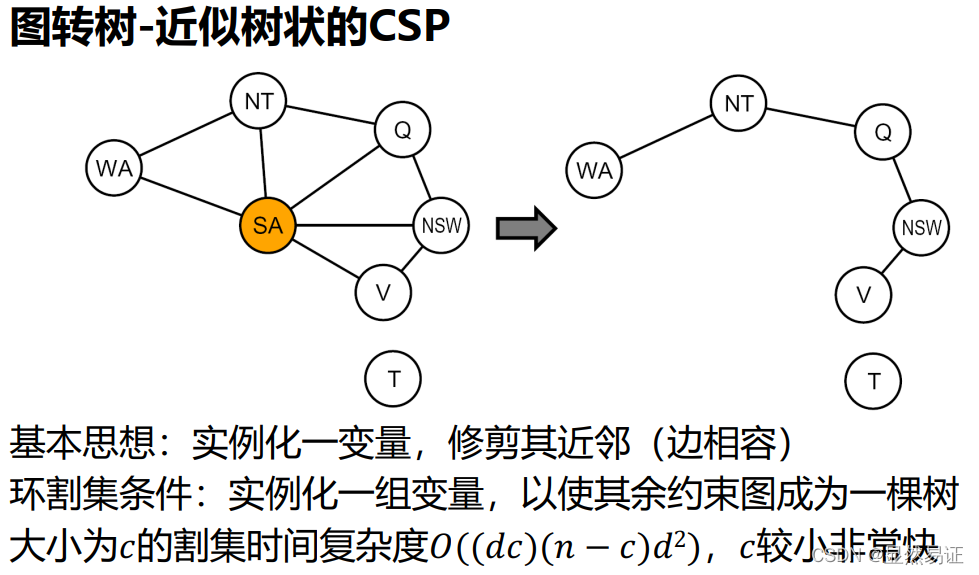
3.4.1 樹狀約束滿足問題-圖轉樹
-
變數(拓撲排序):
選擇一個根變數,對變數進行排序,先父母后孩子,
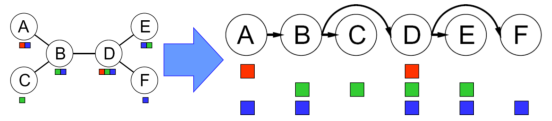
兩變數最多有一條路徑,所以n個結點的樹有n-1條邊, -
邊相容:
應用Remove Inconsistent(Parent( X i X_i Xi?), X i X_i Xi?) -
變數分配:
對于 i = 1 : n i = 1:n i=1:n,相容地分配 X i X_i Xi?
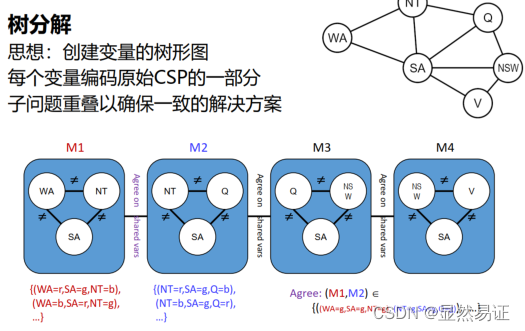
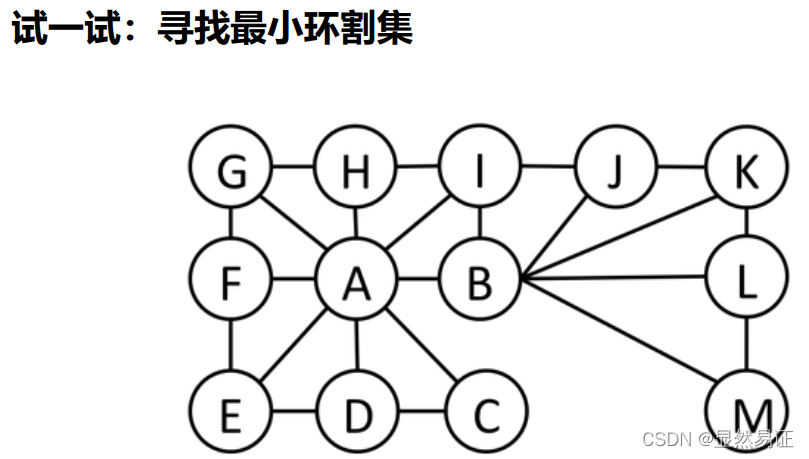
練習題
3.5 區域搜索
優點
- 通常只用常熟級的記憶體
- 通常能在標準約束滿足演算法不適用的很大或無限的(連續的)狀態空間中找到合理的解
- 對于解決純粹的最優化問題十分有用,其目標是根據目標函式找到最佳狀態
- 如果存在解, 最優的區域搜索演算法可找到全域最大/最小值
CSP區域搜索
- 初始變數分配違反一些約束
- 重新分配變數值
基本思想
變數選擇:隨機選擇任何有沖突的變數
值選擇:最小沖突啟發式
- 選擇一個違反最少約束的值
- 爬山法——啟發式資訊h(n)=違反約束的總數
- 其他區域搜索方法:模擬退火、區域束搜索
3.5.1 爬山法
從任意初始狀態開始,每次移動到最好的近鄰狀態,若無近鄰狀態比當前更好,則退出回圈,得到爬山法的解,
- 不具有完備性
- 不具有最優性
- 時間復雜度較低
- 空間復雜度:O(N)
- 可從任意地方開始
- 重復:移動到最好的近鄰狀態
- 若無近鄰狀態比當前更好,則退出

無最優性的概念,不具有完備性,
特點:速度快,但易于陷入區域最優,
改進爬山法
- 隨機爬山法:概率隨機選擇下一步,可能找到更好的解
- 首選爬山法:隨機直至選到優于當前的結點,后繼多時較好
- 隨機重啟爬山法:多次嘗試,演算法完備性的概率接近1
3.5.2 模擬退火
在爬山法的基礎之上,允許“下山”動作跳出區域最優解,從而能有更大概率找到全域最優解,
- 不具有完備性
- 具有最優性
- 時間復雜度比爬山法高
- 空間復雜度:O(N)

