機器學習是關于使模型適應資料,出于這個原因,我們首先展示如何表示資料以便計算機理解,
在本章的開頭,我們參考了 Tom Mitchell 對機器學習的定義:“適定學習問題:一個計算機程式被稱為從經驗 E 中學習關于某些任務 T 和某些性能度量 P,如果它在 T 上的性能,為由 P 衡量,隨著經驗 E 改進,” 資料是機器學習的“原材料”,它從資料中學習,在 Mitchell 的定義中,“資料”隱藏在“體驗 E”和“績效衡量 P”這兩個術語之后,如前所述,我們需要標記資料來學習和測驗我們的演算法,
但是,建議您在開始訓練分類器之前先熟悉資料,
Numpy 提供了理想的資料結構來表示您的資料,而 Matplotlib 為可視化您的資料提供了巨大的可能性,
在下面,我們想展示如何使用sklearn模塊中的資料來做到這一點,
虹膜資料集,機器學習的“Hello World”
你看到的第一個程式是什么?我敢打賭,這可能是一個用某種編程語言發出“Hello World”的程式,很可能我是對的,幾乎所有關于編程的介紹性書籍或教程都以這樣的程式開頭,這種傳統可以追溯到 1968 年 Brian Kernighan 和 Dennis Ritchie 合著的“C 編程語言”一書!
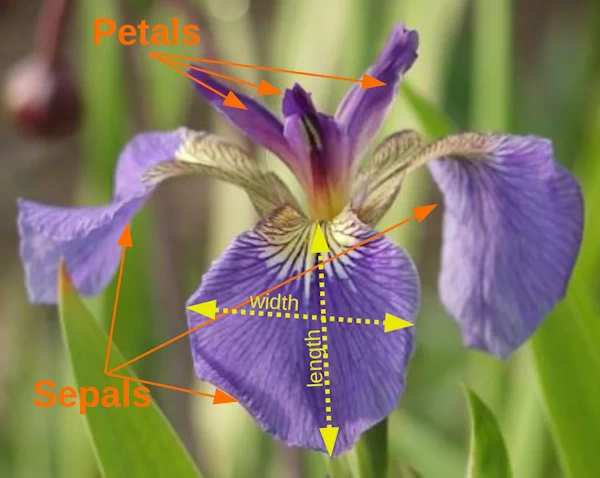
您將在機器學習介紹性教程中看到的第一個資料集是“Iris 資料集”的可能性同樣很高,鳶尾花資料集包含來自 3 個不同物種的 150 朵鳶尾花的測量結果:
- 鳶尾花,
- 變色鳶尾,和
- 鳶尾花-弗吉尼亞,
鳶尾花

變色鳶尾

鳶尾花

鳶尾花資料集因其簡單性而經常被使用,該資料集包含在 scikit-learn 中,但在深入研究 Iris 資料集之前,我們將查看 scikit-learn 中可用的其他資料集,
使用 Scikit-learn 加載虹膜資料
例如,scikit-learn 有一組非常簡單的關于這些鳶尾花的資料,資料包括以下內容:
-
鳶尾花資料集中的特征:
- 萼片長度厘米
- 萼片寬度厘米
- 花瓣長度厘米
- 花瓣寬度厘米
-
要預測的目標類別:
- 鳶尾花
- 變色鳶尾
- 鳶尾花
scikit-learn 嵌入 iris CSV 檔案的副本以及幫助函式以將其加載到 numpy 陣列中:
from sklearn.datasets import load_iris
iris = load_iris ()
結果資料集是一個Bunch物件:
型別(虹膜)
輸出:
sklearn.utils.Bunch
您可以使用以下方法查看此資料型別可用的內容keys():
虹膜,鍵()
輸出:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
Bunch 物件類似于字典,但它還允許訪問屬性樣式中的鍵:
列印(虹膜[ “target_names” ])
列印(虹膜,target_names )
輸出:
['setosa''雜色''弗吉尼亞']
['setosa''雜色''弗吉尼亞']
每個樣本花的特征存盤在data資料集的屬性中:
n_samples , n_features = iris ,資料,形狀
