盤點2021年Apache年報中出現的國產專案:ShardingSphere, IoTDB, Carbon Data, Eagle, Kylin【施工中】
- 1、引言
- 2、專案盤點
- 2.1 ShardingSphere
- 2.2 IoTDB
- 2.3 Carbon Data
- 2.4 Eagle
- 2.5 Kylin
- 2.5 APIXSIX
1、引言

2021年8 月 31 日,Apache 軟體基金會發布 2021 財年(2020 年 5 月 1 日 - 2021 年 4 月 30 日)年度報告,報告內容由 Apache 軟體基金會概覽、基金會主席報告、財務主管報告、財務報表、資金募集、法律事務、基礎設施、安全方面、資料隱私、營銷宣傳、品牌管理、會議、社區發展、多元化與包容、專案及代碼、貢獻方面、基金會成員、聯系方式等十八個部分組成,
Apache 基金會成立于 1999 年,是世界上最大的開源基金會,管理著 2.27 億行以上的代碼,并且 100% 免費向公眾提供價值約 220 億美元的軟體,這些軟體幾乎是每個用戶計算設備上不可或缺的一部分,而開放友好的 Apache License v2 是開源行業標準,幫助了總價值超過數十億美元的公司,并使全球無數用戶受益,
報告中指出,統計周期內共有來自228個國家的用戶共4095908 次訪問,其中來自于中國的用戶數量最多,國內用戶成為了Apache專案的主要使用者,
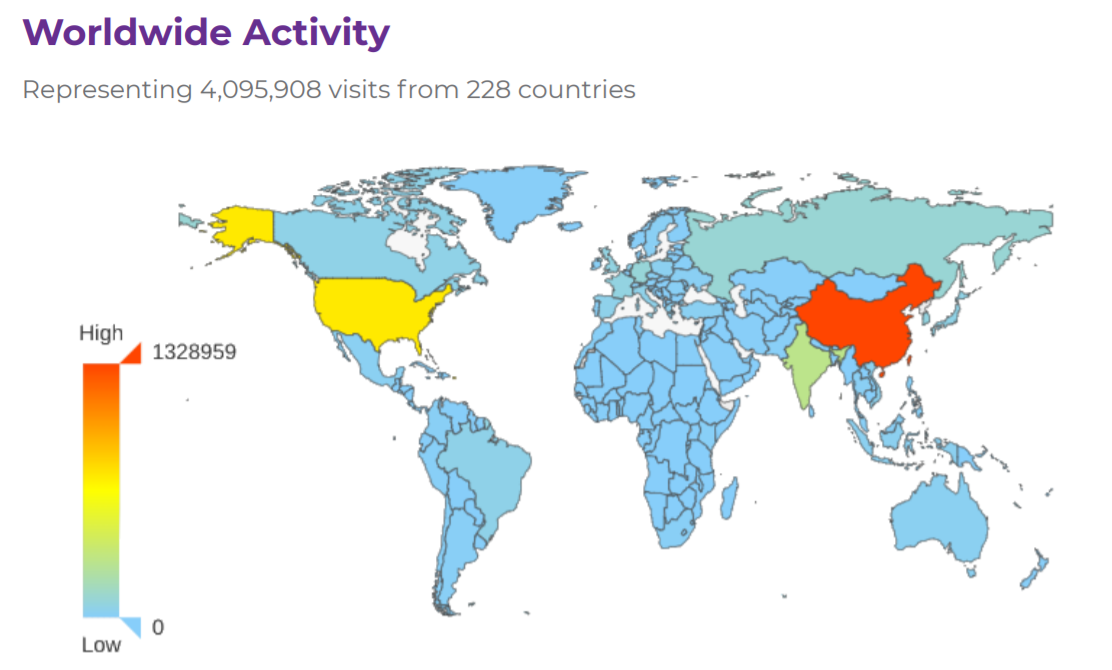
此外,在2020年7 月 15 日,由中國開源軟體推進聯盟(COPU)主辦的2020 第十五屆“開源中國開源世界”高峰論壇上,Apache 基金會副主席 Shane Curcuru表示,在過去的 20 年里,Apache 基金會已經從最初的 21 位創始人發展到了 800 多位 Apache 會員,專案提交數量穩步增長,現在已有近 8000 名提交者,這些 Apache 專案中的提交者已經發布了超過 2 億行代碼,尤其值得關注的是,來自中國的新社區和貢獻者加入 Apache 專案的速度增長驚人,Shane Curcuru 這樣說道:“令人興奮的是,中國的技術專家和公司如此迅速地采用全球開源技術,現在,不僅幫助 Apache 建立新專案,而且改善開源本身的作業方式,來自中國的整個 Apache 新專案的發展也讓人印象深刻,我們目前有 10 個源于中國的頂級專案,其中幾個專案非常有名,現在還有 9 個來自中國的 Apache 范訓器專案正在努力成為頂級專案,重要的是,這些 Apache 專案涵蓋了從大資料、流媒體到物聯網,再到所有涉及云管理的技術領域,”

參考文章:由 Apache 說開,中國開源專案已經走向世界!
