線性可分資料集
正如我們在機器學習教程的前一章中所展示的,僅由一個感知器組成的神經網路足以分離我們的示例類,當然,我們精心設計了這些類以使其作業,有許多類集群,對于它們不起作用,我們將查看其他一些示例,并將討論無法分離類的情況,
我們的類是線性可分的,線性可分性在歐幾里得幾何中有意義,兩組點(或類)稱為線性可分的,如果平面中至少存在一條直線,使得一類的所有點都在直線的一側,而另一類的所有點都在另一側邊,
更正式的:
如果兩個資料簇(類)可以通過線性方程形式的決策邊界分開
∑一世=1nX一世?瓦一世=0
它們被稱為線性可分,
否則,即如果這樣的決策邊界不存在,則這兩個類被稱為線性不可分,在這種情況下,我們不能使用簡單的神經網路,
AND 函式的感知器
在我們的下一個示例中,我們將用 Python 撰寫一個神經網路,它實作邏輯“與”函式,它按以下方式為兩個輸入定義:
| 輸入1 | 輸入2 | 輸出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
我們在上一章中了解到,具有一個感知器和兩個輸入值的神經網路可以解釋為決策邊界,即劃分兩個類別的直線,我們要在示例中分類的兩個類如下所示:
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
圖, ax = plt ,子圖()
xmin , xmax = - 0.2 , 1.4
X = np ,arange ( xmin , xmax , 0.1 )
ax ,scatter ( 0 , 0 , color = "r" )
ax ,scatter ( 0 , 1 , color = "r" )
ax ,分散(1 , 0 , color = "r" )
ax ,scatter ( 1 , 1 , color = "g" )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
m = - 1
#ax.plot(X, m * X + 1.2, label="decision boundary")
plt . 情節()
輸出:

我們還發現,這樣一個原始的神經網路只能創建穿過原點的直線,所以分割線是這樣的:
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
圖, ax = plt ,子圖()
xmin , xmax = - 0.2 , 1.4
X = np ,arange ( xmin , xmax , 0.1 )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
m = - 1
for m in np ,范圍(0 , 6 , 0.1 ):
ax ,繪圖( X , m * X )
ax ,scatter ( 0 , 0 , color = "r" )
ax ,scatter ( 0 , 1 , color = "r" )
ax ,scatter ( 1 , 0 , color = "r" )
ax ,分散( 1, 1 , color = "g" )
plt . 情節()
輸出:
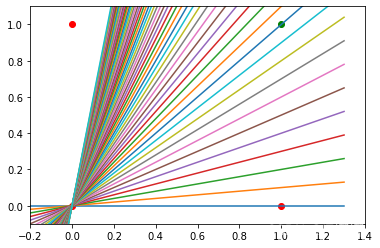
我們可以看到,這些直線都不能用作決策邊界,也不能用作穿過原點的任何其他直線,
我們需要一條線
是=米?X+C其中截距c不等于 0,
例如線
是=-X+1.2
可以用作我們問題的分隔線:
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
圖, ax = plt ,子圖()
xmin , xmax = - 0.2 , 1.4
X = np ,arange ( xmin , xmax , 0.1 )
ax ,scatter ( 0 , 0 , color = "r" )
ax ,scatter ( 0 , 1 , color = "r" )
ax ,分散(1 , 0 , color = "r" )
ax ,scatter ( 1 , 1 , color = "g" )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
m , c = - 1 , 1.2
ax ,繪圖( X , m * X + c )
PLT ,情節()
輸出:
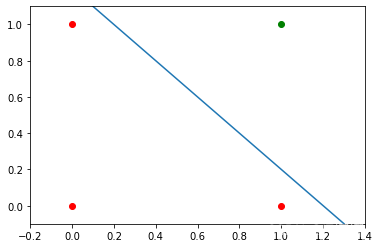
現在的問題是,我們能否找到對網路模型稍加修改的解決方案?或者換句話說:我們能否創建一個能夠定義任意決策邊界的感知器?
