資料庫技識訓礎
1.資料庫系統:資料庫,硬體,軟體,人員
2.DBMS(資料庫管理系統)的功能:資料定義,資料庫操作,資料庫運行管理,資料組織、存盤和管理,資料庫的建立和維護,與其他軟體系統的通信功能等
3.DBMS 的特征:資料結構化且統一管理,有較高的資料獨立性,資料控制功能(資料庫的安全性保護、資料的完整性、并發控制、故障恢復)
4.DBMS 分類:
關系資料庫系統(物體間的聯系用關系表示)
面向物件的資料庫系統(以物件形式對資料建模)
物件關系資料庫系統(在關系資料模型基礎上提供處理新的資料型別操作的能力)
5.資料庫系統體系結構:
集中式(資料、資料管理、資料庫功能等都集中在一起)
分布式(物理上分布+邏輯上分布)
C/S 模式(客戶端負責資料表示服務、服務器負責資料庫服務)
并行結構(多個 CPU 物理上連在一起處理)
6.資料庫的三級模式:
概念模式(資料庫中全部資料的邏輯結構和特征的描述、只涉及型的描述而不涉及具體的值)
外模式(用戶與資料庫系統的介面、用戶用到那部分資料的描述)
內模式(資料物理結構和存盤方式的描述、資料在資料庫內部的表示方式)
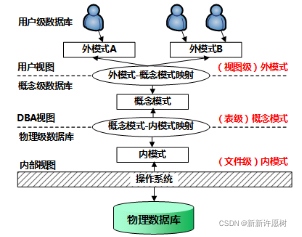
外模式對應視圖;概念模式對應基本表;內模式對應存盤檔案
7.資料庫的兩級映像:
概念模式/內模式映射(實作概念模式與內模式的轉換)
外模式/概念模式映射(實作外模式與概念模式的轉換)
8.資料的獨立性:
物理獨立性(資料庫的內模式改變時資料的邏輯結構不變)
邏輯獨立性(用戶的應用程式與資料庫的邏輯結構相互獨立)
9.資料模型:
概念資料模型(E-R 模型等)
基本資料模型(層次模型:用樹型結構表示資料間的聯系;網狀模型:用網路結構表示資料間的聯系;關系模型:用表格結構表示物體間的聯系;面向物件模型:物件標識+封裝+物件的屬性+類和類層次+繼承)
10.資料模型三要素:資料結構,資料操作,資料的約束條件
