1、主成分分析(PCA)簡介
PCA(principal components analysis)即主成分分析技術,又稱主分量分析,主成分分析也稱主分量分析,旨在利用降維的思想,把多指標轉化為少數幾個綜合指標,其計算流程如下:

(來源于課程展示,直接截PPT了)
一個簡單計算實體如下:

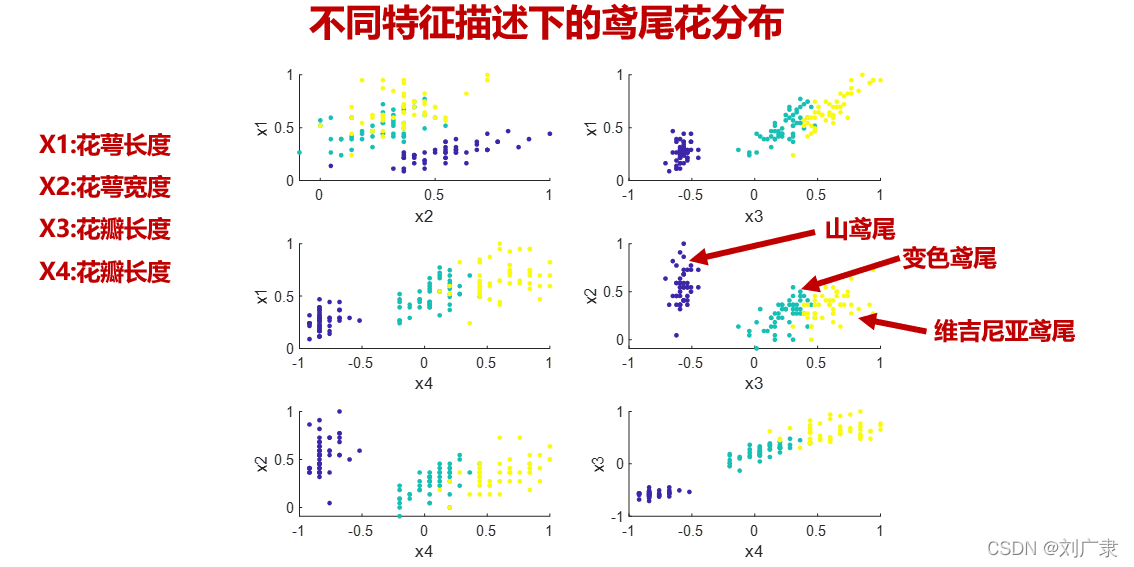
本次采用PCA技術對鳶尾花進行降維,并分析其降維效果,在UCI資料集網站下載得到的資料集如下:
鳶尾花資料簡介:
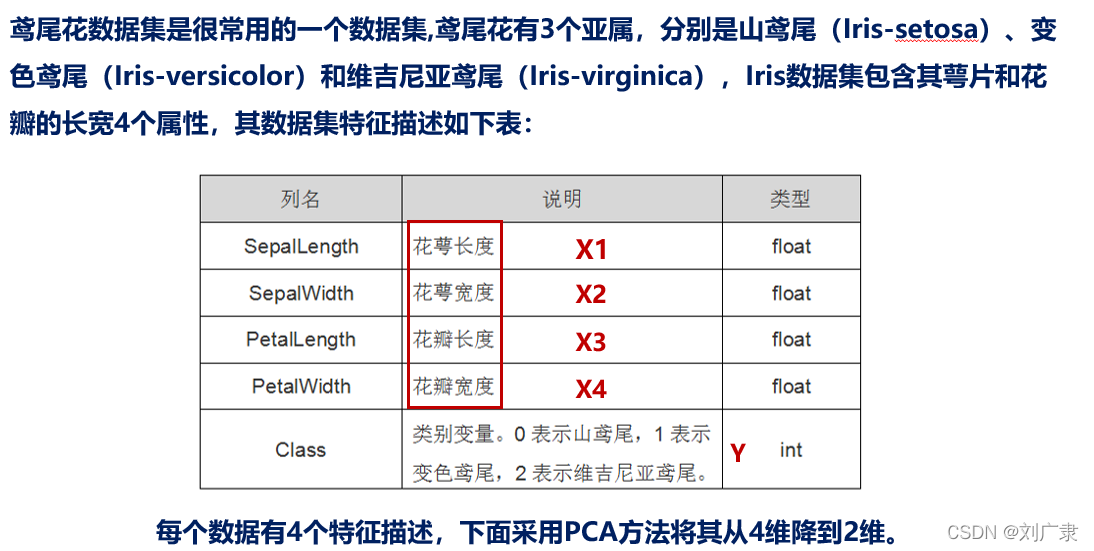
不同特征描述下的分類情況如下:
資料集下載地址:http://archive.ics.uci.edu/ml/datasets/Iris
2、實驗結果
計算得到的特征向量矩陣如下(按列):
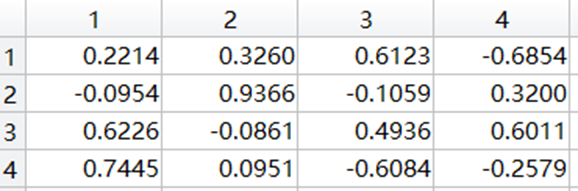
選第1、2列特征向量做變換矩陣:
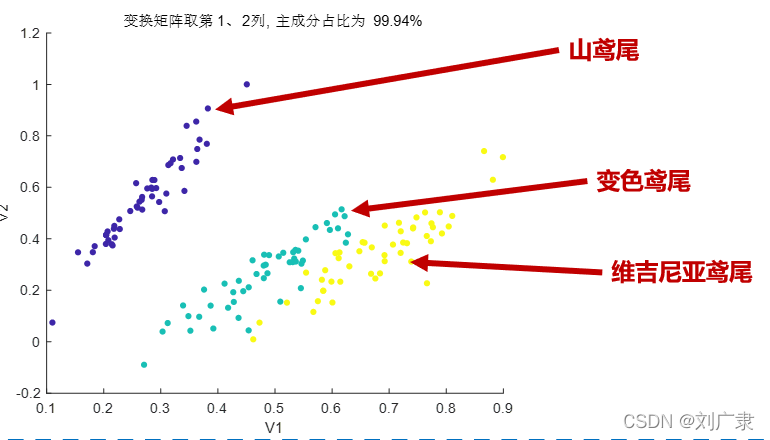
選第1、3列特征向量做變換矩陣:
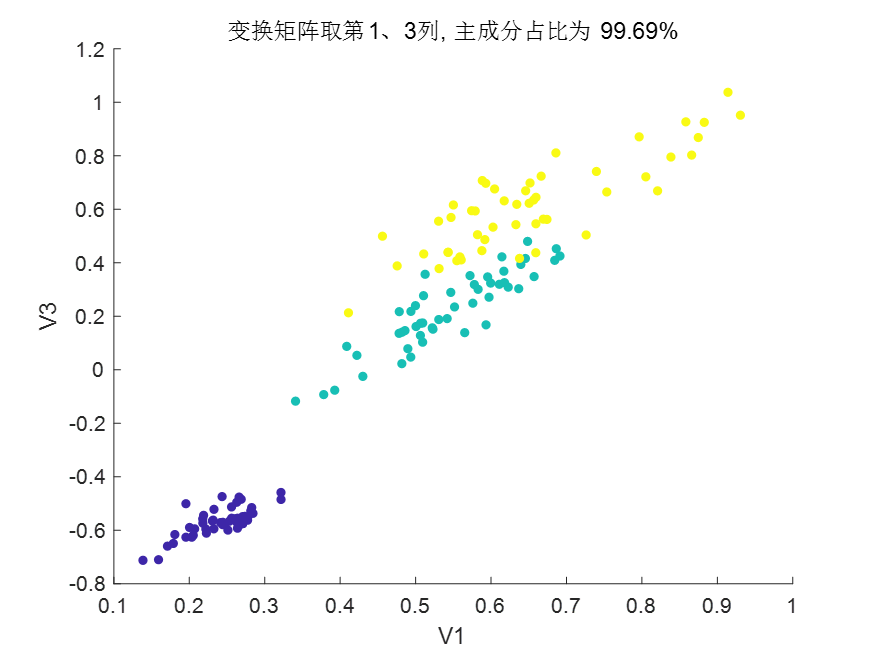
選第2、3列特征向量做變換矩陣(分類效果較差):
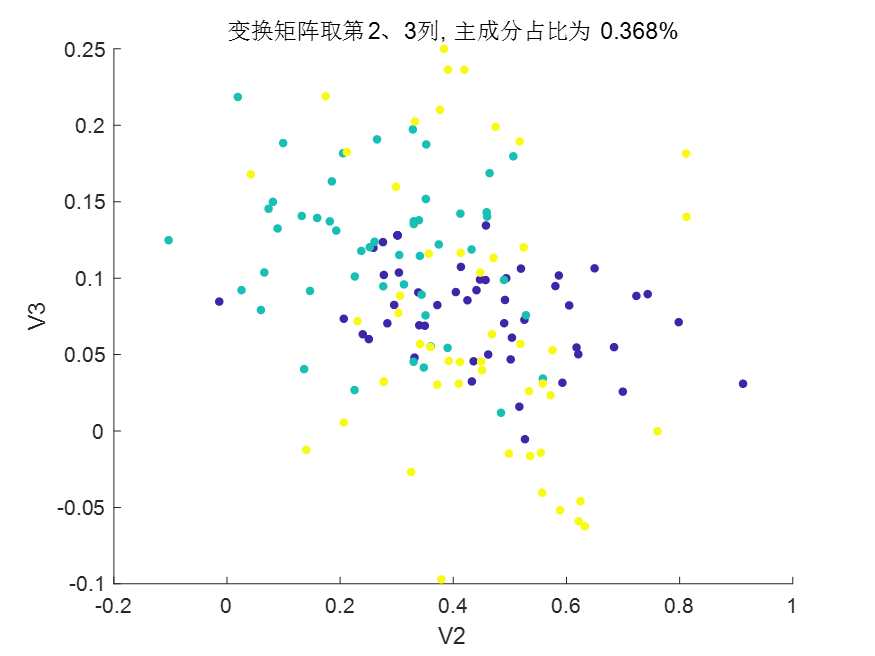
選取不同特征向量得到的主成分占比:

可以發現第一列特征向量的主成分占比最大
3、實驗代碼及說明(Matlab)
%%%%需要事先匯入iris資料集X
[M,N] = size(X); %%%資料集的維度
figure;
for i=1:M
for j=1:i-1