解決方案包括添加偏置節點,
具有偏差的單個感知器
具有兩個輸入值和一個偏差的感知器對應于一條一般直線,借助偏置值,b我們可以訓練感知器來確定具有非零截距的決策邊界c,
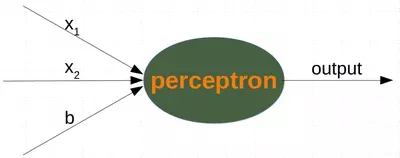
雖然輸入值可以改變,但偏置值始終保持不變,只能調整偏置節點的權重,
現在,感知器的線性方程包含偏差:
∑一世=1n瓦一世?X一世+瓦n+1?乙=0
在我們的例子中,它看起來像這樣:
瓦1?X1+瓦2?X2+瓦3?乙=0
這相當于
X2=-瓦1瓦2?X1-瓦3瓦2?乙
這意味著:
米=-瓦1瓦2
和
C=-瓦3瓦2?乙
import numpy as np
from collections import Counter
類 感知器:
def __init__ ( self ,
weights ,
bias = 1 ,
learning_rate = 0.3 ):
"""
'weights' 可以是一個 numpy 陣列、串列或具有
權重實際值的
元組,輸入值的數量 由'weights'
"""
self 的長度,權重 = np ,陣列(權重)
自我,偏見 = 偏見
自我,學習率 = 學習率
@staticmethod
def unit_step_function ( x ):
如果 x <= 0 :
return 0
else :
return 1
def __call__ ( self , in_data ):
in_data = np ,串連( (IN_DATA , [自,偏壓]) )
結果 = 自我,weights @ in_data
回傳 感知器,unit_step_function (結果)
def 調整( self ,
target_result ,
in_data ):
if type ( in_data ) != np . ndarray :
in_data = np ,陣列(IN_DATA ) #
calculated_result = 自(IN_DATA )
誤差 = target_result - calculated_result
如果 錯誤 =! 0 :
IN_DATA = NP ,連接( (in_data , [ self . 偏差]) )
校正 = 錯誤 * in_data * self ,learning_rate
自我,權重 += 修正
DEF 評估(自, 資料, 標簽):
評價 = 計數器()
對于 樣品, 標簽 在 拉鏈(資料, 標簽):
結果 = 自(樣品) #預測
如果 結果 == 標簽:
評價[ “正確” ] + = 1
否則:
評估[ “錯誤” ] += 1
回傳 評估
我們假設上面帶有 Perceptron 類的 Python 代碼以“perceptrons.py”的名稱存盤在您當前的作業目錄中,
import numpy as np
from perceptrons import Perceptron
def labelled_samples ( n ):
for _ in range ( n ):
s = np ,隨機的,randint ( 0 , 2 , ( 2 ,))
yield ( s , 1 ) if s [ 0 ] == 1 and s [ 1 ] == 1 else ( s , 0 )
p = 感知器(權重= [ 0.3 , 0.3 , 0.3 ],
learning_rate = 0.2 )
對于 IN_DATA , 標簽 在 labelled_samples (30 ):
p ,調整(標簽,
輸入資料)
test_data , test_labels = list ( zip ( * labelled_samples ( 30 )))
評價 = p ,評估(test_data , test_labels )
列印(評估)
