引言
? T r a n s f o r m e r \mathrm{Transformer} Transformer模型是 G o o g l e \mathrm{Google} Google團隊在 2017 2017 2017年 6 6 6月由 A s h i s h V a s w a n i \mathrm{Ashish\text{ }Vaswani} Ashish Vaswani等人在論文《 A t t e n t i o n I s A l l Y o u N e e d \mathrm{Attention\text{ }Is\text{ }All \text{ }You \text{ } Need} Attention Is All You Need》所提出,當前它已經成為 N L P \mathrm{NLP} NLP領域中的首選模型, T r a n s f o r m e r \mathrm{Transformer} Transformer拋棄了 R N N \mathrm{RNN} RNN的順序結構,采用了 S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention機制,使得模型可以并行化訓練,而且能夠充分利用訓練資料的全域資訊,加入 T r a n s f o r m e r \mathrm{Transformer} Transformer的 S e q 2 s e q \mathrm{Seq2seq} Seq2seq模型在 N L P \mathrm{NLP} NLP的各個任務上都有了顯著的提升,本文做了大量的圖示目的是能夠更加清晰地講解 T r a n s f o r m e r \mathrm{Transformer} Transformer的運行原理,以及相關組件的操作細節,文末還有完整可運行的代碼示例,
注意力機制
? T r a n s f o r m e r \mathrm{Transformer} Transformer中的核心機制就是 S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention, S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention機制的本質來自于人類視覺注意力機制,當人視覺在感知東西時候往往會更加關注某個場景中顯著性的物體,為了合理利用有限的視覺資訊處理資源,人需要選擇視覺區域中的特定部分,然后集中關注它,注意力機制主要目的就是對輸入進行注意力權重的分配,即決定需要關注輸入的哪部分,并對其分配有限的資訊處理資源給重要的部分,
Self-Attention
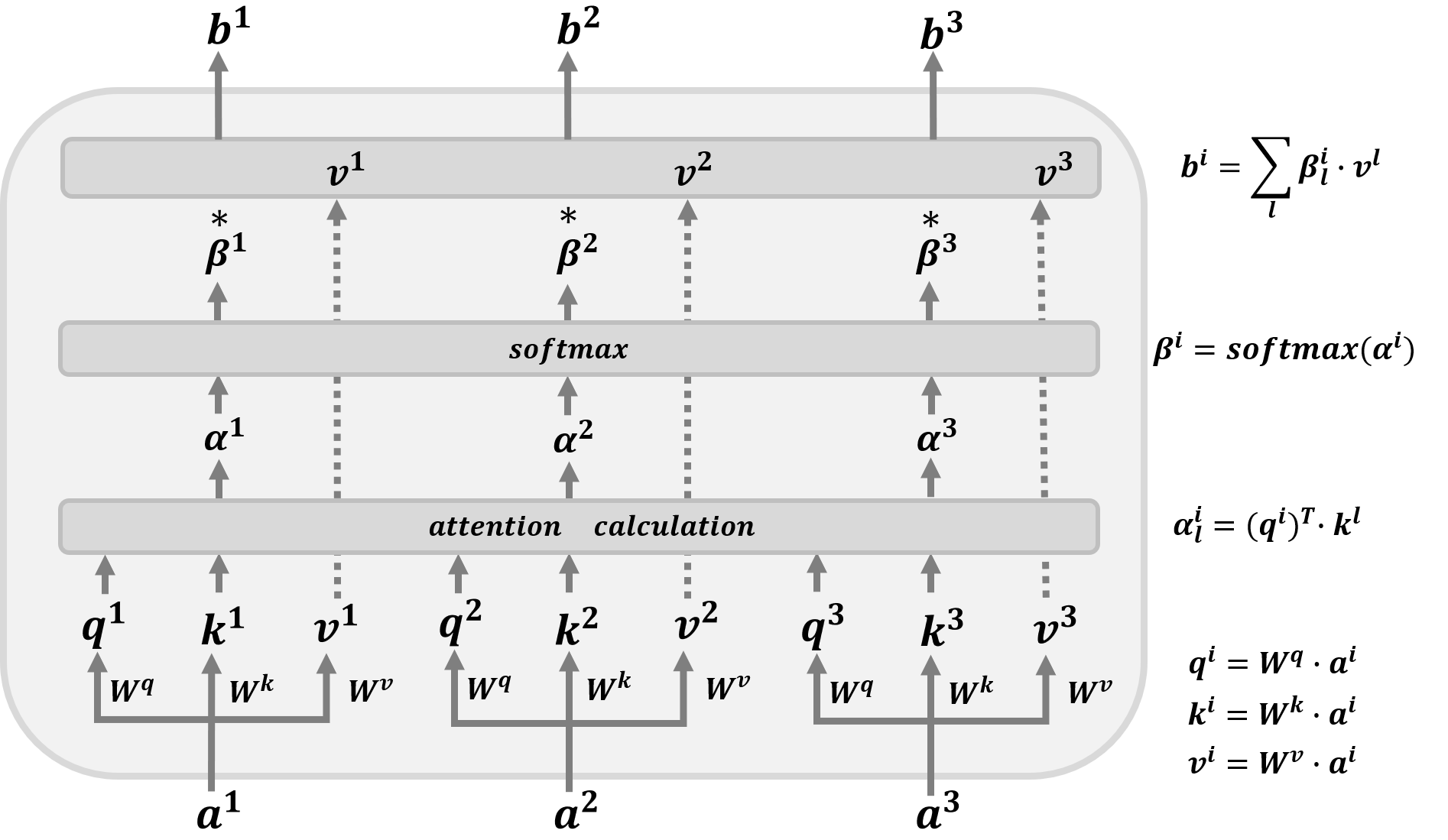
? S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention作業原理如上圖所示,給定輸入 w o r d e m b e d d i n g \mathrm{word\text{ }embedding} word embedding向量 a 1 , a 2 , a 3 ∈ R d l × 1 a^1,a^2,a^3 \in \mathbb{R}^{d_l \times 1} a1,a2,a3∈Rdl?×1,然后對于輸入向量 a i , i ∈ { 1 , 2 , 3 } a^i,i\in \{1,2,3\} ai,i∈{1,2,3}通過矩陣 W q ∈ R d k × d l , W k ∈ R d k × d l , W v ∈ R d l × d l W^q\in \mathbb{R}^{d_k \times d_l},W^k\in \mathbb{R}^{d_k \times d_l},W^v\in \mathbb{R}^{d_l\times d_l} Wq∈Rdk?×dl?,Wk∈Rdk?×dl?,Wv∈Rdl?×dl?進行線性變換得到 Q u e r y \mathrm{Query} Query向量 q i ∈ R d k × 1 q^i\in\mathbb{R}^{d_k \times 1} qi∈Rdk?×1, K e y \mathrm{Key} Key向量 k i ∈ R d k × 1 k^i\in \mathbb{R}^{d_k \times 1} ki∈Rdk?×1,以及 V a l u e \mathrm{Value} Value向量 v i ∈ R d l × 1 v^i\in \mathbb{R}^{d_l \times 1} vi∈Rdl?×1,即 { q i = W q ? a i k i = W k ? a i , i ∈ { 1 , 2 , 3 } v i = W v ? a i \left\{\begin{aligned}q^i&=W^q \cdot a^i\\k^i&=W^k \cdot a^i,\quad i\in\{1,2,3\}\\v^i&=W^v \cdot a^i\end{aligned}\right. ??????qikivi?=Wq?ai=Wk?ai,i∈{1,2,3}=Wv?ai?如果令矩陣 A = ( a 1 , a 2 , a 3 ) ∈ R d l × 3 A=(a^1,a^2,a^3)\in\mathbb{R}^{d_l \times 3} A=(a1,a2,a3)∈Rdl?×3, Q = ( q 1 , q 2 , q 3 ) ∈ R d k × 3 Q=(q^1,q^2,q^3)\in\mathbb{R}^{d_k \times 3} Q=(q1,q2,q3)∈Rdk?×3, K = ( k 1 , k 2 , k 3 ) ∈ R d k × 3 K=(k^1,k^2,k^3)\in\mathbb{R}^{d_k \times 3} K=(k1,k2,k3)∈Rdk?×3, V = ( v 1 , v 2 , v 3 ) ∈ R d l × 3 V=(v^1,v^2,v^3)\in\mathbb{R}^{d_l \times 3} V=(v1,v2,v3)∈Rdl?×3,則此時則有 { Q = W q ? A K = W k ? A V = W v ? A \left\{\begin{aligned}Q&=W^q \cdot A\\K&=W^k \cdot A\\V&=W^v \cdot A\end{aligned}\right. ??????QKV?=Wq?A=Wk?A=Wv?A?接著再利用得到的 Q u e r y \mathrm{Query} Query向量和 K e y \mathrm{Key} Key向量計算注意力得分,論文中采用的注意力計算公式為點積縮放公式 α l i = ( q i ) ? ? k l d k = d k d k ∑ n = 1 d k k n l ? q n i , i , l ∈ { 1 , 2 , 3 } \alpha^{i}_l=\frac{(q^i)^{\top}\cdot k^l}{\sqrt{d^k}}=\frac{\sqrt{d^k}}{d^k}\sum\limits_{n=1}^{d^k}k^l_n\cdot q^i_n,\quad i,l \in \{1,2,3\} αli?=dk ?(qi)??kl?