目錄
- 前言
- 1 介紹
- 2 方法
- 2.1 資料集準備
- 2.2 特征提取
- 2.3 降維
- 2.4 分類
- 3 實驗結果及分析
- 3.1 模型對分類性能的影響
- 3.2 特征對分類性能的影響
- 4 結論
前言
?? 最近寫了一個python的圖片分類任務的作業,本篇博客是將我所做的流程所進行的整理,資料鏈接:百度網盤 提取碼:rkhw,HoG特征理論知識可參考這里,PCA降維可參考這里
1 介紹
?? 特征提取是影像處理中的一大領域,著名的提取演算法有HoG(Histogram of Oriented Gradient)[1]、LBP(Local Binary Pattern)[2]和Haar-like[3]等等,近些年來,隨著GPU算力的急速發展,深度學習也得到了迅速發展,使得影像特征提取的效率大大提升,各種分類任務的正確率不斷的重繪提升,而深度學習存在著較差的可解釋性和海量資料需求的問題,這是對機器視覺任務來說是偽命題,與之相反的是,傳統特征提取方法可視性非常強,且現有的卷積神經網路可能與這些特征提取方法有一定類似性,因為每個濾波權重實際上是一個線性的識別模式,與這些特征提取程序的邊界與梯度檢測類似,因此對我們的學習來說,傳統特征提取方法的學習是不可少的,本次實驗是基于HoG 的影像特征提取及其分類研究,
??HOG特征是一種在計算機視覺和影像處理中用來進行物體檢測的特征描述子,它通過計算和統計影像區域區域的梯度方向直方圖來構成特征,最早出現在2005年CVPR上,法國的研究人員Navneet Dalal 和Bill Triggs利用HOG特征+SVM進行行人檢測,在當時得到了較好的檢測效果,主要流程如下:

??本次的實驗也是基于上述流程進行一步一步實作,最終實作分類,
2 方法
2.1 資料集準備
??本次分類任務是對貓、狗、人臉、蛇四種類別的分類,收集每種類別各4000張圖片,其中87.5%作為訓練集,12.5%作為預測集,且每個類別的占比相同,灰度圖的形式讀取圖片,將圖片重塑大小至256×256,最后給資料集的車、狗、人臉、蛇分別打上1,2,3,4的標簽,以便訓練預測以及后續的性能評估,
2.2 特征提取
??1)采用不同的Gamma值(默認2.2)校正法對輸入影像進行顏色空間的標準化(歸一化),目的是調節影像的對比度,降低影像區域的陰影和光照變化所造成的影響,同時可以抑制噪音的干擾,2)計算影像每個像素的梯度(包括大小和方向),主要是為了捕獲輪廓資訊,同時進一步榷訓光照的干擾,本實驗使用Sobel算子進行計算,3)將影像劃分成小cells,因考慮到設備的性能及維度過大問題,而本實驗一個cell的大小為32×32個像素,3)統計每個cell的梯度直方圖(不同梯度的個數),形成每個cell的描述子,4)對每個cell的梯度方向進行投票,本實驗將cell的梯度方向180度分成9個方向塊即9個bins,每個bin的范圍為20,cell梯度的大小作為權值加到bins里面,5)本實驗將每四個cell組成一個block(2×2cell/block),一個block內所有cell的特征描述子串聯起來便得到該block的HOG特征描述子,6)將影像image內的所有block的bins串聯起來就可以得到該圖片的HoG特征向量,這一步中由于是串聯求和程序,使得梯度強度的變化范圍非常大,這就需要對block的梯度強度做歸一化,歸一化能夠進一步地對光照、陰影和邊緣進行壓縮,
2.3 降維
??在提取特征的步驟中,我們可以算出每一張圖片提取出的特征向量的維度是2×2×9×7×7等于1764維,這是較大的維數,里面包含了許多冗余資訊,所以我們應考慮對特征向量進行降維,本實驗實作的是PCA(主成分分析)演算法的降維,其主要程序如下:1)對所有樣本進行中心化: x i x_i xi?← x i x_i xi?- ∑ i = 1 n x i \displaystyle\sum_{i=1}^{n} x_i i=1∑n?xi?,2)計算樣本的協方差矩陣 x x T xx^T xxT,3)對協方差矩陣 x x T xx^T xxT做特征值分解,4)取最大的m個特征值所對應的單位特征向量: ω 1 , ω 2 , ? , ω m ω_1,ω_2,?,ω_m ω1?,ω2?,?,ωm?,5)得到投影矩陣,
2.4 分類
??本實驗的分類器利用了sklearn庫中的svm模型,設定不同的懲罰引數(默認1.0)和核函式(默認’rbf’)的型別進行多次訓練和測驗,
3 實驗結果及分析
??本實驗采用不同的懲罰程度、核函式、gamma校正值、特征維數的分類性能進行對比,采用了精確率、召回率和micro_F1分數對實驗結果進行性能評估,
3.1 模型對分類性能的影響
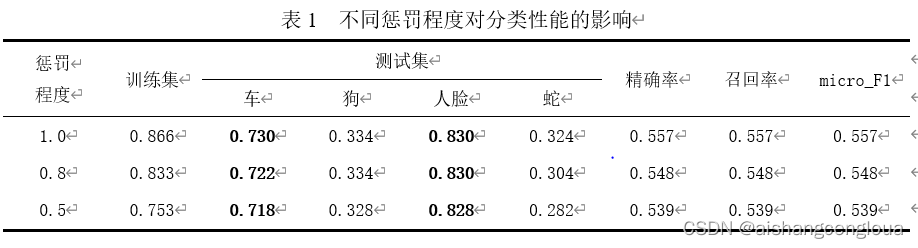
??不同懲罰程度的模型性能對比如表1所示,隨著懲罰程度的減少,也即松弛變數減小,訓練集的正確率從0.866降低至0.753,這是因為對誤分類的懲罰減小,允許容錯,按照理論來講此時模型的泛化能力應增強,但是精確率、召回率和micro_F1分數均從0.557減小至0.539,原因未能找到,此外,本實驗還統計了此特征提取方法對應的每一類的分類情況,從表1中我們可以看出在車和人臉兩類上精確率分別達到0.730和0.830左右,而狗和蛇兩類分類的效果很差,分別只有0.334和0.324左右,
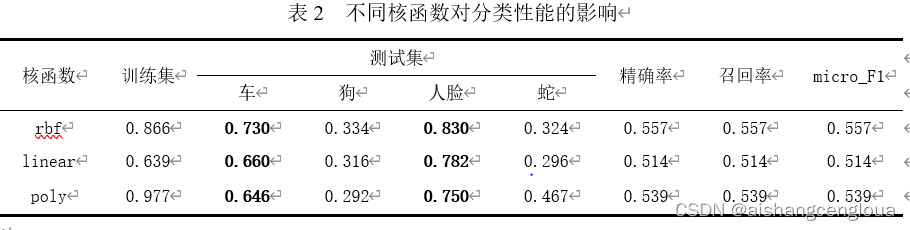
??不同和函式對模型性能的影響表2所示,在rbf、linear和poly三種核函式中,高斯核函式rbf的性能是最好的有0.557,這是因為訓練的維度是14000×404,樣本數n遠遠大于特征維數m,這也導致了linear性能最差;而多項式核函式poly的訓練集的精確率有0.977,原因是多項式的階數很高,網路變得更加復雜,但這也導致了過擬合,對于四種類別之間的分類精確率差異仍未得到很好的改善,
3.2 特征對分類性能的影響
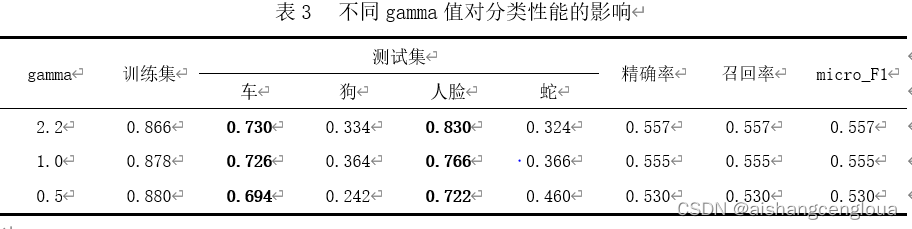