輸出:
計數器({'正確':30})
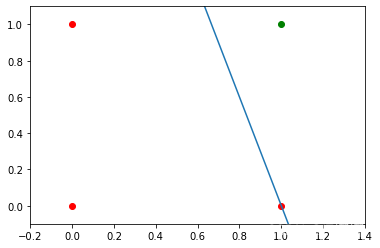
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
圖, ax = plt ,子圖()
xmin , xmax = - 0.2 , 1.4
X = np ,arange ( xmin , xmax , 0.1 )
ax ,scatter ( 0 , 0 , color = "r" )
ax ,scatter ( 0 , 1 , color = "r" )
ax ,分散(1 , 0 , color = "r" )
ax ,scatter ( 1 , 1 , color = "g" )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
m = - p ,權重[ 0 ] / p ,權重[ 1 ]
c = - p. 權重[ 2 ] / p ,weights [ 1 ]
列印( m , c )
ax ,繪圖( X , m * X + c )
plt ,情節()
輸出:
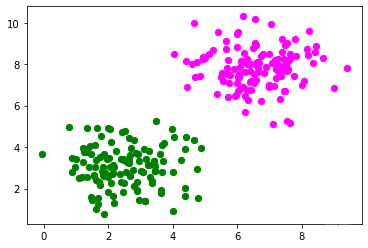
我們將創建另一個具有線性可分資料集的示例,該資料集需要一個偏置節點才能進行分離,我們將使用以下make_blobs函式sklearn.datasets:
從 sklearn.datasets 匯入 make_blobs
n_samples = 250 個
樣本, 標簽 = make_blobs ( n_samples = n_samples ,
中心= ([ 2.5 , 3 ], [ 6.7 , 7.9 ]),
random_state = 0 )
讓我們可視化之前創建的資料:
匯入 matplotlib.pyplot 作為 plt
顏色 = ( 'green' , 'magenta' , 'blue' , 'cyan' , 'yellow' , 'red' )
fig , ax = plt . 子圖()
用于 n_class 在 范圍(2 ):
斧,分散(樣本[標簽== n_class ][:, 0 ], 樣本[標簽== n_class ][:, 1 ],
c =顏色[ n_class ], s = 40 , label = str ( n_class ))
n_learn_data = int ( n_samples * 0.8 ) # 80% 的可用資料點
learn_data , test_data = samples [: n_learn_data ], samples [ - n_learn_data :]
learn_labels , test_labels = labels [: n_learn_data ], labels [ - n_learn_data :]
從 感知器 匯入 感知器
p = 感知器(權重= [ 0.3 , 0.3 , 0.3 ],
learning_rate = 0.8 )
為 樣品, 標簽 在 拉鏈(learn_data , learn_labels ):
p ,調整(標簽,
樣本)
評價 = p ,評估(學習資料, 學習標簽)
列印(評估)
輸出:
計數器({'正確':200})
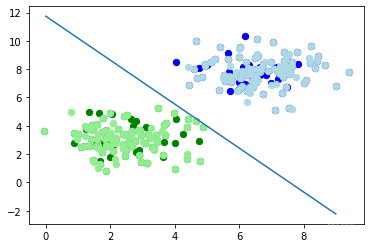
讓我們可視化決策邊界:
匯入 matplotlib.pyplot 作為 plt
圖, ax = plt ,子圖()
# 繪制學習資料
colors = ( 'green' , 'blue' )
for n_class in range ( 2 ):
ax ,分散( learn_data [ learn_labels == n_class ][:, 0 ],