=dkdk ??n=1∑dk?knl??qni?,i,l∈{1,2,3}論文中假定 K e y \mathrm{Key} Key向量 k l = ( k 1 l , k 2 l , k 3 l ) k^l=(k^l_1,k^l_2,k^l_3) kl=(k1l?,k2l?,k3l?)的元素和 Q u e r y \mathrm{Query} Query向量 q i = ( q 1 i , q 2 i , q 3 i ) q^i=(q^i_1,q^i_2,q^i_3) qi=(q1i?,q2i?,q3i?)的元素獨立同分布,且令均值為 0 0 0,方差為 1 1 1,則此時注意力向量 a i ∈ R 3 × 1 a^{i}\in \mathbb{R}^{3 \times 1} ai∈R3×1的第 l l l個分量 α l i \alpha^{i}_l αli?的均值為 0 0 0,方差 1 1 1具體的計算公式如下 E [ α l i ] = d k d k ∑ n = 1 d k E [ k n l ] ? E [ q n i ] = 0 , i , l ∈ { 1 , 2 , 3 } V a r [ α l i ] = 1 d k ∑ n = 1 d k V a r [ k n l ] ? V a r [ q n i ] = 1 , i , l ∈ { 1 , 2 , 3 } \begin{aligned}\mathbb{E}\left[\alpha^i_l\right]&=\frac{\sqrt{d^k}}{d^k}\sum\limits_{n=1}^{d^k}\mathbb{E}\left[k^l_n\right]\cdot \mathbb{E}\left[q^i_n\right]=0,\quad i,l \in \{1,2,3\}\\ \mathrm{Var}\left[\alpha^i_l\right]&=\frac{1}{d^k}\sum\limits_{n=1}^{d^k}\mathrm{Var}\left[k^l_n\right]\cdot \mathrm{Var}\left[q^i_n\right]=1,\quad i,l \in \{1,2,3\}\end{aligned} E[αli?]Var[αli?]?=dkdk ??n=1∑dk?E[knl?]?E[qni?]=0,i,l∈{1,2,3}=dk1?n=1∑dk?Var[knl?]?Var[qni?]=1,i,l∈{1,2,3}?令注意力分數矩陣 Λ = ( α 1 , α 2 , α 3 ) ∈ R 3 × 3 \Lambda=(\alpha^1,\alpha^2,\alpha^3)\in \mathbb{R}^{3 \times 3} Λ=(α1,α2,α3)∈R3×3,則有 Λ = K ? ? Q d k \Lambda=\frac{K^{\top}\cdot Q}{\sqrt{d^k}} Λ=dk ?K??Q?注意分數向量 α i \alpha^i αi經過 s o f t m a x \mathrm{softmax} softmax層得到歸一化后的注意力分布 β i \beta^i βi,即為 β j i = e α j i ∑ n = 1 3 e α n i , i , j = { 1 , 2 , 3 } \beta^i_j = \frac{e^{\alpha^{i}_j}}{\sum\limits_{n=1}^3e^{\alpha^{i}_n}},\quad i,j=\{1,2,3\} βji?=n=1∑3?eαni?eαji??,i,j={1,2,3}最后利用得到的注意力分布向量 β i \beta^i βi和 V a l u e \mathrm{Value} Value矩陣 V V V獲得最后的輸出 b i ∈ R d l × 1 b^i\in \mathbb{R}^{d_l \times 1} bi∈Rdl?×1,則有 b i = ∑ l = 1 3 β l i ? v l , i ∈ { 1 , 2 , 3 } b^i=\sum\limits^{3}_{l=1}\beta^{i}_l \cdot v^{l},\quad i \in \{1,2,3\} bi=l=1∑3?βli??vl,i∈{1,2,3}令輸出矩陣 B = ( b 1 , b 2 , b 3 ) ∈ R d l × 3 B=(b^1,b^2,b^3)\in\mathbb{R}^{d_l\times 3} B=(b1,b2,b3)∈Rdl?×3,則有 B = A t t e n t i o n ( Q , K , V ) = V ? s o f t m a x ( K ? ? Q d k ) B=\mathrm{Attention}(Q,K,V)=V\cdot\mathrm{softmax}\left(\frac{K^{\top}\cdot Q}{\sqrt{d^k}}\right) B=Attention(Q,K,V)=V?softmax(dk ?K??Q?)
Multi-Head Attention
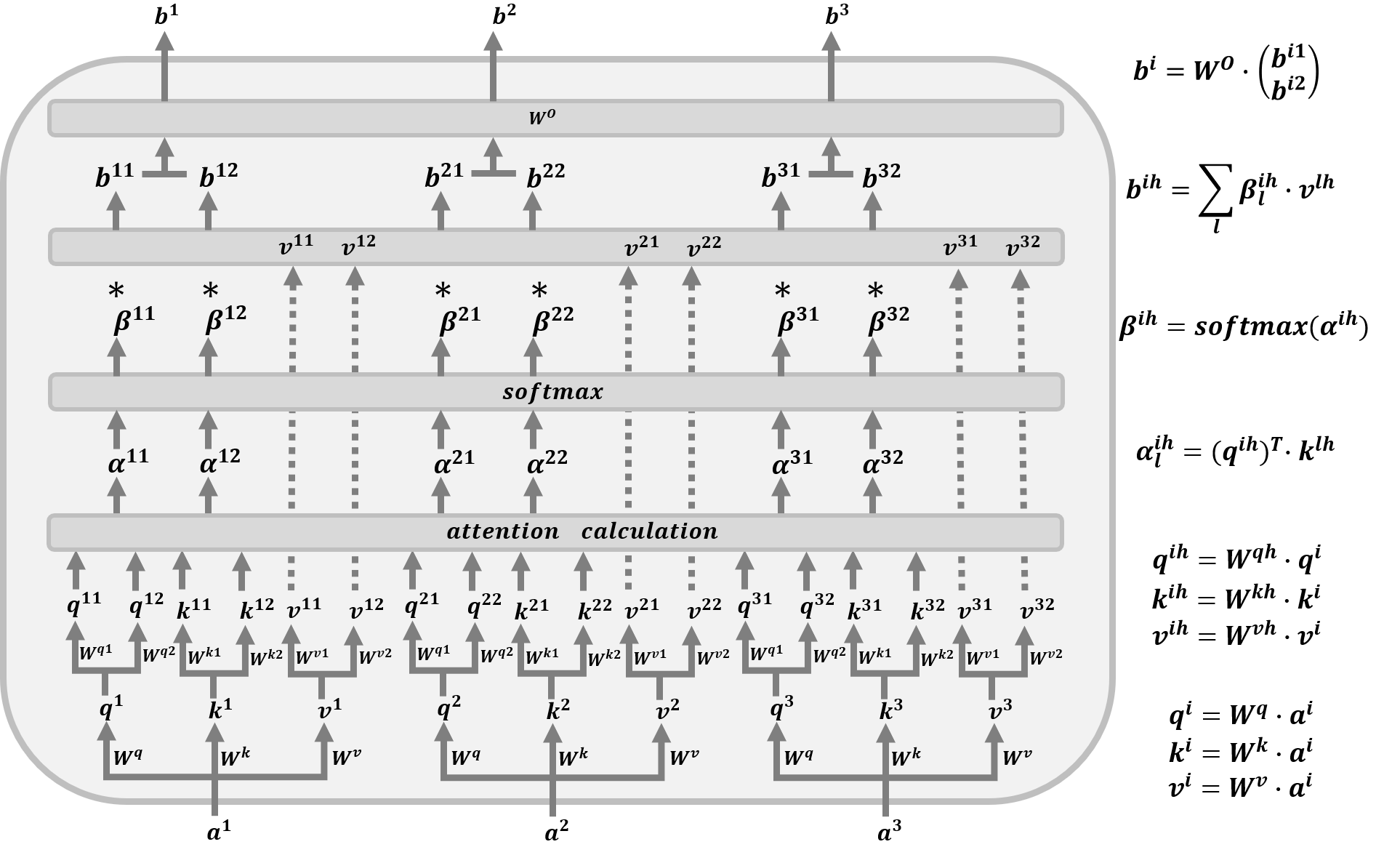
? M u l t i \mathrm{Multi} Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention的作業原理與 S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention的作業原理非常類似,為了方便圖解可視化將 M u l t i \mathrm{Multi} Multi- H e a d \mathrm{Head} Head設定為 2 2 2- H e a d \mathrm{Head} Head,如果 M u l t i \mathrm{Multi} Multi- H e a d \mathrm{Head} Head設定為 8 8 8- H e a d \mathrm{Head} Head,則上圖的 q i , k i , v i , i ∈ { 1 , 2 , 3 } q^i,k^i,v^i,i\in\{1,2,3\} qi,ki,vi,i∈{1,2,3}的下一步的分支數為 8 8 8,給定輸入 w o r d e m b e d d i n g \mathrm{word\text{ }embedding} word embedding向量 a 1 , a 2 , a 3 ∈ R d l × 1 a^1,a^2,a^3 \in \mathbb{R}^{d_l \times 1} a1,a2,a3∈Rdl?×1,然后對于輸入向量 a i , i ∈ { 1 , 2 , 3 } a^i,i\in \{1,2,3\} ai,i∈{1,2,3}通過矩陣 W q ∈ R d k × d l , W k ∈ R d k × d l , W v ∈ R d l × d l W^q\in \mathbb{R}^{d_k \times d_l},W^k\in \mathbb{R}^{d_k \times d_l},W^v\in \mathbb{R}^{d_l\times d_l} Wq∈Rdk?×dl?,Wk∈Rdk?×dl?,Wv∈Rdl?×dl?