1,PyTorch安裝
1.1,不需切換版本
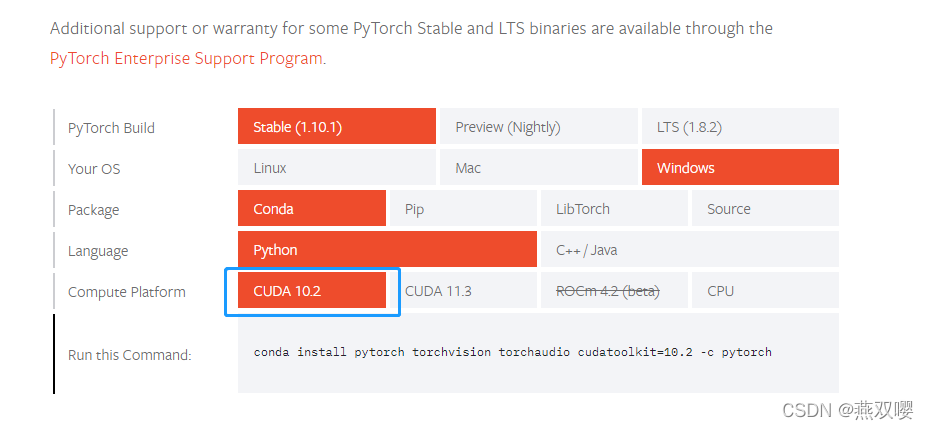
前往PyTorch官網,找到對應自己顯卡版本的PyTorch安裝命令,
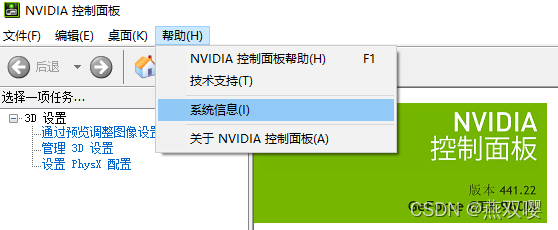
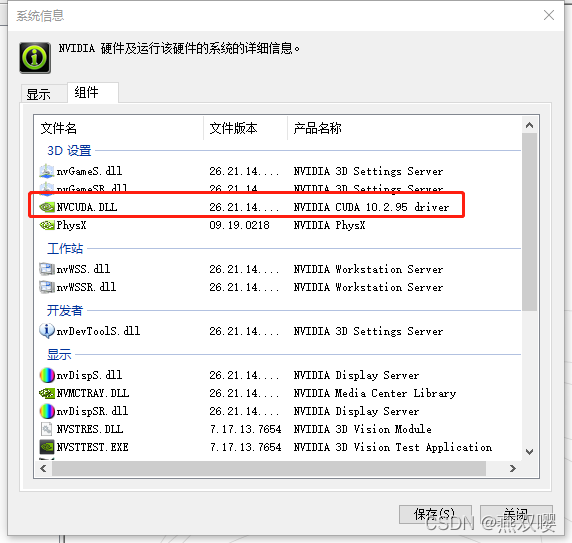
PyTorch只對CUDA版本有要求,對于cudnn沒有要求,甚至不需要安裝,查看方式如下:
1.2,切換CUDA版本
前往NVIDA官網(CUDA Toolkit Archive | NVIDIA Developer)下載指定版本,
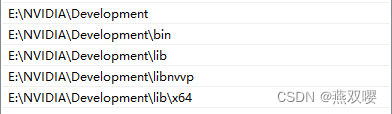
安裝路徑自定義,其他的默認,最后還需要在系統變數中添加如下內容:
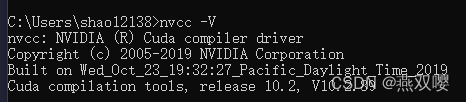
驗證方式:
2,PyTorch基礎知識
2.1,構造Tensor
Tensor是PyTorch中用來存盤多維矩陣資料的資料結構,和NumPy中的naddary比較類似,但Tensor能夠使用GPU來加速運算,
在PyTorch中構造Tensor方式有很多:
#生成隨機Tensor import torch x = torch.Tensor(2, 3) print(x) ================================================ tensor([[-7.5173e-01, 9.3731e-38, -1.5563e-04], [ 9.3731e-38, -4.4988e-05, 9.3731e-38]])#利用list構造Tensor import torch x = torch.Tensor([1,2,3]) print(x) y = torch.Tensor([[1,2,3],[6,5,4]]) print(y) =================================== tensor([1., 2., 3.]) tensor([[1., 2., 3.], [6., 5., 4.]])import torch #隨機元素值0~1之間矩陣 x= torch.rand(3,3) print(x) #元素全部為0的矩陣 x= torch.zeros(3,3) print(x) #元素全部為1的矩陣 x= torch.ones(3,3) print(x) ================================== tensor([[0.3766, 0.8037, 0.7080], [0.9064, 0.4387, 0.0712], [0.0787, 0.1682, 0.7385]]) tensor([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]) tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]])獲取一個Tensor的大小:
x = torch.ones(3, 3) print(x.size()) ==================== torch.Size([3, 3])
2.2,Tensor操作
在PyTorch中我們可以方便地進行一些數學運算和矩陣操作,比如矩陣可以直接乘以一個數字,再加上另外一個矩陣:
x=torch.ones(2,3) y=torch.ones(2,3)*2 print(x+y) print(torch.add(x,y)) print(x.add_(y)) print(x*y)PS:add_()會原地修改Tensor x的值,在PyTorch中,任何原地修改Tensor內容的操作都會在方法名后加一個下劃線作為后綴,例如:x.copy_(y)、x.t_(),這些都會改變x的值,
Tensor也支持NumPy中各種切片操作,比如操作矩陣的某一列:
x = torch.ones(3, 3) x[:, 1] = x[:, 1] + 2 print(x) ==================== tensor([[3., 3., 3.], [1., 1., 1.], [1., 1., 1.]])
另外,可以使用torch.view()來改變矩陣的形狀(同NumPy中的reshape):
x = torch.ones(3, 3) x=x.view(1,9) print(x) ============================================== tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1.]])
2.3,Tensor和NumPy array間的轉化
Torch的Tensor和NumPy的array可以非常方便地進行相互轉化,但是需要注意的是,它們會共享記憶體的地址,所以修改其中一個會導致另外一個也發生改變,
import torch x = torch.ones(2, 3) print(x) y = x.numpy() print(y) x.add_(2) print(y) z = torch.from_numpy(y) print(z) ======================== tensor([[1., 1., 1.], [1., 1., 1.]]) [[1. 1. 1.] [1. 1. 1.]] [[3. 3. 3.] [3. 3. 3.]] tensor([[3., 3., 3.], [3., 3., 3.]])