列印(“樣品數:” , N_SAMPLES次)
列印(“的特征數:” , n_features )
#萼片長度,萼片寬度,花瓣長度和第一樣本(第一花)的花瓣寬度
列印(虹膜,資料[ 0 ])
輸出:
樣本數:150
功能數量:4
[5.1 3.5 1.4 0.2]
每朵花的特征都存盤在data資料集的屬性中,讓我們來看看一些示例:
# 指數為 12、26、89 和 114
iris 的花,資料[[ 12 , 26 , 89 , 114 ]]
輸出:
陣列([[4.8, 3., 1.4, 0.1],
[5. , 3.4, 1.6, 0.4],
[5.5, 2.5, 4., 1.3],
[5.8, 2.8, 5.1, 2.4]])
每個樣本的類別資訊,即標簽,存盤在資料集的“目標”屬性中:
列印(虹膜.資料.形狀)
列印(虹膜.目標.形狀)
輸出:
(150, 4)
(150,)
列印(虹膜,目標)
輸出:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
將 numpy 匯入為 np
NP . bincount (虹膜,目標)
輸出:
陣列([50, 50, 50])
使用 NumPy 的 bincount 函式(上圖)我們可以看到這個資料集中的類是均勻分布的——每個物種有 50 朵花,其中
- 第 0 類:鳶尾花
- 第 1 類:變色鳶尾
- 第 2 類:弗吉尼亞鳶尾
這些類名存盤在最后一個屬性中,即target_names:
列印(虹膜,target_names )
輸出:
['setosa''雜色''弗吉尼亞']
我們的鳶尾花資料集的每個樣本的類資訊都存盤在資料集的target屬性中:
列印(虹膜,目標)
輸出:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
除了資料的形狀,我們還可以檢查標簽的形狀,即target.shape:
每個花卉樣本在資料陣列中占一行,列(特征)代表以厘米為單位的花卉測量值,例如,我們可以表示這個 Iris 資料集,由 150 個樣本和 4 個特征組成,一個二維陣列或矩陣電阻150×4 格式如下:
X=[X1(1)X2(1)X3(1)X4(1)X1(2)X2(2)X3(2)X4(2)????X1(150)X2(150)X3(150)X4(150)]
上標分別表示第i行,下標分別表示第j個特征,
一般來說,我們有 n 行和 克 列:
X=[X1(1)X2(1)X3(1)…X克(1)X1(2)X2(2)X3(2)…X克(2)?????X1(n)X2(n)X3(n)…X克(n)]
列印(虹膜.資料.形狀)
列印(虹膜.目標.形狀)
輸出:
(150, 4)
(150,)
bincountof NumPy 計算非負整數陣列中每個值的出現次數,我們可以使用它來檢查資料集中類的分布:
將 numpy 匯入為 np
NP . bincount (虹膜,目標)
輸出:
陣列([50, 50, 50])
我們可以看到類是均勻分布的——每個物種有 50 朵花,即
- 第 0 類:鳶尾花-Setosa
- 第 1 類:變色鳶尾
- 第 2 類:Iris-Virginica