進行第一次線性變換得到 Q u e r y \mathrm{Query} Query向量 q i ∈ R d k × 1 q^i\in\mathbb{R}^{d_k \times 1} qi∈Rdk?×1, K e y \mathrm{Key} Key向量 k i ∈ R d k × 1 k^i \in\mathbb{R}^{d_k \times 1} ki∈Rdk?×1,以及 V a l u e \mathrm{Value} Value向量 v i ∈ R d l × 1 v^i \in\mathbb{R}^{d_l \times 1} vi∈Rdl?×1,然后再對 Q u e r y \mathrm{Query} Query向量 q i q^i qi通過矩陣 W q 1 ∈ R d m × d k W^{q1}\in \mathbb{R}^{d_m \times d_k} Wq1∈Rdm?×dk?和 W q 2 ∈ R d m × d k W^{q2}\in \mathbb{R}^{d_m\times d_k} Wq2∈Rdm?×dk?進行第二次線性變換得到 q i 1 ∈ R d m × 1 q^{i1}\in \mathbb{R}^{d_m \times 1} qi1∈Rdm?×1和 q i 2 ∈ R d m × 1 q^{i2}\in \mathbb{R}^{d_m\times 1} qi2∈Rdm?×1,同理對 K e y \mathrm{Key} Key向量 k i k^i ki通過矩陣 W k 1 ∈ R d m × d k W^{k1}\in \mathbb{R}^{d_m \times d_k} Wk1∈Rdm?×dk?和 W k 2 ∈ R d m × d k W^{k2}\in \mathbb{R}^{d_m\times d_k} Wk2∈Rdm?×dk?進行第二次線性變換得到 k i 1 ∈ R d m × 1 k^{i1}\in \mathbb{R}^{d_m\times 1} ki1∈Rdm?×1和 k i 2 ∈ R d m × 1 k^{i2}\in \mathbb{R}^{d_m\times 1} ki2∈Rdm?×1,對 V a l u e \mathrm{Value} Value向量 v i v^i vi通過矩陣 W v 1 ∈ R d l 2 × d l W^{v1}\in \mathbb{R}^{\frac{d_l}{2}\times d_l} Wv1∈R2dl??×dl?和 W v 2 ∈ R d l 2 × d l W^{v2}\in \mathbb{R}^{\frac{d_l}{2}\times d_l} Wv2∈R2dl??×dl?進行第二次線性變換得到 v i 1 ∈ R d l 2 × 1 v^{i1}\in \mathbb{R}^{\frac{d_l}{2}\times 1} vi1∈R2dl??×1和 v i 2 ∈ R d l 2 × 1 v^{i2}\in \mathbb{R}^{\frac{d_l}{2}\times 1} vi2∈R2dl??×1,具體的計算公式如下所示: { q i h = W q h ? W q ? a i k i h = W k h ? W k ? a i , i = { 1 , 2 , 3 } , h = { 1 , 2 } v i h = W v h ? W v ? a i \left\{\begin{aligned}q^{ih}&=W^{qh}\cdot W^{q} \cdot a^i\\ k^{ih}&=W^{kh}\cdot W^{k} \cdot a^i,\quad i=\{1,2,3\},\quad h=\{1,2\}\\v^{ih}&=W^{vh}\cdot W^{v} \cdot a^i\end{aligned}\right. ????????qihkihvih?=Wqh?Wq?ai=Wkh?Wk?ai,i={1,2,3},h={1,2}=Wvh?Wv?ai?令矩陣 Q 1 = ( q 11 , q 21 , q 31 ) ∈ R d m × 3 Q 2 = ( q 12 , q 22 , q 32 ) ∈ R d m × 3 K 1 = ( k 11 , k 21 , k 31 ) ∈ R d m × 3 K 2 = ( k 12 , k 22 , k 32 ) ∈ R d m × 3 V 1 = ( v 11 , v 21 , v 31 ) ∈ R d l 2 × 3 V 2 = ( v 12 , v 22 , v 32 ) ∈ R d l 2 × 3 \begin{array}{ll}Q^{1}=(q^{11},q^{21},q^{31})\in \mathbb{R}^{d_m\times 3}&\quad Q^2=(q^{12},q^{22},q^{32})\in\mathbb{R}^{d_m\times 3}\\K^{1}=(k^{11},k^{21},k^{31})\in \mathbb{R}^{d_m\times 3}&\quad K^2=(k^{12},k^{22},k^{32})\in\mathbb{R}^{d_m\times 3}\\V^{1}=(v^{11},v^{21},v^{31})\in \mathbb{R}^{\frac{d_l}{2}\times 3}&\quad V^2=(v^{12},v^{22},v^{32})\in\mathbb{R}^{\frac{d_l}{2}\times 3}\end{array} Q1=(q11,q21,q31)∈Rdm?×3K1=(k11,k21,k31)∈Rdm?×3V1=(v11,v21,v31)∈R2dl??×3?Q2=(q12,q22,q32)∈Rdm?×3K2=(k12,k22,k32)∈Rdm?×3V2=(v12,v22,v32)∈R2dl??×3?此時則有 Q 1 = W q 1 ? W q ? A Q 2 = W q 2 ? W q ? A K 1 = W k 1 ? W k ? A K 2 = W k 2 ? W k ? A V 1 = W v 1 ? W v ? A V 2 = W v 2 ? W v ? A \begin{array}{ll}Q^{1}=W^{q1}\cdot W^{q} \cdot A &\quad Q^2=W^{q2}\cdot W^{q} \cdot A\\K^{1}=W^{k1}\cdot W^{k} \cdot A&\quad K^2=W^{k2}\cdot W^{k} \cdot A\\V^{1}=W^{v1}\cdot W^{v} \cdot A&\quad V^2=W^{v2}\cdot W^{v} \cdot A\end{array} Q1=Wq1?Wq?AK1=Wk1?Wk?AV1=Wv1?Wv?A?Q2=Wq2?Wq?AK2=Wk2?Wk?AV2=Wv2?Wv?A?對于每個 H e a d \mathrm{Head} Head利用得到對于 Q u e r y \mathrm{Query} Query向量和 K e y \mathrm{Key} Key向量計算對應的注意力得分,其中注意力向量 α i h \alpha^{ih} αih的第 l l l個分量的計算公式為 α l i h = ( q i h ) ? ? k l h , i ∈ { 1 , 2 , 3 } , h ∈ { 1 , 2 } , l ∈ { 1 , 2 , 3 } \alpha^{ih}_l=(q^{ih})^{\top}\cdot k^{lh},\quad i\in\{1,2,3\},h\in\{1,2\},l\in\{1,2,3\} αlih?