2.4,Autograd:自動梯度
在任何深度學習框架中,都需要一個計算誤差的梯度并進行反向傳播的機制,這對于構建神經網路模型至關重要,在PyTorch中,這個機制是由Autograd包實作的,其中提供了對Tensor上的所有操作進行自動求導操作,
Variale類是Autograd包中最核心的一個類,它包裝了一個Tensor,并且支持幾乎所有定義在Tensor上的操作,我們可以通過.data屬性訪問原始的Tensor,
import torch from torch.autograd import Variable x = Variable(torch.ones(2, 2) * 2, requires_grad=True) print(x) print(x.data) ===================================================== tensor([[2., 2.], [2., 2.]], requires_grad=True) tensor([[2., 2.], [2., 2.]])我們傳入了一個Tensor,并設定requires_grad引數為True,只有一個Variable的requires_grad為True,我們才能求出關于它的梯度,
x = Variable(torch.ones(2, 2) * 2, requires_grad=True) y = 2 * (x * x) + 5 * x print(y) ============================= tensor([[18., 18.], [18., 18.]], grad_fn=<AddBackward0>)
可以看作一個關于
的函式,它關于
的運算式我們可以通過計算得到:
,現在
,將其帶入
,
import torch from torch.autograd import Variable x = Variable(torch.ones(2, 2) * 2, requires_grad=True) y = 2 * (x * x) + 5 * x y=y.sum() y.backward() print(x.grad) ===================== tensor([[13., 13.], [13., 13.]])在PyTorch中,當我們計算完成之后,可以通過呼叫.backward()方法來自動計算梯度,現在我們需要計算的是y關于x的梯度,所以我們呼叫y.backward(),而計算得到的梯度會存盤到Variable x的.grad屬性中,
3,PyTorch中搭建神經網路
3.1,定義神經網路
在PyTorch中,神經網路的構件主要使用torch.nn包,我們定義的神經網路需要繼承內置的nn.Module類,nn.Module類給我們提供了很多定義好的功能,一般情況下我們只需要定義自己的網路模型結構及前向方法,
import torch import torch.nn.functional as F import torch.nn as nn class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 定義一個神經網路 self.conv1 = nn.Conv2d(3, 6, 5) # 兩個卷積層,三個全連接層 self.conv2 = nn.Conv2d(6, 16, 5) # 輸入3個通道,輸出6個通道,卷積核5*5 self.fc1 = nn.Linear(16 * 5 * 5, 120) # 輸入84維,輸出10維 self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) # 在init中我們值定義了搭建網路的層,但沒有真正定義網路的結構 # 真正的輸入輸出關系是在forward()方法中定義的,控制資料在網路中的流動方式 def forward(self, x): x = F.max_pool2d(F.relu(self.conv1(x)), 2) # 激活函式ReLU,先經過一個卷積層,然后一個全連接層 x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xPS:torch.nn中要求輸入的資料是一個mini-batch,因為我們的影像資料(CIFAR-10)本身是3維的,所以forward()的輸入x是4維的,在經過兩個卷積層之后還是4維的Tensor,所以在輸入后面的全連接層之前我們先使用.view()方法將其轉化為2維的Tensor,
這樣就定義好了我們自己的神經網路,接下來我們可以創建這個神經網路的實體,并列印出來,
if __name__ == '__main__': net = Net() print(net) #神經網路結果 ============================ Net( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
神經網路模型中可以訓練的引數由net.parameters()回傳,在我們剛才定義的網路中,共有10個引數,分別對應于5個層的weight引數和bias引數(權重和偏執),比如前面兩個分別是第1個卷積層conv1的weight引數和bias引數,我們可以通過列印出來的引數的size確定這一點,
params = list(net.parameters()) print(len(params)) print(params[0].size()) print(params[1].size()) =============================== 10 torch.Size([6, 3, 5, 5]) torch.Size([6])我們也可以直接通過層和引數的名字訪問具體的引數,比如net.conv1.weight是第一個卷積層conv1的weight引數,另外,我們可以看到,這些模型引數的requires_grad是默認的True,這意味著后面可以計算關于這些引數的梯度并用梯度來更新這些引數,
當然,如果我們想要固定網路中的某些層的引數不更新,那么可以設定這部分網路對應的引數的requires_grad為False,這樣在方向求梯度程序中就不會計算這些引數對應的梯度了,
print(net.conv1.weight.size()) print(net.conv1.bias.size()) print(net.conv1.weight.requires_grad) ===================================== torch.Size([6, 3, 5, 5]) torch.Size([6]) True定義好了神經網路,讓我們來看一下如何呼叫這個神經網路獲取輸出,前面提到的,我們這邊需要的輸入資料是4維的,同時,在PyTorch里神經網路的輸入樣本作為示例,有了輸入資料之后,可以直接將其傳入神經網路得到輸出,實際上呼叫我們定義的net.forward()方法,可以看到,神經網路的輸出也是一個Variable,共有10維,和我們預期的一致,
