作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/122203173
目錄
前言:
第1章 YOLO V2應運而生
1.1 YOLO V1的不足
1.2 YOLO V2的出現
1.3 YOLO V2的優點
1.4 YOLO總體的網路結構
1.5 YOLO V2的總體網路架構:Darknet網路
第2章 YOLO V2網路的圖片輸入
2.1 輸入圖片的尺寸的改進
2.3 多尺度輸入
2.4 圖片的標簽(用于Loss計算與反向網路訓練)
2.5 輸入圖片的預處理
第3章 YOLO V2 前向特征提取網路: 卷積網路
3.1 Darknet特征提取骨干網
3.2 細粒度特征提取: Fine-Grained Features
3.3 Batch Nomalization(BN)
第4章 YOLO V2 前向輸出網路:卷積層輸出
4.1 YOLO V2的輸出網路
4.2 YOLO V2對圖片區域的切分
4.3 YOLO V2對Bounding Box優化
4.4 先驗框Anchor的引入
4.5 每個網格包含的結構化的資訊
4.6 每個域的含義
4.7 所有網格,所有Bounding Box
第5章 前向輸出(預測階段)后處理:NMS非極大值抑制處理
第6章 YOLO V2 反向Loss計算與網路優化訓練
6.1 Loss函式的設計(核心、核心、核心)
6.2 優化演算法
第7章 YOLO V2的不足與改進
參考視頻:
前言:
本文重點講解YOLO V2對YOLO V1的改進,而不是介紹整個V2網路的所有演算法細節,
解讀本文時,請先參考YOLO V1版本的解讀,V1是YOLO所有后續版本的基礎:
https://blog.csdn.net/HiWangWenBing/article/details/122156426![]() https://blog.csdn.net/HiWangWenBing/article/details/122156426
https://blog.csdn.net/HiWangWenBing/article/details/122156426
第1章 YOLO V2應運而生
1.1 YOLO V1的不足
(1)每張圖片能夠進行分類數量太少,只有20種物體分類,
(2)檢測的目標的數量太少,一張圖只能檢測 7 * 7 = 49個目標,
YOLO V1只有 7 * 7 = 49個網格,每個網格只能檢測一個目標,整張圖,最大只能檢測49個目標,
如下的情形,YOLU V1就傻眼了,

(3)對重疊在一起的物體檢測性不好
YOLO V1每個網格只能檢測一個目標,當兩個物體的中心點,落在同一個網格時,就會丟掉一個物體,

(4)YOLO對小目標的檢測效果不好,
YOLO V1每個網格,只提供了2個先驗框,當多種不同尺寸的物體,同時出現在同一個圖片上時,YOLO對小目標的檢測就不盡如人意,YOLO沒有足夠多的先驗框去適配不同尺度的物體,
另一方面,多個小目標,很可能落在同一個網格內,而YOLO V1,一個網格只能檢測一個目標,這就導致,大量的小目標就丟失掉了,無法檢測,如下圖所示,兩只小麻雀落在同一個網格內,就只能當一個目標來檢測了,

另外,YOLO V1對小目標和大目標的Loss值,是組合在一起進行計算的,然后,相同的數值偏差,對小圖片和大圖片影響是不一樣的,這種方法,對于小圖片檢查的準確性造成了很大的影響,雖然已經采用了根號的方式,降低大目標與小目標數值上的差異,但并未消除,如果能夠使用相對誤差,或許對小圖更加的公平,
YOLO V2要嘗試解決上述問題,
1.2 YOLO V2的出現
(1) YOLO V2相對于YOLO V1版本,也不過就是一年的時間
(2)YOLO V2在整個目標檢測中的位置

1.3 YOLO V2的優點

這是YOLO V2的宣傳頁面,可以看出YOLO V2相對于YOLO V1帶來如下效果或性能上的改進,
(1)更好Better:更好的功能帶來更好的精度提升,

更好的功能,帶來更好的mAP精度提升,
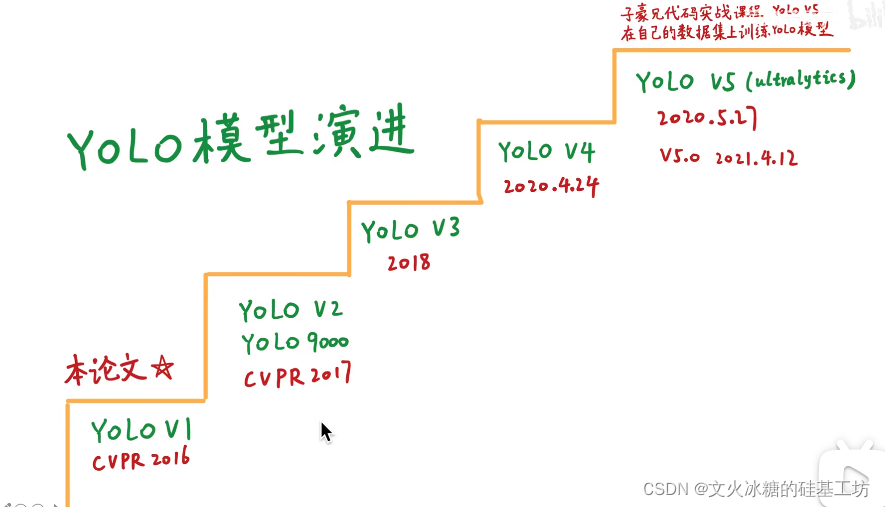
YOLO V1 mAP只有63.4, 經過YOLO V2各項改進后,YOLO V2的mAP高達78.6, 如下圖所示:
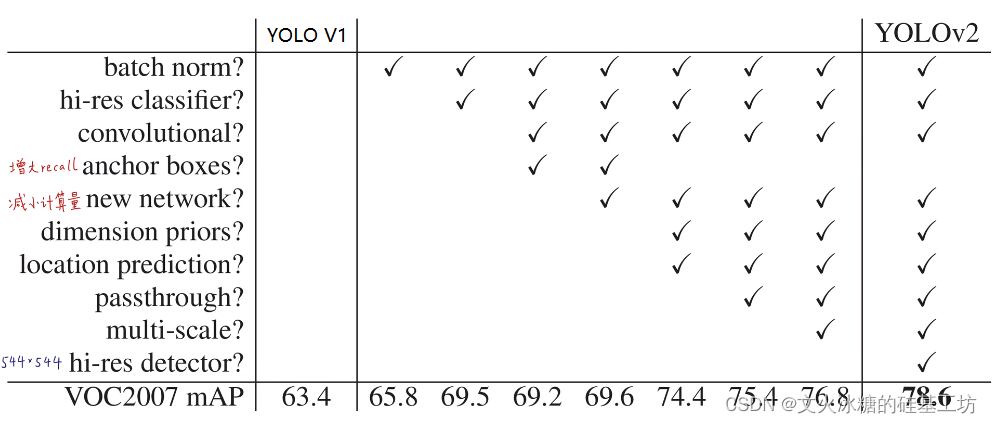
(2)更快Faster: 計算量減少,每秒處理的幀更多
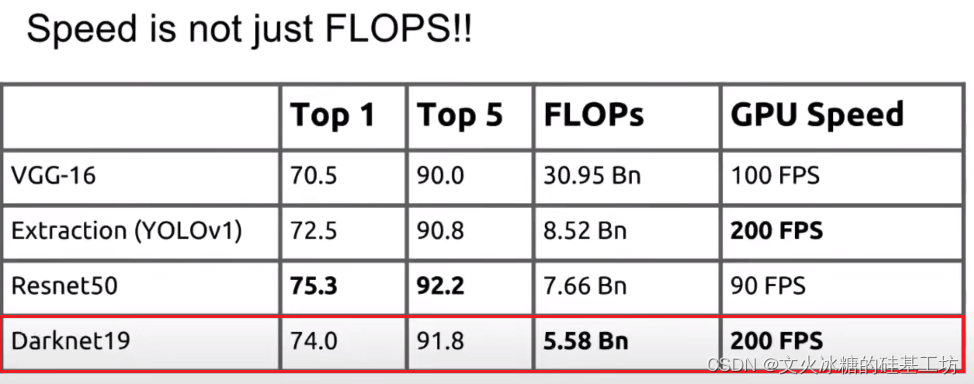
速度的提升,主要是靠更換骨干網路來實作的, 把V1的Resnet網路更換成了Darknet19.
Darknet19的計算量只有5.58 Bn,計算速度得到了極大的提升,

