序言
前兩天nanodet-plus隆重發布,又賺了一波熱度,趁著年底有空,趕緊學習一波,避免被卷死;因為之前有過nanodet的訓練實踐經歷,但是有好長一段時間沒用了,代碼都生疏了,還好作者將新版本合并到老倉庫中,代碼結構基本上沒變,舊的組態檔修改依舊適用,重新上手起來也比較容易,這次打算拿之前的筷子資料集來試試效果,本文記錄訓練程序,
NanoDet-Plus與上一代NanoDet相比,在僅增加1毫秒多的延時的情況下,精度提升了30%,與YOLOv5-n, YOLOX-Nano等其他輕量級模型相比,在精度和速度上也都高了不少!同時NanoDet-Plus改進了代碼和架構,提出了一種非常簡單的訓練輔助模塊,使模型變得更易訓練!同時新版本也更易部署,同時提供ncnn、OpenVINO、MNN以及安卓APP的Demo!
先看下nanodet-plus與上一代nanodet以及其他輕量型的檢測演算法對比:
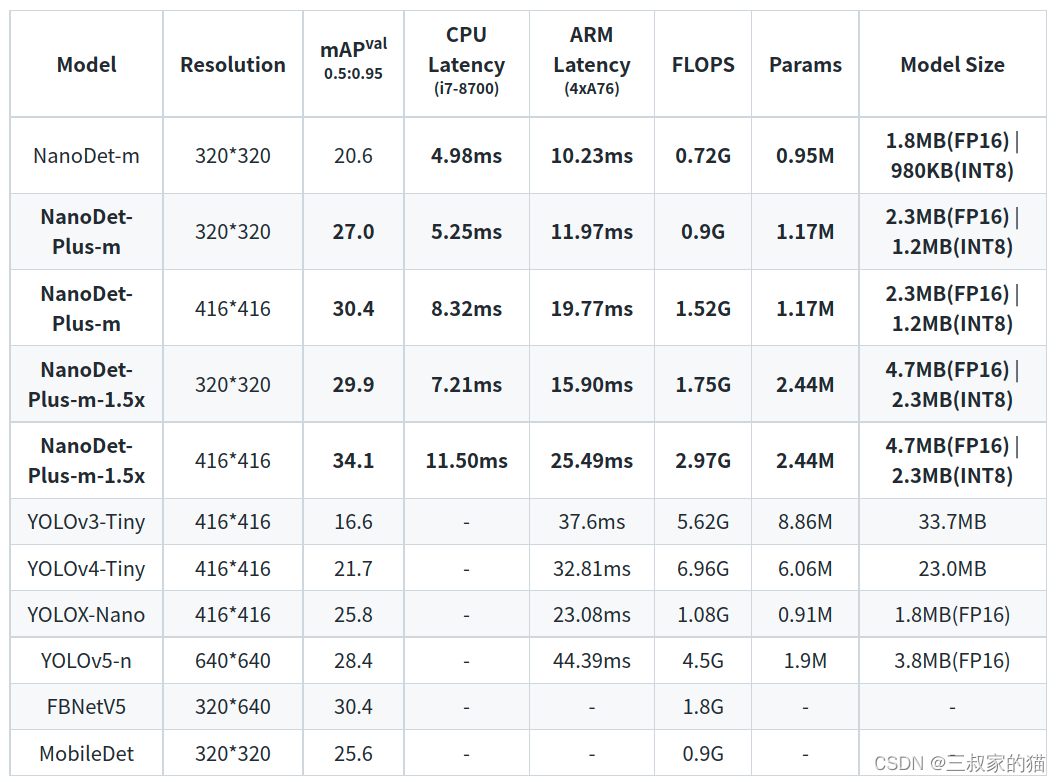
具體改進請參考作者知乎原文介紹:Nanodet-Plus 知乎介紹
一、環境配置
簡單介紹一下我的本機環境:
- ubuntu 18.04
- RTX 3070
- cuda 11.2
- python 3.7
- pytorch 1.8
1.1 nanodet安裝
需要安裝nanodet及相關依賴,打開終端界面,在終端中輸入命令如下:
git clone https://github.com/RangiLyu/nanodet.git
cd nanodet
pip install -r requirements.txt
python setup.py develop
安裝成功后進行測驗,在nanodet檔案夾下創建一個images檔案夾,將測驗圖片放入該檔案夾中,然后下載coco資料集訓練的權重(權重放在谷歌云盤上,下載的話需要科學上網),運行測驗demo:
python demo/demo.py image --config CONFIG_PATH --model MODEL_PATH --path IMAGE_PATH
- CONFIG_PATH 是nanodet-plus的yml組態檔
- MODEL_PATH 是剛才下載的權重路徑
- IMAGE_PATH 是測驗圖片路徑
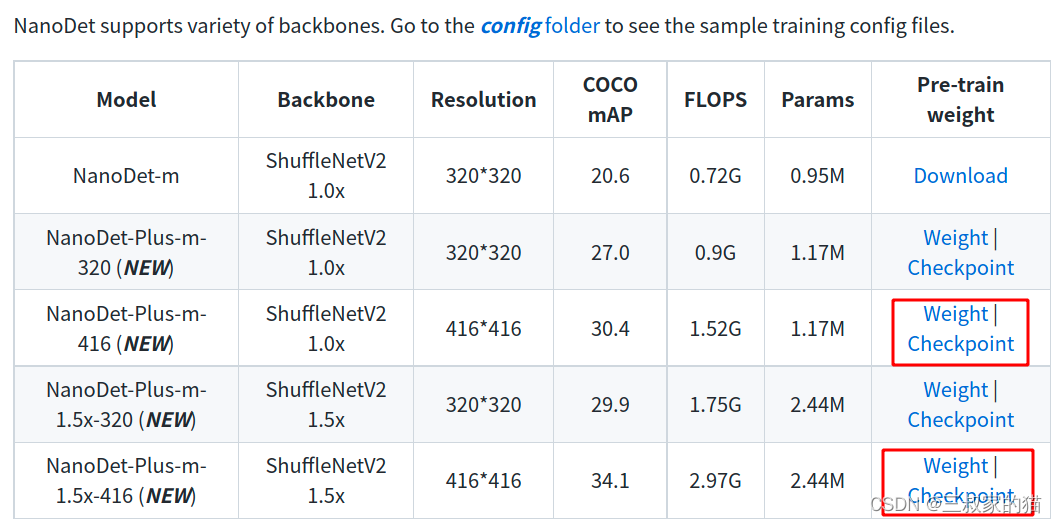
權重下載連接地址,可以將weight和checkpoint都下載下來,推理的時候只使用weight,訓練的時候會用到checkpoint,我這里只下了416尺寸的:
以下是我的測驗例子,下載的權重放在新建的weights檔案夾中,使用nanodet-plus-m的416尺寸推理:
python demo/demo.py image --config config/nanodet-plus-m_416.yml --model weights/nanodet-plus-m_416.pth --path images/