今天我們來盤點一下有哪些專案在2021年的Apache年報中出現,以及這些專案目前的情況,
2、專案盤點
2.1 ShardingSphere
出現次數:1次
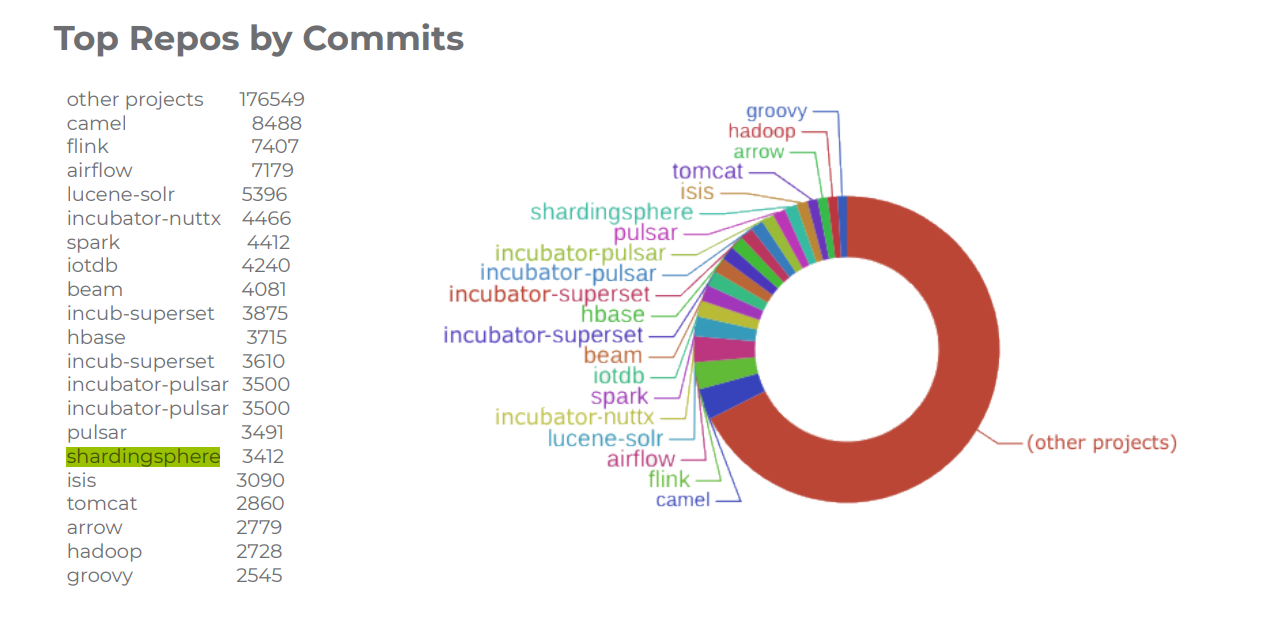
Apache ShardingSphere 是一套開源的分布式資料庫中間件解決方案組成的生態圈,它由 3 款相互獨立,卻又能夠混合部署配合使用的產品組成,它們均提供標準化的資料分片、分布式事務和資料庫治理功能,可適用于如 Java 同構、異構語言、云原生等各種多樣化的應用場景,
Apache ShardingSphere 由三個子專案組成,形成一個完整的資料庫解決方案,合稱 J.P.S. 生態系統,
- ShardingSphere-JDBC:定位為輕量級 Java 框架,在 Java 的 JDBC層提供額外服務,它使用客戶端直連資料庫,以 jar 包形式提供服務,無需額外部署和依賴,可理解為增強版的 JDBC
驅動,完全兼容JDBC 和各種 ORM 框架,- ShardingSphere-Proxy:定位為透明化的資料庫代理端,提供封裝了資料庫二進制協議的服務端版本,用于完成對異構語言的支持,目前提供MySQL/PostgreSQL
版本,它可以使用任何兼容 MySQL/PostgreSQL 協議的訪問客戶端操作資料,對 DBA 更加友好,- ShardingSphere-Sidecar(TODO):定位為 Kubernetes 的云原生資料庫代理,以 Sidecar 的形式代理所有對資料庫的訪問,通過無中心、零侵入的方案提供與資料庫互動的的嚙合層,即 Database Mesh,又可稱資料網格,