input = Variable(torch.rand(1,3,32,32)) output = net(input) print(output) ================================================================================ tensor([[ 0.1417, 0.0634, -0.0652, -0.0445, 0.0899, 0.0334, 0.0029, -0.0582, 0.0845, 0.1239]], grad_fn=<AddmmBackward>)
3.2,訓練神經網路
要訓練神經網路,我們首先需要定義一個損失函式,我們訓練的目的就是通過調整神經網路模型的引數來最小化這個損失函式,1個損失函式輸入神經網路的預測輸出和樣本真實標簽,然后回傳1個值評測輸出距離真實標簽的遠近程度,在torch.nn包中,有很多定義好的損失函式,比如nn.MSELoss、nn.L1Loss、nn.CrossEntropyLoss等,因為我們是在訓練1個多分類模型,所以使用交叉熵損失函式nn.CrossEntropyLoss,
criterion = nn.CrossEntropyLoss()假設剛才隨機生成的按個輸入樣本input為例,假設它對應的真實標簽是4,而我們剛才已經得到了它通過神經網路之后的輸出output,那么我們就可以直接把它們輸入剛才選擇的損失函式計算得到loss,需要注意,損失函式的輸入outpur和label都要求是Variable,輸出loss也是一個Variable,
if __name__ == '__main__': net = Net() criterion = nn.CrossEntropyLoss() input = Variable(torch.rand(1, 3, 32, 32)) output = net(input) print(output) label = Variable(torch.LongTensor([4])) print(label) loss = criterion(output,label) print(loss) ================================================================================ tensor([[ 0.1201, 0.0682, 0.0639, 0.0945, -0.0587, 0.0728, 0.0730, 0.1388, -0.0845, 0.1373]], grad_fn=<AddmmBackward>) tensor([4]) tensor(2.4264, grad_fn=<NllLossBackward>)
在定義玩損失函式之后,我們還需要最小化這個損失函式是準備采用的優化方法,這時候我們需要用到torch.optim包,里面已經實作了各種常用的優化方法,比如SGD、Nesterov-SGD、Adam、RMSProp等,一般我們從中選擇就可以了,我們選擇帶動量的隨機梯度下降法,并將需要訓練的模型引數作為第一個引數傳入,同時設定學習速率引數lr=0.001,動量引數momentun=0.9,
import torch.optim as optim optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9)定義好損失函式和優化方法,我們就可以訓練更新神經網路的引數了,在更新之前,我們先挑一個引數看一下:
print(net.conv1.bias) ============================== Parameter containing: tensor([ 0.0416, -0.0456, -0.0261, 0.0349, -0.0015, -0.0484], requires_grad=True)引數訓練更新主要包含兩步,首先我們呼叫loss.backward()自動計算loss關于所有可訓練引數的梯度,然后執行optimizer.step(),根據上一步計算得到的梯度更新引數,需要注意,在呼叫backward()計算梯度之前,我們一般需要先呼叫optimizer.zero_grad()將所有引數的梯度置為0,因為backward()計算得到的梯度是積累到原有的梯度之上的,
if __name__ == '__main__': net = Net() print(net.conv1.bias) criterion = nn.CrossEntropyLoss() # 損失函式 input = Variable(torch.rand(1, 3, 32, 32)) output = net(input) print(output) label = Variable(torch.LongTensor([4])) loss = criterion(output, label) print(loss) optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) optimizer.zero_grad() loss.backward() #計算梯度 optimizer.step() print(net.conv1.bias) =========================================== Parameter containing: tensor([ 0.0580, 0.0789, 0.0258, -0.0612, -0.0216, 0.0890], requires_grad=True) tensor([[-0.0903, -0.0205, 0.0408, -0.0373, 0.0255, 0.0164, 0.1519, 0.1117, -0.1146, -0.0415]], grad_fn=<AddmmBackward>) tensor(2.2844, grad_fn=<NllLossBackward>) Parameter containing: tensor([ 0.0580, 0.0789, 0.0258, -0.0613, -0.0216, 0.0891], requires_grad=True)由于樣本集就一個樣本,并且沒有迭代回圈,故該變數極小,
3.3,在CIFAR-10資料集上進行訓練和測驗
首先我們需要獲取CIFAR-10資料集,并對資料進行必要的預處理,有一個torchvision包已經為我們收好了各種常用的影像資料集,比如:Imagenet、CIFAR-10、MNIST等,并提供了非常方便的加載和預處理的功能,