測驗結果如下,誤檢率還是挺高的,不過置信度都比較低,可以通過閾值過濾掉:

或者使用nanodet-plus-m-1.5x_416版本,效果會好很多:

好了,先不糾結精度的問題,測驗成功的話說明環境已經安裝成功了,如果運行出錯的話需要自己排查一下,按照步驟來一般不會有什么問題,
二、資料準備
為了以后方便測驗某個新出的目標檢測演算法,介于coco和voc資料集都太大了,訓練一次要耗費很長的時間,所以我自己構建了一個筷子資料集,數量只有兩百多張,圖片少了點,但是非常方便訓練配置,資料集小,訓練速度快,很容易出結果,具有很好的模型測驗意義,具體介紹請看我之前的構建文章構建了一個用于目標檢測點數的資料集

然后根據組態檔資料集讀入要求,將voc格式的資料集分為train和val兩部分,檔案夾劃分如下,因為資料集資料量少,不想寫腳本劃分的話,自己手動復制粘貼劃分一下也沒問題,記錄下路徑:
三、修改組態檔
將config/nanodet_custom_xml_dataset.yml復制一份,另取名為config/nanodet_plus-m-416_test.yml,按需修改以下幾處:
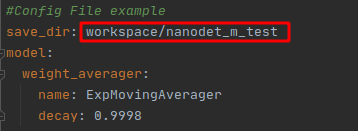
訓練保存的檔案夾:
訓練目標類別數,根據自己資料集來,我的只有一類:
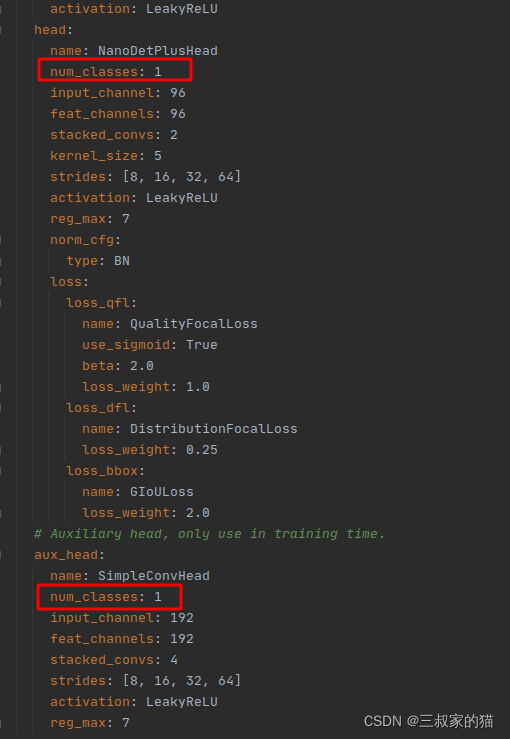