這些類名存盤在最后一個屬性中,即target_names:
列印(虹膜,target_names )
輸出:
['setosa''雜色''弗吉尼亞']
可視化虹膜資料集的特征
特征資料是四維的,但我們可以使用簡單的直方圖或散點圖一次可視化一兩個維度,
從 sklearn.datasets 匯入 load_iris
虹膜 = load_iris ()
列印(虹膜,資料[虹膜,目標== 1 ] [:5 ])
列印(虹膜,資料[虹膜,靶向== 1 , 0 ] [:5 ])
輸出:
[[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]]
[7. 6.4 6.9 5.5 6.5]
特征的直方圖
匯入 matplotlib.pyplot 作為 plt
圖, ax = plt ,副區()
x_index = 3個
色 = [ '藍' , '紅' , '綠色' ]
為 標簽, 顏色 在 拉鏈(范圍(len個(虹膜,target_names )), 顏色):
斧,HIST (虹膜,資料[虹膜,目標==標簽, x_index ],
標簽=虹膜,target_names [標簽],
顏色=顏色)
斧頭,set_xlabel ( iris . feature_names [ x_index ])
ax ,圖例(loc = '右上角' )
plt ,顯示()
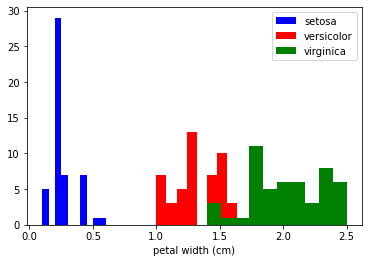
鍛煉
查看其他特征的直方圖,即花瓣長度、萼片寬度和萼片長度,
具有兩個特征的散點圖
外觀圖在一張圖中顯示了兩個特征:
匯入 matplotlib.pyplot 作為 plt
fig , ax = plt ,子圖()
x_index = 3
y_index = 0
顏色 = [ '藍色' 、 '紅色' 、 '綠色' ]
為 標簽, 顏色 在 拉鏈(范圍(len個(虹膜,target_names )), 顏色):
斧,散射(虹膜,資料[虹膜,目標==標簽, x_index ],
虹膜,資料[虹膜,目標==標簽, y_index ],
標簽=虹膜,target_names [標簽],
c =顏色)
斧頭,set_xlabel ( iris . feature_names [ x_index ])
ax ,set_ylabel ( iris . feature_names [ y_index ])
ax ,圖例(loc = '左上' )
plt ,顯示()
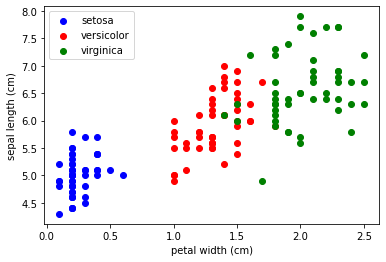
鍛煉
更改上面腳本中的 x_index 和 y_index
更改上面腳本中的 x_index 和 y_index 并找到最大程度地分隔三個類的兩個引數的組合,
概括
我們現在將在一個組合圖中查看所有特征組合:
匯入 matplotlib.pyplot 作為 plt
n = len ( iris . feature_names )
fig , ax = plt ,子圖( n , n , figsize = ( 16 , 16 ))
顏色 = [ '藍色' 、 '紅色' 、 '綠色' ]