??不同gamma值對分類性能的影響如表3所示,隨著gamma值從2.2減小至0.5,模型性能由0.557減小至0.530,車、人臉兩類分類的精確率由0.730、0.830減小至0.694、0.722,蛇的精確率由0.324升至0.460,狗的精確率先有小幅度上升后減小至0.242,而訓練集的精確率由0.866升至0.880,說明模型存在較為明顯的過擬合問題,此外,車和人臉的分類精確率依然大幅度超過狗和蛇的分類精確率,
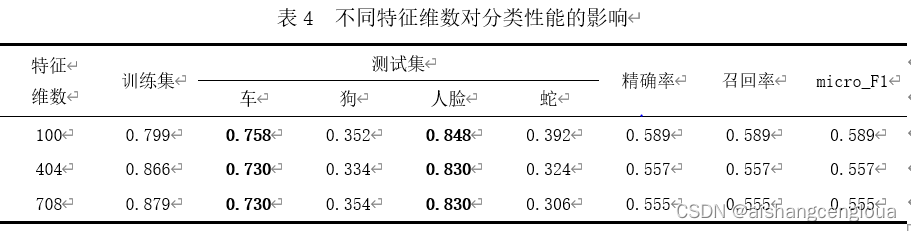
??不同特征維數對分類性能的影響如表4所示,特征維數由100增加至704,訓練集精確率由0.779增加至0.879,性能由0.589減小至0.555,四個類別的分類精確率出了狗均減小,原因是隨著特征維數的增大,保留了更多的冗余資訊,導致模型過擬合,
4 結論
??本實驗通過修改模型引數和特征提取引數來對比分類性能,從表1到表4,無論怎么修改引數,分類性能最高為0.589,始終未超過0.600,將四個類別的分類精確率進行統計,發現車和人臉的分類效果十分好,最高可以分別達到0.758和0.848,HoG特征與SVM的結合之所以對這兩類資料分類有較好的結果是因為HoG特征有對光照的不敏感,即使存在部分遮擋也可檢測出來、能夠反映人體的輪廓,并且它對影像中的人體的亮度和顏色變化不敏感的優點,因此HoG特征適合行人檢測和車倆檢測等領域,而本次實驗對狗和蛇的分類性能很差,最高分別只有0.354和0.467,原因可能是HoG無法從含有狗和蛇的圖片中有效提取它們的梯度和梯度方向,是否可以通過對圖片的預處理比如裁剪來提高精度,還需要后續的實驗,
[1] Dalal N , Triggs B . Histograms of Oriented Gradients for Human Detection[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE, 2005.
[2] Ojala T , Pietikainen M , Maenpaa T . Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns[C]// IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE, 2002:971-987.
[3] Papageorgiou C P , Oren M , Poggio T . General framework for object detection[C]// Computer Vision, 1998. Sixth International Conference on. IEEE, 1998.
代碼
import cv2 as cv
import numpy as np
import os
import random
import math
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
class HoG(object) :
def __init__(self, img, cell_w, bin_count) :
rows, cols = img.shape
img = np.power(img / 255.0, 2.2) * 255
self.img = img
self.cell_w = cell_w
self.bin_count = bin_count
self.angle_unit = 180.0 / bin_count
self.cell_x = int(rows / cell_w)
self.cell_y = int(cols / cell_w)
#求每個像素的x和y方向的梯度值和梯度方向
def Pixel_gradient(self) :
gradient_values_x = cv.Sobel(self.img, cv.CV_64F, 1, 0, ksize = 5)#x方向梯度
gradient_values_y = cv.Sobel(self.img, cv.CV_64F, 0, 1, ksize = 5)#y方向梯度
gradient_magnitude = np.sqrt(np.power(gradient_values_x, 2) + np.power(gradient_values_y, 2))#計算總梯度
# gradient_angle = cv.phase(gradient_values_x, gradient_values_y, angleInDegrees=True)#計算梯度方向
gradient_angle = np.arctan2( gradient_values_x, gradient_values_y )
gradient_angle[ gradient_angle > 0 ] *= 180 / 3.14
gradient_angle[ gradient_angle < 0 ] = ( gradient_angle[ gradient_angle < 0 ] + 3.14 ) * 180 / 3.14
return gradient_magnitude, gradient_angle
#求每個cell的x和y方向的梯度值和梯度方向
def Cell_gradient(self, gradient) :
cell = np.zeros((self.cell_x, self.cell_y, self.cell_w, self.cell_w))
gradient_x = np.split(gradient, self.cell_x, axis = 0)
for i in range(self.cell_x) :
gradient_y = np.split(gradient_x[i], self.cell_y, axis = 1)
for j in range(self.cell_y) :