3.5.3 區域束搜索
從k個隨機生成的狀態開始,每一步全部k個狀態的所有后繼被生成,如果其中有一個是目標狀態,則演算法停止;否則從整個所有后繼串列中選擇k個最佳后繼,重復直至達到目標狀態,
- 不具有完備性
- 不具有最優性
- 時間復雜度比爬山法高
- 空間復雜度:O(N)
(隨機)束搜索:
在所有后繼串列中隨機選擇k個后繼,其中選中概率是狀態值的遞增函式,類似于自然選擇,
3.5.4 遺傳演算法
遺傳是隨機束搜索的一個變形,把兩個父狀態結合(選擇、交叉、變異)來生長后繼,而不是通過修改單一狀態進行,
- 具有完備性
- 具有最優性
- 時間復雜度比爬山法高
- 空間復雜度:O(N)
練習題
-
回溯演算法優化方法有哪些,其主要思想是什么,可以帶來哪些好處?
-
編程實作N皇后回溯搜索演算法,至少采用一種優化策略加速搜索程序,
-
實作N皇后至少一種區域搜索方法,并分析其演算法的性能(四個搜索演算法評價指標),
四、對抗搜索
4.1 Minimax
搜索:自頂向下
計算:自底向上
搜索方法:類似DFS
時間復雜度:O(
b
m
b^m
bm)
空間復雜度:O(
b
m
bm
bm)
面臨問題:搜索空間巨大
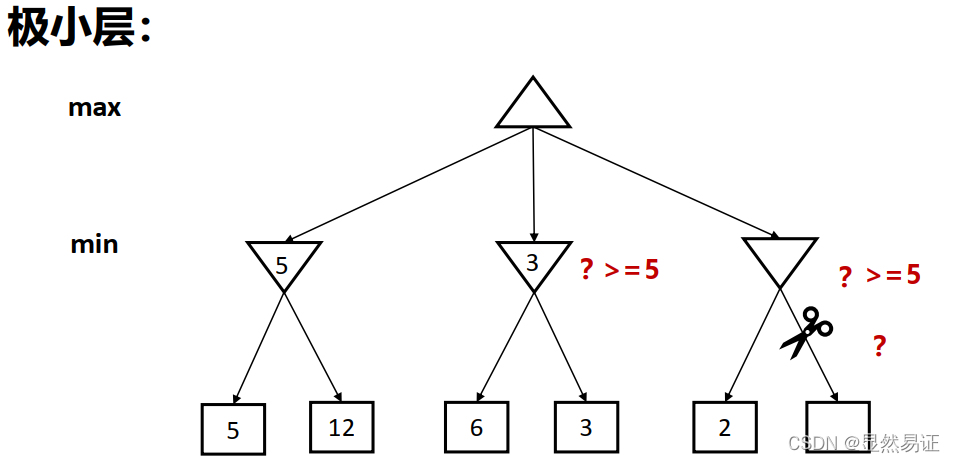
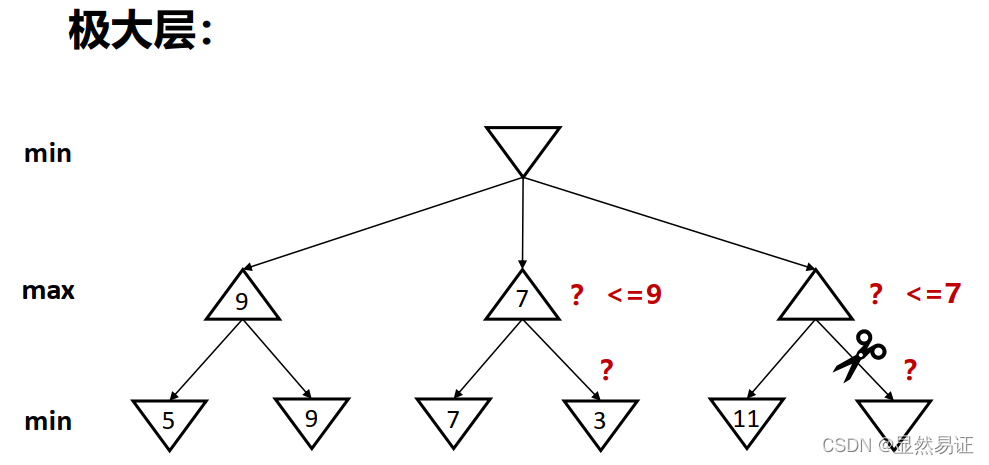
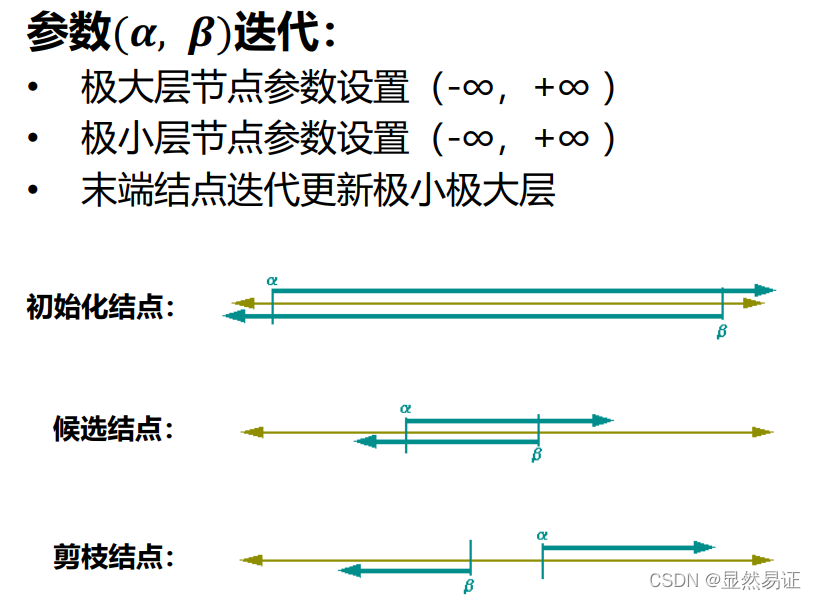
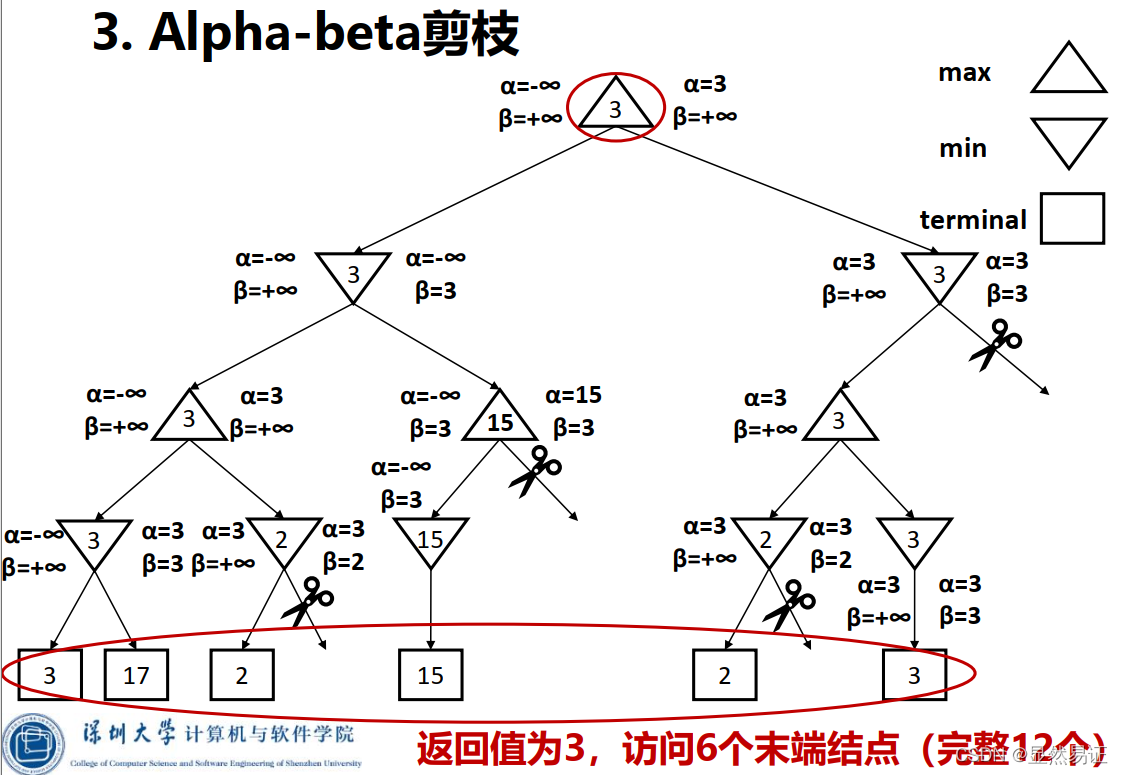
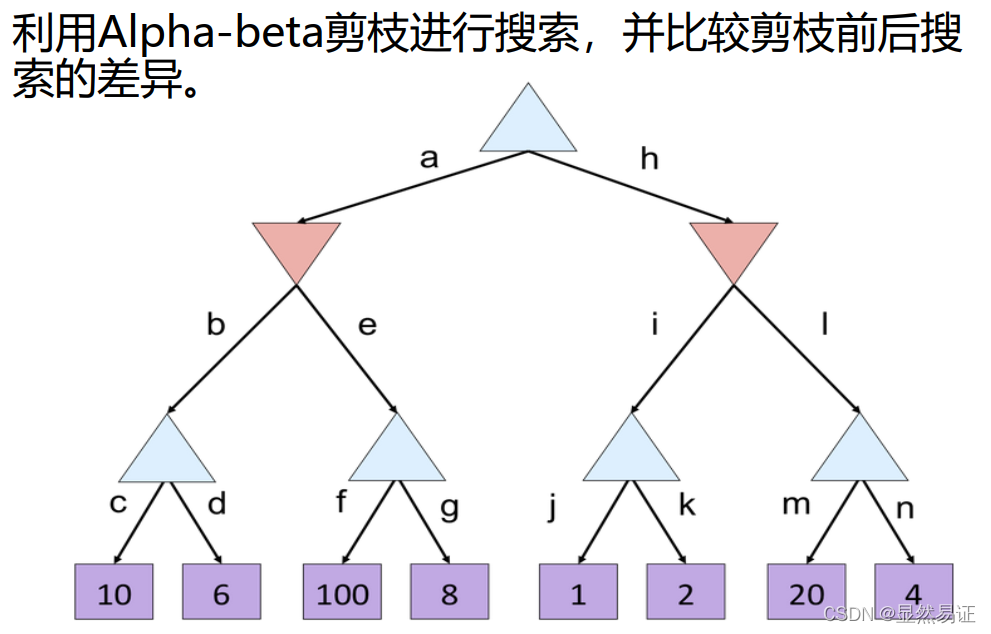
4.2 Alpha-Beta剪枝
一種找到最佳minimax步驟的方法,同時可以避免搜索不可能被選擇的步驟的子樹,
Alpha:可能步驟的最大下界
Beta:可能步驟的最小上界
任何新節點被認為是可能路徑節點 當且僅當
α
≤
V
a
l
u
e
(
N
)
≤
β
α≤Value(N)≤β
α≤Value(N)≤β
剪枝性質:
- 剪枝不影響根節點Minimax值
- 中間節點值可能不同
- 子節點的次序影響剪枝效率
- 最好時間復雜度:O( b m / 2 b^{m/2} bm/2)

