作者|Nouman 編譯|VK 來源|Towards Data Science
在這篇文章中,我將教你建立你自己的網頁應用程式,它將接受你的狗的圖片,并輸出其品種,準確率超過80%!

我們將使用深度學習來訓練一個模型的資料集的狗影像與他們的品種,以學習的特征來區分每一個品種,
資料分析
資料集可以從這里下載(https://s3-us-west-1.amazonaws.com/udacity-aind/dog-project/dogImages.zip),在成功加載和瀏覽資料集后,以下是關于資料的一些介紹:
犬種總數:133
狗圖片總數:8351(訓練集:6680,驗證集:835,測驗集:836)
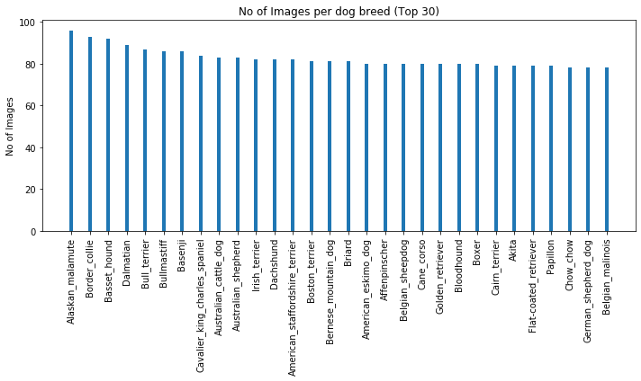
最受歡迎的品種:阿拉斯加:96,博德牧羊犬:93
按圖片數量排序的前30個品種如下:
我們還可以在這里看到一些狗的圖片和它們的品種:

資料預處理
經過分析,為機器學習演算法準備資料,我們將把每個影像作為一個numpy陣列加載,并將它們的大小調整為224x224,因為這是大多數傳統神經網路接受影像的默認大小,我們還將為影像的數量添加另一個維度
from keras.preprocessing import image
from tqdm import tqdm
def path_to_tensor(img_path):
'''將給定路徑下的影像轉換為張量'''
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
'''將給定路徑中的所有影像轉換為張量'''
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
最后,我們將使用ImageDataGenerator對影像進行動態縮放和增強
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=20)
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255.)
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255.)
train_generator = train_datagen.flow(train_tensors, train_targets, batch_size=32)
valid_generator = train_datagen.flow(valid_tensors, valid_targets, batch_size=32)
test_generator = train_datagen.flow(test_tensors, test_targets, batch_size=32)
CNN
我們將在預處理資料集上從頭開始訓練卷積神經網路(CNN),如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(224, 224, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(256, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(2048, activation='softmax'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1024, activation='softmax'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(133, activation='softmax')
])
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath='../saved_models/weights_best_custom.hdf5',
verbose=1, save_best_only=True)
model.fit(train_generator, epochs=5, validation_data=https://www.cnblogs.com/panchuangai/p/valid_generator, callbacks=[checkpointer])
我們使用一個ModelCheckpoint回呼來保存基于驗證分數的模型,測驗這個模型,我們得到的準確率只有1%左右
使用遷移學習
現在,我們將看到如何使用預訓練的特征可以產生巨大的不同,下載ResNet-50,你可以通過運行下面的代碼單元來提取相應的訓練集、測驗和驗證集:
bottleneck_features = np.load('Data/bottleneck_features/DogResnet50Data.npz')
train_Resnet50 = bottleneck_features['train']
valid_Resnet50 = bottleneck_features['valid']
test_Resnet50 = bottleneck_features['test']
我們現在將再次定義模型,并對提取的特征使用GlobalAveragePooling2D,它將一組特征平均為一個值,最后,如果驗證損失在兩個連續的epoch內沒有增加,我們使用額外的回呼來降低學習率,降低平臺,并且如果驗證損失在連續的5個epoch內沒有增加,也可以提前停止訓練,
Resnet50_model = tf.keras.models.Sequential()
Resnet50_model.add(tf.keras.layers.GlobalAveragePooling2D(input_shape=train_Resnet50.shape[1:]))
Resnet50_model.add(tf.keras.layers.Dense(1024, activation='relu'))
Resnet50_model.add(tf.keras.layers.Dense(133, activation='softmax'))
Resnet50_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath='saved_models/weights_best_Resnet50.hdf5',
verbose=1, save_best_only=True)
early_stopping = tf.keras.callbacks.EarlyStopping(patience=5, monitor='val_loss')
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(patience=2, monitor='val_loss')
Resnet50_model.fit(train_Resnet50, train_targets,
validation_data=https://www.cnblogs.com/panchuangai/p/(valid_Resnet50, valid_targets),
epochs=50, batch_size=20, callbacks=[checkpointer, early_stopping, reduce_lr], verbose=1)### 訓練模型
在測驗集上的準確率為82.65%,與我們白手起家訓練的模型相比,這是一個巨大的進步,
構建web應用程式
對于web應用程式,我們將首先撰寫一個helper函式,該函式接受影像路徑并回傳品種,label_to_cat字典將每個數字標簽映射到它的狗品種,
def predict_breed(img_path):
'''預測給定影像的品種'''
# 提取特征
bottleneck_feature = extract_Resnet50(path_to_tensor(img_path))
bottleneck_feature = tf.keras.models.Sequential([
tf.keras.layers.GlobalAveragePooling2D(input_shape=bottleneck_feature.shape[1:])
]).predict(bottleneck_feature).reshape(1, 1, 1, 2048)
# 獲得預測向量
predicted_vector = Resnet50_model.predict(bottleneck_feature)
# 模型預測的犬種
return label_to_cat[np.argmax(predicted_vector)]
對于web應用程式,我們將使用flaskweb框架來幫助我們用最少的代碼創建web應用程式,我們將定義一個接受影像的路由,并用狗的品種呈現一個輸出模板
@app.route('/upload', methods=['POST','GET'])
def upload_file():
if request.method == 'GET':
return render_template('index.html')
else:
file = request.files['image']
full_name = os.path.join(UPLOAD_FOLDER, file.filename)
file.save(full_name)
dog_breed = dog_breed_classifier(full_name)
return render_template('predict.html', image_file_name = file.filename, label = dog_breed)
predict.html是分別顯示影像及其犬種的模板,
結論
祝賀 你!你已經成功地實作了一個狗品種分類器,并且可以自信地分辨出狗的品種,讓我們總結一下我們在這里學到的:
我們對資料集進行了分析和預處理,機器學習演算法需要單獨的訓練集、測驗集和驗證集來進行置信預測,
我們從零開始使用CNN,由于未能提取特征,所以表現不佳,
然后我們使用遷移學習,準確度大大提高
最后,我們構建了一個Flask web應用程式來準備我們的專案產品
我們確實學到了很多東西,但還有很多其他的事情你可以嘗試,你可以在heroku上部署web應用程式,也可以嘗試使用不同的層(如Dropout層)來提高準確性,
要獲得更多資訊和詳細分析,請查看我的GitHub上的代碼:https://github.com/nouman-10/Dog-Breed-Classifier
原文鏈接:https://towardsdatascience.com/dont-know-the-breed-of-your-dog-ml-can-help-6558eb5f7f05
歡迎關注磐創AI博客站: http://panchuang.net/
sklearn機器學習中文官方檔案: http://sklearn123.com/
歡迎關注磐創博客資源匯總站: http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/39768.html
標籤:其他