- 處理288 * 288圖片(低分比率)時,FPS高達91
- 處理416 * 416圖片(中解析度)時,FPS高達67
- 處理544 * 544圖片(高解析度)時,FPS高達40
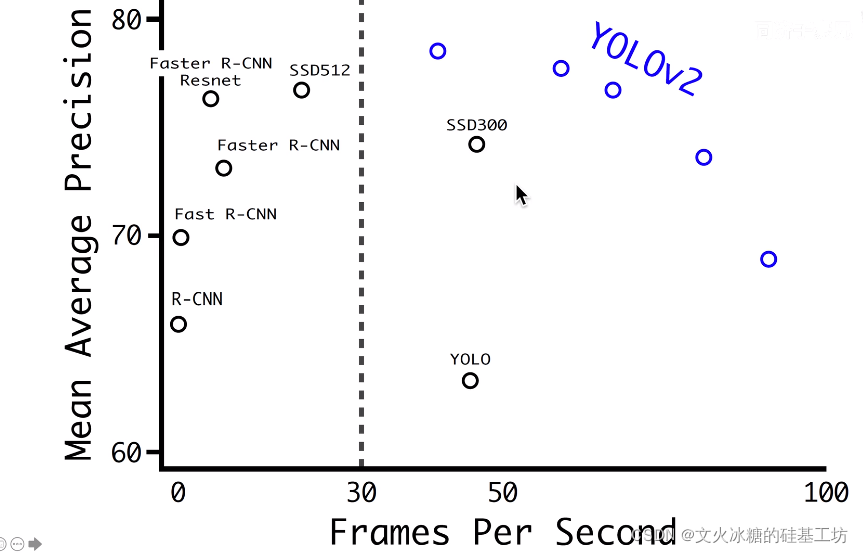
在相同精度的情況下, 相對于其他演算法(包括YOLO V1), YOLO V2的速度是最快的,
在相同速度的情況下, 相對于其他演算法(包括YOLO V1), YOLO V2的精度是最高的,
YOLO V2,無論在速度和精度上,都超過R-CNN系列演算法,
YOLO V1, 只在速度上超過R-CNN系列演算法, 而精度上不如R-CNN系列演算法,
(3)更強Stronger: YOLO 9000分類
YOLO V2宣稱能進行9000種分類,實際應用中,需要這么多種分類的場合也不多,
總之,相對于V1, V2的改進力度還是很大的,
1.4 YOLO總體的網路結構

(1) YOLO的核心演算法體現在:
- 結構化的輸出定義
- 損失函式的設計
(2)與目標檢測配套的地方體現在:
- 輸入圖片的標簽:定位目標的手工定位資訊 + 目標的分型別別
- 輸出圖片:原始圖片 + 添加的額外資訊(目標預測定位資訊 + 目標型別 + 可能性大小)
1.5 YOLO V2的總體網路架構:Darknet網路


