目標檢測之YOLOv4
- 框架
- 技巧Trick/優化
- 1.BoF
- 2.BoS
- YOLO V4
論文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
源代碼:https://github.com/AlexeyAB/darknet,原作者YOLO V4的代碼是基于C++的
pytorch實作:
https://github.com/GZQ0723/YoloV4
https://github.com/Tianxiaomo/pytorch-YOLOv4
禁止任何形式的轉載!!!
YOLOV4兼顧了速度和精度(文中也說了設計的初心還是保證大家用單張顯卡就能完成實驗),所以這里先對YOLO V4簡單總結一下,后續有時間會把一些內容展開(可以點進藍色字體的鏈接get相應的知識),
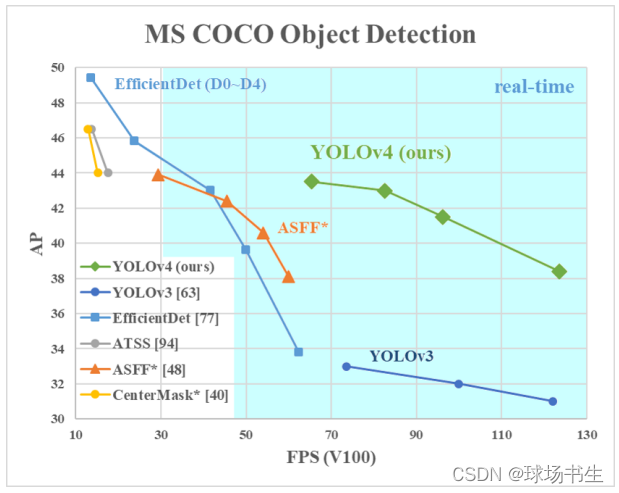
框架
文中將檢測的框架進行了劃分:
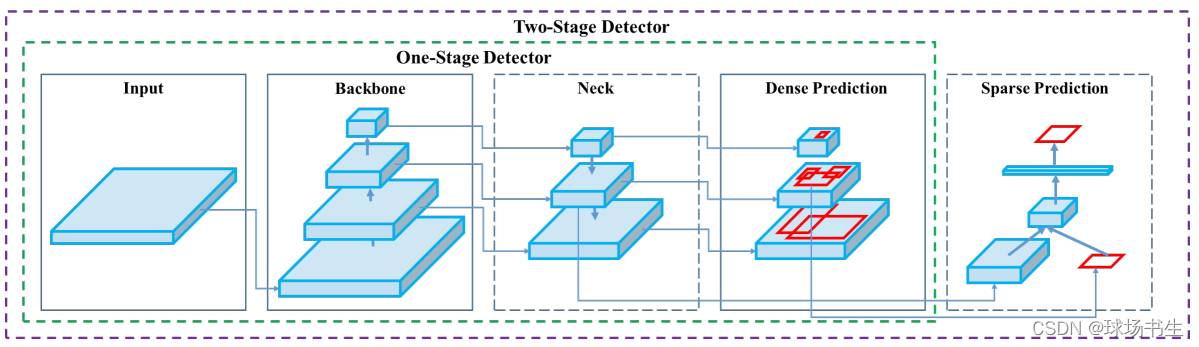
先不講YOLO V4的具體結構,先把這個框架講完,YOLO V4無非就是從這個框架里選取出來的,
? Input:Image, Patches, Image Pyramid
? Backbones(提取特征):VGG, ResNet, DenseNet,ResNeXt,CSPResNeXt50,CSPDarknet53(手工設計的適合在GPU上用);SqueezeNet,MobileNet,ShuffleNet,GhostNet,MixNet(輕量級網路,CPU上比較友好);此外還有通過自動搜索得到的網路結構SpineNet, EfficientNet-B0/B7 , EfficientNet V2
