本文將會圍繞《ZooKeeper’s atomic broadcast protocol: Theory and practice》這篇論文講解 ZooKeeper 和 ZAB 的精髓之處,
📢📢📢大家好,我是周周,前幾周開組會時被點名回答一些 ZooKeeper 相關問題,竟然一問三不知,組長直呼當初被我帥氣外表所騙,稀里糊涂的招了進來,
于是下來后對這個在我手發揮極其重要作用的這項基建產生了濃厚興趣,所以決定痛改前非,先從 ZAB 出發,開啟一系列的 ZooKeeper 進階之旅,
tips:
本文主要是對 Paper 的消化和理解,稍顯枯燥,建議作業累了劃水時對著 Paper 慢慢看,
文章目錄
- 1 概述
- 1.1 什么是 ZooKeeper
- 1.2 什么是 ZAB
- 1.3 奔潰恢復模型
- 1.4 ZAB 的基本屬性
- 2 原子廣播協議
- 2.1 選舉階段
- 2.2 發現階段
- 2.3 同步階段
- 2.4 廣播階段
- 3 ZAB 協議實作
- 3.1 Discover
- 3.2 Fast Leader Election
- 選票 PK
- 接收選票
- FLE 演算法
- 演算法精髓
- 4 總結
1 概述
ZooKeeper 作為一項重要的基礎設施應用于各大廠商中,其可用性和可靠性不言而喻,而 ZAB(ZooKpeeper 原子廣播協議)更是保證 ZK 可用性和可靠性的基礎,也是本文主要的分享點,
1.1 什么是 ZooKeeper
在了解 ZAB 之前,我們要先了解 ZooKeeper 是究竟什么?
關于這個問題,ZK 官方給出了自己的定義:A Distributed Coordination Service for Distributed Applications,即 ZK 是一個為分布式系統提供協調能力的系統,
ZK 作用
- 配置服務