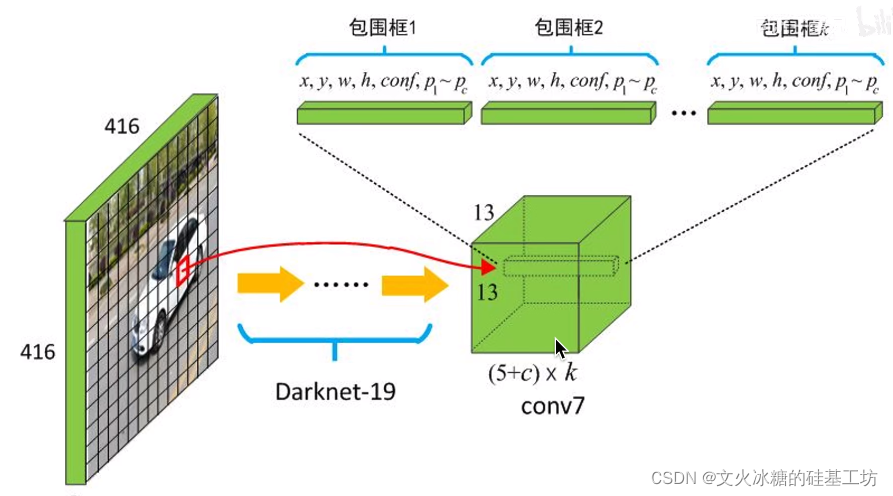
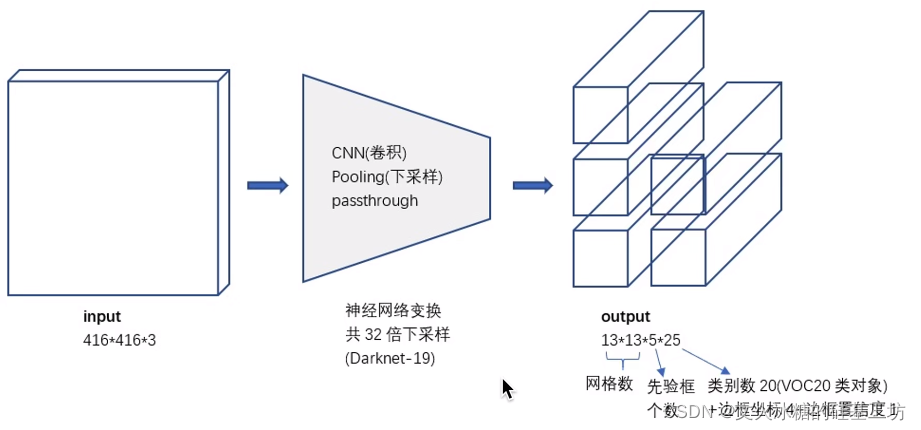
與YOLO V1不同的是:
- 特征提取網路結構不同:V1采用的ResNet骨干網,V2采用的是Darknet-19骨干網,
- 目標定位網路結構不同:V1采用的全連接層FC, V2采用卷積層,
Darknet骨干網是YOLO的作者為YOLO獨創的骨干網,
關于Darket網路,請參考相關文章 ,Darket本身不是本文的重點,
第2章 YOLO V2網路的圖片輸入
2.1 輸入圖片的尺寸的改進
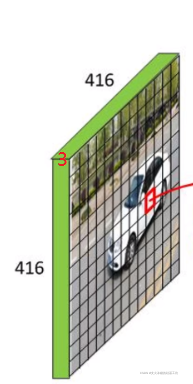
圖片的大小:V1 = 448 * 448 * 3, V2 = 416 * 416 * 3
2.2 高解析度分類(僅僅使用于分類,而不是目標檢測)