資料集標簽類別:

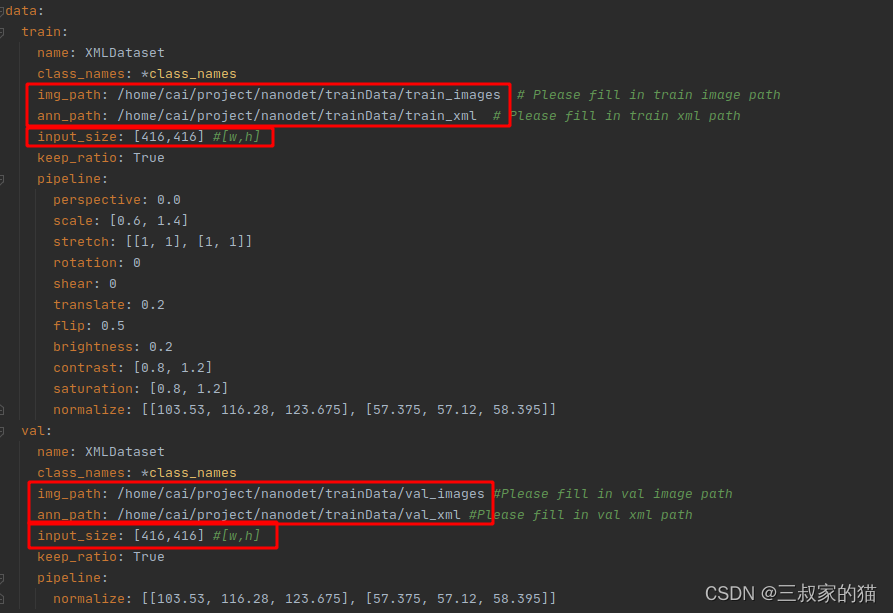
訓練尺寸和資料集路徑:
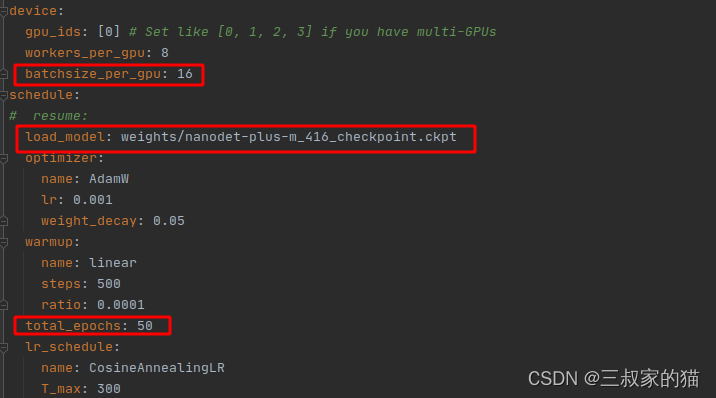
依次為訓練批次大小(根據自己的顯卡來)、預訓練權重路徑(好像不加收斂速度也很快)、訓練總輪次:
修改結束后運行訓練命令:
python tools/train.py config/config/nanodet_plus-m-416_test.yml
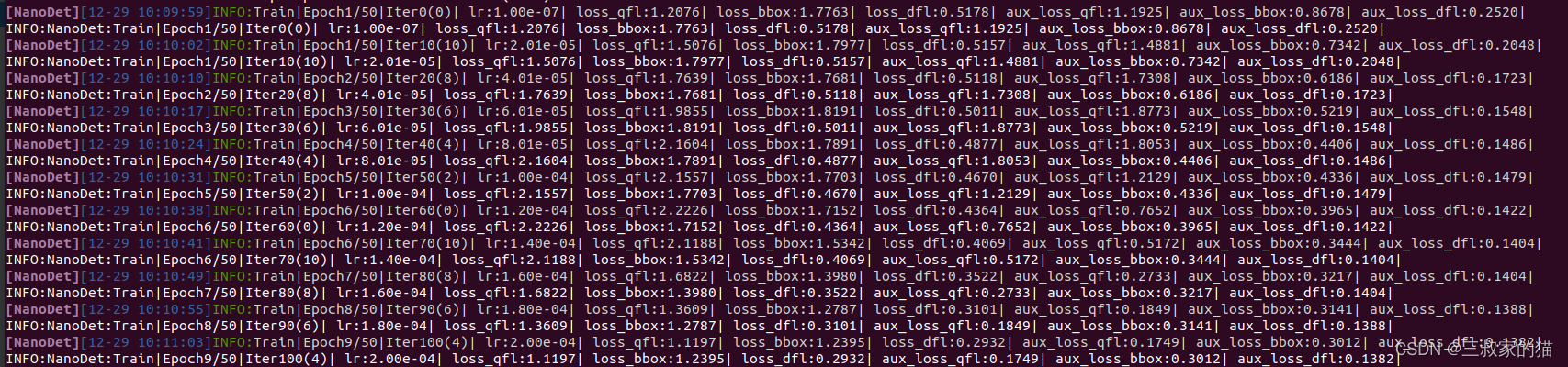
出現如下訓練界面說明模型已經開始訓練,如果遇到問題的話,檢查一下自己是不是組態檔沒修改成功,具體問題具體排查:
最終訓練精度結果如下:
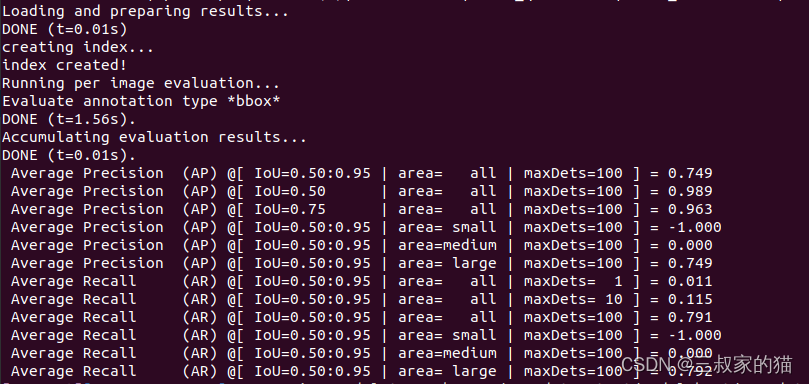
還不錯的樣子,AP0.5:0.95達到了 0.749,AP0.5 也達到了0.989,具體看可視化效果如何,
運行測驗demo,可視化結果如下,效果好像稍微差一丟丟,不過問題不大,可以通過調整后處理閾值過濾,或者訓練程序調整一些超引數來更好的訓練,因為只是簡單跑通看看效果,結果實際上看起來還是很不錯的,上1.5x的模型效果應該更好:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/397641.html
標籤:其他