- 分布式鎖
- 服務管理
- 服務注冊與發現
資料模型
ZK 本質還是一個基于記憶體的 KV 系統,但與一般 KV 系統不同的是 ZK 以 Path 來作為 Key,以 DataTree 樹視圖來組織這些 Path,
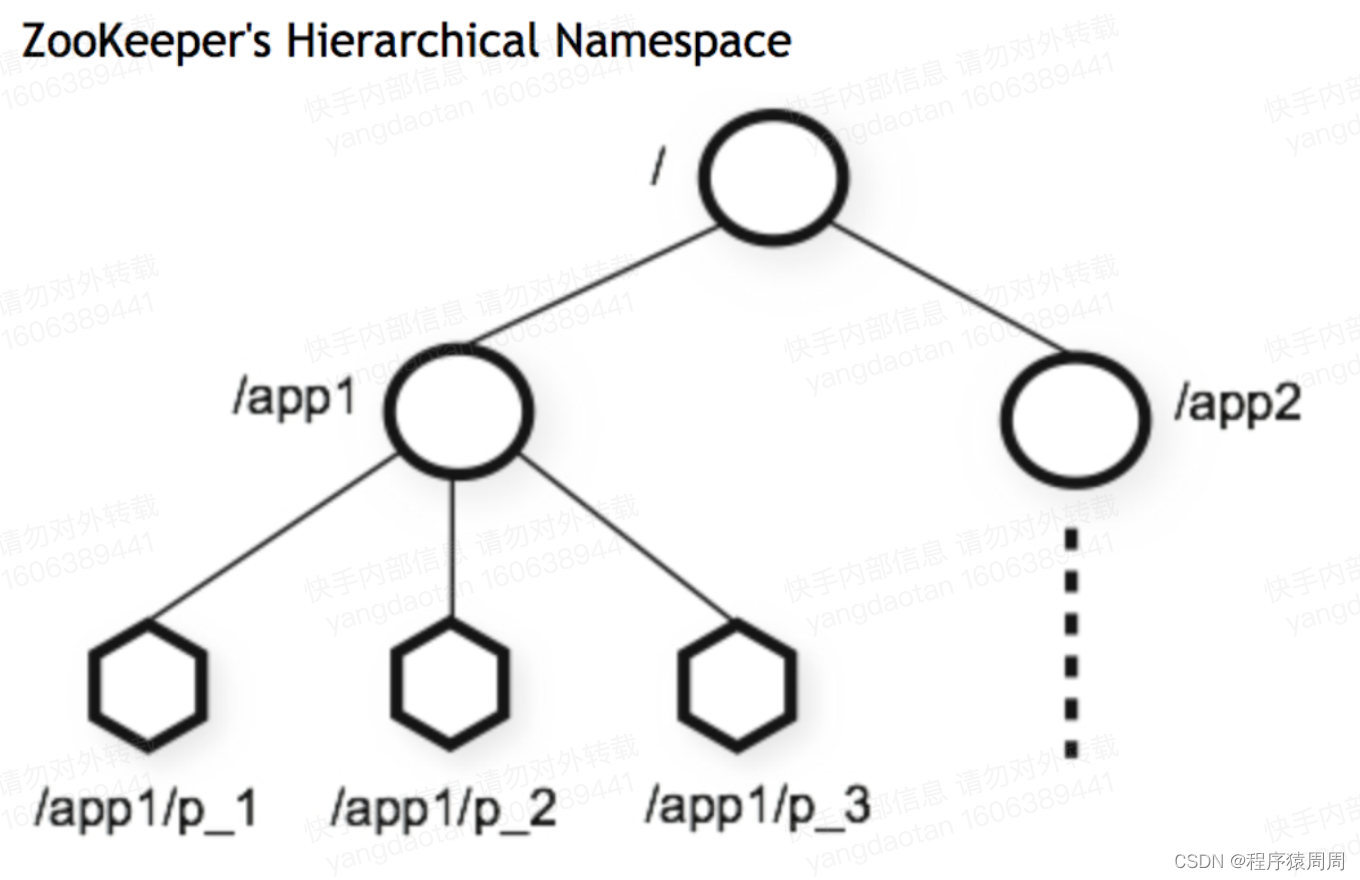
如上圖所示,資料資訊被保存在?個個的資料節點上,這些節點被稱為 ZNode,ZNode 是 ZooKeeper 中最?資料單位,在 ZNode 下??可以再掛 ZNode,這樣?層層下去就形成了?個層次化命名空間 ZNode 樹,
ZK 內部用 ConcurrentHashMap<String /*Path*/, DataNode> 來維持所有的 Path,每個 ZNode 會掛一個子節點的 Path 串列,
所以 ZK 對某個 Path 的插入和查詢性能很高,并不需要遍歷什么樹,是直接對 HashMap 的操作,
節點角色
- Leader 所有的寫操作均需要通過該節點完成
- Follower 處理讀請求和轉發寫請求給 Leader,并對 Leader 廣播的寫請求投票
- Observer 類似 Follower,但無投票權
1.2 什么是 ZAB
ZAB 協議是為 Zookeeper 專門設計的一種支持崩潰恢復的原子廣播協議,而 Paxos 是一種通用的分布式一致性演算法,故不能把 ZAB 和 Paxos 進行等同,
在 ZK 中主要依賴 ZAB 來實作分布式資料的一致性,從本質上講,ZK 也是一種主備模式(Leader-Follower-Observer)的系統架構,用來保持集群中各副本之間的一致性,即在 Leader 進行單點寫,同時也能在 Leader crash 后進行恢復重新選主,
ZAB 協議的核心是定義了那些會改變 ZooKeeper 服務器資料狀態的事務請求(Transaction)的處理方式,即:
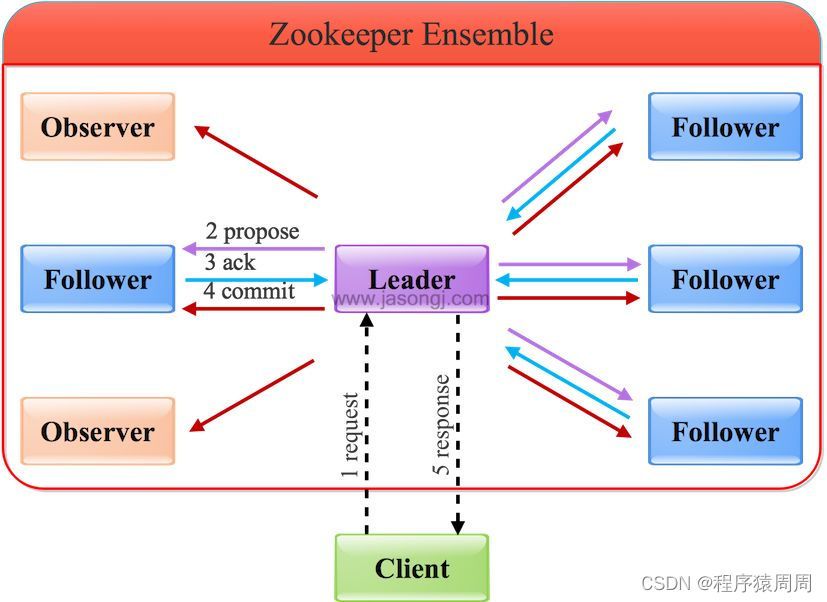
1)所有事務請求必須由一個全域唯一的服務器(Leader)來協調處理,剩余的服務器稱為 Follower(有權利參與選主)或者 Observer(只負責從 Leader 同步資料,用于讀擴展和分擔集群整體連接數),
2)Leader 負責將一個客戶端事務請求轉換成一個事務 Proposal(提議),并將該 Proposal 分發給集群中所有的 Follower 節點(Leader 會維持一個 Follower 串列),
3)之后 Leader 需要等待 Follower 的反饋,一旦超過半數的 Follower 進行了正確的反饋,Leader 則會對所有 Follower 發起 Commit 訊息,要求所有 Follower 將該 Proposal 進行提交(即寫入 Transaction Log),
- Refer 實體詳解ZooKeeper ZAB協議、分布式鎖與領導選舉
1.3 奔潰恢復模型
Crash-recovery system model
ZooKeeper 是一個奔潰恢復系統模型,即有能力從崩潰狀態中自我恢復,如某個節點掛掉或者 Leader 掛掉,只要過半的節點存活并且能通信就能保證 ZooKeeper 的高可用和高可靠能力,
假設系統是由 N 個行程組成 Π = {p1, p2, . . . , pN },每個行程稱為 Peer(節點),且節點之間能夠相互通信,并有各自的存盤來記錄事務日志和 DataTree 的快照,
Q (quorum of Π) 表示行程集合中的過半節點集合,滿足 Q ? Π 和 |Q| > N/2,任何的兩個 Q 必然會有 Peer 之間的交集,
行程有兩種狀態:up 和 down,ZK 節點什么時候提供寫能力呢?
