
論文:TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation
代碼:https://github.com/automl/trivialaugment
文章目錄
- Introduction
- 解決的問題
- 使用方法
- 演算法描述
Introduction
本文主要研究資料增強在影像分類場景的應用,影像分類中的資料增強是基于原始影像生成新的影像,增強完以后仍然屬于相同的分類,相當于資料的擴充,早期的資料增強策略是純人工設計的,直至AA等自動搜索出的資料增強策略的提出,才降低了資料增強的設計難度,
自動搜索的資料增強策略在使用時雖然是幾乎for free的,但是搜索確實是一個耗時耗卡的大工程,Trivial Augment的提出,不需要特定的任務選擇的資料增強策略,也不用將多種資料增強策略組合在一起,是一種簡單有效的策略,
解決的問題
使用NAS方法自動搜索的資料增強的方法雖然是有效的,但局限在于需要權衡搜索效率和資料增強的性能,為了解決這個問題,論文提出了Trivial Augment資料增強策略(后文簡稱TA),相比于之前的資料增強策略,TA是無引數的,每張圖片只使用一次資料增強方式,因此相比于AA、PBA乃至RA,它的搜索成本幾乎是free的,而且取得了SOTA的效果,
使用方法
作者開源了代碼,使用方法很簡單,通過以下幾行代碼的呼叫就能搞定:
augment = aug_lib.TrivialAugment()
trans = transforms.Compose(
[
transforms.RandomResizedCrop(train_crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(),
augment,
transforms.ToTensor(),
normalize,
]
)
演算法描述
TA采用了和RandomAugment相同的資料增強風格,具體來說,資料增強被定義為由一個資料增強函式a和對應的強度值m(部分資料增強函式不使用強度值)組成,
作業原理

如上圖所示,我們首先輸入影像x和資料增強函式的集合A作為輸入,我們簡單地從A中隨機采樣一個資料增強函式,然后從{0,1,2….30}中均勻采樣一個值作為強度m,然后對輸入影像進行資料增強,并回傳增強后的影像,
