🚀 作者 :“大資料小禪”
🚀 **文章簡介 **:本篇文章屬于Spark系列文章,專欄將會記錄從spark基礎到進階的內容,,內容涉及到Spark的入門集群搭建,核心組件,RDD,算子的使用,底層原理,SparkCore,SparkSQL,SparkStreaming等,Spark專欄地址.歡迎小伙伴們訂閱💪
🚀 **文章原始碼獲取 **:與本文相關的安裝包,大資料交流群,小伙伴們可以關注文章底部的公眾號,點擊“聯系我”備注對應內容獲取,
🚀 歡迎小伙伴們 點贊👍、收藏?、留言💬
1.為什么會有Spark
在開始講Spark運行的整體架構之前,先來講講為什么會有Spark?這個框架被設計出來是要解決什么問題的?
Mapreduce是離線大資料處理時經常使用的一種計算模型,但是也有著較多的缺點,例如不適合互動式計算,不適合迭代計算,
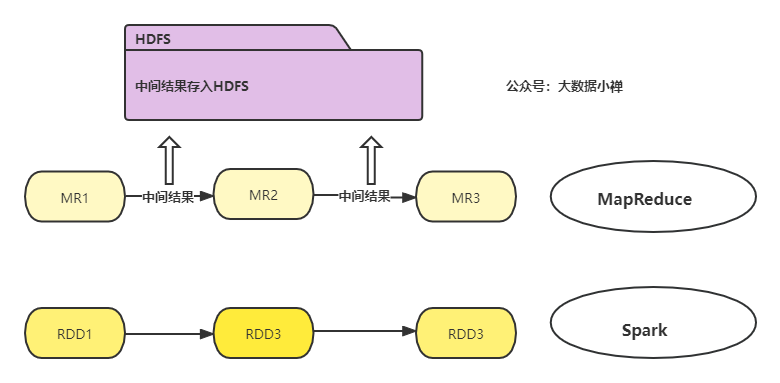
比如說,我們進行一個資料計算,流程如下圖,這個使用使用MapReduce的話,每個節點可能都要使用一個Map還有一個reduce去表示,那MR1跟MR2之間的結果要怎么傳遞?就要把結果放在HDFS分布式檔案中存盤,這樣的話帶來的問題就是耗時費記憶體,開銷大,
而spark在每個計算節點中是可以通過記憶體來傳遞結果的,而且提供了更好的上層API,相比之下Spark就具有了和明顯的優勢,Spark提供了多種算子做計算,支持多種語言,雖然spark本身沒有提供類似于HDFS的分布式檔案系統,但是他可以和hadoop生態的眾多框架整合,可以訪問多種資料庫,包括redis都可以整合,
2.Spark的運行架構以及流程
Spark運行的基本流程
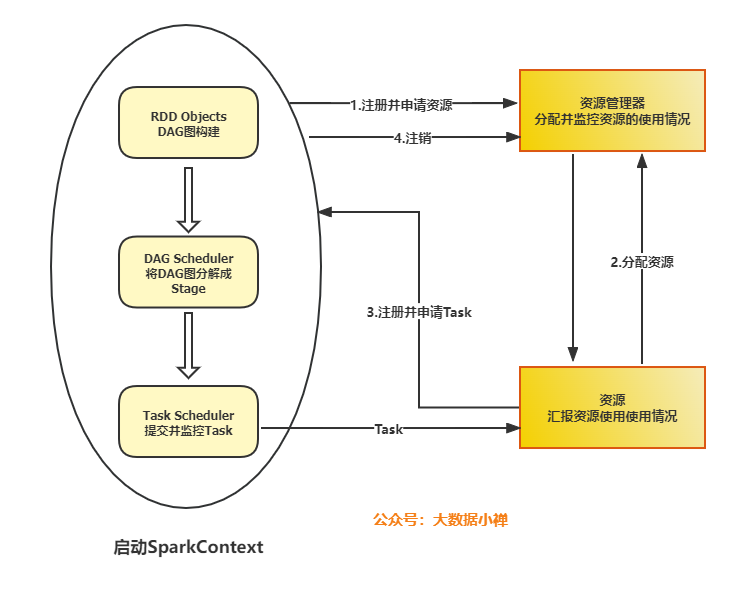
由上圖,spark在運行的時候一般有如下流程
- 由Driver創建一個SparkContext進行資源申請,任務分配與監控
- 資源管理器給Executor分配資源,申請完畢在worker中啟動Executor行程
- SparkContext根據RDD的依賴關系生產DAG圖
- DAG圖由DAGScheduler決議成Stage,之后把一個個TaskSet提交給底層調度器TaskScheduler處理
- Executor向Sparkcontext申請Task,TaskScheduler將Task發給Executor運行并提供程式代碼
- 運行完畢后寫入資料并釋放資源
涉及到的基本概念
對于Spark運行的流程介紹中涉及到了一些Spark基本概念與名詞,下面進行解釋
-
Driver:該行程呼叫Spark程式的main方法,并啟動SparkContext
-
Executor:作為一個行程運行在作業節點WorkerNode,負責運行Task
-
RDD:彈性分布式資料集,是分布式記憶體的抽象概念,后續文章會大篇幅介紹到
-
Task:是運行在Excutor上的作業單元
-
Job:一個Job包含了多個RDD以及作用于對于RDD上的各種操作,
-