4.3 優化
- 減少搜索范圍
- 設定下棋風格
- 利用多執行緒
- 增大搜索層數
- 使用置換表
- 啟發式搜索
- 自學習
- 蒙特卡洛樹搜索(多次模擬博弈,并嘗試根據模擬結果預測最優的移動方案)
練習題
五、貝葉斯推理
5.1 推理(參考離散數學)
5.2 貝葉斯推理(概率論與數理統計回顧)
- 聯合分布
- 邊緣分布
- 去除聯合分布中變數的子表
- 邊緣化:累加去除變數后的行
- 條件概率
P ( x ∣ y ) = P ( x , y ) p ( y ) P(x|y) = \frac{P(x,y)}{p(y)} P(x∣y)=p(y)P(x,y)? - 全概率公式
P ( A ) = ∑ i P ( B i ) P ( A ∣ B i ) P(A) = \sum_i{P(B_i)P(A|B_i)} P(A)=i∑?P(Bi?)P(A∣Bi?) - 鏈式規則
P ( x 1 , x 2 , x 3 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 1 , x 2 , . . . , x n ) = ∏ i P ( x i ∣ x 1 . . . x i ? 1 ) P(x_1,x_2,x_3) = P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)\\ P(x_1,x_2,...,x_n)=\prod_iP(x_i|x_1...x_{i-1}) P(x1?,x2?,x3?)=P(x1?)P(x2?∣x1?)P(x3?∣x1?,x2?)P(x1?,x2?,...,xn?)=i∏?P(xi?∣x1?...xi?1?) - 貝葉斯規則
P ( A , B ) = P ( A ∣ B ) P ( B ) P ( A , B ) = P ( B ∣ A ) P ( A ) P ( A ∣ B ) = P ( B ∣ A ) P ( B ) P ( A ) P(A,B)=P(A|B)P(B)\\ P(A,B)=P(B|A)P(A)\\ P(A|B)=\frac{P(B|A)}{P(B)}P(A) P(A,B)=P(A∣B)P(B)P(A,B)=P(B∣A)P(A)P(A∣B)=P(B)P(B∣A)?P(A)
后驗 \qquad 調整因子 \qquad 先驗
-
條件獨立
? x , y , z : P ( x , y ∣ z ) = P ( x ∣ z ) P ( y ∣ z ) \forall x,y,z:P(x,y|z)=P(x|z)P(y|z) ?x,y,z:P(x,y∣z)=P(x∣z)P(y∣z)
【給定z,x條件獨立于y】 -
貝葉斯網路=圖拓撲結構+區域條件概率
練習題
- 利用貝葉斯公式解決問題
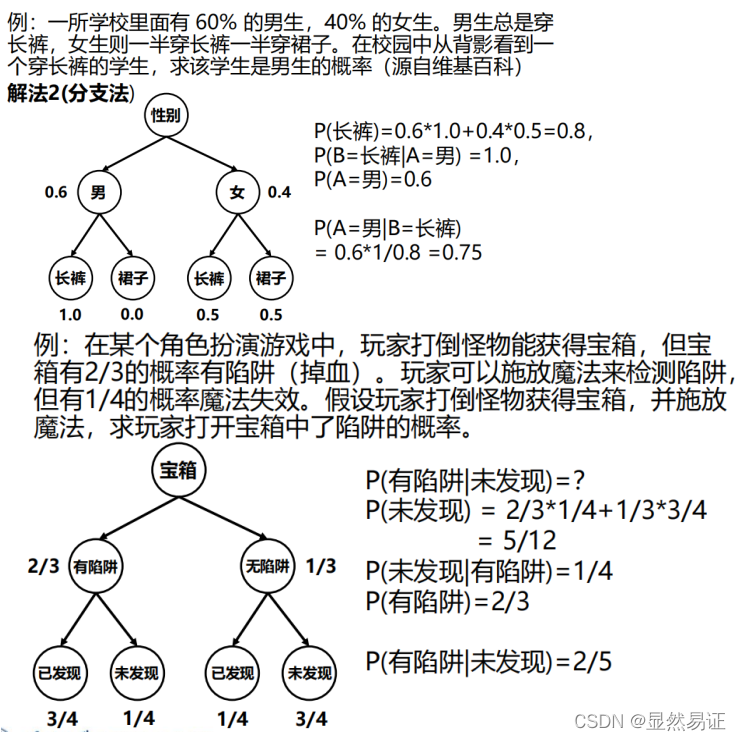
- 利用概率公式解決問題