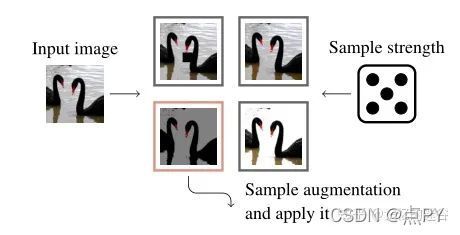
上面一張圖是TA的程序可視化,對于每個影像,TA均勻采樣一個資料增強函式和一個強度值,然后回傳增強后的圖片,此外,之前的方法往往疊加多個資料增強方式,而TA只對每個圖使用單一的資料增強方式,使用這樣的方式,可以將TA增強后的資料集看做是:將一張圖片使用所有的資料增強方式分別增強,然后從中均勻采樣,
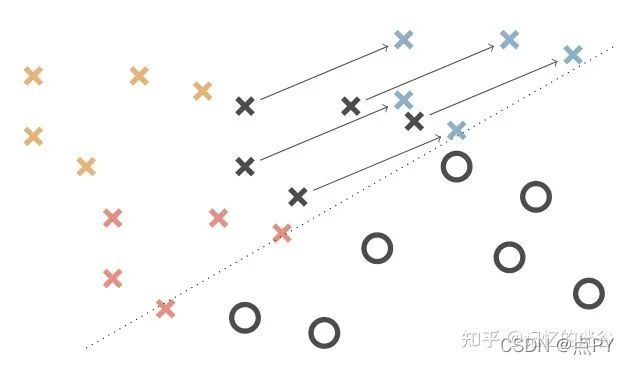
具體來說,如上圖所示,X和O代表兩個類別,中間用虛線作為分界線,其中黑色的代表原始類別,彩色的代表擴充后的類別,可以看到,TA相當于把原始圖片按照不同的資料增強方式分別做了增強,然后我們再從中隨機抽樣獲得增強后的資料,
資料增強的可選空間
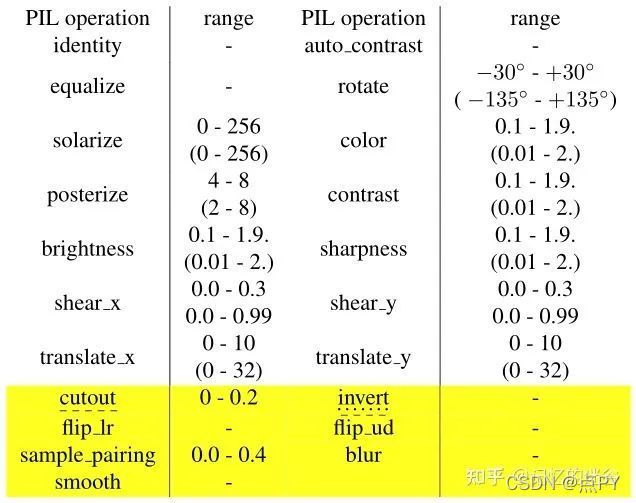
上述就是TA的搜索空間,由不同的PIL庫函式以及其對應的資料增強的強度(部分操作沒有強度項)組成,總的來說,TA的資料增強空間建立在RA搜索空間的基礎上,添加了UA、 OHL的資料增強空間,
實際效果
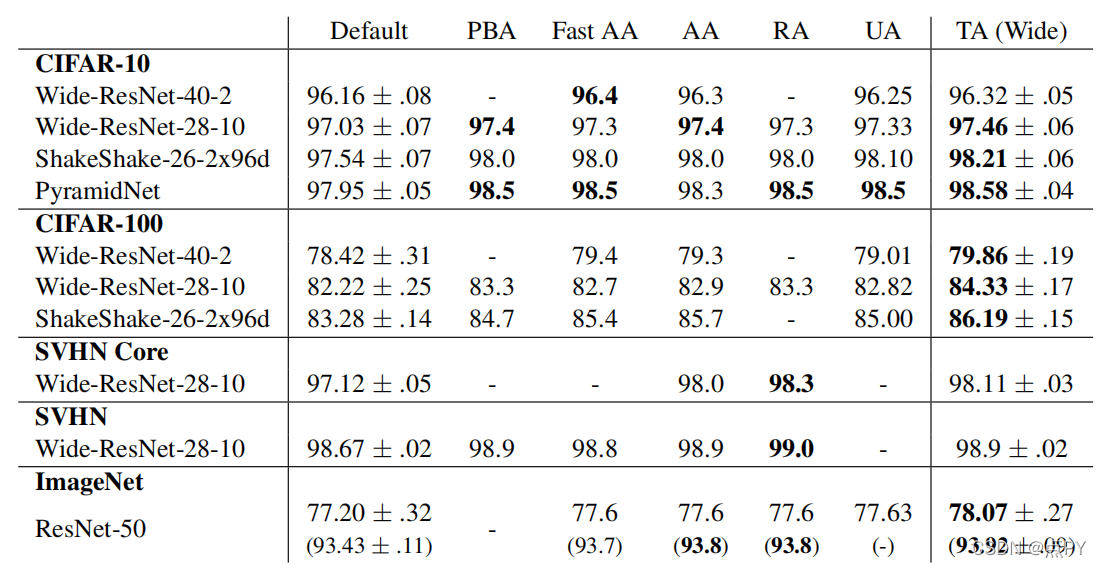
論文將TA和PBA、Fast AA等資料增強策略對比,發現其在針對不同的資料集,使用不同的網路進行對比(訓練5~10次取平均值),在大部分資料集和模型上訓練都取得了SOTA的結果,這也表明了TA策略針對多種資料集和模型均有效果且魯棒性較強,
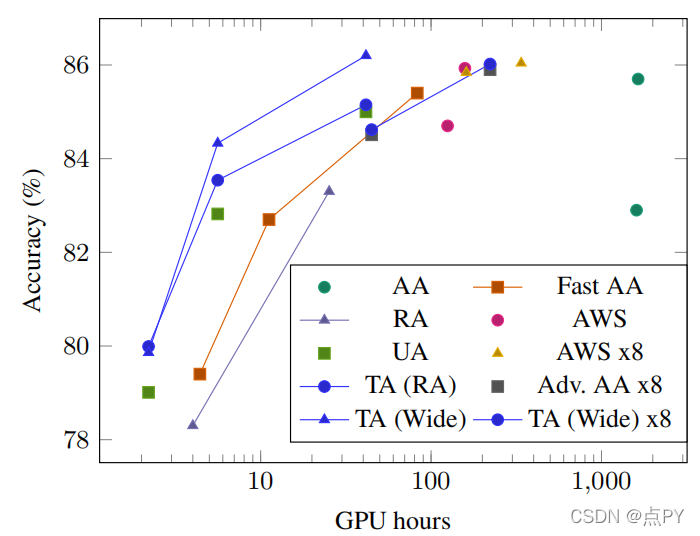
論文對比了不同的資料增強策略的效率,它們都使用Wide-ResNet模型訓練,對比達到指定的精度所耗費的GPU卡時,從平行于x軸的方向來看,達到同樣的精度TA耗時最少,從平行于y軸的方向來看,使用相同的訓練時長,TA的精度最高,總的來講,在精度、計算資源兩個維度下,TA的是最高效的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/399976.html
標籤:其他
上一篇:無法填充物件陣列