? Neck(收集提取到的特征):
- Additional blocks:通常為注意力模塊(SE,SAM );多尺度模塊(SPP, ASPP,DCN,RFB)
- Path-aggregation blocks:聚合不同的特征FPN, PAN,NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
? Heads(輸出檢測結果):單階段是在整個特征圖上進行預測,最侄訓輸出很多檢測結果,所以是Dense Prediction;兩階段是在候選框的基礎上再預測,結果就相對較少,Sparse Prediction,
- Dense Prediction (one-stage):
? RPN, SSD, YOLO, RetinaNet(anchor based)
? CornerNet, CenterNet, MatrixNet, FCOS(anchor free) - Sparse Prediction (two-stage):
? Faster R-CNN, R-FCN, Mask RCNN(anchor based)
? RepPoints(anchor free)
技巧Trick/優化
BoF與BoS可以理解為一些漲點的Trick,BoF不影響測驗的時間,會影響訓練的時間;BoS會犧牲一部分的測驗時間,
1.BoF
一般來說都是在輸入,輸出和訓練方式做文章,而不是對網路做更改,只有這樣才不會影響推理時間,
資料增強:
基本的一些請看【資料增強綜述】(這個人講得超棒);沒有涉及到的這里單列一下
Random erasing,隨機擦除隨機選擇影像中的一個矩形區域,并用隨機值擦除其像素,