Apache ShardingSphere 的亮點主要包括:
- 完整的分布式資料庫解決方案:提供資料分片、分布式事務、資料彈性遷移、資料庫和資料治理等核心能力,
- 獨立的 SQL 決議引擎:支持多 SQL 方言的完全獨立化 SQL 決議引擎,能夠脫離ShardingSpher獨立使用,
- 可插拔微內核:所有的 SQL 方言、資料庫協議和功能都能夠通過 SPI的可插拔方式加載或卸載,微內核甚至在未來可以運行于無任何功能的空白環境中,
有關ShardingSphere的范訓程序以及更多的資訊可以訪問:GitHub 標星 10,000+,Apache 頂級專案 ShardingSphere 的開源之路
2.2 IoTDB
出現次數:2次
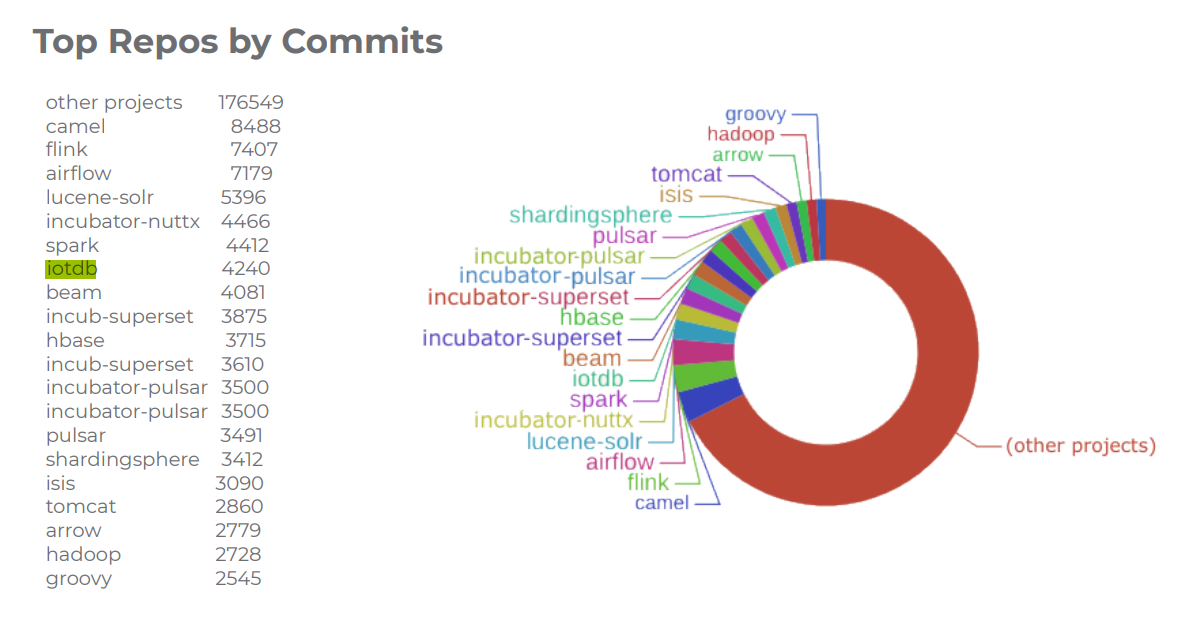

IoTDB 是一款聚焦工業物聯網、高性能輕量級的時序資料管理系統,具備低存盤成本、高速資料寫入(百萬資料點秒級寫入)、快速查詢(TB級資料毫秒級查詢)、功能完備(資料的增刪改查、豐富的聚合函式、相似性匹配)、查詢分析一體化(一份資料,滿足實時查詢與分析挖掘)、簡單易用(采用標準的 JDBC 介面、類 SQL 查詢語言)等特點,
基準測驗表明IoTDB讀寫性能均優于現有的時序資料庫InfluxDB、OpenTSDB、Cassandra以及GE的工業大資料平臺Predix,根據中國軟體評測中心和中國人民大學的性能對標測驗,IoTDB的各項性能指標均明顯優于當今國際最優的時序資料庫系統,