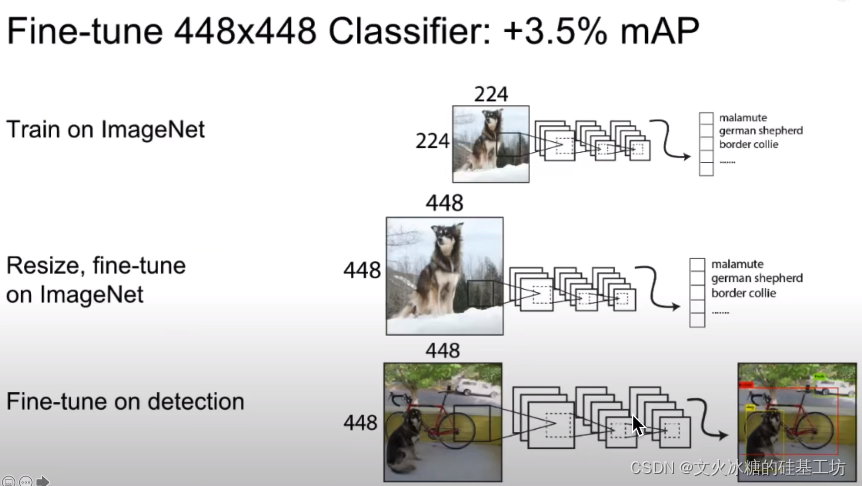
改進前:
- 使用Image Net原始的224 * 224圖片,來訓練YOLO V1的特征提取網路(骨干網路),
ImageNet資料集包含大量的分類標準的圖片,用該資料集,能夠很好地訓練出為進一步的分類或目標定位的特征提取網路,
- 然后使用448 *448的目標檢測的圖片,進一步fine tunning骨干網路和訓練目標識別網路,
改進后:
- 先把Image Net原始的224 * 224圖片,resize到448 * 448大小上,
- 然后用resize之后的448 * 448的圖片集,訓練YOLO V2的骨干網路,
- 最后使用448 *448的目標檢測的圖片,進一步fine tunning骨干網路和訓練目標識別,
- 這樣的改動,提升了性能,mAP直接提升3.5%
2.3 多尺度輸入
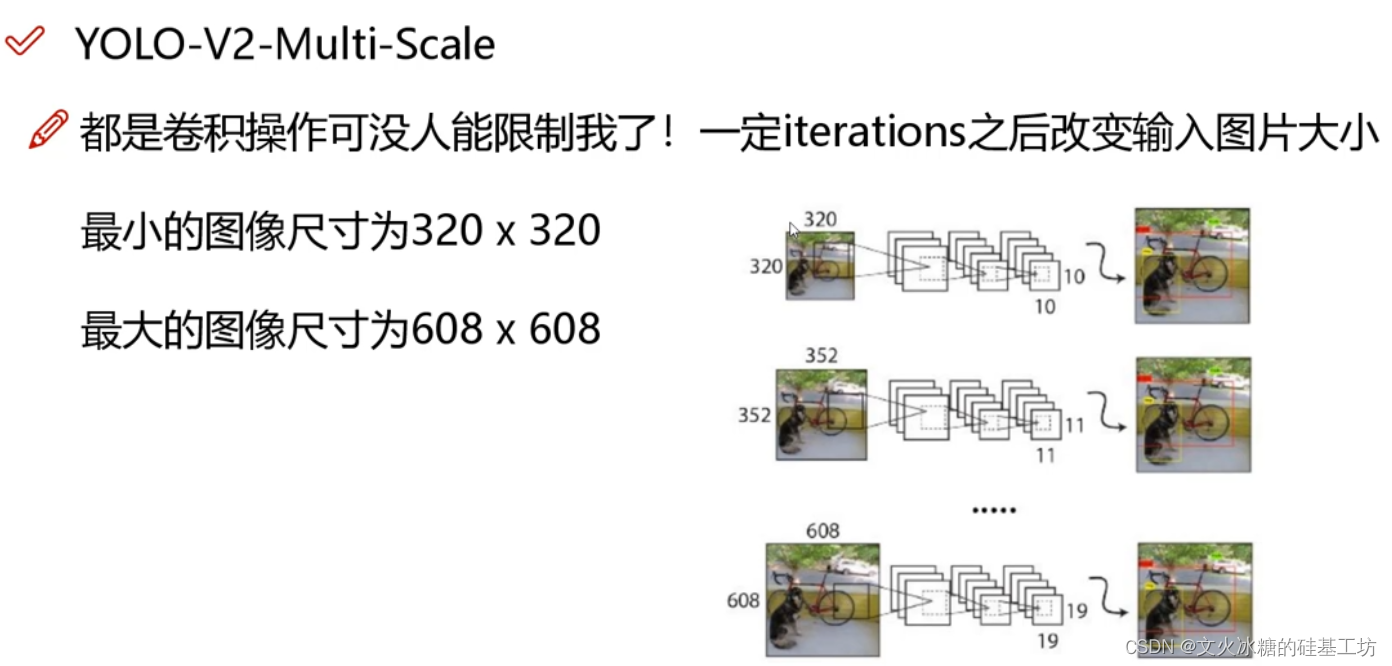
由于沒有了全連接層,YOLO V2除了支持標準的416 * 416 * 3尺度外,還支持其他尺度的輸入,
為了能夠使得網路的適應性更好,YOLO V2還定期采用其他尺度的圖片進行訓練,包括小尺寸的320 * 320和大尺寸的608 *608.
2.4 圖片的標簽(用于Loss計算與反向網路訓練)
相對于V1, V2沒有改進
2.5 輸入圖片的預處理
無特別的地方,與其他網路一致,