cell[i][j] = gradient_y[j]
return cell
#對每個梯度方向進行投票
def Get_bins(self, cell_gradient, cell_angle) :
bins = np.zeros((cell_gradient.shape[0], cell_gradient.shape[1], self.bin_count))
for i in range(bins.shape[0]) :
for j in range(bins.shape[1]) :
tmp_unit = np.zeros(self.bin_count)
cell_gradient_list = np.int8(cell_gradient[i][j].flatten())
cell_angle_list = cell_angle[i][j].flatten()
cell_angle_list = np.int8( cell_angle_list / self.angle_unit )#0-9
cell_angle_list[ cell_angle_list >=9 ] = 0
# cell_angle_list = cell_angle_list.flatten()
# cell_angle_list = np.int8(cell_angle_list / self.angle_unit) % self.bin_count
for m in range(len(cell_angle_list)) :
tmp_unit[cell_angle_list[m]] += int(cell_gradient_list[m])#將梯度值作為投影的權值
bins[i][j] = tmp_unit
return bins
#獲取整幅影像的特征向量
def Block_Vector(self) :
gradient_magnitude, gradient_angle = self.Pixel_gradient()
cell_gradient_values = self.Cell_gradient(gradient_magnitude)
cell_angle = self.Cell_gradient(gradient_angle)
bins = self.Get_bins(cell_gradient_values, cell_angle)
block_vector = []
for i in range(self.cell_x - 1) :
for j in range(self.cell_y - 1) :
feature = []
feature.extend(bins[i][j])
feature.extend(bins[i + 1][j])
feature.extend(bins[i][j + 1])
feature.extend(bins[i + 1][j + 1])
mag = lambda vector : math.sqrt(sum(i ** 2 for i in vector))
magnitude = mag(feature)
if magnitude != 0 :
normalize = lambda vector, magnitude: [element / magnitude for element in vector]
feature = normalize(feature, magnitude)
block_vector.extend(feature)
return np.array(block_vector)
class PCA() :
def __init__(self, n_components) :
self.n_components = n_components
def fit(self, X) :
def deMean(X) :
return X - np.mean(X, axis = 0)
def calcCov(X) :
return np.cov(X, rowvar = False)
def deEigenvalue(cov) :
return np.linalg.eig(cov)
n, self.d = X.shape
assert self.n_components <= self.d
assert self.n_components <= n
X = deMean(X)
cov = calcCov(X)
eigenvalue, featurevector = deEigenvalue(cov)
index = np.argsort(eigenvalue)
n_index = index[-self.n_components : ]
self.w = featurevector[ : , n_index]
return self
def transform(self, X) :
n, d = X.shape
assert d == self.d
return np.dot(X, self.w)
class DataSet(object) :
def __init__(self, root, division) :
self.root = root
self.division = division
def data_segmentation(self, car, dog, face, snake) :
#將每一類圖片分割成訓練集和測驗集,四種類分別設定標簽是[1, 2, 3, 4]方便后續的性能評估
train_car, test_car = car[ : int(car.shape[0] * self.division)], car[int(car.shape[0] * self.division) : ]
train_car_target, test_car_target = np.full(len(train_car) , 1, dtype = np.int64), np.full(len(test_car) , 1, dtype = np.int64)