IoTDB 已通過 Apache 基金會范訓器的討論并獲得10票贊成,Apache 范訓器主席Justin Mclean、國際著名大資料公司 HortonWorks 副總裁 Joe Witt、Apache PLC4X 專案負責人 Christofer Dutz、華為開源中心負責人姜寧成為本專案的指導者,2018年11月18日,IoTDB專案正式成為 Apache范訓器專案,這是我國高校目前唯一一個進入Apache范訓器的專案*,
【*目前Apache IoTDB已從Apache基金會畢業,成為Apache頂級專案,見Apache Blog】
以上內容摘自:歡迎加入 Apache IoTDB!
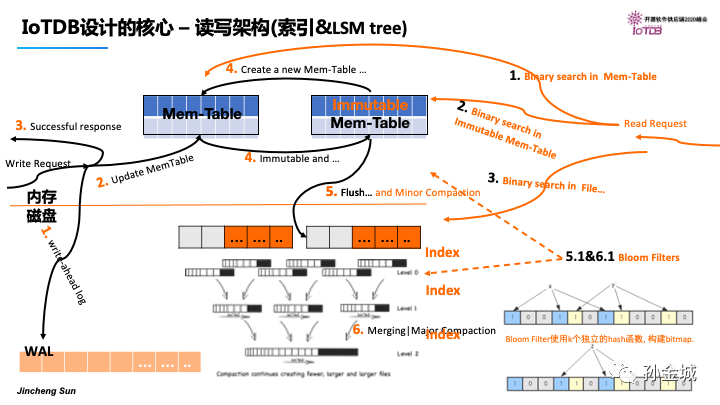
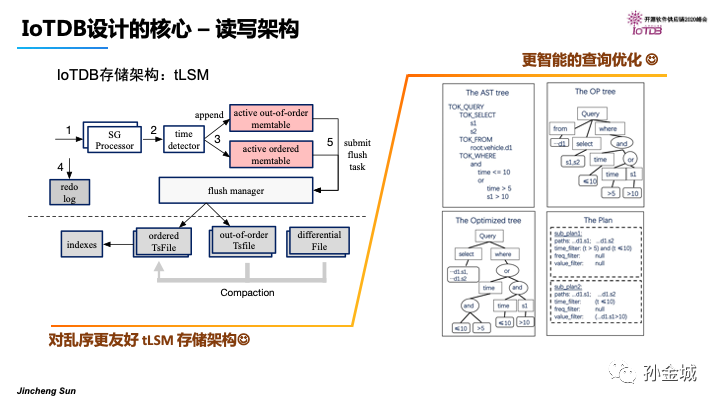
Apache IoTDB的核心技術:【from Apache IoTDB 隨筆 - IoTDB核心技術剖析】
2.3 Carbon Data
出現次數:1次
 Apache CarbonData是一種新的大資料檔案格式,使用先進的柱狀存盤、索引、壓縮和編碼技術來提高計算效率,這有助于在pb級的資料上以數量級的速度加快查詢速度,
Apache CarbonData是一種新的大資料檔案格式,使用先進的柱狀存盤、索引、壓縮和編碼技術來提高計算效率,這有助于在pb級的資料上以數量級的速度加快查詢速度,
CarbonData特別設計了多種優化策略,如多級索引、壓縮和編碼技術,旨在提高包含filter、aggregation和counst distinct等分析查詢的性能,用戶期望在擁有較少節點的商用集群上獲得對TB級別資料的亞秒級回應,
CarbonData具有以下優點:
-
獨特的資料組織形式:以獲得更快的查詢性能及更少的資料檢索成本
-
進一步的下推優化策略:與Spark進行深度集成,以改進Spark DataSource