一個 Follower 節點掛了重啟后不是立馬就能對外回應請求的,因為 Follower 落后 Leader 的 Proposal,只有待資料同步后才能對外提供服務,
所以 Peer 奔潰后到開始恢復前階段稱為 down 狀態,從開始恢復階段到下次奔潰稱為 up 狀態,
1.4 ZAB 的基本屬性
在崩潰恢復模型中,需要保證同一時刻只有一個 Leader 存在,每個時期(epoch)的 Leader 可以不同,如 p1.p2.p3....pe..., ρe ∈ Π,
每個 Proposal 用 <v, z> 表示,其中 v 是提交的新狀態值,z 則是 zxid,
zxid 用于唯一標示一個事務請求(Transaction),一個事務請求有兩種狀態:
- proposed 表示一個事務已經被 Leader 提出,但尚未被 Quorum 進行 ACK,
- commited 表示這個 Transaction 已經被 Quorum 進行 ACK,后續 Leader 對所有的 Follower 發出 commit 的請求,所有節點進行了本地 commit 操作,
因為,為了實作 ZooKeeper 副本的一致性,ZAB 需要滿足一下基本條件:
-
Integrity(正確性):如果有節點收到 commit Proposal(提交議案) 的請求,那么肯定是有節點對該 Proposal 進行了廣播,即 Proposal 不能是拜占庭問題,
-
Total order(全域順序性):,即某個 Peer 按序提交了
<v, z>和<v', z'>兩個 Proposal, 那么任意其它 Peer 上也必然是<v, z>比<v', z'>先被提交, -
Agreement(契約性):如果 Pi 提交了
<v, z>, Pj 提交了<v', z'>,那么要不 Pi 已經提交了了<v', z'>, 要不 Pj 已經提交了<v, z>,
此外,對于 Leader 節點而言,還需滿足其順序屬性:
- Local primary order(本地順序性):如果 Leader 在原子廣播階段先后 commit了
<v, z>和<v', z'>, 一個 Follower 提交了<v', z'>, 那么 Follower 肯定先提交了<v, z>, - Global primary order(全域一致性):如果 ρi 是 epoch 為 i 的 Leader,ρj 是 epoch 為 j 的 Leader,且 i < j, 表示 ρi 是之前的 Leader, ρj 是之后的 Leader,ρi 提交了
<v, z>, pj 提交了<v', z'>, 如果 Leader 提交了<v, z>和<v', z'>, 那么肯定是<v, z>先于<v', z'>被提交. - Primary integrity (正確性):ρi 如果廣播了<v, z> ,并且其他Follower commit了<v’, z’>,而<v’, z’> 是pj先于pi提交的,即pj的epoch比pi的epoch小,那么pi肯定也commit了<v, z>,
2 原子廣播協議
Atomic broadcast protocol
在了解原子廣播協議前,先來了解一些概念:
三種狀態
在 ZAB 協議中,每個服務器節點 Peer 有三種可能狀態:following、leading 以及 election,(其中處于 following 的節點稱為 Follower,處于 leading 的節點稱為 Leader)
四個階段
同時 ZAB 協議整體分為四個階段:0)Leader election、 1)discovery、 2)synchronization、 3)broadcast,
處于階段 0)到階段 2)的 ZK 集群還處于不可用的狀態,即不能回應客戶端的讀寫請求操作,只有選出主并完成上一個 epoch 期間的 Proposal 的廣播后,整個集群才會對外服務,也就是說只有處于階段3即原子廣播階段才能對外服務,
ZAB 的每個階段是順序推進的,如果在階段 1)-3) 任何一個階段出現故障,比如失敗或者超時,則會重新進入階段 0)再來一輪,
zxid
zxid 作為 ZooKeeper 最核心的一個概念,唯一標識一個 Transaction,即 Proposal 表示為 <value, zxid>,為了保證順序性,zkid 必須單調遞增,因此全域唯一遞增的 64 位正整數,所以 zxid 又由 <epoch, count> 構造,
epoch 是 zxid 的高 32 位,指的是每個 Leader 生命周期的一個標識,簡單來說就是年號,每次選出新的 Leader,epoch 就加一,