Stage:是Job調度的基本單位,一個Job分成多組Task,每組Task被稱為Stage,或者稱為TaskSet,
-
DAG:有向無環圖,主要反映RDD之間的依賴關系
-
Master:負責管理集群與節點,不參與到計算
-
Worker:該行程是一個守護行程,主要負責和外部集群工具打交道,申請或者釋放集群資源,
-
Client:用戶進行程式提交的入口
3.Spark的組成
Spark主要由五大部分組成,這五大部分的內容結構歸結起來就可以說是學習Spark的基本路線了,Spark最核心的功能是RDDs,而RDDs就存在于spark-core這個包內,這個包也是spark最核心的部分,提供給了多種上層API,用于不同場景下的計算,
- Spark Core:
Spark-Core是整個Spark的基礎,
包含Spark的基本功能,包含任務調度,記憶體管理,容錯機制等,內部定義了RDDs(彈性分布式資料集),提供了很多APIs來創建和操作這些RDDs,為其他組件提供底層的服務,
- Spark SQL:
Spark SQL在spark-core的基礎之上又推出一個DataSet與DataFrame的資料抽象化概念,提供了在DataSet與DataFrame之上執行SQL的能力,
Spark SQL處理結構化資料的庫,就像Hive SQL,Mysql一樣,企業中用來做報表統計,
- Spark Streaming:
Spark streaming充分利用了spark-core的快速調度能力來進行流發計算與分析,是實時資料流處理組件,類似Storm,Spark Streaming提供了API來操作實時流資料,企業中用來從可以Kafka接收資料做實時統計,
- MLlib:
MLlib是Spark上分布式機器學習的框架,是一個包含通用機器學習功能的包,Machine learning lib包含分類,聚類,回歸等,還包括模型評估和資料匯入,MLlib提供的上面這些方法,都支持集群上的橫向擴展,
- Graphx:
Graphx是分布式圖計算框架,是用來處理圖的庫(例如,社交網路圖),并進行圖的并行計算,像Spark Streaming,Spark SQL一樣,它也繼承了RDD API,它提供了各種圖的操作,和常用的圖演算法,例如PangeRank演算法,
Spark提供了全方位的軟體堆疊,只要掌握Spark一門編程語言就可以撰寫不同應用場景的應用程式(批處理,流計算,圖計算等),Spark主要用來代替Hadoop的MapReduce部分,
4.總結
到這里我們就完成了集群的搭建與第一個小案例的運行,如果操作程序中遇到問題可以私信我,博主會盡力幫你解答💪,Spark專欄地址,更多的大資料資料以及本文安裝包可以通過下方公眾號獲取哦,加入小禪的🏘?大資料技術社區一起交流學習,感謝支持!💪
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400496.html
標籤:其他
上一篇:RabbitMQ速通入門
下一篇:kibana 開發工具常用命令