第3章 YOLO V2 前向特征提取網路: 卷積網路
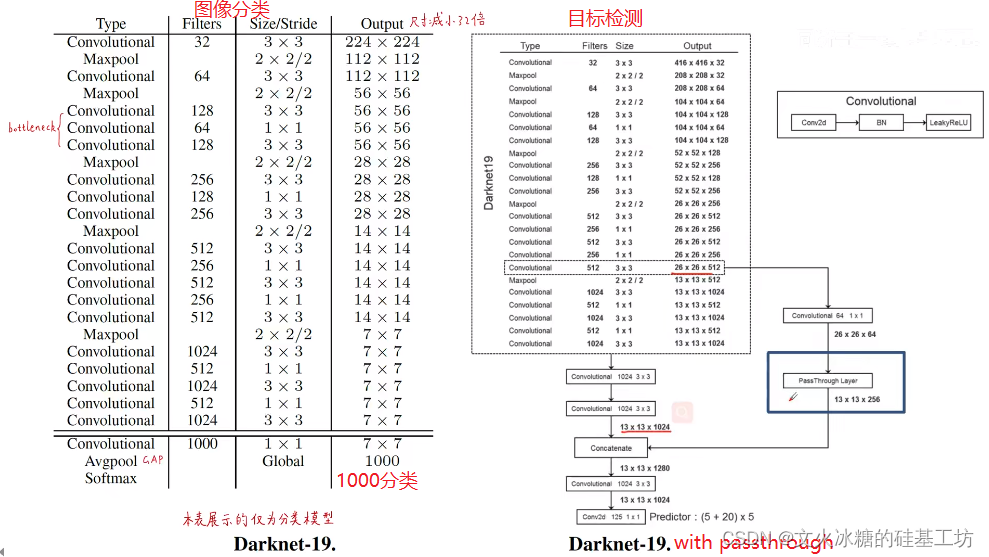
3.1 Darknet特征提取骨干網
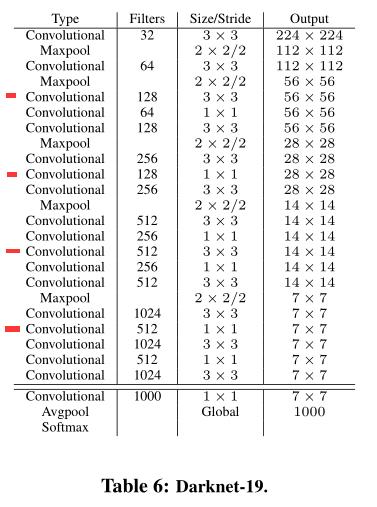
V2使用Darknet-19替代V1的RsetNet骨干網,進一步提升了YOLO V2的檢測速度,Darknet-19的FLOPs只有5.58Bn,特別適合硬體算力低的平臺,
3.2 細粒度特征提取: Fine-Grained Features
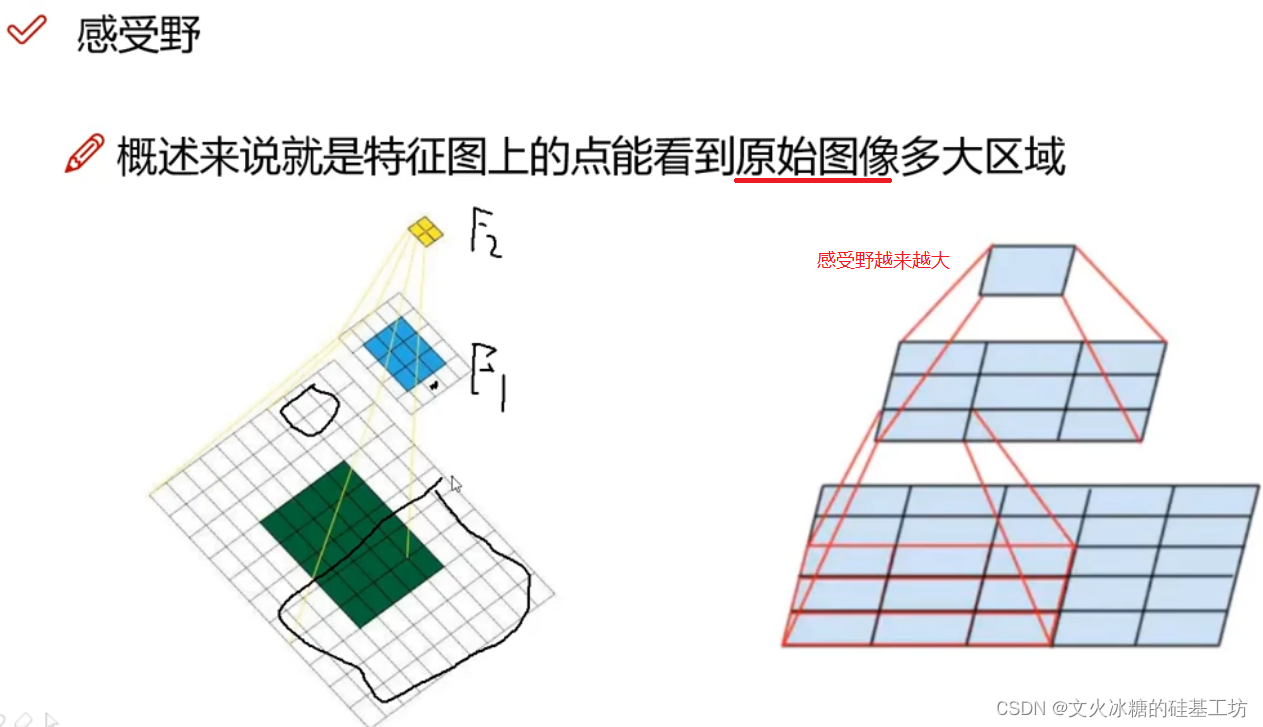
感受野反應了特征圖上的一個點,能夠感受到原始影像上像素點區域的大小,
越是接近輸入端,特征圖上的一個點的感受野越小,區域資訊越多,宏觀資訊越少,
越是遠離輸入端,特征圖上的一個點的感受野越大,區域資訊越少,宏觀資訊越多,
YOLO V1的定位與分類,是基于最后的特征輸出的資訊,因此YOLO對宏觀資訊把控比較好,對區域的微觀資訊容易忽略,導致YOLO V1對小目標識別不是太理想,經常檢測不到小目標,
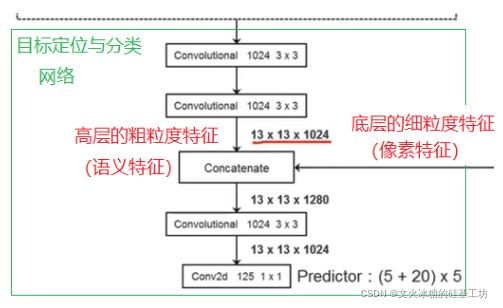
為了能夠克服YOLO V1對小目標識別能力弱這個特點,YOLO V2在在Darknet網路的基礎之上增加了一個細粒度特征提取的功能, 并通過pass through來實作的,如下圖所示:


目標定位和分類的輸入:
- 高層的粗粒度的語意特征(適合大目標)
- 底層的細粒度的像素特征(適合小目標)
這樣的網路設計,同時兼顧大目標和小目標的檢測,
3.3 Batch Nomalization(BN)

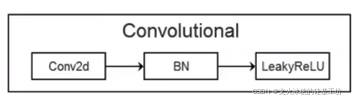
(1)增加BN網路,構成新的卷積單元Convolutional
在YoLOv2中,作者在每個卷積層后面都加上了BN(Batch Nomalization)層,它處于神經元與激活函式之間,對訓練收斂有非常大的幫助,同時也減少了所需使用的正則化處理,且可以移除dropout操作(解決過擬合)

增加了BN層后,卷積網路的基本單元變成如下形式:
(2)目的與解決的問題
- 遠離激活函式的飽和區,改善梯度,防止梯度消失、加快收斂
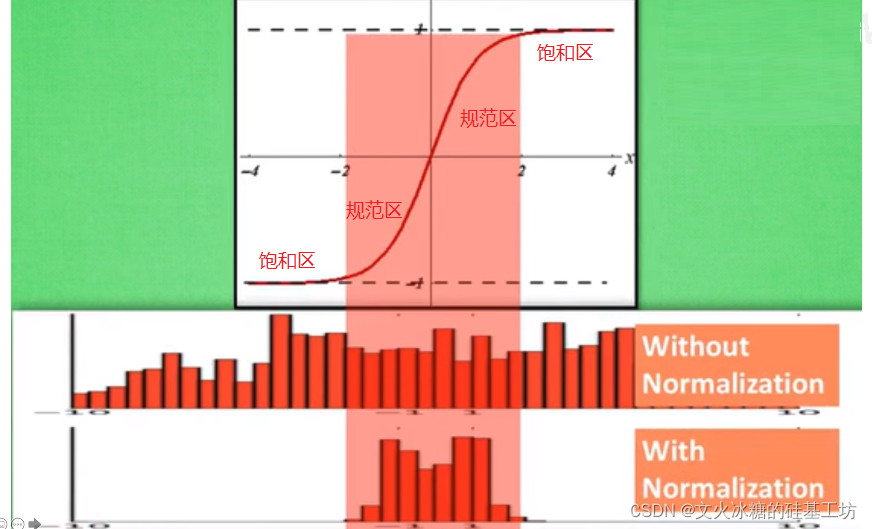
Nomalization通過規范化處理的函式,使得原先離散、發散的資料,根據的規范化和集中化,向中心點處集中,
- 與Dropout類似,防止過擬合,但不能與dropout同時使用,
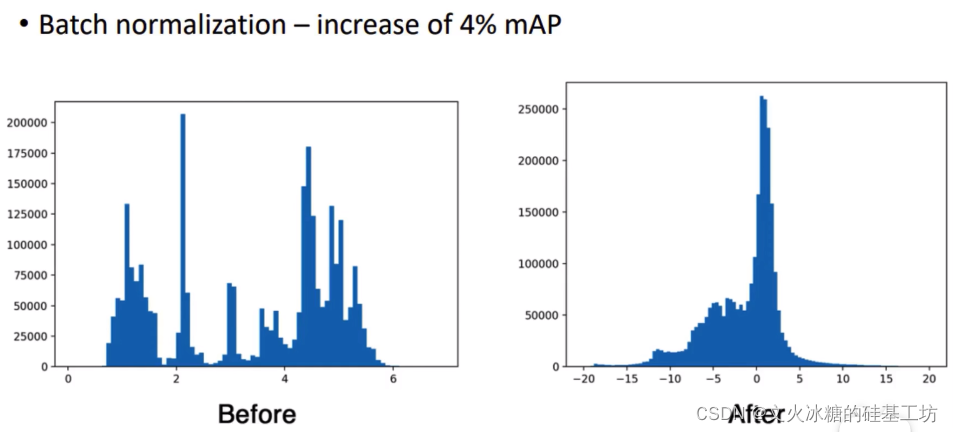
- 還能提升mAP 4%, 這是一個非常不錯的改進
(3)Nomalization:規范化的基本概念
https://blog.csdn.net/HiWangWenBing/article/details/121215445
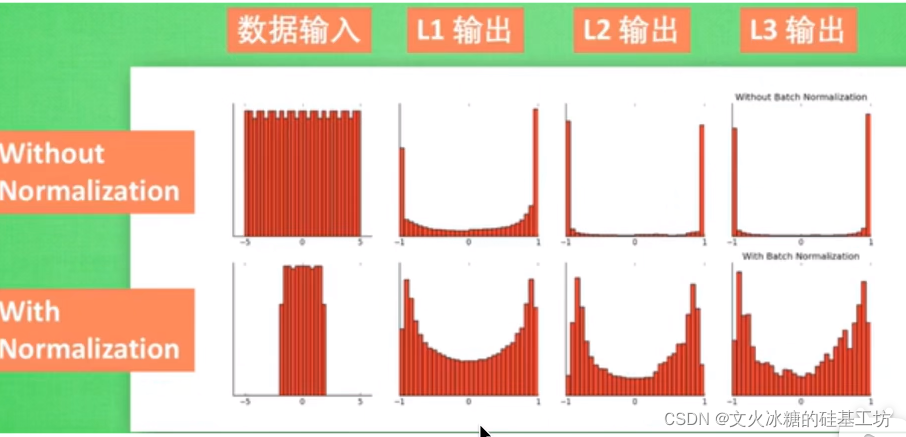
Nomalization的功能,使得上一級網路的輸出,即下一級網路的輸入的資料更加的規范化,如下圖所示:
(4)Batch Nomalization:
Batch是在bach層面進行的Nomalization,而不是單張圖片level進行Nomalization,
第4章 YOLO V2 前向輸出網路:卷積層輸出
4.1 YOLO V2的輸出網路
YOLO V2的輸出網路,由V1的全連接網路,直接更換成了V2的卷積網路,
4.2 YOLO V2對圖片區域的切分
(1)網格的數量定義