count 是低 32 位,標識一個 epoch 期間每個 Transaction ID,每個 epoch 的 count 都會從 0 開始遞增,
核心變數
1)history:被 Peer 提交的歷史 Proposal
2)acceptedEpoch:接收最新 NEWEPOCH 的 epoch
3)currentEpoch:接收最新 NEWLEADER 的 epoch
4)lastZxid:history 中最近一個提交的 Proposal 的 zxid
簡單的來說,acceptedEpoch 用于 Discovery 階段來判斷要不要接收新的 NEWEPOCH,currentEpoch 用于存放上個 epoch 的值,
這幾個值都會進行存盤,其中 acceptedEpoch 和 currentEpoch 會存盤在磁盤上,history 和 lastZxid 可以從 DataTree 的 snapshot 中恢復,
2.1 選舉階段
Leader Election
這個階段的目的是選出一個 Leader,然后進入后續階段,具體的演算法將會在后續 ZK 的實作小節中闡述,也就是 FLE(Fast Leader Election)演算法,
2.2 發現階段
Discovery
該階段的目的就是確定一個新 Leader 的 epoch 值,然后找到上個 epoch 周期內擁有最大 zxid 的 Follower 節點,之所以可以取最大 zxid 作為新的 Leader 的 history,是基于一個假設,因為 zxid 是全域遞增的,也就是擁有最大 zxid 的節點也擁有了最新的 Proposal 提交記錄,

具體流程如下:
1)Follower 向準 Leader 發送一個 FOLLOWERINFO 型別訊息,將自己的資訊上報給準 Leader,該資訊包括自己的 epoch 內容 F.acceptedEpoch,
2)Leader 等待收到過半的 FOLLOWERINFO 訊息后,從這些 Follower 節點的 acceptedEpoch 中取出最大的 epoch,并且加1,即 newEpoch = max {F.acceptedEpoch} + 1,再將新的 epoch 資訊 NEWEPOCH 發給集群中的節點,
3)Follower 收到 NEWEPOCH 后,將新的 epoch 與自己的 epoch 比較:
- 新 epoch > acceptedEpoch, 即更新自己的 acceptedEpoch為 為新 epoch,然后給 Leader 發送一個 ACKEPOCH 資訊,該資訊包括上個 epoch、history 和 lastZxid,
- 新 epoch < acceptedEpoch,則回退到階段0
4)Leader 收到所有 Follower 的 ACKEPOCH 后,從中找出 currentEpoch 最大的或者 lastZxid 最大的 Follower,把該 Follower 的 history 作為自己的 history,
值得注意的是,Quorum 是包括 Leader 自身的,這里的 Leader 還只是準 Leader,
2.3 同步階段
Synchronization
同步階段的目的就是準 Leader 需要將最新的 history 同步給集群內所有的 Follower,

1)在上階段準 Leader 拿到過半的 ACKEPOCH 后,也就是有了最新的 Proprosal history,
2)Leader 給所有 Follower 發一個 NEWLEADER 型別訊息,把最新的 epoch 和 histroy 帶過去,
3)Follower 收到 NEWLEADER 訊息后,判斷自己的 acceptedEpoch 和新 epoch 是否相等,
-
如果相等則表示自己已經跟上了新 epoch,那么更新自己的 currentEpoch 為新 epoch,表示進入新的朝代,同時按照 zxid 的大小逐一進行本地 proposed(此時這些 Transaction 還未 commit),然后更新history,回傳一個 ACKNEWLEADER 訊息表示已經同步完資料,
-
如果不相等,那么退回到選舉階段,重新進行選主,
3)Leader 收到集群中節點的 ACKNEWLEADER 后,對 history 中的這些 Proposal 進行 commit,即向所有 Follower 發送 commit 請求,
4)Follower 收到 Leader 對 history 的 COMMIT 訊息后,對于 outstanding(即已經 proposed,但還未 commit)的事務按 zxid 順序進行 commit,
5)Leader 和 Follower 都完成資料同步后進入廣播階段.