train_dog, test_dog = dog[ : int(dog.shape[0] * self.division)], dog[int(dog.shape[0] * self.division) : ]
train_dog_target, test_dog_target = np.full(len(train_dog) , 2, dtype = np.int64), np.full(len(test_dog) , 2, dtype = np.int64)
train_face, test_face = face[ : int(face.shape[0] * self.division)], face[int(face.shape[0] * self.division) : ]
train_face_target, test_face_target = np.full(len(train_face) , 3, dtype = np.int64), np.full(len(test_face) , 3, dtype = np.int64)
train_snake, test_snake = snake[ : int(snake.shape[0] * self.division)], snake[int(snake.shape[0] * self.division) : ]
train_snake_target, test_snake_target = np.full(len(train_snake) , 4, dtype = np.int64), np.full(len(test_snake) , 4, dtype = np.int64)
#將四類圖片拼接成一個大的矩陣
train_data = np.concatenate([train_car, train_dog, train_face, train_snake])
test_data = np.concatenate([test_car, test_dog, test_face, test_snake])
train_target = np.concatenate([train_car_target, train_dog_target, train_face_target, train_snake_target])
test_target = np.concatenate([test_car_target, test_dog_target, test_face_target, test_snake_target])
#以索引方式打亂訓練集
index = [i for i in range(len(train_data))]
random.shuffle(index)
train_data = train_data[index]
train_target = train_target[index]
return train_data, train_target, test_data, test_target
def datasets(self) :
#讀取每類圖片的名字
image_car = list(sorted(os.listdir(os.path.join(self.root, 'car'))))
image_dog = list(sorted(os.listdir(os.path.join(self.root, 'dog'))))
image_face = list(sorted(os.listdir(os.path.join(self.root, 'face'))))
image_snake = list(sorted(os.listdir(os.path.join(self.root, 'snake'))))
#儲存圖片
car = np.zeros((4000, 256, 256), dtype = np.uint8)
dog = np.zeros((4000, 256, 256), dtype = np.uint8)
face = np.zeros((4000, 256, 256), dtype = np.uint8)
snake = np.zeros((4000, 256, 256), dtype = np.uint8)
#讀取車、狗、人臉、蛇的圖片,進行resize至256 * 256
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'car', image_car[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
car[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'dog', image_dog[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
dog[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'face', image_face[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
face[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'snake', image_snake[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
snake[i] = img
print(car.shape, dog.shape, face.shape, snake.shape)
#分割
train_data, train_target, test_data, test_target = self.data_segmentation(car, dog, face, snake)
return train_data, train_target, test_data, test_target