YOLO V2把網格的數量從V1的7個,直接升格到V2的13個,
(2)網格的作用
與V1相同,每個網格負責檢測:是否有物體(方框)的中心落在自己的網格內,如果有物體(方框)的中心點落在自己的網格范圍內,這該網格負責檢測該物體, 包括物體的尺寸 + 分類,
4.3 YOLO V2對Bounding Box優化
(1)增加了Bounding Box的數量:增加到5個
YOLO V1中,每個網格有2個Bounding Box,到YOLO V2中,增加到了5個Bounding Box,
(2)增加了Bounding Box能力:獨立進行物體分類
YOLO V1的兩個Bounding Box是共享相同的分類器,也就是說,YOLO V1雖然有兩個網格,兩個網格時相互配合,分時復用相同的分類器,導致每個網格同時只能檢測1個物體,
YOLO V2的5個Bounding Box擁有自己獨立的分類器,即每個網格可以獨立的檢測物體,這就意味著YOLO V2的每個網格可以同時檢測5個物體,
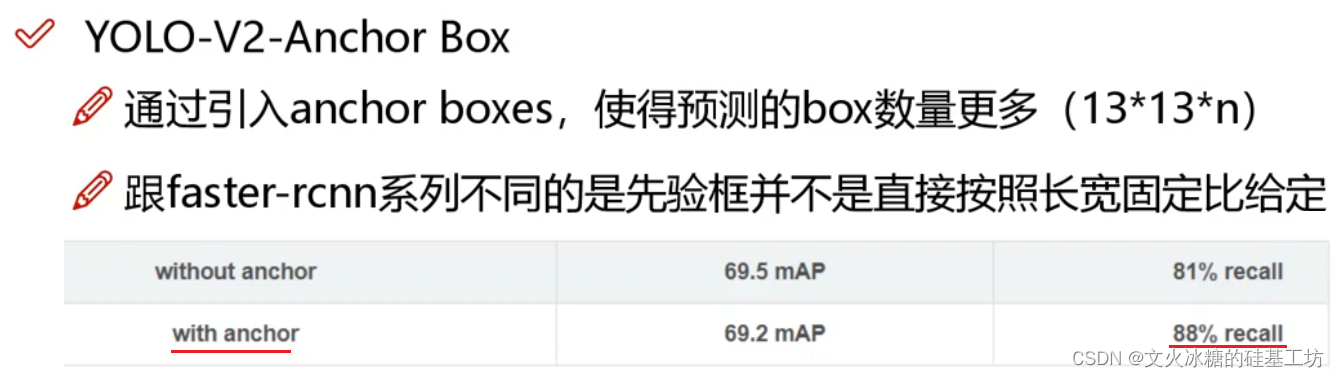
4.4 先驗框Anchor的引入
(1)什么是先驗框Anchor
先驗框Anchor是為了更好的初始化和管理5個Bounding Box,先驗框Anchor有如下幾個作用:
- 設定每個Bounding Box長度和寬度的初始值
- 作為每個Bounding Box長度和寬度增長的基準,訓練程序中,W,H值的變化是以Anchor框為基準偏移值,而Bounding Box長度和寬度并不是相對于0點的數值,
- 訓練的程序更容易收斂,訓練的速度更快、更準,
備注:
- Anchor是不包括Bounding Box的中心點的,因為物體在中心點的位置是任意的,
- Anchor本身代表“先驗框”,但它并不是用于預測的Bounding Box,而是Bounding Box的基準或初始值,
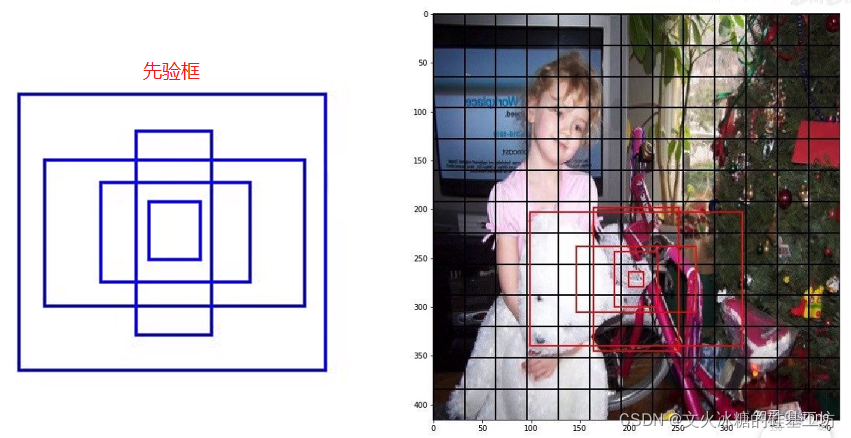
(2)Bounding Box與先驗框Anchor的關系
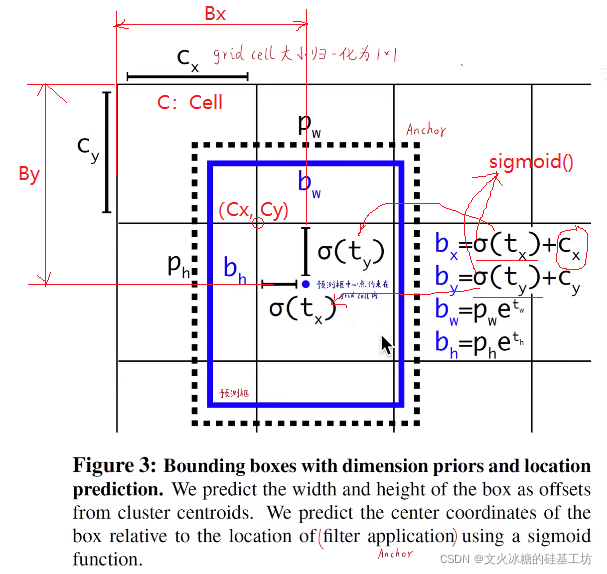
網格的歸一化:不管圖片的實際size有多大,每個網格都會被歸一化處理,每個網格的長度為1.
中心點:對Bounding Box的輸出用sigmod函式進行了(0,1)區間限制,這就導致,無論如何調整W, B的引數,Bounding Box最終的中心點一定會與其對應的Anchor,被限定在同一個網格grid cell中,
長度與寬度:Bounding Box長度和寬度是相對于Anchor中心點的offset,而不是相對于起點0的offset,也不是相對于Grid Cell的offset,且經過指數放大,目的是使長度和寬度更加的敏感,
(3) 先驗框的尺寸是如何設定的
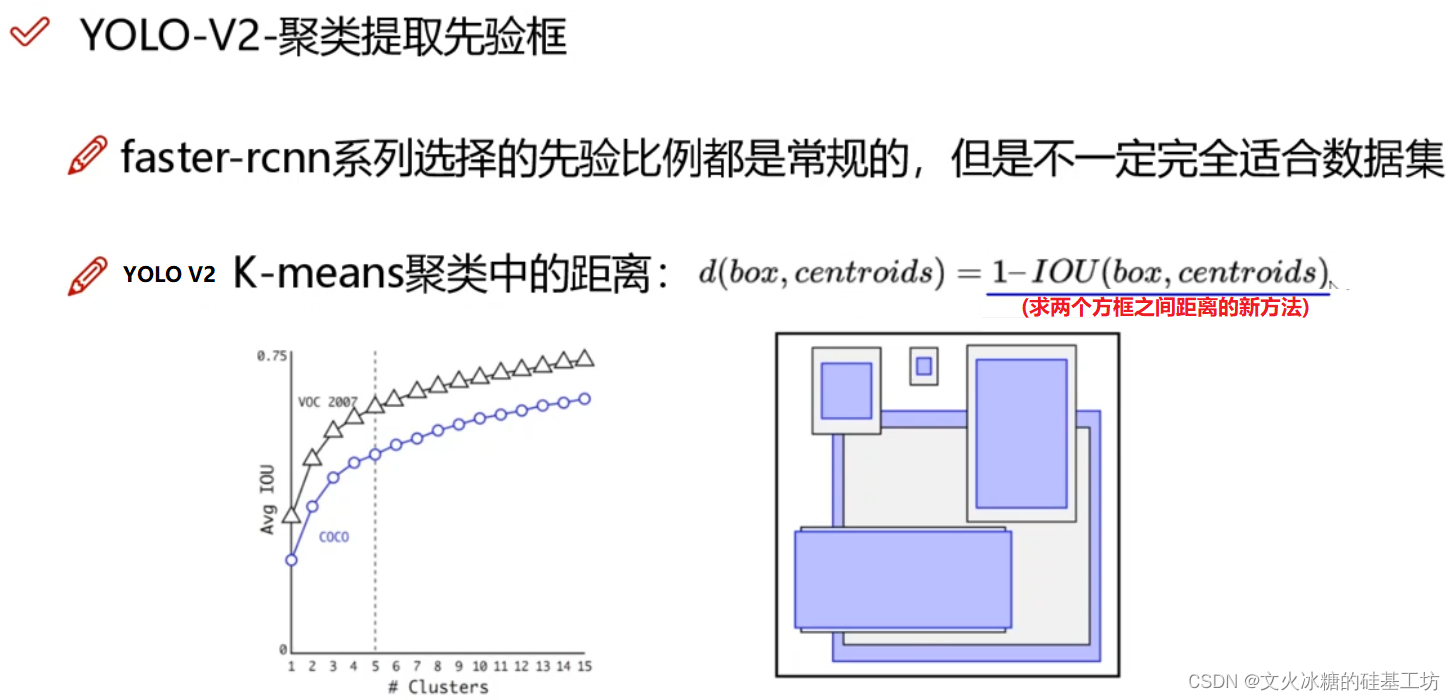
在Fast R-CNN中,先驗框的尺寸是人為固定設計的:如1:1, 2:1, 4:1, 1:4, 1:2,人為設定的最大缺點是:實際物體的尺寸與人為設定的不一定一樣,