=(qih)??klh,i∈{1,2,3},h∈{1,2},l∈{1,2,3}令注意力分數矩陣 Λ 1 = ( α 11 , α 21 , α 31 ) \Lambda^1=(\alpha^{11},\alpha^{21},\alpha^{31}) Λ1=(α11,α21,α31), Λ 2 = ( α 12 , α 22 , α 32 ) \Lambda^2=(\alpha^{12},\alpha^{22},\alpha^{32}) Λ2=(α12,α22,α32),則有 Λ 1 = ( K 1 ) ? ? Q 1 d m , Λ 2 = ( K 2 ) ? ? Q 2 d m \Lambda^{1}=\frac{(K^1)^{\top}\cdot Q^1}{\sqrt{d_m}},\quad\Lambda^{2}=\frac{(K^2)^{\top}\cdot Q^2}{\sqrt{d_m}} Λ1=dm? ?(K1)??Q1?,Λ2=dm? ?(K2)??Q2?注意分數向量 α i h \alpha^{ih} αih經過 s o f t m a x \mathrm{softmax} softmax層得到歸一化后的注意力分布 β i h \beta^{ih} βih,即為 β j i h = e α j i h ∑ n = 1 3 e α n i h , i , j = { 1 , 2 , 3 } , h = { 1 , 2 } \beta^{ih}_j = \frac{e^{\alpha^{ih}_j}}{\sum\limits_{n=1}^3e^{\alpha^{ih}_n}},\quad i,j=\{1,2,3\}, h=\{1,2\} βjih?=n=1∑3?eαnih?eαjih??,i,j={1,2,3},h={1,2}對于每一個 H e a d \mathrm{Head} Head利用得到的注意力分布向量 β i h \beta^{ih} βih和 V a l u e \mathrm{Value} Value矩陣 V h V^h Vh獲得最后的輸出 b i h ∈ R d l 2 × 1 b^{ih}\in \mathbb{R}^{\frac{d_l}{2} \times 1} bih∈R2dl??×1,則有 b i h = ∑ l = 1 3 β l i h ? v l h , i ∈ { 1 , 2 , 3 } , h ∈ { 1 , 2 } b^{ih}=\sum\limits^{3}_{l=1}\beta^{ih}_l \cdot v^{lh},\quad i \in \{1,2,3\}, h\in\{1,2\} bih=l=1∑3?βlih??vlh,i∈{1,2,3},h∈{1,2}兩個 H e a d \mathrm{Head} Head的 b i h b^{ih} bih的向量按照如下方式拼接在一起,則有 B = ( b 11 b 21 b 31 b 12 b 22 b 32 ) ∈ R d l × 3 B=\left(\begin{array}{lll}b^{11}&b^{21}&b^{31}\\b^{12}&b^{22}&b^{32}\end{array}\right)\in \mathbb{R}^{d_l \times 3} B=(b11b12?b21b22?b31b32?)∈Rdl?×3給定引數矩陣 W O ∈ R d l × d l W^{O}\in \mathbb{R}^{d_l\times d_l} WO∈Rdl?×dl?,則輸出矩陣為 O = W O ? B ∈ R d l × 3 O=W^{O}\cdot B\in \mathbb{R}^{d_l \times 3} O=WO?B∈Rdl?×3綜上所述則有 O = M u l t i H e a d ( Q , K , V ) = W O ? C o n c a t ( V 1 ? s o f t m a x ( ( K 1 ) ? ? Q 1 d m ) V 2 ? s o f t m a x ( ( K 2 ) ? ? Q 2 d m ) ) O=\mathrm{MultiHead}(Q,K,V)=W^O\cdot\mathrm{Concat}\left(\begin{array}{l}V^1\cdot\mathrm{softmax}\left(\frac{(K^1)^{\top}\cdot Q^1}{\sqrt{d_m}}\right)\\ \\V^2\cdot\mathrm{softmax}\left(\frac{(K^2)^{\top}\cdot Q^2}{\sqrt{d_m}}\right)\end{array}\right) O=MultiHead(Q,K,V)=WO?Concat?????V1?softmax(dm? ?(K1)??Q1?)V2?softmax(dm? ?(K2)??Q2?)??????
Mask Self-Attention
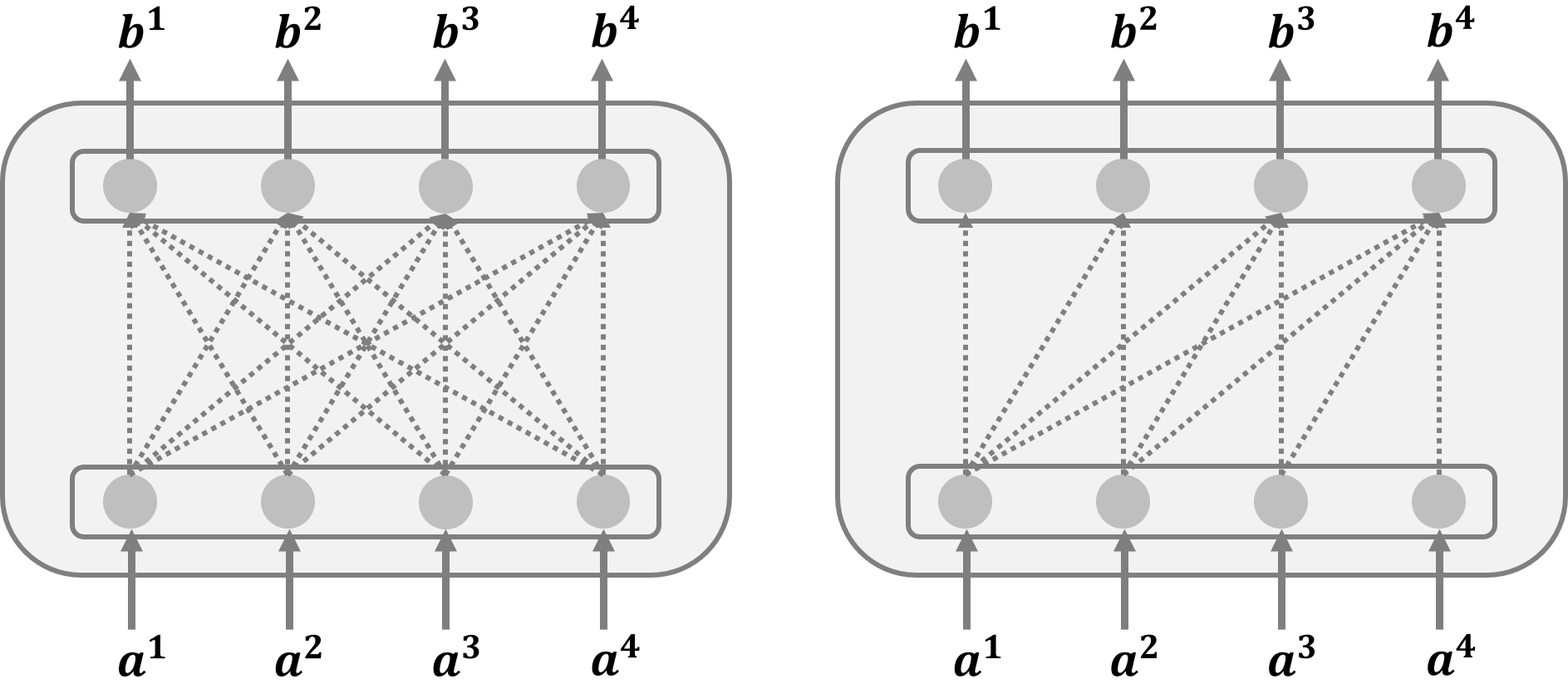
? 如下圖左半部分所示, S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention的輸出向量 b i , i ∈ { 1 , 2 , 3 , 4 } b^i, i \in \{1,2,3,4\} bi,i∈{1,2,3,4}綜合了輸入向量 a i , i ∈ { 1 , 2 , 3 , 4 } a^i, i \in \{1,2,3,4\} ai,i∈{1,2,3,4}的全部資訊,由此可見, S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention在實際編程中支持并行運算,如下圖右半部分所示, M a s k S e l f \mathrm{Mask \text{ } Self} Mask Self- A t t e n t i o n \mathrm{Attention} Attention的輸出向量 b i b^i bi只利用了已知部分輸入的向量 a i a^i ai的資訊,例如, b 1 b1 b1只是與 a 1 a^1 a1有關; b 2 b^2 b2與 a 1 a^1 a1和 a 2 a^2 a2有關; b 3 b^3 b3與 a 1 a^1 a1, a 2 a^2 a2和 a 3 a^3 a3有關; b 4 b^4 b4與 a 1 a^1 a1, a 2 a^2 a2, a 3 a^3 a3和 a 4 a^4 a4有關, M a s k S e l f \mathrm{Mask \text{ } Self} Mask Self- A t t e n t i o n \mathrm{Attention} Attention在 T r a n s f o r m e r \mathrm{Transformer} Transformer中被用到過兩次,