Cutout,原論文有兩種方法,簡單方式選擇一個固定大小的正方形區域,然后將該區域填充為0即可;有針對性的方法,專門從影像的輸入中洗掉影像的重要特征,具體是:在訓練的epoch程序中,保存每張圖片輸出的最大特征激活點,在下一回合,對最大激活圖上采樣到和原圖一樣大,使用閾值劃分為二值圖,蓋在原圖上再輸入cnn中訓練,
hide-and-seek ,不再通過隨機位置確定patch的位置,而是將原圖劃分為若干份,然后對劃分的每一份依概率進行隱藏,如果簡單的將像素值替換為0,暴力填黑,會造成訓練和測驗資料分布不一致問題,因此,作者采用整個資料集的均值來處理【不是單張影像的均值】
GridMask:

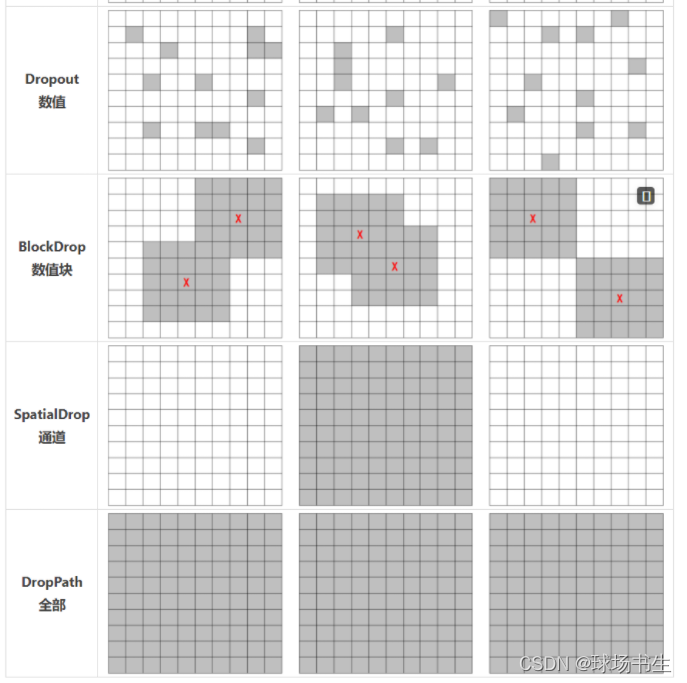
正則化:Dropout、Dropconnect、Dropblock,對于全連接,DropOut是將神經元激活輸出隨機置0,而DropConnect是作用于輸入神經元的權重,以一定概率將與其相連的輸入權重清0,對于卷積,卷積層的特征是空間強相關的,即使有DropOut,資訊仍能傳送到下一層,DropBlock的本質其實就是將Cutout方法應用于CNN的每一個特征圖,
Spatial Dropout常用于NLP中,是對特征層的整個通道drop,
DropPath是將深度學習模型中的多分支結構隨機失活的一種正則化策略,
語意分布偏差(如:資料樣本類別不平衡;類別間有關聯):
-
資料樣本類別不平衡:難例挖掘hard negative example mining(通常用于兩階段方法,因為RPN之后的有些負樣本很容易被分對);OHEM(正負樣本都挖掘,根據損失排序選出難樣本,并作為ROI網路的輸入);Focal Loss(單階段網路不像雙階段,雙階段會先選取候選框,把正負樣本控制在一定比例);GHM梯度均衡機制(梯度越大,越不好分);IoU bbalance loss(針對正樣本的,強化分類和回歸的關系,高IoU低socre,低IoU高socre)