11.E-R 圖:物體(矩形),聯系(菱形),屬性(橢圓形)
12.完整性約束:物體完整性,參照完整性,用戶自定義完整性
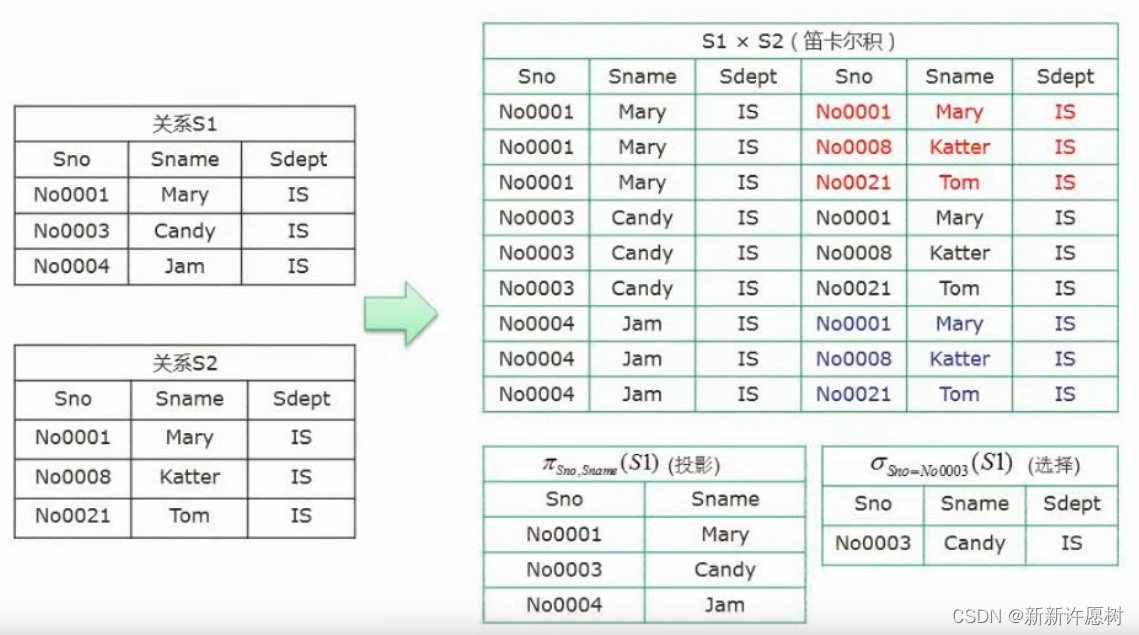
13.關系代數運算:并,交,差,笛卡爾積,投影,選擇,連接,除
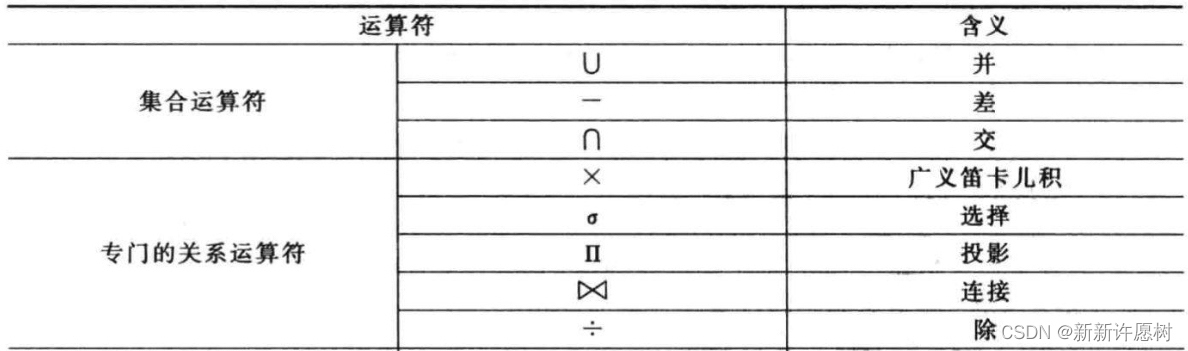
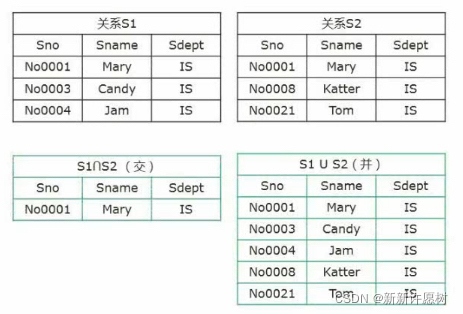
并:兩個關系不同的部分,S1∪S2→S1和S2不同的記錄
交:兩個關系相同的部分,S1∩S2→S1和S2相同的記錄
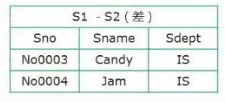
差:前一個關系有而后一個關系沒有的部分,S1-S2→S1有但S2沒有記錄
連接:屬性相連,去掉重復列
笛卡爾積:兩個關系每條記錄都連接一次
投影:指定屬性展示出來
選擇:指定記錄展示出來
14.SQL 語言的特點:綜合統一,高度非程序化,面向集合的操作方式,兩種使用方式(自含式、嵌入式),語言簡潔易學易用
15.SQL 語言的組成:語資料定義言,互動式資料操縱語言,事務控制,嵌入式SQ 和動態SQL,完整性,權限管理
16.SQL 資料定義:創建(create),修改(alter),洗掉(drop):表(table),視圖(view[as select]),索引(index[on])
17.SQL 資料查詢:select...from...where...group by...having...order by...
18.插入資料:insert into...values...
19.修改資料:update...set...=...where...
20.洗掉資料:delete from...where...
21.授權:grant...on...to...(with grant option)
22.回收權限:revoke...on...from...