- 推理問題

六、專家系統
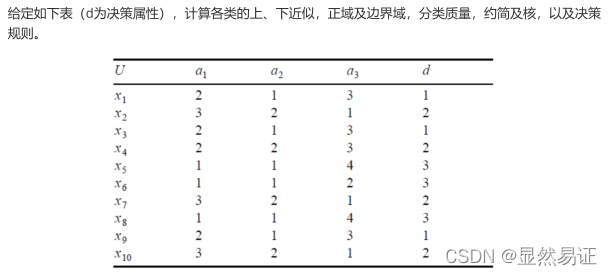
【重點】啟發性、知識庫、屬性約簡、決策規則
6.1 基本概念

練習題
七、機器學習
【重點】機器學習概述、研究內容、基本概念
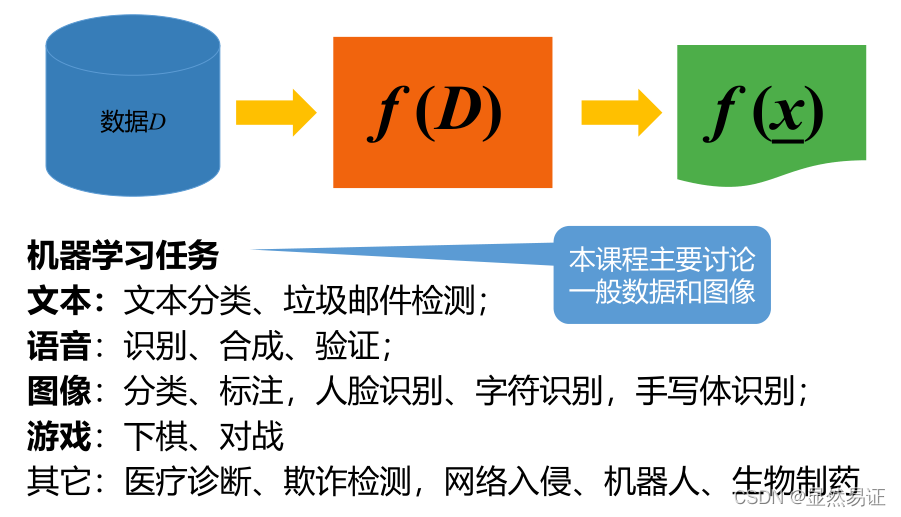
7.1 機器學習概述
機器學習(Machine Learning):致力于研究如何通過計算的手段,利用經驗來改善系統自身的性能–(周志華-機器學習)
形式定義:假設用P來評估計算機程式在某任務類T上的性能,若一個程式通過利用經驗E在T中任務上獲得了性能改善,則程式對E進行了學習
經驗:資料驅動,概率、統計和優化方法
學習演算法:從資料中產生“模型”的演算法
7.2 相關問題
7.3 研究內容
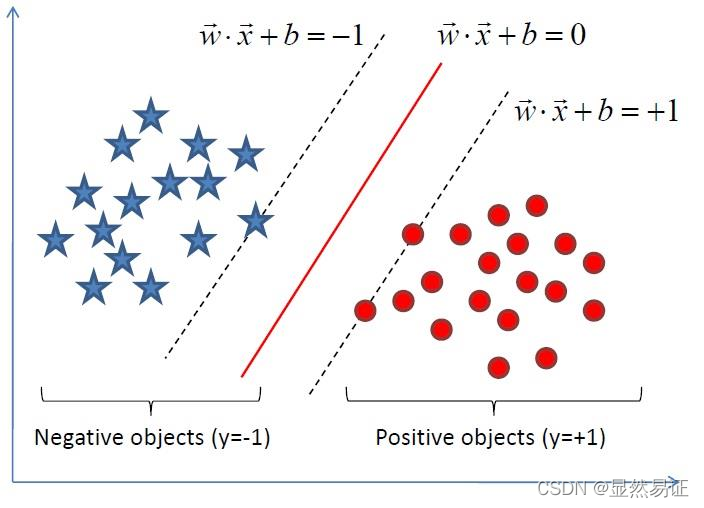
有監督學習
任務:給定一組帶類別標記資訊的資料,如何訓練有效的模型對未知類別的資料進行預測(有師學習)
標記資訊:離散型(分類),連續型(回歸)
常見有監督演算法:
線性回歸
線性判別分析
樸素貝葉斯
決策樹
支持向量機
神經網路
K近鄰
無監督學習
任務:給定一組無類別資訊的資料,如何訓練模型推斷出資料的一些內在結構資訊(無師學習)
常見無監督演算法:
k-means
Fuzzy k-means
DBSCAN
譜聚類
層次聚類
PCA
NMF
PageRank
半監督學習
任務:給定少量有類別資訊和大量無類別資訊的資料,如何訓練模型進行預測或推斷出資料的一些內在結構
常見半監督演算法:
主動學習
協同學習
分岐模型
圖模型
半監督SVM
半監督聚類
研究內容
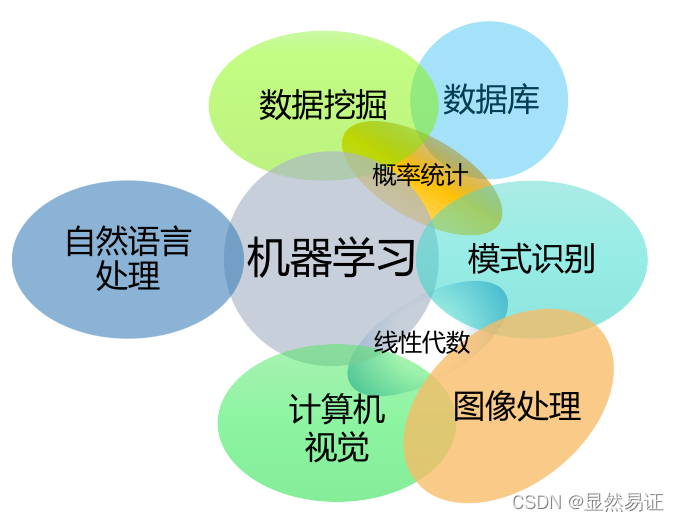
7.4 基本概念
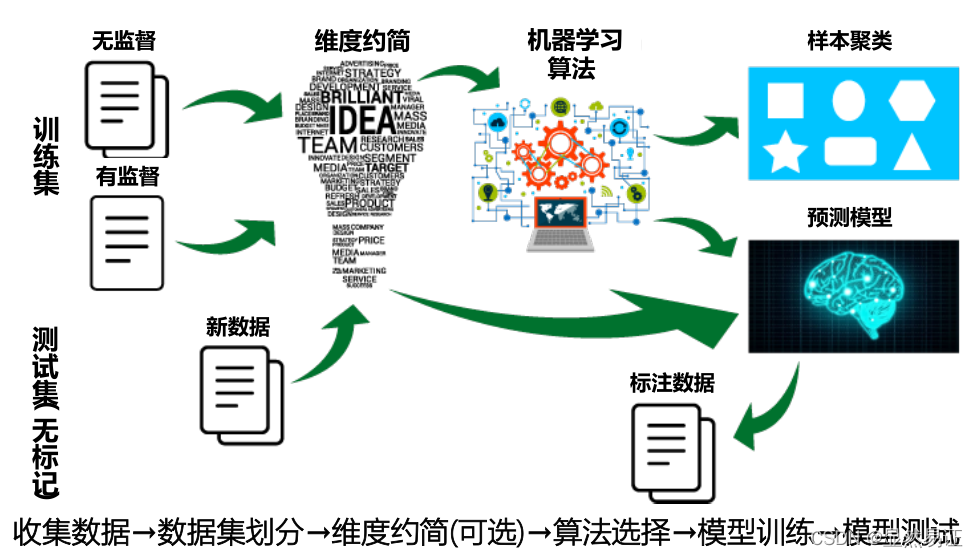
假設空間
演繹與歸納:科學推理的兩在基本手段
歸納學習:“從樣例中學習”–特殊到一般的“泛化”(generalization)程序,機械學習
假設空間:多個與訓練集一致的“假設”(hypothesis)集合
奧卡姆剃刀(Occam‘s razor):若有多個假設與觀察一致,則選最簡單的那個-假設也即模型
模型評估與選擇
錯誤率(error rate): 分類錯的樣本數目占樣本總數的比率;相應地,可定義精度(accuracy),即精度=1-錯誤率
誤差(error): 模型的預測輸出與樣本的真實輸出之間的差異
訓練誤差(training error):模型在訓練集上的誤差
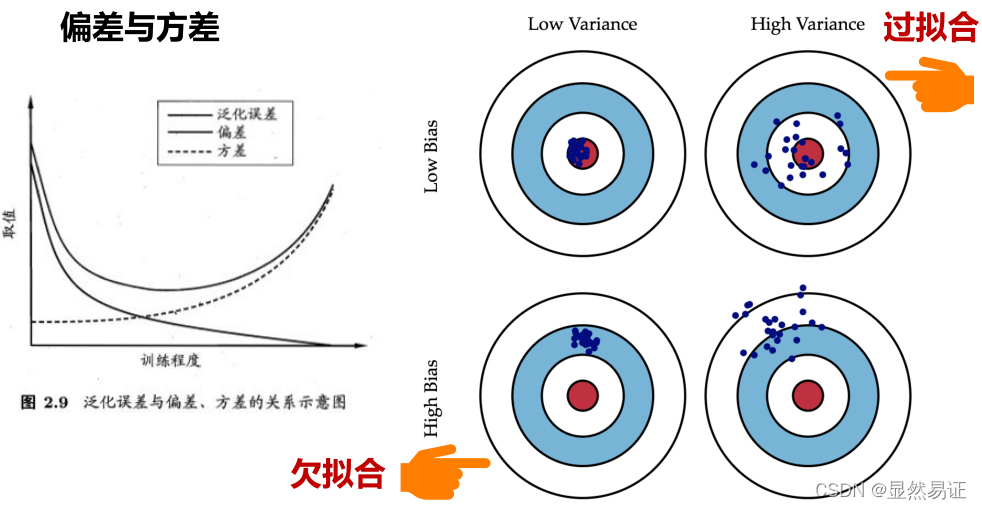
泛化誤差(generalization error):模型在新樣本上的誤差
泛化誤差小,但預測樣本未知,實際只能使訓練誤差小
資料集的劃分
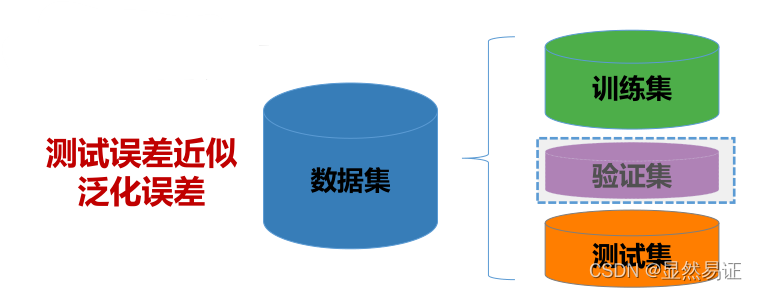
1) 留出法
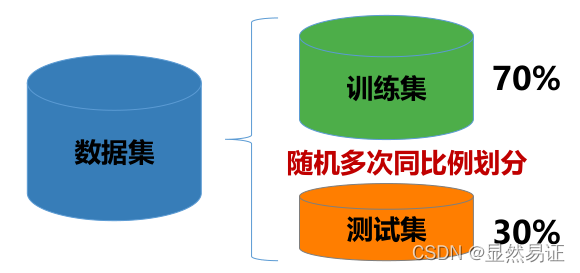
2)交叉驗證法(cross validation)
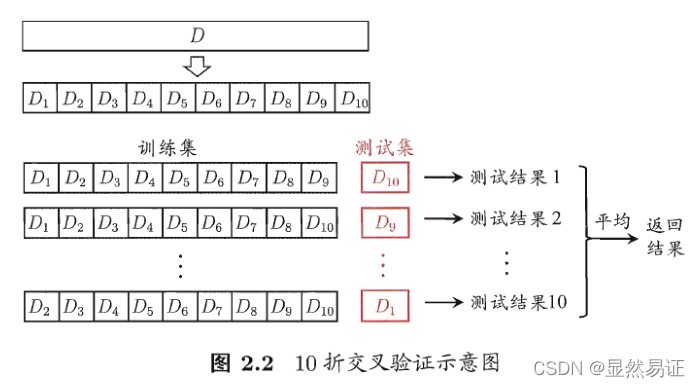
3)驗證集(validation set)—— 調參
性能度量