- T r a n s f o r m e r \mathrm{Transformer} Transformer的 E n c o d e r \mathrm{Encoder} Encoder中如果輸入一句話的 w o r d \mathrm{word} word長度小于指定的長度,為了能夠讓長度一致往往會用 0 0 0進行填充,此時則需要用 M a s k S e l f \mathrm{Mask \text{ } Self} Mask Self- A t t e n t i o n \mathrm{Attention} Attention來計算注意力分布,
- T r a n s f o r m e r \mathrm{Transformer} Transformer的 D e c o d e r \mathrm{Decoder} Decoder的輸出是有時序關系的,當前的輸出只與之前的輸入有關,所以此時算注意力分布時需要用到 M a s k S e l f \mathrm{Mask \text{ } Self} Mask Self- A t t e n t i o n \mathrm{Attention} Attention,
Transformer模型
?以上對
T
r
a
n
s
f
o
r
m
e
r
\mathrm{Transformer}
Transformer中的核心內容即自注意力機制進行了詳細解剖,接下來會對
T
r
a
n
s
f
o
r
m
e
r
\mathrm{Transformer}
Transformer模型架構進行介紹,
T
r
a
n
s
f
o
r
m
e
r
\mathrm{Transformer}
Transformer模型是由
E
n
c
o
d
e
r
\mathrm{Encoder}
Encoder和
D
e
c
o
d
e
r
\mathrm{Decoder}
Decoder兩個模塊組成,具體的示意圖如下所示,為了能夠對
T
r
a
n
s
f
o
r
m
e
r
\mathrm{Transformer}
Transformer內部的操作細節進行更清晰的展示,下圖以矩陣運算的視角對
T
r
a
n
s
f
o
r
m
e
r
\mathrm{Transformer}
Transformer的原理進行講解,
?
E
n
c
o
d
e
r
\mathrm{Encoder}
Encoder模塊操作的具體流程如下所示:
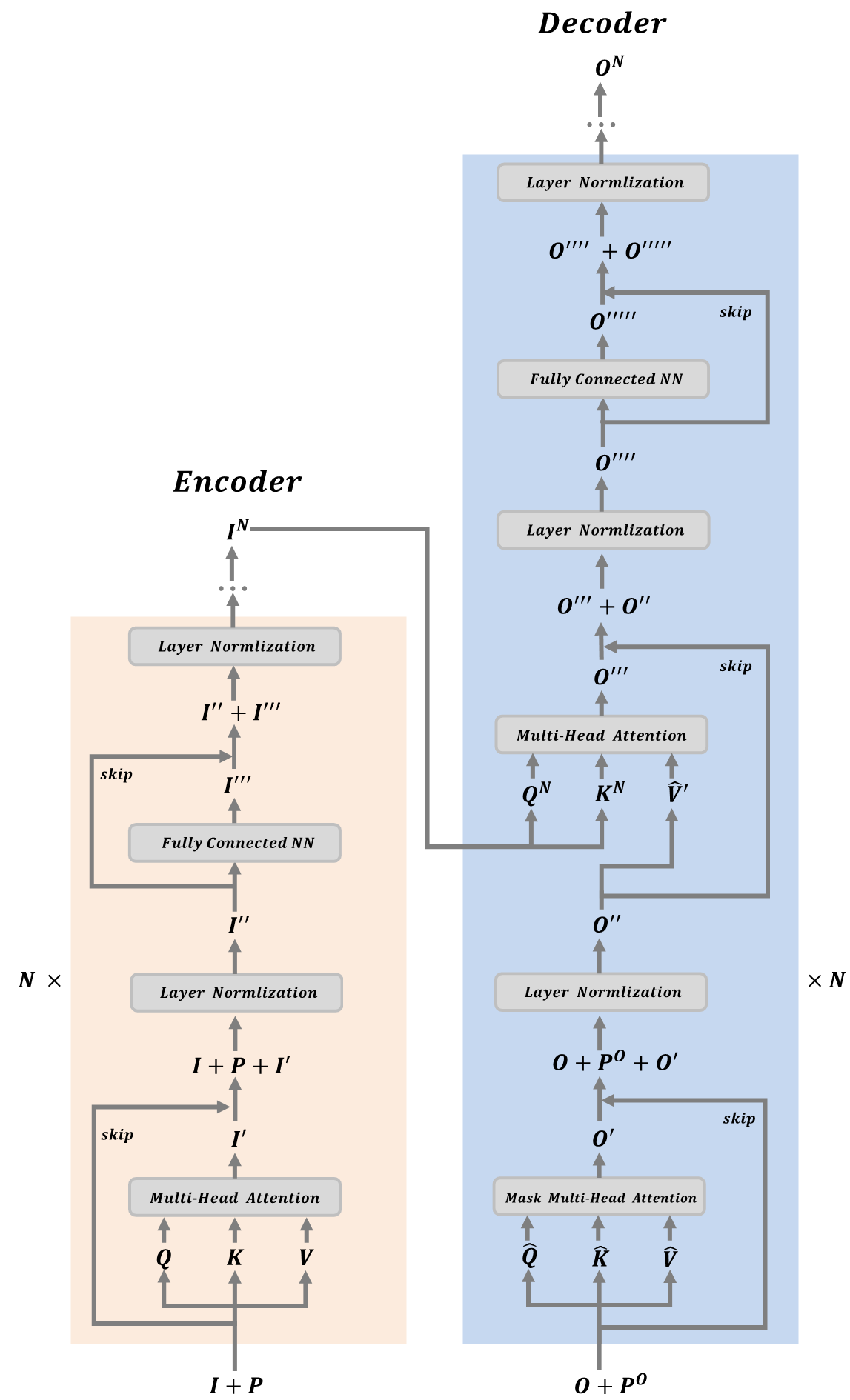
- E n c o d e r \mathrm{Encoder} Encoder的輸入由兩部分組成分別是詞編碼矩陣 I ∈ R n × l × d I \in \mathbb{R}^{n \times l \times d} I∈Rn×l×d和位置編碼矩陣 P ∈ R n × l × d P \in \mathbb{R}^{n \times l \times d} P∈Rn×l×d,其中 n n n表示句子數目, l l l表示一句話單詞的最大數目, d d d表示的是詞向量的維度,位置編碼矩陣 P P P表示的是每個單詞在一句里的所有位置資訊,因為 S e l f \mathrm{Self} Self- A t t e n t i o n \mathrm{Attention} Attention計算注意力分布的時候只能給出輸出向量和輸入向量之間的權重關系,但是不能給出詞在一句話里的位置資訊,所以需要在輸入里引入位置編碼矩陣 P P P,位置編碼向量生成方法有很多,一種比較簡單粗暴的方式就是根據單詞在句子中的位置生成一個 o n e \mathrm{one} one- h o t \mathrm{hot} hot的位置編碼;還有的方法是將位置編碼當成引數進行訓練學習;在該論文里是利用三角函式對位置進行編碼,具體的公式如下所示 P E ( p o s , 2 i ) = sin ? ( p o s 100 0 2 i / d ) , P E ( p o s , 2 i + 1 ) = cos ? ( p o s 100 0 2 i / d ) \mathrm{PE}(pos,2i)=\sin(\frac{pos}{1000^{2i/d}}),\quad \mathrm{PE}(pos,2i+1)=\cos(\frac{pos}{1000^{2i/d}}) PE(pos,2i)=sin(10002i/dpos?),PE(pos,2i+1)=cos(10002i/dpos?)其中 P E \mathrm{PE} PE表示的是位置編碼向量, p o s pos pos表示詞在句子中的位置, i i i表示編碼向量的位置索引,
- 輸入矩陣 I + P I+P I+P通過線性變換生成矩陣 Q Q Q, K K K, V V V,在實際編程中是將輸入 I + P I+P I+P直接賦值給 Q Q Q, K K K, V V V,如果輸入單詞長度小于最大長度并 0 0 0來填充的時候,還要相應引入 M a s k \mathrm{Mask} Mask矩陣,
- 將矩陣 Q Q Q, K K K, V V V輸入到 M u l t i \mathrm{Multi} Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention模塊中進行注意分布的計算得到矩陣 I ′ ∈ R n × l × d I^{\prime}\in \mathbb{R}^{n \times l \times d} I′∈Rn×l×d,計算公式為 I ′ = M u l t i H e a d ( Q , K , V ) I^{\prime}=\mathrm{MultiHead}(Q,K,V) I′=MultiHead(Q,K,V)具體的計算細節參考上文關于 M u l t i \mathrm{Multi} Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention原理的講解不在這里贅述,然后將原始輸入 I + P I+P I+P與注意力分布 I ′ I^{\prime} I′進行殘差計算得到輸出矩陣 I + P + I ′ ∈ R n × l × d I+P+I^{\prime}\in \mathbb{R}^{n \times l \times d} I+P+I′∈Rn×l×d,
- 對矩陣 I + P + I ′ = { x i j k } n l d I+P+I^{\prime}=\{x_{ijk}\}^{nld} I+P+I′={xijk?}nld進行層歸一化操作得到 I ′ ′ ∈ R n × l × d I^{\prime\prime}\in\mathbb{R}^{n \times l \times d} I′′∈Rn×l×d,具體的計算公式為 { μ i j = ∑ k = 1 d x i j k σ i j = ∑ k = 1 d ( x i j k ? μ i j ) 2 ? x ^ i j k = x i j k ? u i j σ i j , i ∈ { 1 , ? ? , n } , j ∈ { 1 , ? ? , l } , k ∈ { 1 , ? ? , d } \left\{\begin{aligned}\mu^{ij}&=\sum\limits_{k=1}^d x_{ijk}\\\sigma^{ij}&=\sqrt{\sum\limits_{k=1}^d\left(x_{ijk}-\mu^{ij}\right)^2}\end{aligned}\right. \Longrightarrow \hat{x}_{ijk}=\frac{x_{ijk}-u^{ij}}{\sigma^{ij}},\quad i\in\{1,\cdots,n\},j\in\{1,\cdots,l\},k\in\{1,\cdots,d\} ????????????????μijσij?=k=1∑d?xijk?=k=1∑d?(xijk??μij)2 ???x^ijk?=σijxijk??uij?,i∈{1,?,n},j∈{1,?,l},k∈{1,?,d}
