布隆過濾器
譚文濤 2021-12-24
假如你在程式員的面試中碰到如下問題,你該如何回答:
1、 比如中國現在接種第3針加強針新冠疫苗的人數已超過10億,怎樣快速判斷出一位持有中國身份證的居民沒有接種第3針疫苗?
2、 因為你和領導喜歡公司同一個妹子,你的領導想辭退你,但你平時的作業和考勤表現都無可挑剔,于是他給你一臺記憶體是2G的筆記本電腦和A,B兩個檔案,每個檔案各存放50億條URL,每條URL占用64位元組,讓你找出A,B檔案所有共同的URL,你咋辦?
3、 之前被你領導排擠走的程式員非常氣憤,于是寫了個程式大批量頻繁呼叫公司的http介面目的是攻擊公司的資料庫,雖然公司用了redis快取,但由于他之前在公司干過,他的介面入參全都是快取中不存在的,全都擊穿了redis去訪問資料庫,領導眼看資料庫每天都蹦,正好把鍋甩給你,讓你解決這個redis被擊穿的問題,你咋處理?
其實上面三個問題的解答辦法都是同一種,那就是“布隆過濾器”——BloomFilter
,下面我們來揭開他的神秘面紗
1、什么事布隆過濾器
布隆過濾器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的,它實際上是由一個很長的二進制向量和一系列隨機映射函陣列成,布隆過濾器可以用于檢索一個元素是否在一個集合中,它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和洗掉困難,但是沒有識別錯誤的情形(即如果某個元素確實沒有在該集合中,那么Bloom Filter 是不會報告該元素存在于集合中的,所以不會漏報),
2、布隆過濾器的基本原理
如果想判斷一個元素是不是在一個集合里,一般是將集合中所有元素保存起來,然后通過比較確定,鏈表、樹、哈希表等資料結構都是這種思路,但是隨著集合元素的增加需要的存盤空間越大,檢索速度也越慢,
應該蠻多人會說用 HashMap 吧,確實可以將值映射到 HashMap 的 Key,然后可以在 O(1) 的時間復雜度內回傳結果,效率奇高,但是 HashMap 的實作也有缺點,例如存盤容量占比高,還比如說你的資料集存盤在遠程服務器上,本地服務接受輸入,而資料集非常大不可能一次性讀進記憶體構建 HashMap 的時候,也會存在問題,
接下來讓我們看看“布隆過濾器”是怎么解決這個問題的:
布隆過濾器是一個 bit 向量或者說 bit 陣列(超長超長,記住一定要足夠長),長這樣:
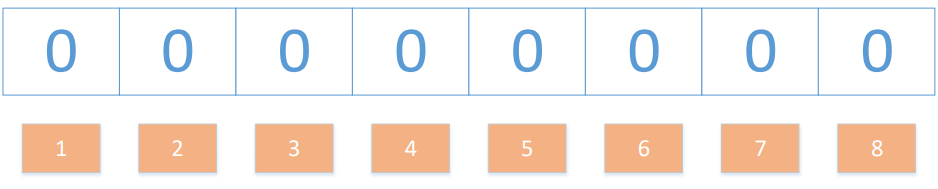
我們要映射一個值到布隆過濾器中,我們需要使用多個不同的哈希函式生成多個哈希值,并對每個生成的哈希值指向的 bit 位置 1,例如針對值 “baidu” 和三個不同的哈希函式分別生成了哈希值 1、4、7,則上圖轉變為:
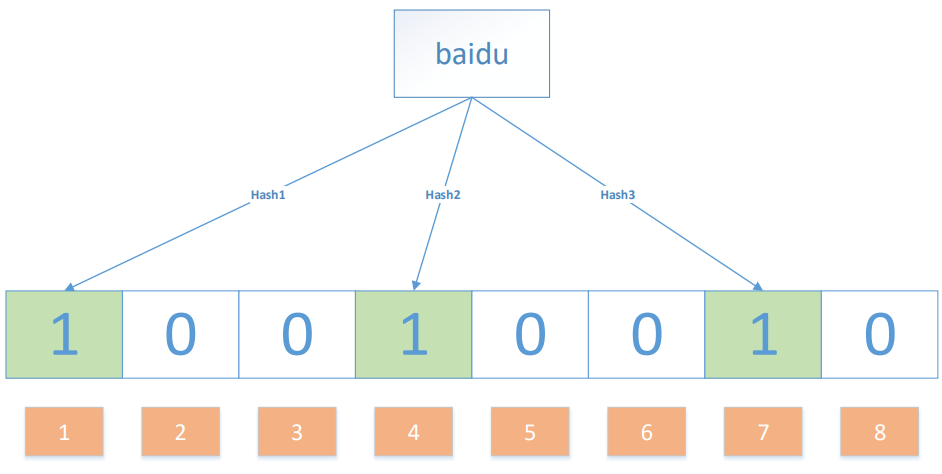
Ok,我們現在再存一個值 “tencent”,如果哈希函式回傳 3、4、8 的話,圖繼續變為:
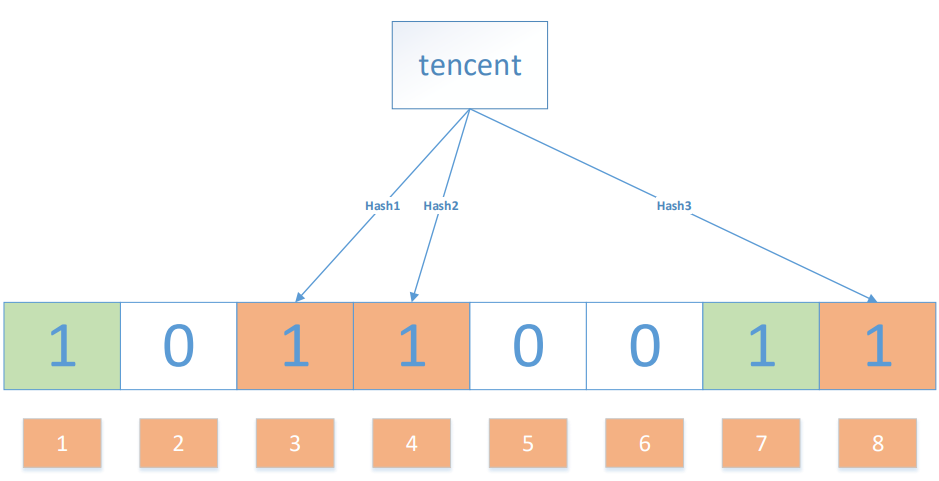
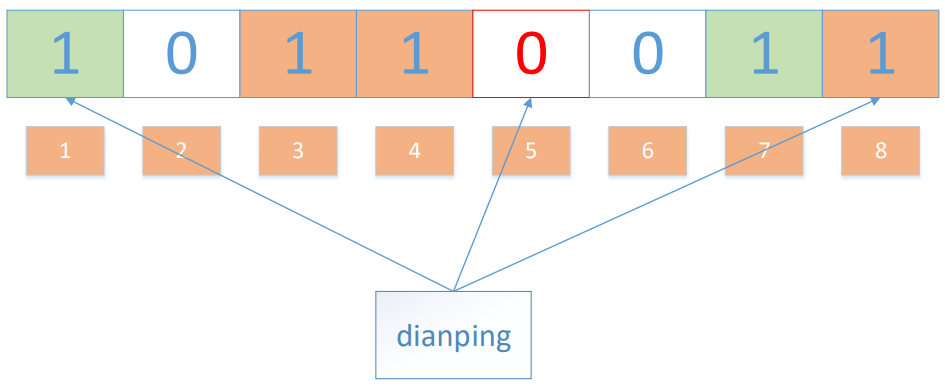
值得注意的是,4 這個 bit 位由于兩個值的哈希函式都回傳了這個 bit 位,因此它被覆寫了,現在我們如果想查詢 “dianping” 這個值是否存在,哈希函式回傳了 1、5、8三個值,結果我們發現 5 這個 bit 位上的值為 0,說明沒有任何一個值映射到這個 bit 位上,因此我們可以很確定地說 “dianping” 這個值不存在,
而當我們需要查詢 “baidu” 這個值是否存在的話,那么哈希函式必然會回傳 1、4、7,然后我們檢查發現這三個 bit 位上的值均為 1,那么我們可以說 “baidu” 存在了么?答案是不可以,只能是 “baidu” 這個值可能存在,這是為什么呢?答案跟簡單,因為隨著增加的值越來越多,被置為 1 的 bit 位也會越來越多,這樣某個值 “taobao” 即使沒有被存盤過,但是萬一哈希函式回傳的三個 bit 位都被其他值置位了 1 ,那么程式還是會判斷 “taobao” 這個值存在,
為什么我上面說布隆過濾器的bit陣列要足夠長?
很顯然,過小的布隆過濾器很快所有的 bit 位均為 1,那么查詢任何值都會回傳“可能存在”,起不到過濾的目的了,布隆過濾器的長度會直接影響誤報率,布隆過濾器越長其誤報率越小,
布隆過濾器的演算法總結:
1.初始化時,需要一個長度為n位元的陣列,每個位元位初始化為0;
2. 然后需要準備k個hash函式,每個函式可以把key散列成為1個整數;
3. 某個key加入集合時,用k個hash函式計算出k個散列值,并把bit陣列中對應的位元位置為1;
4. 判斷某個key是否在集合時,用k個hash函式計算出k個散列值,并查詢陣列中對應的位元位,如果有位元位是0,則該key一定不在集合中,
3、布隆過濾器的典型應用
布隆在海量資料查詢中以優異的空間效率和低誤判率有非常廣泛的應用,其中包括但不限于:
(1)檢查單詞拼寫正確性
(2)檢測海量名單嫌疑人
(3)垃圾郵件過濾
(4)搜索爬蟲URL去重
(5)快取穿透過濾
世界上著名各大科技公司使用布隆過濾器的實際案例:
Google 著名的分布式資料庫 Bigtable 使用了布隆過濾器來查找不存在的行或列,以減少磁盤查找的IO次數,
Squid 網頁代理快取服務器在 cache digests 中使用了也布隆過濾器,
Venti 檔案存盤系統也采用布隆過濾器來檢測先前存盤的資料,
SPIN 模型檢測器也使用布隆過濾器在大規模驗證問題時跟蹤可達狀態空間,
Google Chrome瀏覽器使用了布隆過濾器加速安全瀏覽服務,
4、結語
本質上布隆過濾器是一種資料結構,比較巧妙的概率型資料結構(probabilistic data structure),特點是高效地插入和查詢,可以用來告訴你 “某樣東西一定不存在或者可能存在”,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/399501.html
標籤:其他