練習題
-
[1] 影響模型泛化性能的因素在哪些?
-
[2] 例舉一個機器學習的應用,并嘗試分析其背后的技術,
八、維度約簡
【重點】維度約簡概述、特征選擇、過濾式方法、互資訊特征選擇
8.1 概述
高維特征資料可能存在不相關的特征,特征之間也可能存在相互依賴,引起維數災難問題:
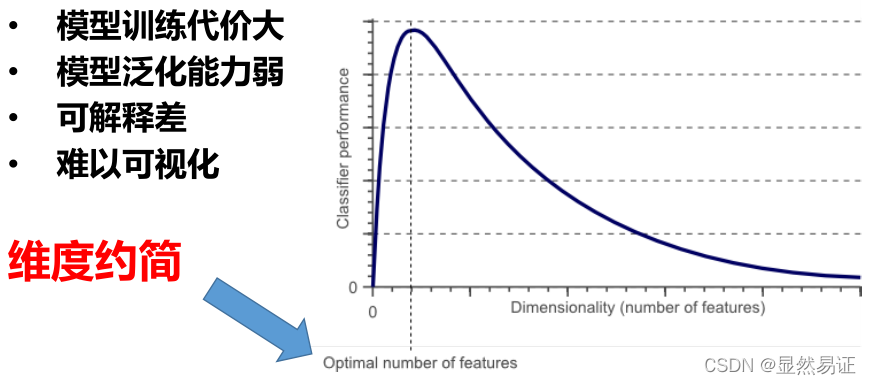
維度約簡:機器學習領域中一個重要的研究方向,是一種在保持資料某種特性情況下去除無關和冗余特征的程序
特征變換:高維特征空間映射至低維空間
? 將原始高維特征空間進行空間變換
? 選擇變換后重要的且冗余性小的特征構建低維空間
特征選擇:去除無關和冗余特征/保留有用特征
? 選擇的特征應與分類/預測任務強相關
? 選擇的特征彼此之間冗余性小
8.2 特征選擇(不考)
特征選擇:其目標是保留用于學習的相關特征并去除冗余和不相關的特征從而達到減少特征個數,提高模型精確度,減少運
行時間的目的
一般程序:特征子集選擇,評價函式,停止準則,驗證程序
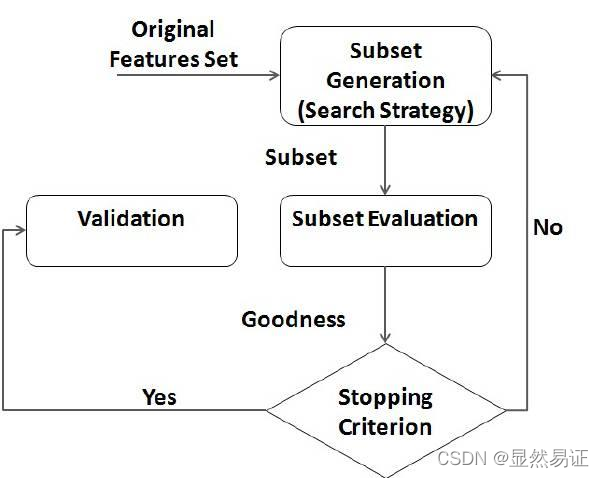
常見的特征選擇方法大概可以分為三種:
過濾式
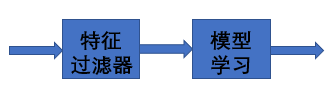
過濾式方法:先對資料集進行特征選擇,然后再訓練學習器,特征選擇程序與后續學習程序相互獨立
思路:對每一維的特征打分,即給每一維的特征賦予權重,這樣的權重就代表該維特征的重要性,然后依據權重排序
主要方法:
? 相關系數
? 卡方檢驗
? 資訊增益,互資訊
過濾式方法根據其對特征評價的方式可分為:特征排序(Feature Ranking)和特征子集(Feature subset)
特征排序:對每個特征分別度量其重要性,賦予一個“相關統計量”,并按大到小的排序-相關系數
設計一個閾值,然后選擇比閾值大的相關統計量分量所對應的特征;或者指定欲選取的特征個數𝒌,然后選擇相關統計量指數最大的指定個數特征(Top k)
特征排序:相關系數
相關系數最早是由統計學家卡爾·皮爾遜設計的統計指標,是研究變數之間線性相關程度的量

特征子集:根據特征重要性的度量,選擇保持資料某種特性不變的特征子集-互資訊特征選擇設計特征和特征子集重要性度量準則,啟發式加入帶來最大效益的特征,直至找到與原所有特征集合在度量值上相等的特征子集(無參)
包裹式
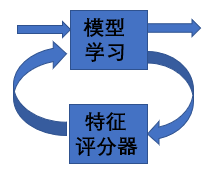
包裹式方法:選擇在將要使用的學習器上最好性能的特征子集
思路:將子集的選擇看作是一個搜索尋優的問題,生成不同的
特征組合,對組合進行評價,再與其他的組合進行比較,由此將特征子集的選擇作為一個優化問題求解包裹式特征選擇的目的就是為給定學習器選擇最有利于其性能、“量身定做”的特征子集
主要方法:
? 完全搜索
? 啟發式搜索
? 隨機搜索
包裹式方法:特征子集產生程序是搜索特征子集空間的程序,
搜索策略可分為三類:
完全搜索(Complete)
? 廣度優先搜索(Breadth First Search)
? 分支限界搜索(Branch and Bound)
? 定向搜索 (Beam Search)
? 最優優先搜索 (Best First Search)
啟發式搜索(Heuristic)
? 序列前向選擇(SFS , Sequential Forward Selection)
? 序列后向選擇(SBS , Sequential Backward Selection)
? 雙向搜索(BDS , Bidirectional Search)
隨機搜索(Random)
? 模擬退火演算法(SA, Simulated Annealing)
? 遺傳演算法(GA, Genetic Algorithms)
嵌入式

嵌入式方法:將特征選擇程序與學習器訓練程序融為一體,兩者在同一個優化程序中完成,在學習器訓練程序中自動地進行特征選擇
思路:在給定學習任務(目標)的情況下,獲得對于提升預測準確性最重要的屬性,即在確定模型的程序中,挑選出對于學習任務相對重要的屬性,