- 將 I ′ ′ I^{\prime\prime} I′′輸入到全連接神經網路中得到 I ′ ′ ′ ∈ R n × l × d I^{\prime\prime\prime}\in \mathbb{R}^{n \times l \times d} I′′′∈Rn×l×d ,然后再讓全連接神經網路的輸入 I ′ ′ I^{\prime\prime} I′′與輸出 I ′ ′ ′ I^{\prime\prime\prime} I′′′進行殘差計算得到 I ′ ′ + I ′ ′ ′ I^{\prime\prime}+I^{\prime\prime\prime} I′′+I′′′,接著對 I ′ ′ + I ′ ′ ′ I^{\prime\prime}+I^{\prime\prime\prime} I′′+I′′′進行層歸一化操作,
- 以上是一個 B l o c k \mathrm{Block} Block的操作原理,將 N N N個 B l o c k \mathrm{Block} Block進行堆疊就組成了 E n c o d e r \mathrm{Encoder} Encoder的模塊,得到的最后輸出為 I N ∈ R n × l × d I^N \in \mathbb{R}^{n \times l \times d} IN∈Rn×l×d,這里需要注意的是 E n c o d e r \mathrm{Encoder} Encoder模塊中的各個組件的操作順序并不是固定的,也可以先進行歸一化操作,然后再計算注意力分布,再歸一化,再預測等,
? D e c o d e r \mathrm{Decoder} Decoder模塊操作的具體流程如下所示:
- D e c o d e r \mathrm{Decoder} Decoder的輸入也由兩部分組成分別是詞編碼矩陣 O ∈ R n 1 × l 1 × d O \in \mathbb{R}^{n_1 \times l_1 \times d} O∈Rn1?×l1?×d和位置編碼矩陣 P O ∈ R n 1 × l 1 × d P^O \in \mathbb{R}^{n_1 \times l_1 \times d} PO∈Rn1?×l1?×d,因為 D e c o d e r \mathrm{Decoder} Decoder的輸入是具有時順序關系的(即上一步的輸出為當前步輸入)所以還需要輸入 M a s k \mathrm{Mask} Mask矩陣 M M M以便計算注意力分布,
- 輸入矩陣 O + P O O+P^O O+PO通過線性變換生成矩陣 Q ^ \hat{Q} Q^?, K ^ \hat{K} K^, V ^ \hat{V} V^,在實際編程中是將輸入 O + P O O+P^O O+PO直接賦值給 Q ^ \hat{Q} Q^?, K ^ \hat{K} K^, V ^ \hat{V} V^,如果輸入單詞長度小于最大長度并 0 0 0來填充的時候,還要相應引入 M a s k \mathrm{Mask} Mask矩陣,
- 將矩陣 Q ^ \hat{Q} Q^?, K ^ \hat{K} K^, V ^ \hat{V} V^以及 M a s k \mathrm{Mask} Mask矩陣 M M M輸入到 M a s k M u l t i \mathrm{Mask\text{ }Multi} Mask Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention模塊中進行注意分布的計算得到矩陣 O ′ ∈ R n 1 × l 1 × d O^{\prime}\in \mathbb{R}^{n_1 \times l_1 \times d} O′∈Rn1?×l1?×d,計算公式為 O ′ = M a s k M u l t i H e a d ( Q ^ , K ^ , V ^ , M ) O^{\prime}=\mathrm{MaskMultiHead}(\hat{Q},\hat{K},\hat{V},M) O′=MaskMultiHead(Q^?,K^,V^,M)具體的計算細節參考上文關于 M a s k S e l f \mathrm{Mask \text{ }Self} Mask Self- A t t e n t i o n \mathrm{Attention} Attention的講解不在這里贅述,然后將原始輸入 O + P O O+P^O O+PO與注意力分布 O ′ O^{\prime} O′進行殘差計算得到輸出矩陣 O + P O + O ′ ∈ R n 1 × l 1 × d O+P^O+O^{\prime}\in \mathbb{R}^{n_1 \times l_1 \times d} O+PO+O′∈Rn1?×l1?×d,接著再對矩陣 O + P O + O ′ O+P^O+O^{\prime} O+PO+O′進行層歸一化操作得到 O ′ ′ ∈ R n 1 × l 1 × d O^{\prime\prime}\in\mathbb{R}^{n_1 \times l_1 \times d} O′′∈Rn1?×l1?×d,
- E n c o d e r \mathrm{Encoder} Encoder的輸出 I N I^N IN通過線性變換得到 Q N Q^N QN和 K N K^N KN, O ′ O^{\prime} O′進行線性變換得到 V ^ ′ \hat{V}^{\prime} V^′,利用矩陣 Q N Q^N QN和 K N K^N KN和 V ^ ′ \hat{V}^{\prime} V^′進行交叉注意力分布的計算得到 O ′ ′ ′ O^{\prime\prime\prime} O′′′,計算公式為 O ′ ′ ′ = M u l t i H e a d ( Q N , K N , V ^ ′ ) O^{\prime\prime\prime}=\mathrm{MultiHead}(Q^N,K^N,\hat{V}^{\prime}) O′′′=MultiHead(QN,KN,V^′)這里的交叉注意力分布綜合 E n c o d e r \mathrm{Encoder} Encoder輸出結果和 D e c o d e r \mathrm{Decoder} Decoder中間結果的資訊,實際編程編程中將 I N I^N IN直接賦值給 Q ^ \hat{Q} Q^?和 K ^ \hat{K} K^, O ′ O^{\prime} O′直接賦值給 V ^ ′ \hat{V}^{\prime} V^′,然后將 O ′ ′ O^{\prime\prime} O′′與注意力分布 O ′ ′ ′ O^{\prime\prime\prime} O′′′進行殘差計算得到輸出矩陣 O ′ ′ + O ′ ′ ′ O^{\prime\prime}+O^{\prime\prime\prime} O′′+O′′′,