-
類別間有關聯:Label Smoothing;基于知識蒸餾的soft label
邊框回歸:IoU GIoU DIoU CIoU Loss
2.BoS
-
往網路里加入一些漲點的模塊
增強感受野的多尺度模塊:SPP, ASPP,DCN,RFB
注意力機制:SE,SAM
特征聚合:skip connection,hyper-column,FPN, PAN,NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
激活函式:

-
后處理方法
NMS:是直接刪去周圍非最大分數的框,將IoU大于閾值的視窗的得分全部置為0,
Soft NMS:核心是降低置信度,而非直接洗掉,這樣可以保留下一些靠得比較密集的目標,只抑制同一物體上重復的框,不過這是理想狀況,實際還需要調參,
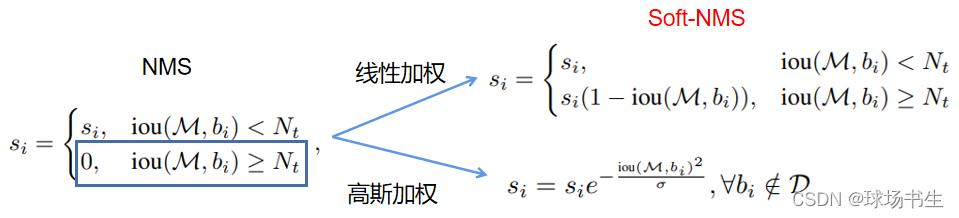
上面這個線性加權公式是不連續的,導致box集合中的score出現斷層,因此就有了下面這個式子(大部分實驗中采用的式子),高斯函式是連續的,而且離得越近函式越高聳,衰減越大,滿足在沒有重疊時應該沒有懲罰,在高重疊時應該有很高的懲罰,
DIoU NMS: DIoU替代IoU 作為NMS的評判準則
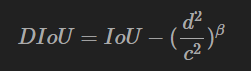
引數β用于控制中心距離所代表的重要性

為什么不用CIOU_nms?因為CIOU,是在DIOU基礎上添加形狀,包含groundtruth標注框的資訊,在訓練時用于回歸,但在測驗程序中,并沒有groundtruth的形狀資訊,除非我們之前事先知道待檢測的目標的長寬形狀比例,這個時候我們可以事先規定后計算CIOU,