import torch.utils.data import torchvision import torchvision.transforms as transforms transform = transforms.Compose( [transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))] ) transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] ) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=0) # windows 下執行緒引數設為 0 安全 testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=0) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')我們來看幾張 CIFAR10 的圖片樣例, 分別是
frog、cat、deer、frog,32 X 32 的像素,看起來是有些模糊,import matplotlib.pyplot as plt import numpy as np # functions to show an image def imshow(img): img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # get some random training images dataiter = iter(trainloader) images, labels = dataiter.next() # show images imshow(torchvision.utils.make_grid(images)) # print labels print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

資料準備好之后,我們就可以開始真正的訓練了,我們會多次遍歷訓練資料集,每次取出一個mini-batch(設定為4)的資料,根據mini-batch的資料執行更新神經網路,
構建神經網路:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x定義損失函式及優化器:
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)訓練模型:
- 先通過
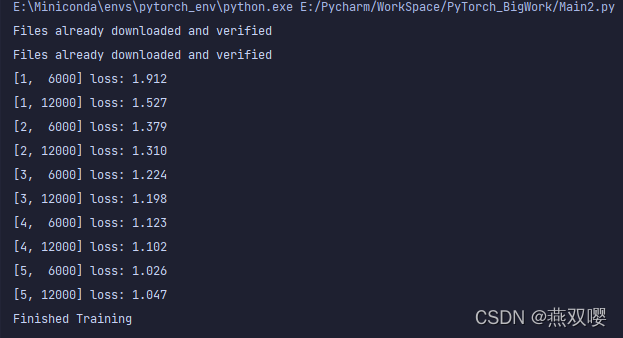
optimizer.zero_grad()把梯度清理干凈,防止受之前遺留梯度的影響,outputs = net(inputs), 把圖片資料送到網路里面,得到預測結果,loss = criterion(outputs, labels), 計算當前 batch 的損失值,loss.backward(),執行鏈式求導,計算梯度,optimizer.step(),通過4中計算出來的梯度,更新每個可訓練權重,net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) for epoch in range(5): running_loss = 0.0 for i, data in enumerate(trainloader, 0): inputs, labels = data inputs, labels = Variable(inputs), Variable(labels) optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 6000 == 5999: print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 6000)) running_loss = 0.0 print('Finished Training')
可以看到,隨著訓練程序的推進,損失函式在慢慢變小,說明神經網路的輸出在慢慢接近真實標簽,
模型驗證:我們在測驗集上看一下模型預測的準確率,在預測時,我們將模型輸出的10個值中最大的那個對應的類別作為模型的預測類別,
# 測驗模型 correct = 0 total = 0 for data in testloader: images, labels = data outputs = net(Variable(images)) # 回傳可能性最大的索引 -> 輸出標簽 _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum() print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) ============================================== Accuracy of the network on the 10000 test images: 62 %考慮到一共有10個類別,如果預測一個類別,準確期望在0.1,我們結果為62%,說明經過訓練的網路確實學到了一些東西,下面計算我們的神經網路在每個類別上的分類準確率:
class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) for data in testloader: images, labels = data outputs = net(Variable(images)) _, predicted = torch.max(outputs.data, 1) c = (predicted == labels).squeeze() for i in range(4): # mini-batch's size = 4 label = labels[i] class_correct[label] += c[i] class_total[label] += 1 for i in range(10): print('Accuracy of %5s : %2d %%' % ( classes[i], 100 * class_correct[i] / class_total[i] )) ========================================= Accuracy of plane : 69 % Accuracy of car : 66 % Accuracy of bird : 58 % Accuracy of cat : 35 % Accuracy of deer : 54 % Accuracy of dog : 56 % Accuracy of frog : 70 % Accuracy of horse : 73 % Accuracy of ship : 71 % Accuracy of truck : 67 %
3.4,模型的保存和加載
神經網路的訓練往往是比較耗時的,特別是在模型比較復雜、資料量比較大的時候,所以我們經常會希望將訓練好的模型保存到檔案供以后使用,這時我們可以呼叫網路的state_dict()方法,該方法會以字典的形式回傳模型的所有引數,字典的key是模型引數的名字,字典的value是存盤對應引數具體數值的Tensor,