- 接著對 O ′ ′ + O ′ ′ ′ O^{\prime\prime}+O^{\prime\prime\prime} O′′+O′′′進行層歸一操作得到 O ′ ′ ′ ′ O^{\prime\prime\prime\prime} O′′′′,再將 O ′ ′ ′ ′ O^{\prime\prime\prime\prime} O′′′′輸入到全連接神經網路中得到 O ′ ′ ′ ′ ′ O^{\prime\prime\prime\prime\prime} O′′′′′,接著再做一步殘差操作得到 O ′ ′ ′ ′ + O ′ ′ ′ ′ ′ O^{\prime\prime\prime\prime}+O^{\prime\prime\prime\prime\prime} O′′′′+O′′′′′,最后再進行一層歸一化操作,
- 以上是一個 B l o c k \mathrm{Block} Block的操作原理,將 N N N個 B l o c k \mathrm{Block} Block進行堆疊就組成了 D e c o d e r \mathrm{Decoder} Decoder的模塊,得到的輸出為 O N ∈ R n 1 × l 1 × d O^N \in \mathbb{R}^{n_1 \times l_1 \times d} ON∈Rn1?×l1?×d,然后在詞匯字典中找到當前預測最大概率的單詞,并將該單詞詞向量作為下一階段的輸入,重復以上步驟,直到輸出“ e n d \mathrm{end} end”字符為止,
代碼示例
? T r a n s f o r m e r \mathrm{Transformer} Transformer具體的代碼示例如下所示,根據上文中 M u l t i \mathrm{Multi} Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention原理示例圖可知,嚴格來看 M u l t i \mathrm{Multi} Multi- H e a d A t t e n t i o n \mathrm{Head\text{ }Attention} Head Attention在求注意分布的時候中間其實是有兩步線性變換,給定輸入向量 x ∈ R 256 × 1 x\in \mathbb{R}^{256\times 1} x∈R256×1 第一步線性變換直接讓向量 x x x賦值給 q q q, k k k, v v v,這一程序以下程式中有所體現,在這里并不會產生歧義,第二步線性變換產生多 H e a d \mathrm{Head} Head,假設 H e a d = 8 \mathrm{Head}=8 Head=8的時候,按理說 q q q要與 8 8 8個矩陣 W q 1 , ? ? , W q 8 W^{q1},\cdots,W^{q8} Wq1,?,Wq8進行線性變換得到 8 8 8個 q 1 , ? ? , q 8 q^{1},\cdots,q^{8} q1,?,q8,同理 k k k要與 8 8 8個矩陣 W k 1 , ? ? , W k 8 W^{k1},\cdots,W^{k8} Wk1,?,Wk8進行線性變換得到 8 8 8個 k 1 , ? ? , k 8 k^{1},\cdots,k^{8} k1,?,k8, v v v要與 8 8 8個矩陣 W v 1 , ? ? , W v 8 W^{v1},\cdots,W^{v8} Wv1,?,Wv8進行線性變換得到 8 8 8個 v 1 , ? ? , v 8 v^{1},\cdots,v^{8} v1,?,v8,如果按照這個方式在程式實作則需要定義24個權重矩陣,非常的麻煩,以下程式中有一個簡單的權重定義方法,通過該方法也可以實作以上多 H e a d \mathrm{Head} Head的線性變換,以向量 q = ( q 1 , ? ? , q 256 ) ? ∈ R 256 × 1 q = (q_1,\cdots, q_{256})^{\top}\in \mathbb{R}^{256 \times 1} q=(q1?,?,q256?)?∈R256×1為例:
- 首先將向量
q
q
q進行截斷分成
H
e
a
d
=
8
\mathrm{Head}=8
Head=8個向量,即為
{
q
(
1
)
=
(
E
,
0
,
0
,
0
,
0
,
0
,
0
,
0
)
?
q
q
(
2
)
=
(
0
,
E
,
0
,
0
,
0
,
0
,
0
,
0
)
?
q
q
(
3
)
=
(
0
,
0
,
E
,
0
,
0
,
0
,
0
,
0
)
?
q
q
(
4
)
=
(
0
,
0
,
0
,
E
,
0
,
0
,
0
,
0
)
?
q
q
(
5
)
=
(
0
,
0
,
0
,
0
,
E
,
0
,
0
,
0
)
?
q
q
(
6
)
=
(
0
,
0
,
0
,
0
,
0
,
E
,
0
,
0
)
?
q
q
(
7
)
=
(
0
,
0
,
0
,
0
,
0
,
0
,
E
,
0
)
?
q
q
(
8
)
=
(
0
,
0
,
0
,
0
,
0
,
0
,
0
,
E
)
?
q
\left\{\begin{aligned}q^{(1)}&=({\bf{E},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0}})\cdot q\\q^{(2)}&=({\bf{0},\bf{E},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0}})\cdot q\\q^{(3)}&=({\bf{0},\bf{0},\bf{E},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0}})\cdot q\\q^{(4)}&=({\bf{0},\bf{0},\bf{0},\bf{E},\bf{0},\bf{0},\bf{0},\bf{0}})\cdot q\\q^{(5)}&=({\bf{0},\bf{0},\bf{0},\bf{0},\bf{E},\bf{0},\bf{0},\bf{0}})\cdot q\\q^{(6)}&=({\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{E},\bf{0},\bf{0}})\cdot q\\q^{(7)}&=({\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{E},\bf{0}})\cdot q\\q^{(8)}&=({\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{0},\bf{E}})\cdot q \end{aligned}\right.
???????????