def micro_f1(pred, target) :
#第一類
target1 = target.copy()
pred1 = pred.copy()
target1 = target1 == 1
pred1 = pred1 == 1
TP1 = np.sum(target1[pred1 == 1] == 1)
FN1 = np.sum(target1[pred1 == 0] == 1)
FP1 = np.sum(target1[pred1 == 1] == 0)
TN1 = np.sum(target1[pred1 == 0] == 0)
#第二類
target2 = target.copy()
pred2 = pred.copy()
target2 = target2 == 2
pred2 = pred2 == 2
TP2 = np.sum(target2[pred2 == 1] == 1)
FN2 = np.sum(target2[pred2 == 0] == 1)
FP2 = np.sum(target2[pred2 == 1] == 0)
TN2 = np.sum(target2[pred2 == 0] == 0)
#第三類
target3 = target.copy()
pred3 = pred.copy()
target3 = target3 == 3
pred3 = pred3 == 3
TP3 = np.sum(target3[pred3 == 1] == 1)
FN3 = np.sum(target3[pred3 == 0] == 1)
FP3 = np.sum(target3[pred3 == 1] == 0)
TN3 = np.sum(target3[pred3 == 0] == 0)
#第四類
target4 = target.copy()
pred4 = pred.copy()
target4 = target4 == 4
pred4 = pred4 == 4
TP4 = np.sum(target4[pred4 == 1] == 1)
FN4 = np.sum(target4[pred4 == 0] == 1)
FP4 = np.sum(target4[pred4 == 1] == 0)
TN4 = np.sum(target4[pred4 == 0] == 0)
TP = TP1 + TP2 + TP3 + TP4
FN = FN1 + FN2 + FN3 + FN4
FP = FP1 + FP2 + FP3 + FP4
TN = TN1 + TN2 + TN3 + TN4
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f1 = 2 * precision * recall / (precision + recall)
return precision, recall, f1, TP1, TP2, TP3, TP4
dataset = DataSet(root = 'data', division = 0.875)
train_data, train_target, test_data, test_target = dataset.datasets()
# print(train_data.shape, train_target.shape, test_data.shape, test_target.shape)
# print(test_target, train_target)
#HoG特征獲取
train_feature = []
test_feature = []
for i in range(len(train_data)) :
hog = HoG(train_data[i], 32, 9)
temp_feature = hog.Block_Vector()
train_feature.append(temp_feature)
for i in range(len(test_data)) :
hog = HoG(test_data[i], 32, 9)
temp_feature = hog.Block_Vector()
test_feature.append(temp_feature)
train_feature = np.array(train_feature)
test_feature = np.array(test_feature)
# print(train_feature.shape, test_feature.shape)
#PCA降維
# pca = PCA(n_components = 404)
pca.fit(train_feature)
train_reduction = pca.transform(train_feature)
test_reduction = pca.transform(test_feature)
print(train_reduction.shape)
print(test_reduction.shape)
#模型訓練和預測
clf = svm.SVC()
clf.fit(train_reduction, train_target)
print(clf.score(test_reduction, test_target))
print(clf.score(train_reduction, train_target))
pred = clf.predict(test_reduction)
precision, recall, f1, TP1, TP2, TP3, TP4 = micro_f1(pred, test_target)
print( precision, recall, f1, TP1, TP2, TP3, TP4)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/398540.html
標籤:其他
上一篇:畢業大論文到底怎么寫?