% subplot(3,2,(i-1)+2*(j-1));
if i==4&&j==3
subplot(3,2,6);
else
subplot(3,2,(i-1)+2*(j-1));
end
scatter(X(i,:),X(j,:),7,y,'filled');
xlabel(sprintf('x%g',i)); ylabel(sprintf('x%g',j));
end
end
[V,W] = pca2(X);%計算特征向量及特征值,V為特征向量,W為特征值
mn = mean(X,2);%每行平均值
newX = X - repmat(mn,1,N);%編碼,減去每行平均值
%變換矩陣取前兩列
P = V(:,1:2);
Z = P'*newX;
C = repmat(mn,1,N)+P*Z;%%解碼
q2 = norm(W(1:2))^2/norm(W)^2;%%求主成分
figure(2);
scatter(C(1,:),C(2,:),20,y,'filled')%%繪制散點圖
xlabel('V1'); ylabel('V2')
title(sprintf('變換矩陣取第1、2列, 主成分占比為 %.4g%% ',100*q2))
%變換矩陣取第2、3列
P = V(:,2:3);
Z = P'*newX;
C = repmat(mn,1,N)+P*Z;
q2 = norm(W(2:3))^2/norm(W)^2;%%求主成分
figure(3);
scatter(C(2,:),C(3,:),17,y,'filled')
xlabel('V2'); ylabel('V3')
title(sprintf('變換矩陣取第2、3列, 主成分占比為 %.4g%% ',100*q2))
%變換矩陣取第1、3列
P = V(:,[1,3]);
Z = P'*newX;
C = repmat(mn,1,N)+P*Z;
q2 = norm(W([1,3]))^2/norm(W)^2;%%求主成分
figure(4);
scatter(C(1,:),C(3,:),20,y,'filled')
xlabel('V1'); ylabel('V3')
title(sprintf('變換矩陣取第1、3列, 主成分占比為 %.4g%% ',100*q2))
%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [V,W] = pca2(data)
[M,N] = size(data);
% 減去每個維度的平均值
mn = mean(data,2);%%每行平均值
data = data - repmat(mn,1,N);%%減去每行平均值
% 計算協方差
covariance = 1 / (N-1) .* data * data';
%計算特征值
[V, W] = eig(covariance);
% 計算對應的特征向量
W = diag(W);
% 按特征值大小排列特征向量
[WW, rank] = sort(-1*W);
W = W(rank);
V = V(:,rank);
PCA作為一個非監督學習的降維方法,它只需要特征值分解,就可以對資料進行壓縮、去噪,而且計算還簡單,就是求特征值和特征向量,使用起來非常方便!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400435.html
標籤:AI