然而,在YOLO V2以及后續的版本中,先驗框的尺寸是根據資料集中的實際物體的標注框統計獲得的,通過聚類演算法自動學習獲得的,如下圖所示,通過Clusters聚類演算法,分別獲得了VOC和COCO資料集上5種不同的框的大小,其作為YOLO的Anchor Box,也作為5個Bounding Box的初始值或參考值,
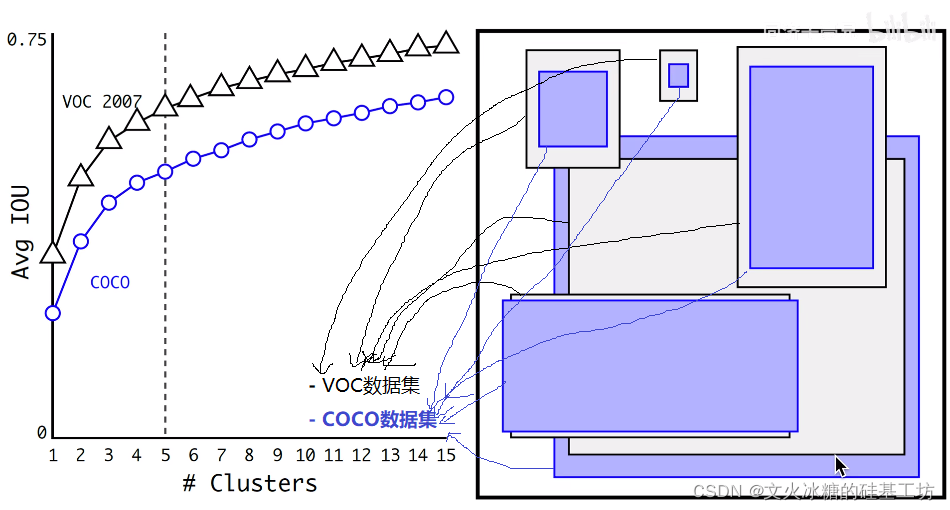
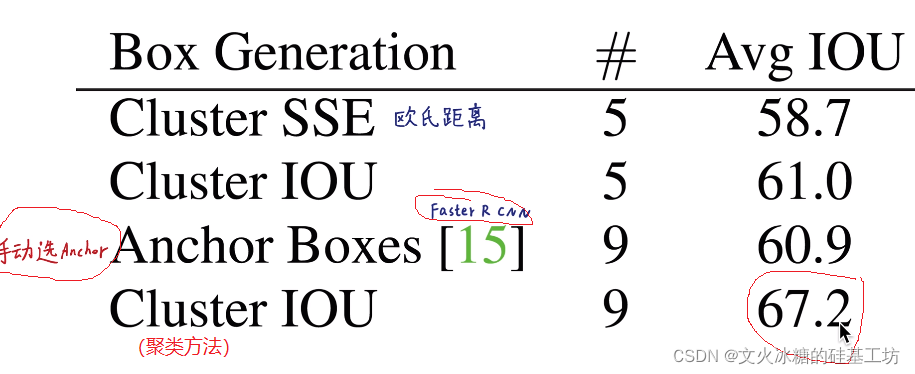
(4)先驗框的好處
4.5 每個網格包含的結構化的資訊
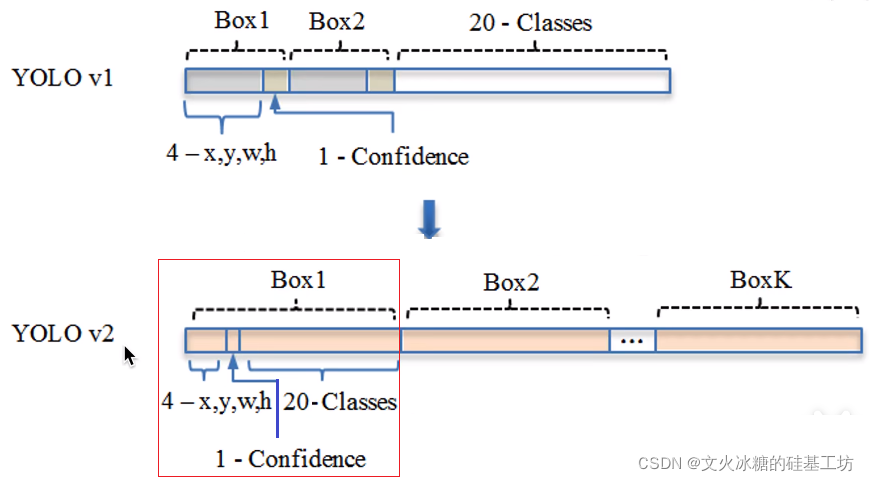
YOLO V1:每個grid cell包含的定位資訊是完整的,而每個Bounding Box包含的定位資訊是不完整的,兩個Boundding Box共享一個20分類輸出資訊,因此定位是基于grid cell的,一個grid cell只能定位一個目標,
從YOLO V2開始:5個Bounding Cell,每個Bounding Box包含的資訊是完整的定位資訊,不盡包括定位框的坐標,長度,寬度,置信度,還包括20分類資訊,因此每個grid cell可以同時進行5個目標的定位,
| V1 | V2 | |
| 網格的總數 | 7 * 7 = 49個 | 13 * 13 = 169個 |
| 每個網格bounding Box數量 | 2個 | 5個 |
| 每個網格可定位的目標的數量 | 1個 | 5個 |
| 每張圖可定位的目標的總數 | 49個 | 169 * 5 = 845個 |
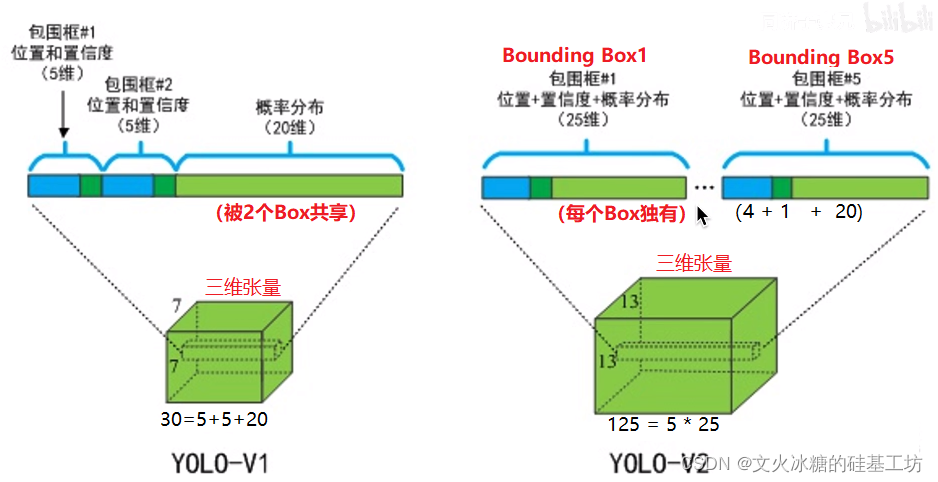
4.6 每個域的含義
與YOLO V1含義相同
4.7 所有網格,所有Bounding Box
V1: 7 * 7 * 2 = 98個bounding Box
V2: 13 * 14 * 5 = 845個bounding Box,定位框的數量提升了9倍左右,
第5章 前向輸出(預測階段)后處理:NMS非極大值抑制處理
(1)V2與V1相同的地方
- V2與V1對輸出資訊的流程相同
- V2與V1的輸出類別相同,都是20.
(1)V2與V1不相同的地方
- 總的框的個數不同: 49 -> 845
第6章 YOLO V2 反向Loss計算與網路優化訓練
6.1 Loss函式的設計(核心、核心、核心)
Loss函式的定義,直接反應了整個網路的輸入與輸出結構,

6.2 優化演算法
YOLO并沒有引入新的優化演算法,梯度下降法等優化演算法,也普遍適應于YOLO目標檢測,
第7章 YOLO V2的不足與改進
(1)mAP有待進一步提升,以超過人眼
參考視頻:
【精讀AI論文】YOLO V2目標檢測演算法_嗶哩嗶哩_bilibili
作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/122203173
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/398534.html
標籤:其他