print(net.state_dict().keys()) print(net.state_dict()['conv1.bias']) ============================================================================ odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias']) tensor([ 0.0970, -0.3732, -0.6456, -0.3526, 0.4653, -0.4466])接下來我們可以進一步使用torch.save()將state_dict()回傳的模型引數保存到檔案之后需要使用的時候,可以先用torch.load()從檔案中讀取模型引數,再用load_state_dict()方法將引數加載到神經網路模型中,
torch.save(net.state_dict(), './data/' + 'model.pt') net.load_state_dict(torch.load('./data/' + 'model.pt'))
3.5,代碼
import torch.utils.data import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch import torch.nn.functional as F import torch.nn as nn from torch.autograd import Variable import torch.optim as optim transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] ) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0) # windows 下執行緒引數設為 0 安全 testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=0) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 定義一個神經網路 self.conv1 = nn.Conv2d(3, 6, 5) # 兩個卷積層,三個全連接層 self.conv2 = nn.Conv2d(6, 16, 5) # 輸入3個通道,輸出6個通道,卷積核5*5 self.fc1 = nn.Linear(16 * 5 * 5, 120) # 輸入84維,輸出10維 self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) # 在init中我們值定義了搭建網路的層,但沒有真正定義網路的結構 # 真正的輸入輸出關系是在forward()方法中定義的,控制資料在網路中的流動方式 def forward(self, x): x = F.max_pool2d(F.relu(self.conv1(x)), 2) # 激活函式ReLU,先經過一個卷積層,然后一個全連接層 x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 訓練模型 # for epoch in range(5): # # running_loss = 0.0 # for i, data in enumerate(trainloader, 0): # inputs, labels = data # inputs, labels = Variable(inputs), Variable(labels) # optimizer.zero_grad() # outputs = net(inputs) # loss = criterion(outputs, labels) # loss.backward() # optimizer.step() # running_loss += loss.item() # if i % 6000 == 5999: # print('[%d, %5d] loss: %.3f' % # (epoch + 1, i + 1, running_loss / 6000)) # running_loss = 0.0 print('Finished Training') # 保存訓練好的模型 #torch.save(net.state_dict(), './data/' + 'model.pt') net.load_state_dict(torch.load('./data/' + 'model.pt')) print(net.state_dict().keys()) print(net.state_dict()['conv1.bias']) # 測驗模型 # correct = 0 # total = 0 # for data in testloader: # images, labels = data # outputs = net(Variable(images)) # # 回傳可能性最大的索引 -> 輸出標簽 # _, predicted = torch.max(outputs, 1) # total += labels.size(0) # correct += (predicted == labels).sum() # # print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total)) # class_correct = list(0. for i in range(10)) # class_total = list(0. for i in range(10)) # for data in testloader: # images, labels = data # outputs = net(Variable(images)) # _, predicted = torch.max(outputs.data, 1) # c = (predicted == labels).squeeze() # for i in range(4): # mini-batch's size = 4 # label = labels[i] # class_correct[label] += c[i] # class_total[label] += 1 # # for i in range(10): # print('Accuracy of %5s : %2d %%' % ( # classes[i], 100 * class_correct[i] / class_total[i] # ))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400442.html
標籤:AI