learn_data [ learn_labels == n_class ][:, 1 ],
c =顏色[ n_class ], s = 40 , label = str ( n_class))
# 繪制測驗資料
colors = ( 'lightgreen' , ' lightblue ' )
for n_class in range ( 2 ):
ax . 分散( test_data [ test_labels == n_class ][:, 0 ],
test_data [ test_labels == n_class ][:, 1 ],
c =顏色[ n_class ], s = 40 , label = str ( n_class))
X = np ,arange ( np . max ( samples [:, 0 ]))
m = - p ,權重[ 0 ] / p ,權重[ 1 ]
c = - p ,權重[ 2 ] / p ,weights [ 1 ]
列印( m , c )
ax ,情節( X, m * X + c )
plt ,情節()
plt ,顯示()
輸出:
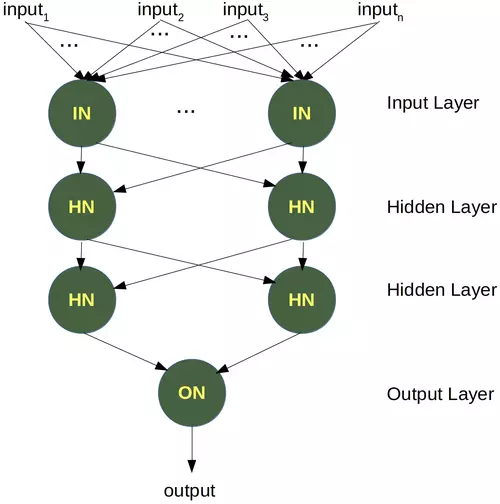
在下一節中,我們將介紹神經網路的 XOR 問題,它是非線性可分神經網路的最簡單示例,它可以通過額外的神經元層來解決,稱為隱藏層,
神經網路的異或問題
XOR(異或)函式由以下真值表定義:
| 輸入1 | 輸入2 | 異或輸出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
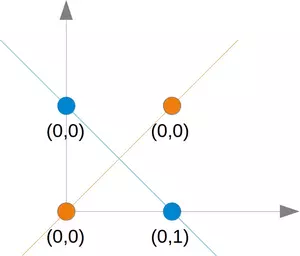
這個問題不能用簡單的神經網路解決,如下圖所示:
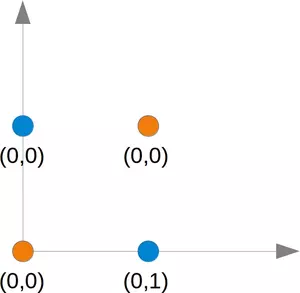
無論您選擇哪條直線,您都不會成功地在一側擁有藍色點而在另一側擁有橙色點,這如下圖所示,橙色點位于橙色線上,這意味著這不能是一條分界線,如果我們平行移動這條線——無論朝哪個方向,總會有兩個橙色和一個藍色點在一側,而在另一側只有一個藍色點,如果我們以非平行方式移動橙色線,則兩側將有一個藍色和一個橙色點,除非該線通過橙色點,所以沒有辦法用一條直線來分隔這些點,
為了解決這個問題,我們需要引入一種新型的神經網路,一種具有所謂隱藏層的網路,隱藏層允許網路重新組織或重新排列輸入資料,
我們只需要一個帶有兩個神經元的隱藏層,一個像與門一樣作業,另一個像或門一樣作業,當 OR 門觸發而 AND 門不觸發時,輸出將“觸發”,
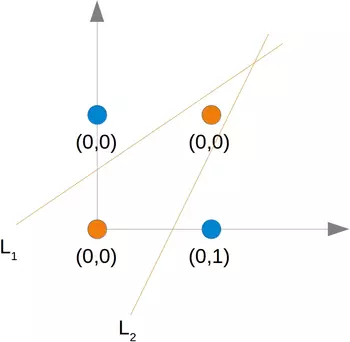
正如我們已經提到的,我們找不到將橙色點與藍色點分開的線,但是它們可以用兩條線分開,例如下圖中的L 1和 L 2:
為了解決這個問題,我們需要以下型別的網路,即具有隱藏層 N 1和 N 2
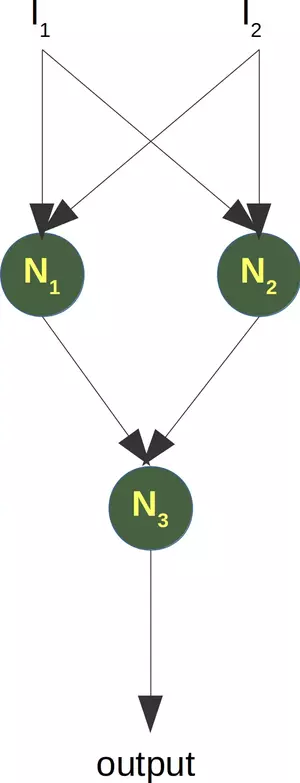
神經元N 1將確定一條線,例如L 1并且神經元N 2將確定另一條線L 2,N 3最侄訓解決我們的問題:
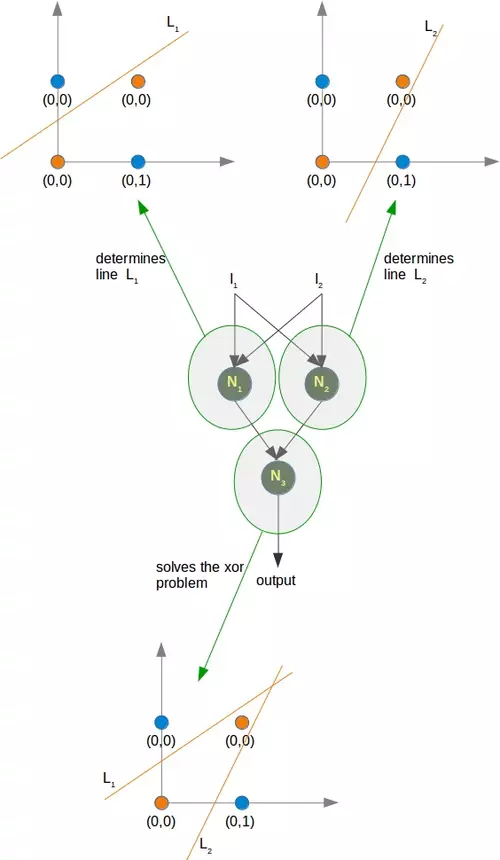
在 Python 中實作這一點必須等到我們機器學習教程的下一章,
練習
練習 1
我們可以通過以下方式將邏輯 AND 擴展為 0 和 1 之間的浮點值:
| 輸入1 | 輸入2 | 輸出 |
|---|---|---|
| x1 < 0.5 | x2 < 0.5 | 0 |
| x1 < 0.5 | x2 >= 0.5 | 0 |
| x1 >= 0.5 | x2 < 0.5 | 0 |
| x1 >= 0.5 | x2 >= 0.5 | 1 |
嘗試訓練一個只有一個感知器的神經網路,為什么不起作用?