API和其他實驗特性,從而確保計算在接近資料的地方執行,從而最大限度地減少資料的讀、處理、轉換和傳輸(shuffle) -
多級索引:有效地修剪要掃描的檔案和資料,從而減少I/O掃描和CPU處理
-
CarbonData檔案格式如圖所示,
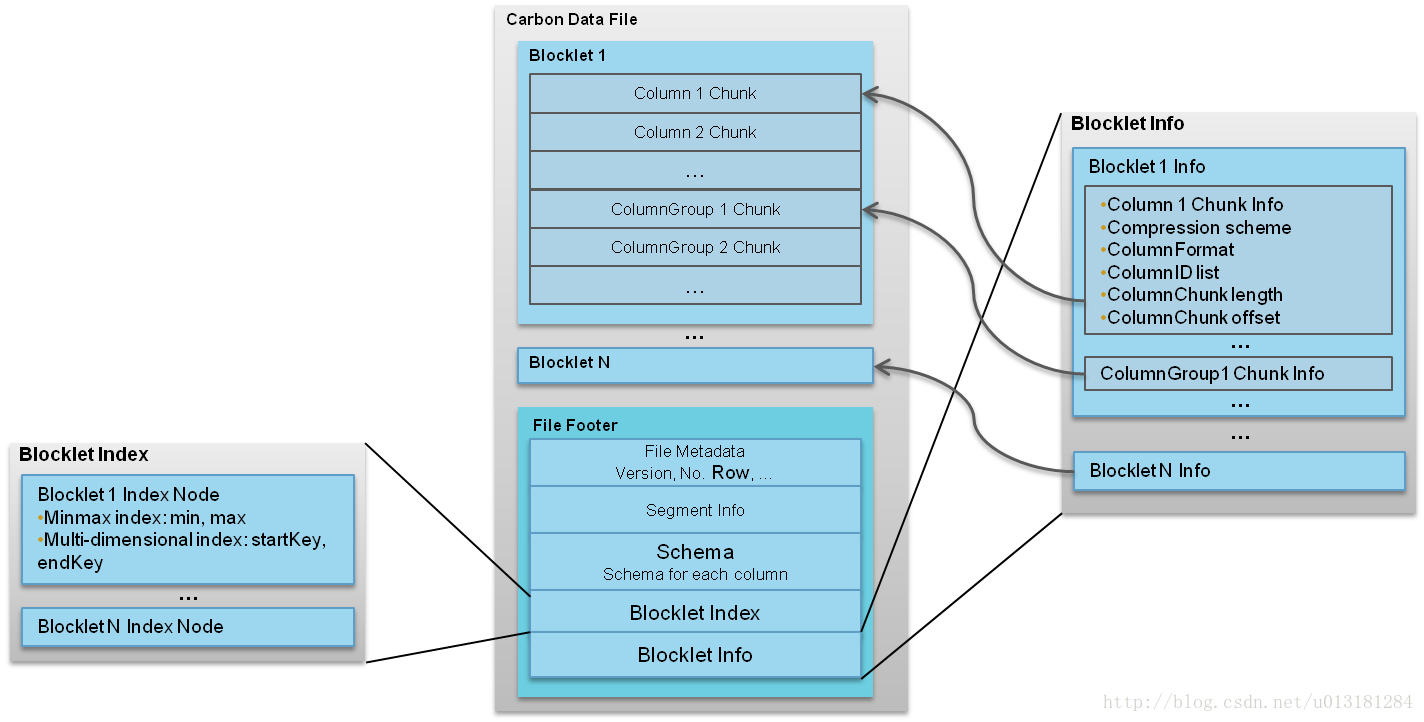
以上內容參考自carbondata 介紹
2.4 Eagle
出現次數:1次
Apache Eagle 是由 eBay 公司開源的一個識別大資料平臺上的安全和性能問題的開源解決方案,該專案于2017年1月10日正式成為 Apache 頂級專案, Apache Eagle 提供一套高效分布式的流式策略引擎,具有高實時、可伸縮、易擴展、互動友好等特點,同時集成機器學習對用戶行為建立Profile以實作實時智能實時地保護 Hadoop 生態系統中大資料的安全,
Apache Eagle 主要包括三大層:
- 資料收集及存盤層(Data Collection and Storage)
- 資料處理層(Data Processing)
- 可視化層(Visualize)
整個組成如下:
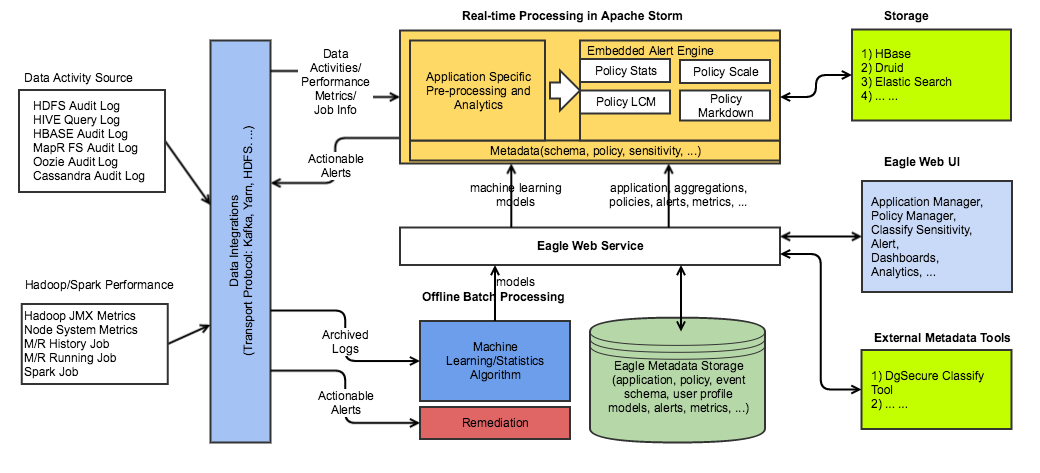
Apache Eagle 依賴于 Apache Storm 來進行資料活動和操作日志的流處理,并且可以執行基于策略的檢測和報警,它提供多個API:作為基于Storm API上的一層抽象的流式處理API和 policy engine provider API的抽象,它將WSO2的開源Siddhi CEP engine作為第一類物件,Siddhi CEP engine支持報警規則的熱部署,并且警報可以使用屬性過濾和基于視窗的規則(例如,在10分鐘內三次以上的訪問)來定義,