8.3 互資訊特征選擇
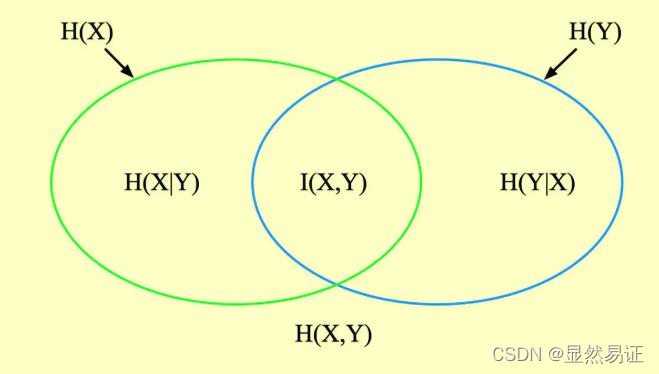
資訊熵:兩個橢圓表示的部分
聯合熵:是資訊熵的并集,兩個橢圓的并
條件熵:是差集,左邊的橢圓去掉重合部分就是
H
(
X
∣
Y
)
H(X|Y)
H(X∣Y)
互資訊:是資訊熵的交集
資訊度量標準:

互資訊最大化:

互資訊保持:


練習題
- 特征選擇的方法有哪些,簡述各方法的優缺點,
九、深度學習緒論
【重點】卷積神經網路
9.1 神經網路基礎
神經網路:是由具有適應性的簡單單元組成的廣泛并行互連的網路,它的組織能夠模擬生物神經系統對真實世界物體所作出的互動反應
神經網路是一種模擬人腦的神經網路以期能夠實作類人工智能的機器學習技術,它是目前最為火熱的研究方向–深度學習的基礎
9.2 經典神經網路
M-P模型
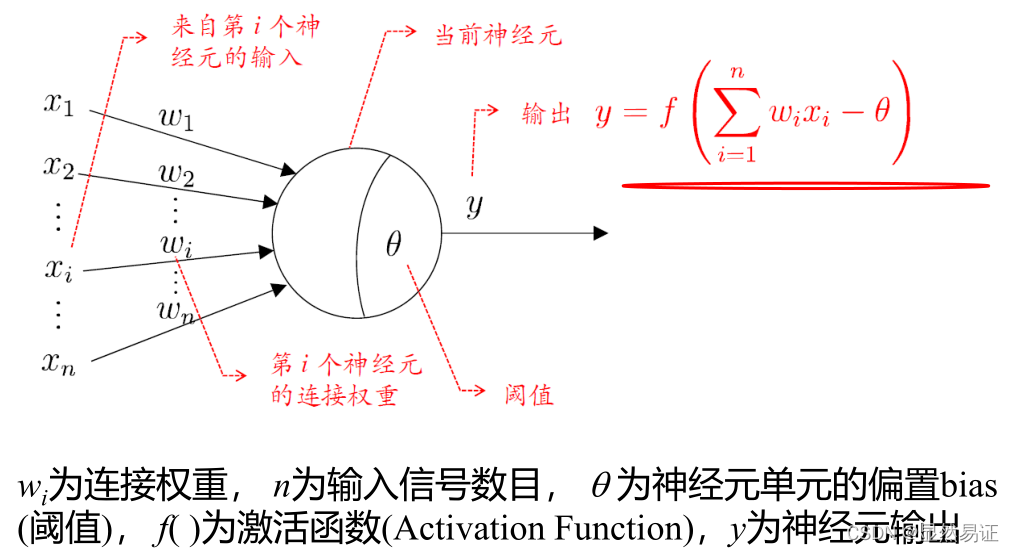
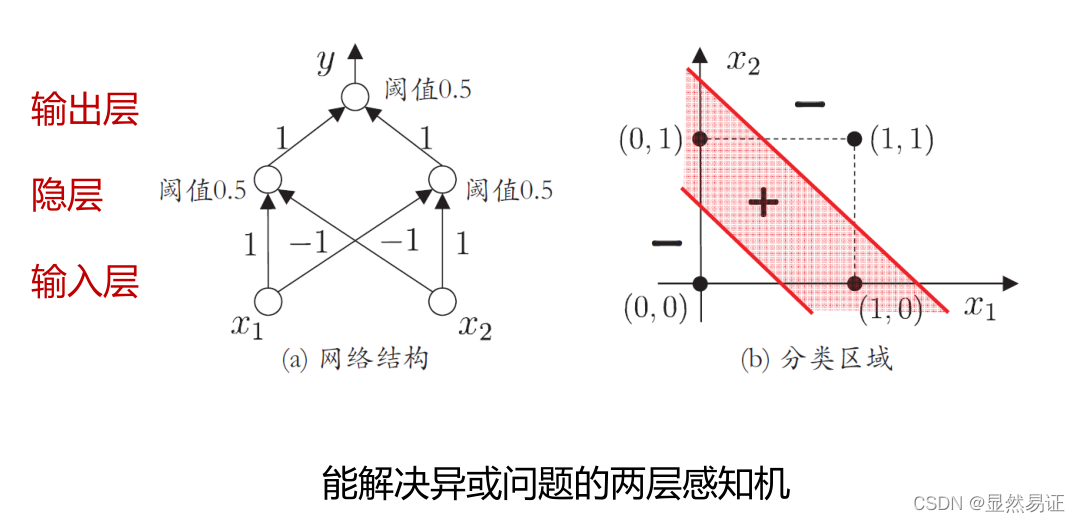
單層感知機
感知器包含有兩個層次,分別是輸入層和輸出層,輸入層里的“輸入單元”只負責傳輸資料,不做計算,輸出層里的“輸出單元”則需要對前面一層的輸入進行計算,
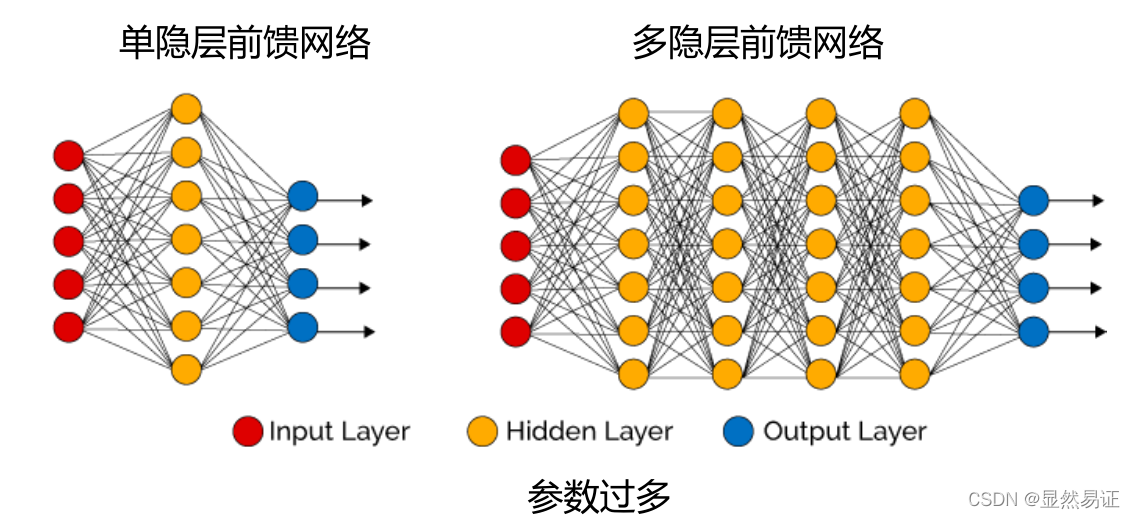
多層感知機
多層前饋神經網路
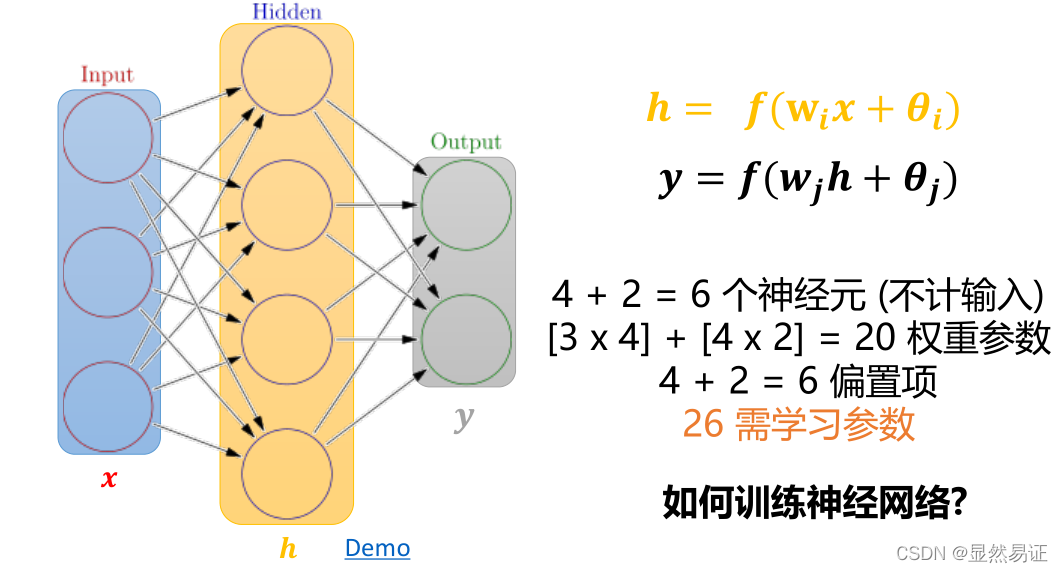
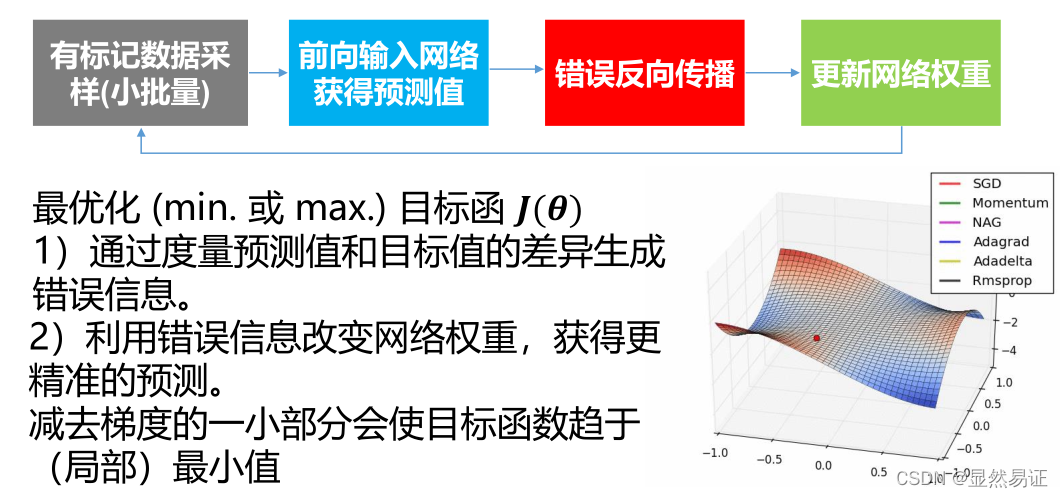
反向傳播演算法
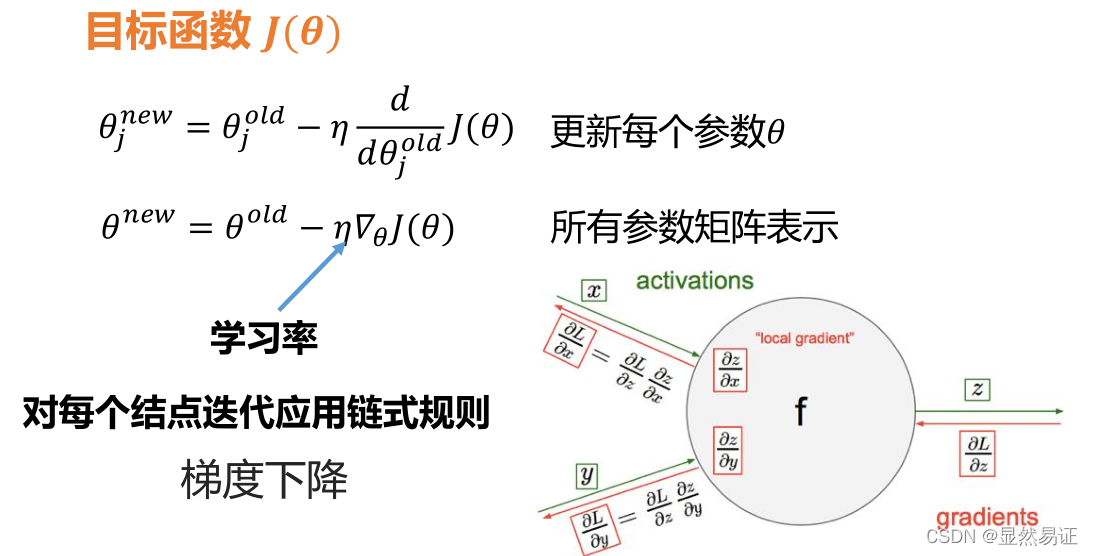
訓練程序