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400449.html標籤:AI
- 標籤雲
-
其他(157675) Python(38076) JavaScript(25376) Java(17977) C(15215) 區塊鏈(8255) C#(7972) AI(7469) 爪哇(7425) MySQL(7132) html(6777) 基礎類(6313) sql(6102) 熊猫(6058) PHP(5869) 数组(5741) R(5409) Linux(5327) 反应(5209) 腳本語言(PerlPython)(5129) 非技術區(4971) Android(4554) 数据框(4311) css(4259) 节点.js(4032) C語言(3288) json(3245) 列表(3129) 扑(3119) C++語言(3117) 安卓(2998) 打字稿(2995) VBA(2789) Java相關(2746) 疑難問題(2699) 细绳(2522) 單片機工控(2479) iOS(2429) ASP.NET(2402) MongoDB(2323) 麻木的(2285) 正则表达式(2254) 字典(2211) 循环(2198) 迅速(2185) 擅长(2169) 镖(2155) 功能(1967) .NET技术(1958) Web開發(1951) python-3.x(1918) HtmlCss(1915) 弹簧靴(1913) C++(1909) xml(1889) PostgreSQL(1872) .NETCore(1853) 谷歌表格(1846) Unity3D(1843) for循环(1842)
- 熱門瀏覽
-
-
如何從xshell上傳檔案到centos linux虛擬機里
如何從xshell上傳檔案到centos linux虛擬機里及:虛擬機CentOs下執行 yum -y install lrzsz命令,出現錯誤:鏡像無法找到軟體包 前言 一、安裝lrzsz步驟 二、上傳檔案 三、遇到的問題及解決方案 總結 前言 提示:其實很簡單,往虛擬機上安裝一個上傳檔案的工具 ......
uj5u.com 2020-09-10 02:00:47 more -
一、SQLMAP入門
一、SQLMAP入門 1、判斷是否存在注入 sqlmap.py -u 網址/id=1 id=1不可缺少。當注入點后面的引數大于兩個時。需要加雙引號, sqlmap.py -u "網址/id=1&uid=1" 2、判斷文本中的請求是否存在注入 從文本中加載http請求,SQLMAP可以從一個文本檔案中 ......
uj5u.com 2020-09-10 02:00:50 more -
Metasploit 簡單使用教程
metasploit 簡單使用教程 浩先生, 2020-08-28 16:18:25 分類專欄: kail 網路安全 linux 文章標簽: linux資訊安全 編輯 著作權 metasploit 使用教程 前言 一、Metasploit是什么? 二、準備作業 三、具體步驟 前言 Msfconsole ......
uj5u.com 2020-09-10 02:00:53 more -
游戲逆向之驅動層與用戶層通訊
驅動層代碼: #pragma once #include <ntifs.h> #define add_code CTL_CODE(FILE_DEVICE_UNKNOWN,0x800,METHOD_BUFFERED,FILE_ANY_ACCESS) /* 更多游戲逆向視頻www.yxfzedu.com ......
uj5u.com 2020-09-10 02:00:56 more -
北斗電力時鐘(北斗授時服務器)讓網路資料更精準
北斗電力時鐘(北斗授時服務器)讓網路資料更精準 北斗電力時鐘(北斗授時服務器)讓網路資料更精準 京準電子科技官微——ahjzsz 近幾年,資訊技術的得了快速發展,互聯網在逐漸普及,其在人們生活和生產中都得到了廣泛應用,并且取得了不錯的應用效果。計算機網路資訊在電力系統中的應用,一方面使電力系統的運行 ......
uj5u.com 2020-09-10 02:01:03 more -
【CTF】CTFHub 技能樹 彩蛋 writeup
?碎碎念 CTFHub:https://www.ctfhub.com/ 筆者入門CTF時時剛開始刷的是bugku的舊平臺,后來才有了CTFHub。 感覺不論是網頁UI設計,還是題目質量,賽事跟蹤,工具軟體都做得很不錯。 而且因為獨到的金幣制度的確讓人有一種想去刷題賺金幣的感覺。 個人還是非常喜歡這個 ......
uj5u.com 2020-09-10 02:04:05 more -
02windows基礎操作
我學到了一下幾點 Windows系統目錄結構與滲透的作用 常見Windows的服務詳解 Windows埠詳解 常用的Windows注冊表詳解 hacker DOS命令詳解(net user / type /md /rd/ dir /cd /net use copy、批處理 等) 利用dos命令制作 ......
uj5u.com 2020-09-10 02:04:18 more -
03.Linux基礎操作
我學到了以下幾點 01Linux系統介紹02系統安裝,密碼啊破解03Linux常用命令04LAMP 01LINUX windows: win03 8 12 16 19 配置不繁瑣 Linux:redhat,centos(紅帽社區版),Ubuntu server,suse unix:金融機構,證券,銀 ......
uj5u.com 2020-09-10 02:04:30 more
- 最新发布
-
-
2023年最新微信小程式抓包教程
01 開門見山 隔一個月發一篇文章,不過分。 首先回顧一下《微信系結手機號資料庫被脫庫事件》,我也是第一時間得知了這個訊息,然后跟蹤了整件事情的經過。下面是這起事件的相關截圖以及近日流出的一萬條資料樣本: 個人認為這件事也沒什么,還不如關注一下之前45億快遞資料查詢渠道疑似在近日復活的訊息。 訊息是 ......
uj5u.com 2023-04-20 08:48:24 more -
web3 產品介紹:metamask 錢包 使用最多的瀏覽器插件錢包
Metamask錢包是一種基于區塊鏈技術的數字貨幣錢包,它允許用戶在安全、便捷的環境下管理自己的加密資產。Metamask錢包是以太坊生態系統中最流行的錢包之一,它具有易于使用、安全性高和功能強大等優點。 本文將詳細介紹Metamask錢包的功能和使用方法。 一、 Metamask錢包的功能 數字資 ......
uj5u.com 2023-04-20 08:47:46 more -
vulnhub_Earth
前言 靶機地址->>>vulnhub_Earth 攻擊機ip:192.168.20.121 靶機ip:192.168.20.122 參考文章 https://www.cnblogs.com/Jing-X/archive/2022/04/03/16097695.html https://www.cnb ......
uj5u.com 2023-04-20 07:46:20 more -
從4k到42k,軟體測驗工程師的漲薪史,給我看哭了
清明節一過,盲猜大家已經無心上班,在數著日子準備過五一,但一想到銀行卡里的余額……瞬間心情就不美麗了。最近,2023年高校畢業生就業調查顯示,本科畢業月平均起薪為5825元。調查一出,便有很多同學表示自己又被平均了。看著這一資料,不免讓人想到前不久中國青年報的一項調查:近六成大學生認為畢業10年內會 ......
uj5u.com 2023-04-20 07:44:00 more -
最新版本 Stable Diffusion 開源 AI 繪畫工具之中文自動提詞篇
🎈 標簽生成器 由于輸入正向提示詞 prompt 和反向提示詞 negative prompt 都是使用英文,所以對學習母語的我們非常不友好 使用網址:https://tinygeeker.github.io/p/ai-prompt-generator 這個網址是為了讓大家在使用 AI 繪畫的時候 ......
uj5u.com 2023-04-20 07:43:36 more -
漫談前端自動化測驗演進之路及測驗工具分析
隨著前端技術的不斷發展和應用程式的日益復雜,前端自動化測驗也在不斷演進。隨著 Web 應用程式變得越來越復雜,自動化測驗的需求也越來越高。如今,自動化測驗已經成為 Web 應用程式開發程序中不可或缺的一部分,它們可以幫助開發人員更快地發現和修復錯誤,提高應用程式的性能和可靠性。 ......
uj5u.com 2023-04-20 07:43:16 more -
CANN開發實踐:4個DVPP記憶體問題的典型案例解讀
摘要:由于DVPP媒體資料處理功能對存放輸入、輸出資料的記憶體有更高的要求(例如,記憶體首地址128位元組對齊),因此需呼叫專用的記憶體申請介面,那么本期就分享幾個關于DVPP記憶體問題的典型案例,并給出原因分析及解決方法。 本文分享自華為云社區《FAQ_DVPP記憶體問題案例》,作者:昇騰CANN。 DVPP ......
uj5u.com 2023-04-20 07:43:03 more -
Halcon軟體安裝與界面簡介
1. 下載Halcon17版本到到本地 2. 雙擊安裝包后 3. 步驟如下 1.2 Halcon軟體安裝 界面分為四大塊 1. Halcon的五個助手 1) 影像采集助手:與相機連接,設定相機引數,采集影像 2) 標定助手:九點標定或是其它的標定,生成標定檔案及內參外參,可以將像素單位轉換為長度單位 ......
uj5u.com 2023-04-20 07:42:17 more -
在MacOS下使用Unity3D開發游戲
第一次發博客,先發一下我的游戲開發環境吧。 去年2月份買了一臺MacBookPro2021 M1pro(以下簡稱mbp),這一年來一直在用mbp開發游戲。我大致分享一下我的開發工具以及使用體驗。 1、Unity 官網鏈接: https://unity.cn/releases 我一般使用的Apple ......
uj5u.com 2023-04-20 07:40:19 more
-
- 友情鏈接