YOLO V4
上面提到那么多的方法,我再來看看究竟如何在“選單”里面點菜,
先是來一份"硬菜"——主干網路:對分類最優的參考模型并不總是對檢測器最優的,與分類器相比,檢測器需要滿足以下要求:
①更大的網路輸入解析度——用于檢測小目標
②更深的網路層——能夠覆寫更大面積的感受野
③更多的引數——更好的檢測同一影像內不同size的目標
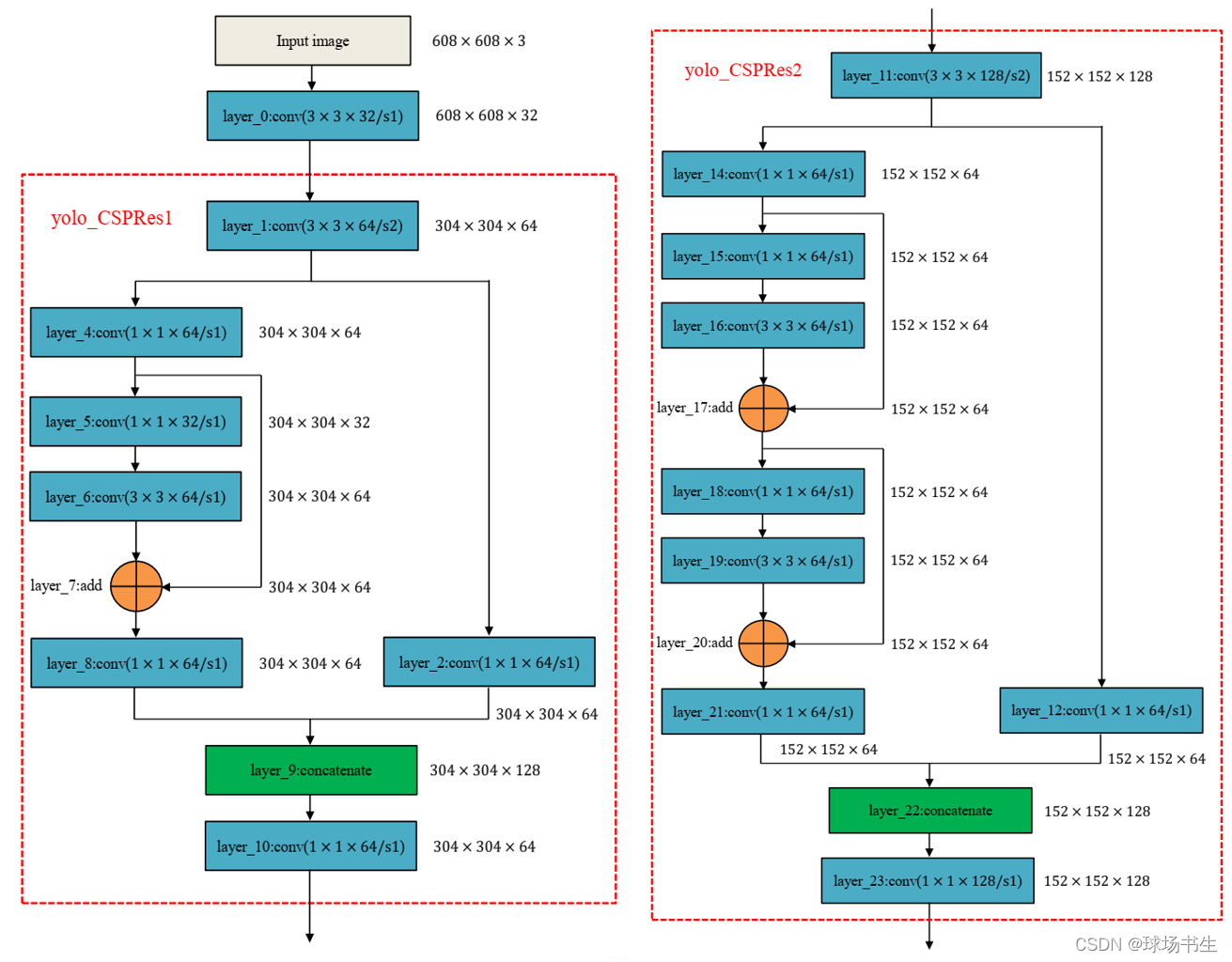
這里選擇了CSPDarknet53
再來一些陪襯的"小菜"——一些漲點的模塊:SAM、SPP additional module、PANet path-aggregation neck、YOLOv3 head
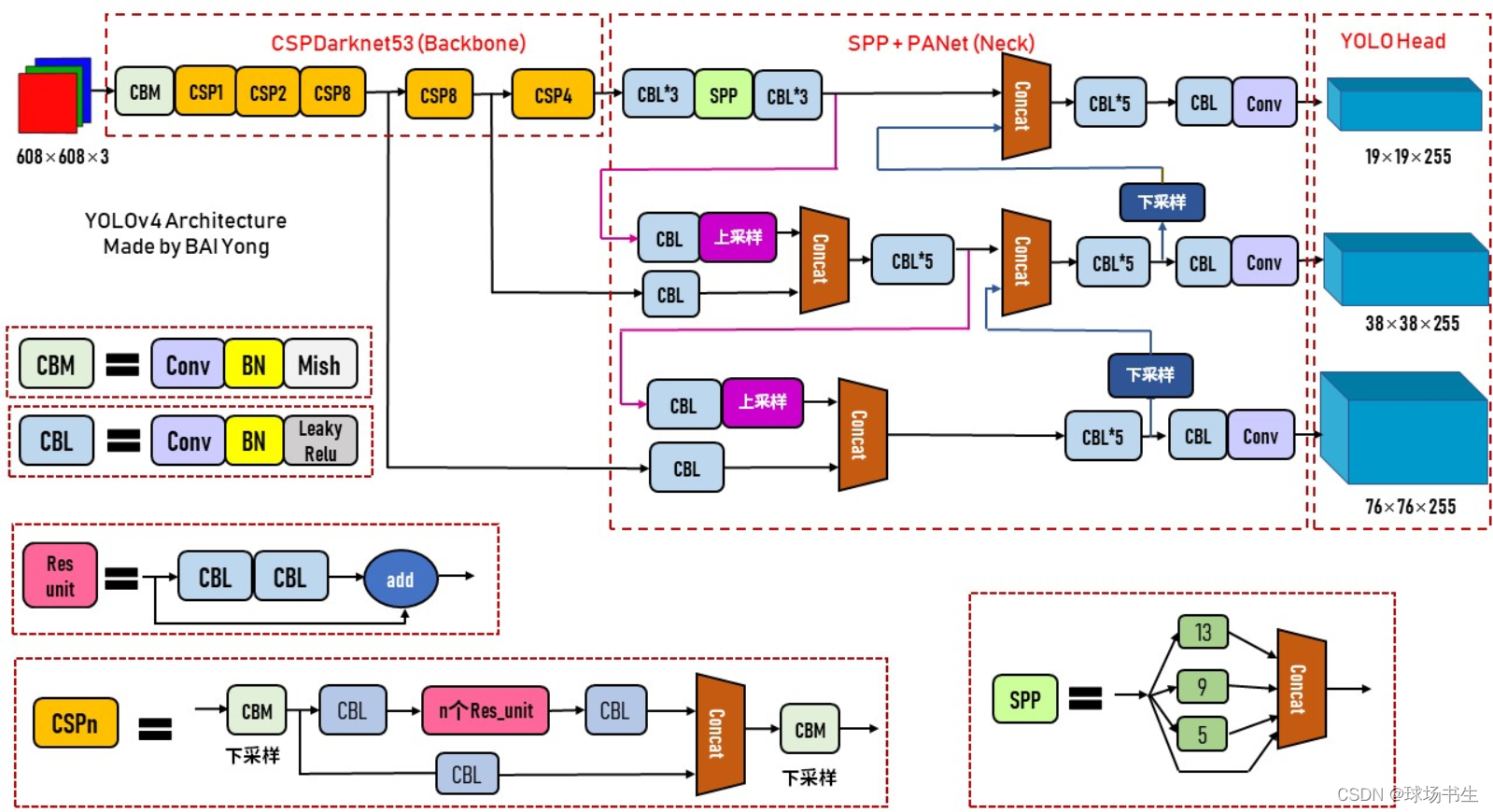
網路結構解讀
CSP:Cross Stage Partial,可以增強CNN的學習能力,能夠在輕量化的同時保持準確性、降低計算瓶頸、降低記憶體成本,顧名思義就是將特征分成兩部分,一部分的特征直接送到下一階段,另一部分的特征經過多層Conv,
PAN:Neck部分主要用來融合不同尺寸特征圖的特征資訊,
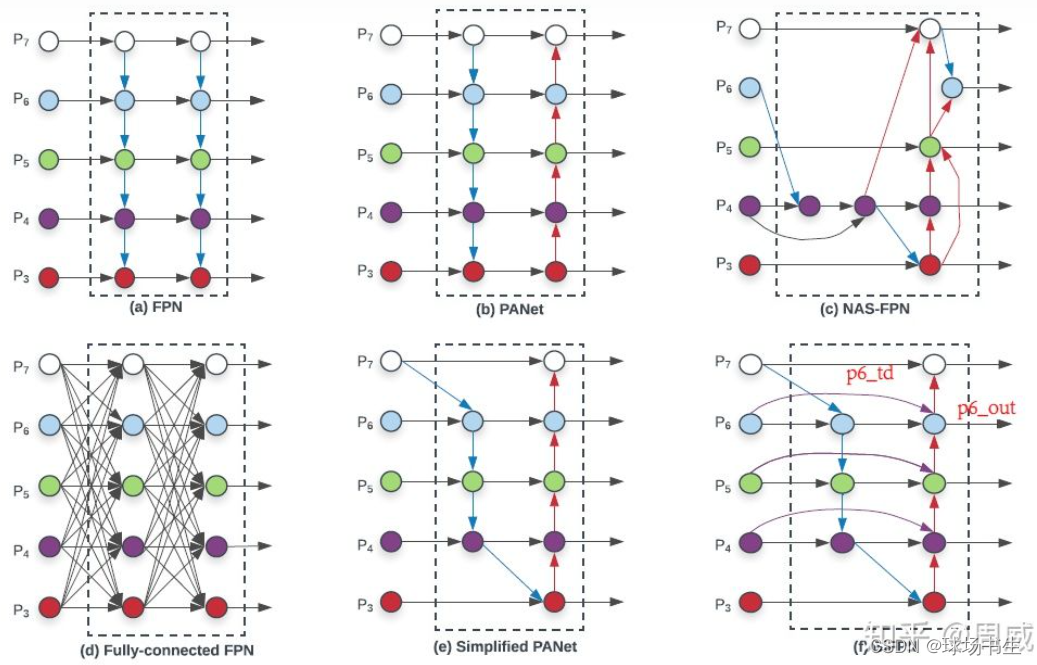
這YOLOv4里進行過改動:相加改為拼接
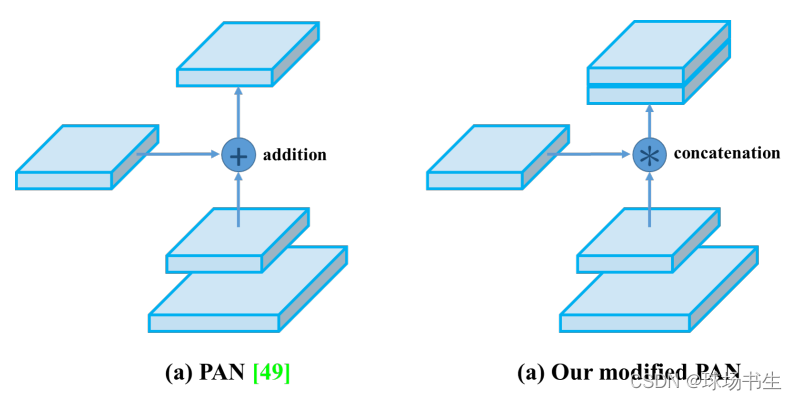
SAM改進:將SAM從空間上的attention修改為點上的attention
激活函式: 由于PRELU和SELU的訓練難度較大,而ReLU6是專門的量化網路的設計,最后主干網路選擇了Mish,在后面輸出的部分是用的leaky-ReLU,
結構完成之后,無非就是一些提升性能的方法了:
邊界框回歸損失: CIoU Loss