Eagle 支持根據用戶在Hadoop平臺上歷史使用行為習慣來定義行為模式或用戶Profile的能力,擁有了這個功能,不需要在系統中預先設定固定臨界值的情況下,也可以實作智能地檢測出例外的行為,Eagle中用戶Profile是通過機器學習演算法生成,用于在用戶當前實時行為模式與其對應的歷史模型模式存在一定程度的差異時識別用戶行為是否為例外,目前,Eagle 內置提供以下兩種演算法來檢測例外,分別為特征值分解(Eigen-Value Decomposition)和 密度估計(Density Estimation),這些演算法從HDFS 審計日志中讀取資料,對資料進行分割、審查、交叉分析,周期性地為每個用戶依次創建Profile 行為模型,一旦模型生成,Eagle的實時流策略引擎能夠近乎實時地識別出例外,分辨當前用戶的行為可疑的或者與他們的歷史行為模型不相符,
以上內容來源:Apache Eagle:分布式實時Hadoop資料安全方案
2.5 Kylin
出現次數:1次

Apache Kylin是一個開源的分布式分析引擎,提供Hadoop之上的SQL查詢介面及多維分析(OLAP)能力以支持超大規模資料,最初由eBay Inc. 開發并貢獻至開源社區,它能在亞秒內查詢巨大的Hive表,
KylinJ架構圖為
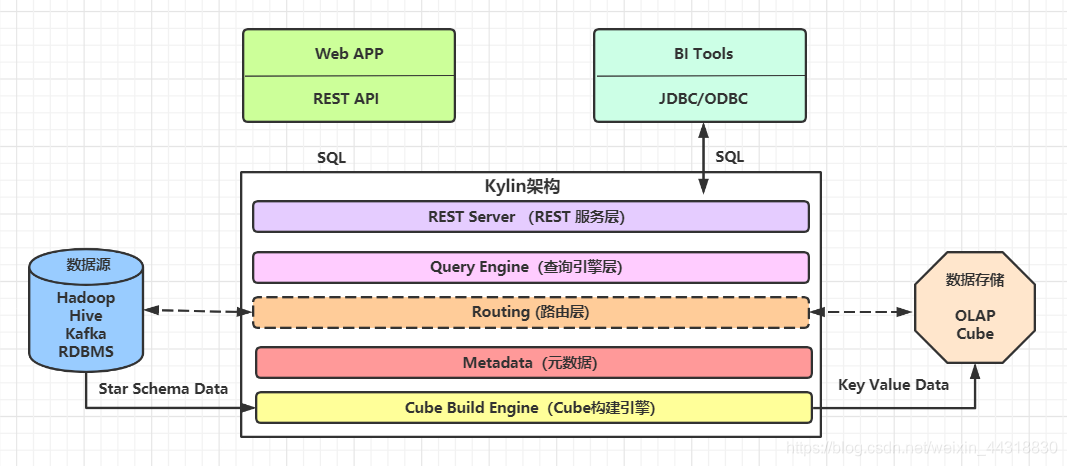
Apache Kylin核心概念
- 表(table):This is definition of hive tables as source of cubes,在build cube 之前,必須同步在 kylin中,