練習 2
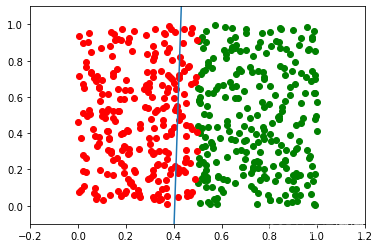
一個點屬于 0 類,如果 X1<0.5 并且屬于第 1 類,如果 X1>=0.5. 用一個感知器訓練一個網路來對任意點進行分類,你對切割邊界有什么看法?輸入值怎么樣X2
練習題解答
第一個練習的解決方案
從 感知器 匯入 感知器
p = 感知器(權重= [ 0.3 , 0.3 , 0.3 ],
偏差= 1 ,
learning_rate = 0.2 )
def labelled_samples ( n ):
for _ in range ( n ):
s = np ,隨機的,random (( 2 ,))
yield ( s , 1 ) if s [ 0 ] >= 0.5 and s [ 1 ] >= 0.5 else ( s , 0 )
對于 IN_DATA , 標簽 在 labelled_samples (30 ):
p ,調整(標簽,
輸入資料)
test_data , test_labels = list ( zip ( * labelled_samples ( 60 )))
評價 = p ,評估(test_data , test_labels )
列印(評估)
輸出:
計數器({'正確':52,'錯誤':8})
查看為什么它不起作用的最簡單方法是將資料可視化,
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
ones = [ test_data [ i ] for i in range ( len ( test_data )) if test_labels [ i ] == 1 ]
zeroes = [ test_data [ i ] for i in range ( len ( test_data )) if test_labels [ i ] == 0 ]
圖, ax = plt ,subplots ()
xmin , xmax = - 0.2 , 1.2
X , Y = list ( zip ( * ones ))
ax ,scatter ( X , Y , color = "g" )
X , Y = list ( zip ( * zeroes ))
ax ,散射( X , Y , color = "r" )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
c = - p ,權重[ 2 ] / p ,權重[ 1 ]
m = - p ,權重[ 0 ] / p ,權重[ 1 ]
X = NP . arange ( xmin , xmax , 0.1 )
ax ,繪圖(X , m * X + c , 標簽= “決策邊界” )
輸出:
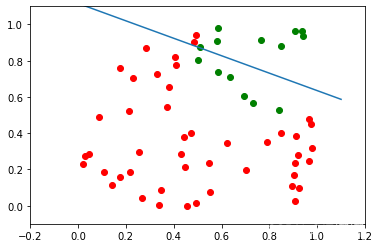
我們可以看到,綠點和紅點不是一條直線,
第二個練習的解決方案
從 感知器 匯入 感知器
import numpy as np
from collections import Counter
def labelled_samples ( n ):
for _ in range ( n ):
s = np ,隨機的,random (( 2 ,))
yield ( s , 0 ) if s [ 0 ] < 0.5 else ( s , 1 )
p = 感知器(權重= [ 0.3 , 0.3 , 0.3 ],
learning_rate = 0.4 )
對于 IN_DATA , 標簽 在 labelled_samples (300 ):
p ,調整(標簽,
輸入資料)
test_data , test_labels = list ( zip ( * labelled_samples ( 500 )))
列印(p ,權重)
p ,評估(test_data , test_labels )
輸出:
[ 2.22622234 -0.05588858 -0.9 ]
計數器({'正確':460,'錯誤':40})
將 matplotlib.pyplot 匯入為 plt
將 numpy 匯入為 np
ones = [ test_data [ i ] for i in range ( len ( test_data )) if test_labels [ i ] == 1 ]
zeroes = [ test_data [ i ] for i in range ( len ( test_data )) if test_labels [ i ] == 0 ]
圖, ax = plt ,subplots ()
xmin , xmax = - 0.2 , 1.2
X , Y = list ( zip ( * ones ))
ax ,scatter ( X , Y , color = "g" )
X , Y = list ( zip ( * zeroes ))
ax ,散射( X , Y , color = "r" )
ax ,set_xlim ([ xmin , xmax ])
ax ,set_ylim ([ - 0.1 , 1.1 ])
c = - p ,權重[ 2 ] / p ,權重[ 1 ]
m = - p ,權重[ 0 ] / p ,權重[ 1 ]
X = NP . arange ( xmin , xmax , 0.1 )
ax ,繪圖(X , m * X + c , 標簽= “決策邊界” )
輸出:
p ,權重, 米
輸出:
(陣列([ 2.22622234, -0.05588858, -0.9 ]), 39.83322163376969)
m在這種情況下,斜率必須越來越大,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400439.html
標籤:AI