類別損失:Class label smoothing
資料增強:CutOut, CutMix
正化方法:DropBlock
后處理:DIoU-NMS
訓練策略:余弦退火學習率(Cosine Annealing LR),遺傳演算法選擇超引數,隨機多尺寸訓練,
自我對抗訓練(SAT):在第一階段,神經網路會更改原始影像,而不是網路權重,這樣,神經網路通過改變原始影像,從而創造了一種影像上沒有想要目標的假象,對其自身執行了對抗攻擊,在第二階段,訓練神經網路以正常方式檢測此修改影像上的目標,
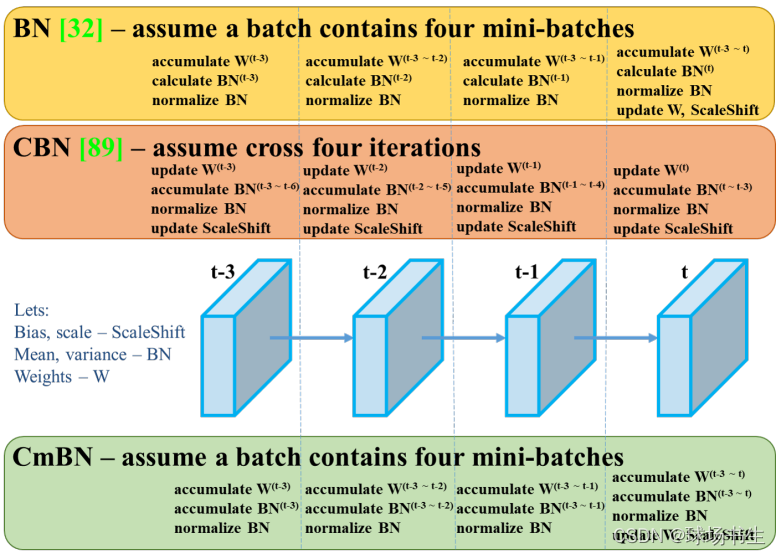
CmBN:CBN解決BN批次太小的問題,batch不想調大,但是有希望能達到batch很大的效果,就采用統計前幾個迭代的均值和方差,CBN屬于利用不同的iter資料來變相擴大batchsize從而改進模型的效果,而CmBN做的改動是僅收集單個batch中的mini-batches之間的統計資訊,具體可以看這里,講得比較清晰,CmBN是CBN的簡化版本,其唯一差別就是在計算第t時刻的BN統計量時候,CBN會考慮前一個mini batch內部的統計量,而CmBN版本,所有計算都是在mini batch內部,
Multiple anchors for a single ground truth:如果IoU(ground truth, anchor) > 閾值,為一個ground truth使用多個anchor,(需要考證)
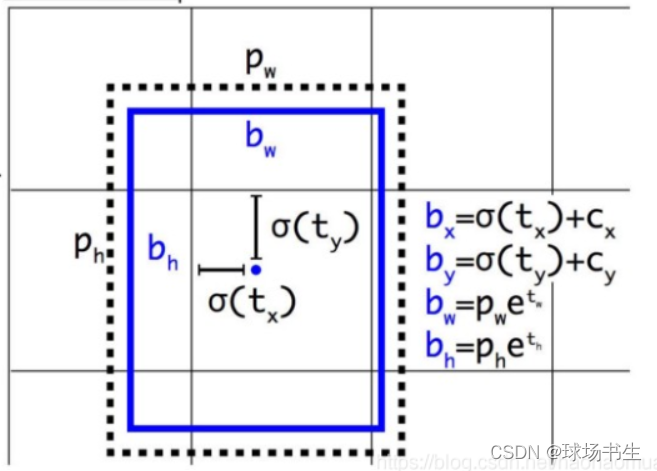
消除網路敏感性:之前使用sigmoid來偏移,需要tx為極端的值才能使得sigmoid(tx)為0或者1,所以在前面乘一個大于1的數,讓他不需要輸出極端大或者小的值就能達到網格端點,