- 模型(model):模型描述了一個星型模式的資料結構,它定義了一個事實表(Fact Table)和多個查找表(Lookup Table)的連接和過濾關系,
- Cube 描述:描述一個Cube實體的定義和配置選項,包括使用了哪個資料模型、包含哪些維度和度量、如何將資料進行磁區、如何處理自動合并等等,
- Cube實體:通過Cube描述Build得到,包含一個或者多個Cube Segment,
- 磁區(Partition):用戶可以在Cube描述中使用一個DATA/STRING的列作為磁區的列,從而將一個Cube按照日期分割成多個segment,
- 立方體段(cube segment):它是立方體構建(build)后的資料載體,一個 segment 映射hbase中的一張表,立方體實體構建(build)后,會產生一個新的segment,一旦某個已經構建的立方體的原始資料發生變化,只需重繪(fresh)變化的時間段所關聯的segment即可,
- 聚合組:每一個聚合組是一個維度的子集,在內部通過組合構建cuboid,
- 作業(job):對立方體實體發出構建(build)請求后,會產生一個作業,該作業記錄了立方體實體build時的每一步任務資訊,作業的狀態資訊反映構建立方體實體的結果資訊,如作業執行的狀態資訊為RUNNING時,表明立方體實體正在被構建;若作業狀態資訊為FINISHED ,表明立方體實體構建成功;若作業狀態資訊為ERROR,表明立方體實體構建失敗!
2.5 APIXSIX
出現次數:1次

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/399649.html
標籤:其他