23.函式依賴:反映屬性間的聯系(X→Y);
完全函式依賴:(學生 ID,所修課程 ID)→成績;
部分函式依賴 :(學生 ID,所修課程 ID)→學生姓名;
平凡函式依賴:X→Y 且 Y 包含于X;
非平凡函式依賴:X→Y 且Y 不包含于X;
傳遞函式依賴:X→Y,Y→Z
求候選鍵:
1、將函式依賴轉化為有向圖
2、找出入度為0的屬性(或屬性集合),以該屬性(或屬性集合)為起點,嘗試遍歷有向圖,若能遍歷完所有節點,則為一個候選鍵,
3、若沒有入度為0的節點,找中間節點進行遍歷
例子:關系R(A1,A2,A3,A4),函式依賴為F={A1→A2,A3→A2,A2→A3,A2→A4}
有向圖為:
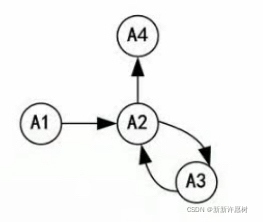
A1入度為0,且能夠遍歷完所有節點,所以A1為候選鍵
24.規范化:
1NF:每個分量都不可再分;
2NF:消除非主屬性對碼的部分函式依賴;
3NF:消除非主屬性對碼的傳遞函式依賴
25.模式分解標準:無損連接,保持函式依賴
26.事務的 ACID 性質:原子性,一致性,隔離性,持久性
27.事務管理:事務開始(begin transaction),事務提交(commit),事務回滾(rollback)
28.資料庫故障:事務內部故障,系統故障,介質故障,計算機病毒
29.資料備份方法:靜態轉儲和動態轉儲,海量轉儲和增量轉儲,日志檔案
30.資料恢復步驟:反向掃描檔案日志,對事物的更新操作執行逆操作,繼續反向掃描和更新,直到事務的開始標志
31.并發控制的技術:封鎖(寫鎖、讀鎖)
32.資料不一致性:丟失修改,不可重復讀,讀臟資料
33.在資料庫邏輯結構設計階段,需要(需求分析)階段形成的(需求說明檔案、資料字典和資料流圖)作為設計依據
資料結構
1.資料結構:資料元素的集合及元素間的相互關系和構造方法
2.線性表的存盤結構:順序存盤,鏈式存盤
3.單鏈表節點:typedef struct node{ int data; struct node *link; }NODE,*LinkList;
4.雙向鏈表:每個節點有兩個指標,分別指出直接前驅和直接后繼
5.回圈鏈表:尾節點指標指向第一個節點
6.靜態鏈表:借助陣列來描述線性表的鏈式存盤結構
7.堆疊:后進先出;初始化堆疊:InitStack(S) 判堆疊空:StackEmpty(S) 入堆疊:Push(S,x) 出堆疊:Pop(S) 讀取堆疊頂元素:Top(S) 順序存盤+鏈式存盤
8.佇列:先進先出,尾入頭出;初始化隊:初始化隊:InitQueue(Q) 判隊空:Empty(Q) 入
佇列的特點是先進先出,若用回圈單鏈表表示佇列,則:入隊和出隊操作都不需要遍歷鏈表
決議:入隊和出隊都只需移到指標指向位置
入隊:新節點s->next指向首結點,然后rear->next指向新的結點s
出隊:rear->next=rear->next->next
9.串:僅由字符構成的有限序列,是取值范圍受限的線性表
10.陣列:定長線性表在維數上的擴張,一般不做插入洗掉運算
11.矩陣:
特殊矩陣(元素分布有一定的規律:對稱矩陣、三角矩陣、對角矩陣);
稀疏矩陣(非零元素遠少于零元素且律:用三元組存盤(行號,列號,值))
12.廣義表(表中有表):表頭(表中第一個元素);表尾(表中除去表頭剩下的部分)
13.樹:遞回的,元素之間有明顯的層次關系
14.完全二叉樹應采用順序存盤結構,一般二叉樹則應采用鏈式存盤結構
15.二叉樹的鏈式存盤結構:typedef struct BiTnode{ int data; struct BiTnode *lchild, *rchild; }BiTnode, *BiTree;
16.二叉樹的遍歷:先序遍歷(先訪問根節點),中序遍歷(第二訪問根節點),后序遍歷(最后訪問根節點),層序遍歷(利用佇列、每次出同一層的節點時進他們的子節點層)
17.線索二叉樹:加上線索(直接前驅和直接后繼)的二叉樹
18.最優二叉樹(哈夫曼樹):一類帶權路徑長度最短的樹
19.樹的存盤結構:雙親表示法(順序存盤);孩子表示法(鏈式存盤);孩子兄弟表示法(鏈式存盤,兩個指標分別為第一個孩子和下一個兄弟)
20.圖:一個節點的前驅節點和后繼節點數目沒有任何限制