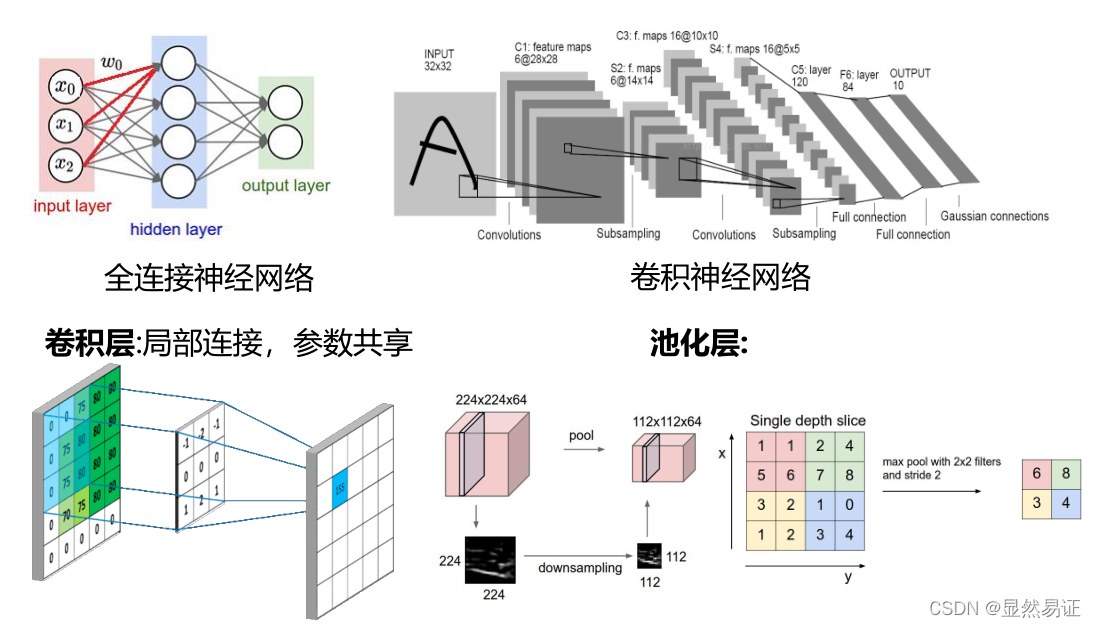
9.3 卷積神經網路
影像表示-灰階、矩陣、RGB顏色、HSV顏色、彩色轉灰度、直方圖
十、集成學習
【重點】 AdaBoosting Bagging
10.1 集成學習基礎
集成學習通過構建并結合多個學習模型(學習器)來完成學習任務,也稱多分類器系統.
個體學習器(Individual Learner):學習演算法從訓練資料產生的學習模型;學習演算法如決策樹,貝葉斯分類器,神經網路等;
同質集成(Homogeneous Ensemble):個體學習器的學習演算法相同,此時個體學習器也稱基學習器(Base Learner)
異質集成(Heterogenous Ensemble):個體學習器的學習演算法不相同,此時個體學習器也稱組件學習器(Component Learner)
理論基礎:PAC(Probably Approximately Correct)
弱學習器:泛化性能略優于隨機猜測的學習器
強學習器:泛化性能好的學習器
任意給定僅比隨機猜測略好的弱學習器,可以將其提升為強學習器√
10.2 個體生成
集成學習主要問題
- 個體生成:多個學習器的構造生成
- 個體差異:學習器之間的差異性度量
- 個體數量:學習器的數目
- 集成策略:學習器的集成方法
個體生成
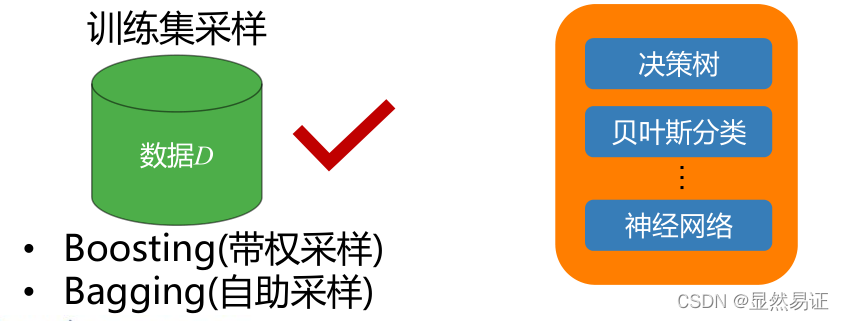
個體生成-Boosting
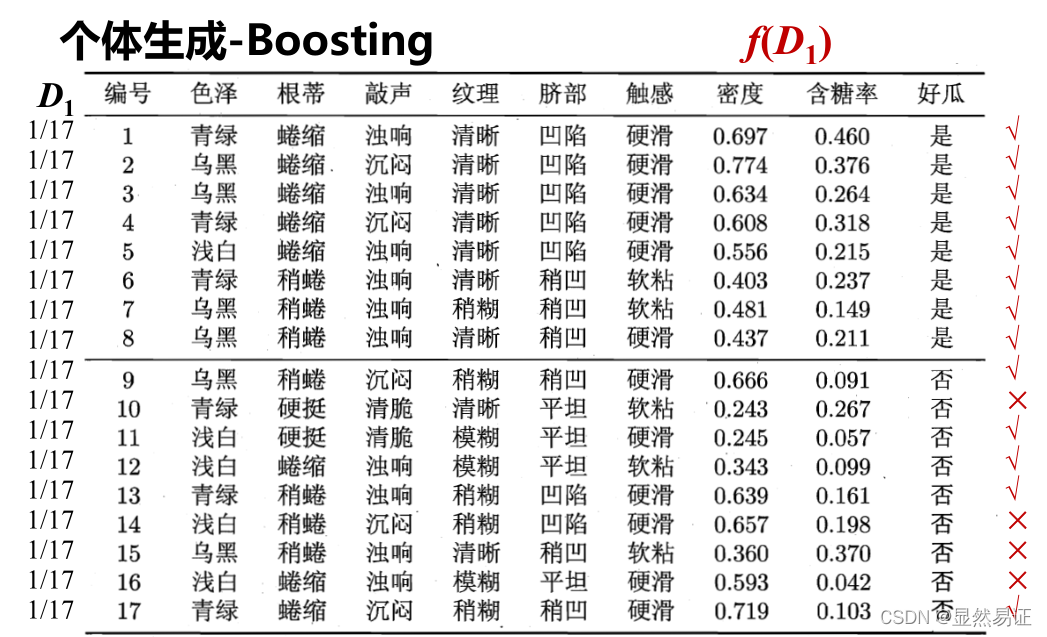
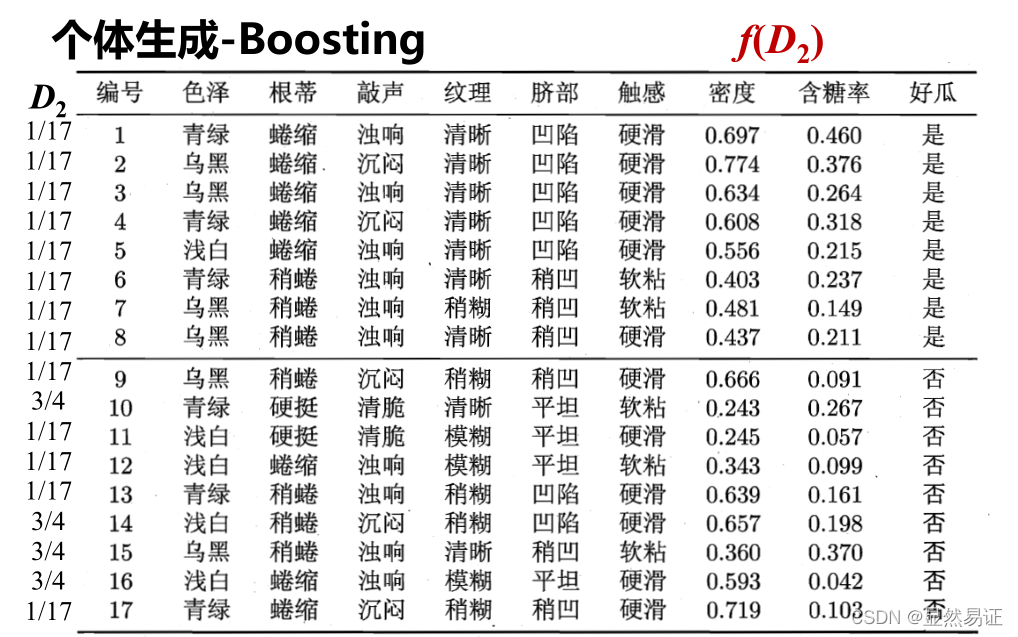
AdaBoosting(Adapting Boosting)- 帶權采樣