2.4 廣播階段
如果所有節點都安然無恙,那么集群就會永遠停留在這個階段,也就是原子廣播階段,該階段才真正對外通過服務,也就是開始接收外界寫請求(Transaction),
這個階段不可能會存在雙主,但可以加入新的 Follower 或 Observer 節點,

發起 Proposal 流程
1)Leader 在接收到 write 請求后,生成一個 Proposal <value, zxid>, zxid = lastzxid + 1,然后對集群 Quorum 中的 Follower 節點發起 propose 請求
2)Follower 接收到 propose 請求后,將 Proposal 放入自己 history 佇列中,并回傳 ACK
3)Leader 收到過半的針對 Proposal 的 ACK 后,認為獲得了大部分的同意,則對 Proposal 進行提交,向所有 Follower 發起 COMMIT 請求
4)Follower 收到 Propose <value, zxid> 的 COMMIT 請求后開始提交,但是為了滿足 zxid 的全域一致性,如果存在比該 zxid 更小的 zxid‘ 還未提交,那么需要等待 zxid’ 的 Propose <value', zxid'> 被提交
新增 Follower 流程
1)新加入的節點會給 Leader 發一個 FOLLOWERINFO 請求
2)Leader 收到 FOLLOWERINFO 請求后會回復 NEWEPOCH 和 NEWLEADER,即告訴 Follower 當前的 epoch 和 history
3)新節點收到 NEWLEADER 后,如果正常邏輯處理后,回一個 ACKNEWLEADER 給 Leader
4)Leader 收到 ACKNEWLEADER 后給該新節點一個 COMMIT 請求,讓新節點提交 history
5)Leader 最后把新加入的 Follower 節點放入自己的 Quorum 串列中,
值得注意的是:
- 整個 propose 程序是并行的,對于 Leader 來說,一個 Proposal 不會等上一個 commit 才會發起新 Proposal 的 propose 請求
- 每個 Peer 進行本地 commit Proposal 的時候是有序的,即 zxid 小的需要先 commit,這也是為了保障全域順序性
3 ZAB 協議實作
在 ZooKeeper 實作原子廣播協議中,對上面描述的幾個階段進行了優化,如圖所示:
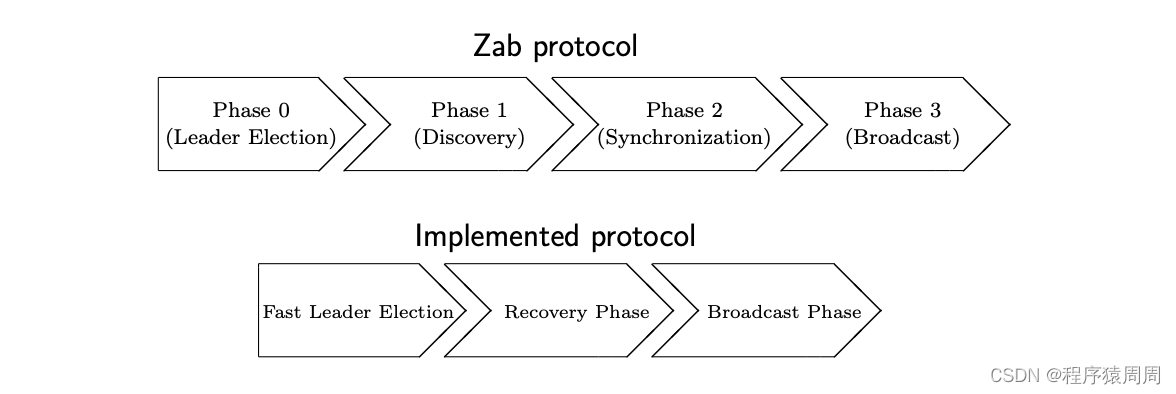
ZK 將階段 0)選主和階段 1)發現合二為一,實作為 Fast Leader Election 階段,其演算法核心內容是嘗試選出一個擁有最新 history 資料(即最大 lastZxid)的節點作為 Leader,這樣就可以把 Discovery 階段省掉,
同時 ZK 還針對階段 2)同步進行了一些調整,實作為發現階段,接下來我們將詳細描述這兩個階段的具體實作,
3.1 Discover

當 ZK 集群進入到恢復階段,Leader 節點已由 FLE 階段選舉出來,并且擁有最大的 zxid,
為了將集群中節點資料恢復到一致,Follower 將處理來自準 Leader 的三種請求:
- SNAP:從 Leader 拉一份 snapshot(快照),再進行本地提交
- DIFF:提交請求體中的 Proposal
- TRUNC:Follower 節點丟棄
Leader.lastCommitedZxid~lastZxid之間所有的 Proposal
接下來的主要流程:
1)Leader 從 lastZxid 中拿出 epoch 進行加 1 作為新的 epoch,并且低 32 位重置為 0,即 LastZxid ← {lastZxid.epoch + 1, 0},
2)Follower 連接上準 Leader 節點后,向其發送攜帶自己 lastZxid 的 FOLLOWERINFO 資訊,如果 Leader 拒絕了連接,可能是因為 Leader 的 epoch 比自己小等原因,那么 Follower 重新將狀態設定回 election,回退到FLE階段,