對于 X 在 范圍(? ):
用于 Y 在 范圍(? ):
的XName = 虹膜,特征名稱[ x ]
yname = 虹膜,feature_names [ ? ]
為 color_ind 在 范圍(len個(虹膜,target_names )):
斧[ X , ? ] ,分散(虹膜,資料[虹膜,目標== color_ind , x ],
iris ,資料[虹膜. 目標== color_ind , y ],
標簽= iris ,目標名稱[ color_ind ],
c =顏色[ color_ind ])
軸[ x , y ] ,set_xlabel ( xname )
ax [ x , y ] ,set_ylabel ( yname )
ax [ x , y ] ,圖例(loc = '左上' )
PLT ,顯示()
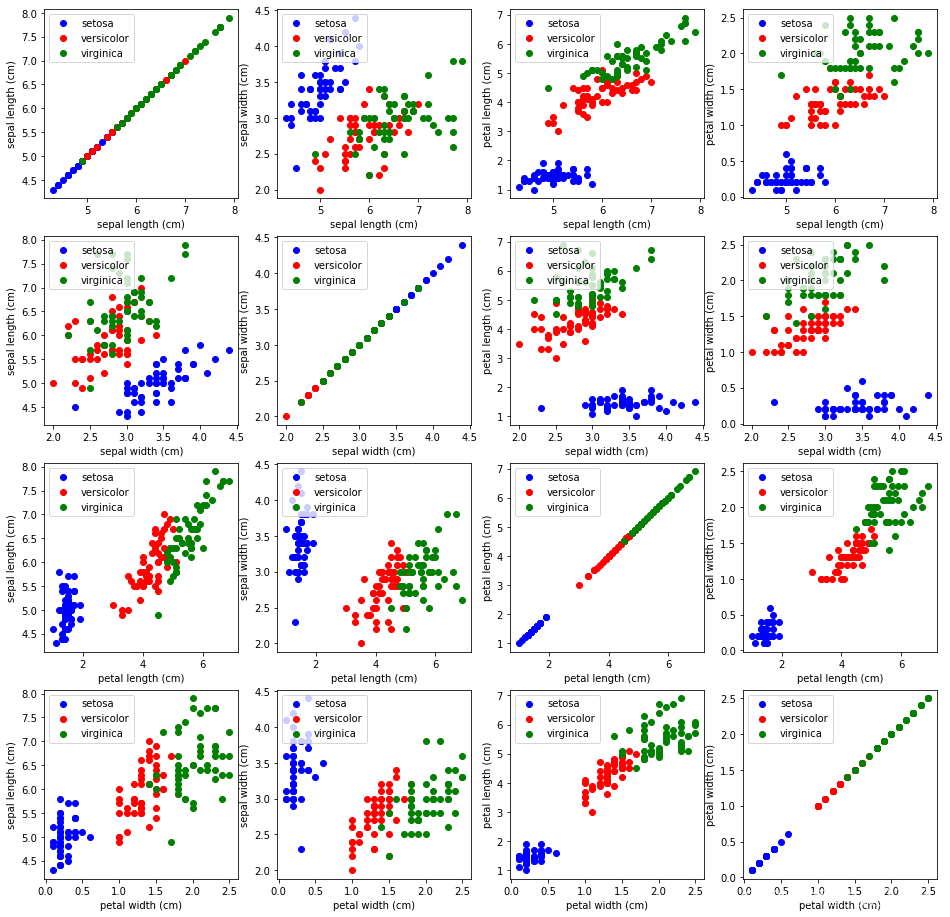
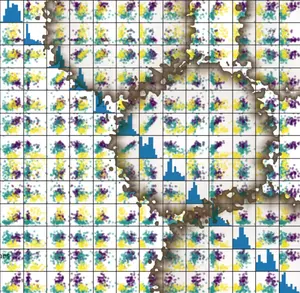
散點圖'矩陣
除了手動操作,我們還可以使用pandas 模塊提供的散點圖矩陣,
散點圖矩陣顯示資料集中所有特征之間的散點圖,以及顯示每個特征分布的直方圖,
將 熊貓 匯入為 pd
iris_df = pd ,資料幀(虹膜,資料, 列=虹膜,feature_names )
PD ,繪圖,scatter_matrix ( iris_df ,
c = iris . target ,
figsize = ( 8 , 8 )
);
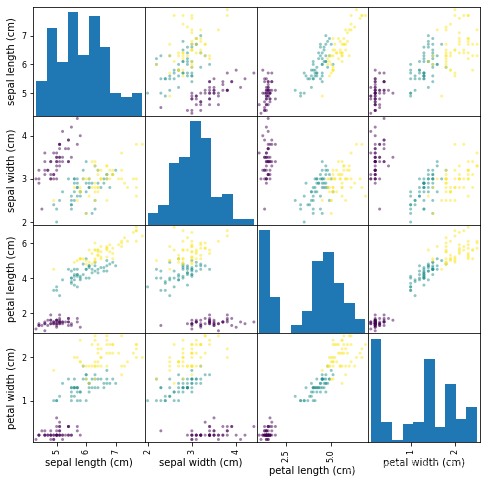
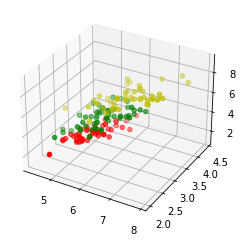
3維可視化
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from mpl_toolkits.mplot3d import Axes3D
iris = load_iris ()
X = []
for iclass in range ( 3 ):
X ,附加([[], [], []])
for i in range ( len ( iris . data )):
if iris . 目標[ i ] == iclass :
X [ iclass ][ 0 ] ,追加(虹膜,資料[ i ][ 0 ])
X [ iclass ][ 1 ] ,追加(虹膜,資料[ i ][ 1 ])
X [ iclass ][ 2 ] ,追加(總和(虹膜,資料[ i ][ 2 :]))
顏色 = ( "r" , "g" , "y" )
fig = plt . 圖()
ax = 圖. add_subplot ( 111 , 投影= '3d' )
為 的iCLASS 在 范圍(3 ):
斧,scatter ( X [ iclass ][ 0 ], X [ iclass ][ 1 ], X [ iclass ][ 2 ], c = colors [ iclass ])
plt . 顯示()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400437.html
標籤:AI