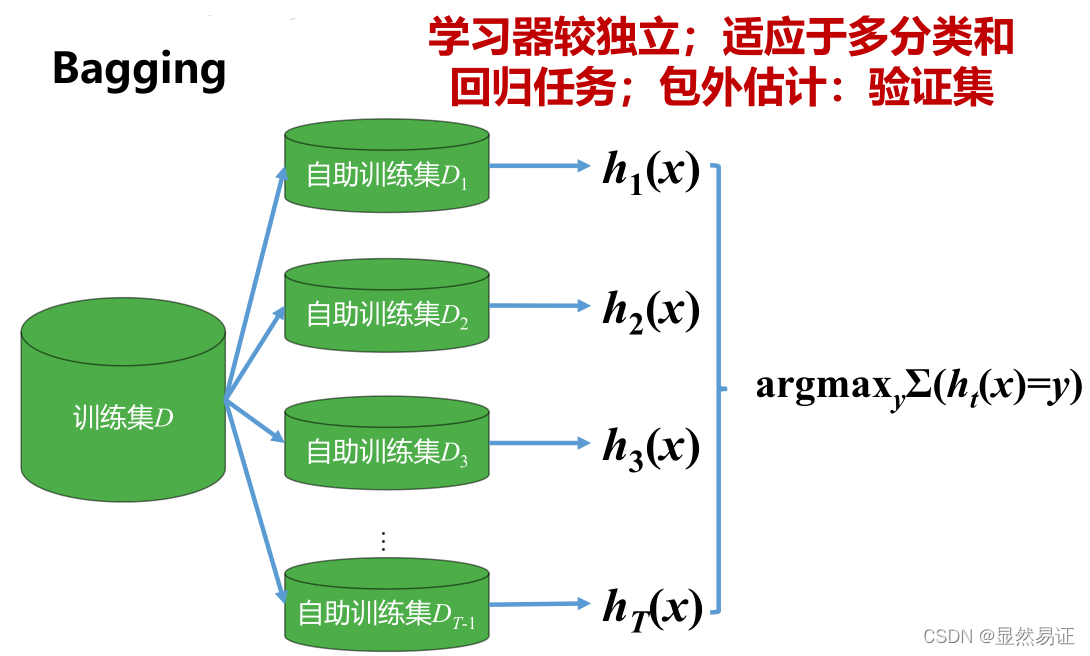
Bagging-自主采樣
自主采樣: 給定包含m個樣本的資料集D,每次隨機抽取一個樣本放入采樣資料集D‘,然后將該樣本放回資料集D,使得該樣本在下次采樣時仍有可能被采到,重復執行m次,得到包含m個樣本的資料集D’.

AI導論總結
期末加油~!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/397551.html
標籤:AI
上一篇:機器學習 簡答題 速記