3)Leader 接收到 Follower 請求后,發送 NEWLEADER 資訊給 Follower,
4)如果 Follower 的 lastZxid 小于 Leader 中的 lastCommittedZxid,證明 Follower 的提交落后于 Leader,需要同步:
- 如果 Follower 的 lastZxid 比 Leader 設定的同步 DIFF 閾值還小,需要同步整個 snapshot,即向 Follower 發一個 SNAP 型別訊息
- 否則 發送一個 DIFF 型別訊息,訊息內容是 Leader 已經提交的 history 中的那些 diff 的議案
5)Follower 收到準 Leader 的 NEWLEADER 請求后,需要對比 epoch:
- 如果 NEWLEADER.newLeaderZxid.epoch 比當前小,那么不能認可該 Leader,自己更新為選主狀態,重新選主
- 如果 epoch 是同一個輪次中,那么則需要處理 SNAP、DIFF 和 TRUNC 請求
- 完成同步后,回傳一個 ACKNEWLEADER 訊息,進入廣播階段
6)Leader 收到集群大部分 Follower 節點的 ACKNEWLEADER 后,表示過半節點完成了同步,也進入階段3——廣播階段,
至于為什么出現 TRUNC 請求,原因很簡單,因為出現了一個有意思的例子:https://issues.apache.org/jira/browse/ZOOKEEPER-1154
3.2 Fast Leader Election
FLE 演算法的核心是在集群 Quorum 中找出 lastZxid 最大的那個節點,那么每個節點之間需要同步選票,就需要幾個核心資訊:
- id:投票節點的 myid(在組態檔中配置)
- vote:被投票節點的 myid
- state:投票節點的狀態,可以是 leading、following 或 election(只有重新發起新一輪 FLE 后才會變更為 election)
- round:投票輪次,每一輪 FLE 都會有一個 round,并在之前基礎上加 1
選票 PK
我們將定義 Vote(zi , i) 表示一次投票,即 myid 為 i 的節點當前 zxid 是 zi,同時定義 Vote 間的優劣: (zi, i) > (zj, j), 滿足zi > zj || (zi = zj && i > j),通俗來說,zxid 大的優先,誰大選誰,zxid 相同時再比較 myid,大的優先,
所以我們在配置 ZK 集群時,需要給每個節點配置一個全域唯一的 myid,
接收選票
在 FLE 階段,集群中每個節點都會維護一個串列當做 “投票箱” 以存放其他節點的選票資訊,當然,也包括節點自身的選票,ZK 還會啟動一個執行緒以便發送自身選票和接收其他節點的選票,同時還會根據對方選票記錄和變更自己的狀態和選擇,

1)如果當前節點是選主(election)狀態,則先將對方投票資訊放入串列中
2)如果對方節點狀態也是選主,那么將先比較一下選舉輪次(round),如果當前節點輪次小于對方節點,則通知對方自己的投票資訊
3)如果當前節點非選主狀態,說明當前節點已經是 Leader 或 Follower,且對方節點還是選主狀態的話,則需要告知對方當前節點的狀態
4)如果雙方都非選主狀態,則代表這一輪選舉結束
整個流程的精髓在于:記錄對方的選票,然后互通有無,
FLE 演算法

先看主流程:
1)節點 P 在啟動初始化后,會投票給自己,即投票是 vote <P.zxid, P.myid>,此時round = round + 1,就是 1,
2)然后開始給所有節點發送自己的投票 (<P.zxid, P.myid>, P.myid, election, 1),
3)完成對自己的投票后,開始等待接收其它節點的投票資訊,(這里需要注意一下,收到的投票不是投給 P 的,是由其它節點廣播給所有集群內的節點自己的選擇)