MS COCO目標檢測實驗中,默認的超引數為:
- 訓練步驟為500500;
- 采用初始學習速率0.01的步長衰減學習速率策略,在400000步和450000步分別乘以因子0.1;
- momentum衰減為0.9,weight衰減為0.0005,
- 所有的架構都使用一個GPU來執行批處理大小為64的多尺度訓練,而小批處理大小為8或4取決于架構和GPU記憶體限制,
除了使用遺傳演算法進行超引數搜索實驗外,其他實驗均使用默認設定,
遺傳演算法利用YOLOv3-SPP進行帶GIoU損失的訓練,搜索300個epoch的min-val5k集,
- 遺傳演算法實驗采用搜索學習率0.00261、momentum0.949、IoU閾值分配ground truth
0.213、損失歸一化器0.07,
遺傳演算法這里講得很簡單易懂:
- 就是很多組引數分別進行訓練;
- 淘汰里面評價指標很差的引陣列合,留下表現最好的部分超引陣列合;
- 將保留下來的引陣列合,選擇出的兩個超引陣列合進行交叉形成新的超引陣列合進入下一個環節(類比于優良基因的交配),父母”超引陣列合并不是使用均勻的隨機采樣,而是基于輪盤賭的演算法(按評價指標來進行采樣,評價指標越好被采樣的概率越大);
- 交叉得到的新的“孩子”超引陣列合也需要發生變異,交叉生成新的超引陣列合之后,需要在新超引陣列合上隨機選擇若干個超引數,隨機修改超引數的值,這樣能突破了當前搜索的限制,更有利于演算法尋找到更優的解;
- 最后不斷的迭代,優勝劣汰,交配繁衍,變異進化,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400400.html
標籤:其他
上一篇:OpenCV-Python教程:霍夫變換~圓形(HoughCircles)
下一篇:cyw前端相關作品