4)當節點收到了對法節點狀態是 Leading 的通知或者在回圈內達成了投票共識(即決策了Leader)后,退出回圈,結束選主狀態,
決策流程
首先從當前節點的選票佇列中彈出收到的選票 n,如果當前沒有收到的投票,那么發出自己的投票資訊,等待 2 倍的 timeout 時間,
當拿到選票后,對選票處理也很簡單,根據選票中投票節點的狀態可以做出兩種行為:
1 如果選票 n 是選主狀態,即 P.state = election:
1)比較選票的投票輪次
- 如果選票中的輪次大于當前節點,代表自身輪次落后,需要更新當前節點的輪次和選票佇列
(i)更新節點自身的 round 為選票 n 的 round,同時清空選票佇列 ReceivedVotes
(ii)PK 選票v = Vote(zxid , myid),如果對方節點的選票較新,則修改自身選票為 v
(iii)向集群廣播自己新一輪選票 - 如果選票輪次與當前節點相同,表示在同一個選票輪次中,那么更新自身的 vote 為選票 n 中的 vote,然后再次進行廣播
- 如果選票輪次比當前節點小,則忽略改選票,繼續處理下一條新
2)如果投票 n 是有效的,那么就放入到佇列 ReceivedVotes 中
3)如果當前 ReceivedVotes 等于 SizeEnsemble,也就是所有節點都進行了投票,則進行開票流程
4)如果當前節點獲得的投票已經占了過半數,則等一個選舉時間(tickTime)后進行開票
2 如果選票 n 已經是 leading 或 following 狀態,那么說明某個節點已經進行開票并決策出結果,當前的節點進行更新狀態即可:
1)如果選票 n 和當前節點處于同一個投票輪次,則選票有效,放入佇列中:
-
如果 n 的狀態是 leading,表示對方節點已經是 leading 狀態,那么直接開票,不用繼續看其余選票,
-
如果 n 是 following,那么對比下選票看看是不是自己中選(超過過半節點)了,如果是則開票更新,否則看下票的 id 是不是處于 leading 狀態,是則開票
2)OutOfElection 是已經出結果的集合,因為這個選票 n 不是 following 就是 leading,所以放入 OutOfElection,然后根據 OutOfElection 進行判斷自己結果
- 當前選票 n 投票的是自己,并且自己獲取了 OutOfElection 中的過半,那么開票,變更狀態
- 如果 OutOfElection 中有過半的投票投給了 n, 并且被投票的節點處于 leading 狀態,也屬于 OutOfElection,進行開票
3 如果以上邏輯均未命中,拿出下個選票,繼續回圈,
演算法精髓
1)節點會隨著收到投票的狀態而變更自己的投票結果,即如果有人投票比自身新,那就變票然后再次發聲,
2)在裁定狀態及退出回圈的判斷中,只接收輪次不比自身小的,不僅會判斷 (vote, id, state, round) 中投票者的狀態,也會判斷這個被投票節點的狀態,另外還要滿足過半節點的策略,
3)每個節點會維持倆個狀態集合 ReceivedVotes 和 OutOfElection, ReceivedVotes存放接收到的合法選票,OutOfElection 存放節點已經是 leading 或 following 狀態的選票,這也不難理解,ReceivedVotes 是還沒開票,需要判斷,OutOfElection 則是已經大選已經接收了,明確的狀態了,
4)總有一個節點會在 election 選主狀態先拿到過半節點,判定自己就是 leading 狀態,然后廣播給其其它節點,其它節點收到廣播后進行自身狀態修改,
4 總結
其實 ZAB 的哲學和 Paxos 一致,即限制未來就是更好的選擇,
就如德州撲克一樣,隨著不斷開牌,勝算小的選手就會不斷放棄自己的 call,最終只剩一個贏家拿走所有籌碼,
🌲🌲🌲 最后,如果大家覺得對你有幫助的話還希望大家動動手指給個免費的一鍵三連~,你的支持是我前進最大的動力,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/398640.html
標籤:其他
上一篇:Kafka消費者