21.圖的表示:G=(V,E);V:頂點的集合;E:邊的集合
22.網:邊帶權值的圖
23.圖的相關概念
24.圖的存盤結構:鄰接矩陣表示法,鄰接鏈表表示法
25.圖的遍歷:深度優先搜索,廣度優先搜索
26.生成樹:極小連通子圖,針對連通圖
27.最小生成樹(權值和最小的生成樹)
演算法:
普尼姆演算法(在相鄰邊的基礎上求最小,與邊數無關,適于邊稠密的網);
克魯斯科爾演算法(在不構成環的基礎上找最小邊直至連通,與頂點數無關,適于邊稀疏的網)
28.AOV 網:有向圖中頂點表示活動,有向邊表示活動間的優先關系
29.拓撲排序:將AOV 網中所有頂點按優先順序排成一個線性序列的程序
30.AOE 網:有向圖中有向邊表示活動,邊上的權值表示該活動持續的時間
31.關鍵路徑:從源點到匯點的路徑中長度最長的
32.最短路徑:從源點到其余各頂點的最短路徑-----迪杰斯克拉演算法
33.平均查找長度:關鍵字和給定值進行過比較的記錄個數的平均值
34.靜態查找方法:順序查找;折半查找;分塊查找
35.動態查找:表結構本身在查找程序中是動態生成的
36.二叉排序樹:左子樹上所有節點的值小于根節點的值,右子樹上所有節點的值大于根節點的值
37.平衡二叉樹(AVL 樹):左子樹和右子樹高度之差的絕對值不超過 1
38.B_樹(m 階):每個節點子樹個數<=m,根節點子樹個數=0 或>=2,其他節點子樹個數=0或>=m/2
39.哈希表:通過哈希函式(以記錄的關鍵字為自變數)得到記錄的存盤地址;定長按一定函式規律存放資料;哈希地址+關鍵字
40.哈希表的重點:構造哈希函式(直接定址法,數字分析法,平方取中法,折疊法,亂數法,除留余數法);解決沖突(開放定址法,鏈地址法,再哈希法)
41.簡單排序(時間復雜度 O(n2),空間復雜度 O(1))
直接插入排序(插入第 i 個時前 i-1 個以排序好)
冒泡排序(相鄰兩個比較排序,每次回圈確定一個極值)
簡單選擇排序(第 i 個依次與后面每個元素比較排序,每次回圈確定一個極值,不穩定)
42.高端內部排序:
希爾排序(先將整個序列分割成若干序列分別進行直接插入排序,再對整個序列進行一次直接插入排序,不穩定);
快速排序(將整個記錄分割成獨立的兩部分,兩個指標分別指向對應部分的兩端,往中間移動比較排序,遞回,不穩定);
堆排序(建立初始堆輸出并洗掉堆頂關鍵字,再建立新堆得到新的關鍵字依次輸出,不穩定)
歸并排序(將若干個有序序列合并為新的有序序列);
基數排序(按組成關鍵字的各個數位的值進行排序)
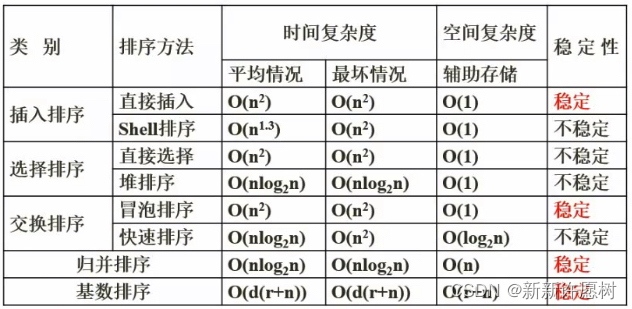
43.排序演算法的時間復雜度、空間復雜度以及是否是穩定排序
直接插入排序、希爾排序、直接選擇排序、冒泡排序:O(n^2),O(1)
穩定:直接插入、冒泡、歸并、基數
對于具有n個元素的一個資料序列,若只需得到其中第k個元素之前的部分排序,最好采用:堆排序
決議:對于希爾排序、直接插入排序,只有在排序程序后才能確保全部序列以及前k個元素的最終排序,
記憶:快速排序時間復雜度【最好和最壞】和空間復雜度,不穩定排序
直接插入排序:從陣列的第二位開始,依次倒敘向前遍歷排序,滿足條件則交換順序
時間復雜度是O(n2),空間復雜度是O(1),穩定排序
private void InsertSort(int[] array) {
if (array == null || array.length < 2) {
return;
}
for (int i = 1; i < array.length; i++) {
// 標志位,防止待插入元素最小
boolean flag = false;
int cur = array[i];
for (int j = i - 1; j > -1; j--) {
// 當前值和它前面的值比較,如果比前面的值小,前面的值后移,當前值替換前面的值;否則設定標識位
if (cur < array[j]) {
array[j + 1] = array[j];
array[j] = cur;
} else {
flag = true;
break;
}
}
if (!flag) {
array[0] = cur;
}
}
}希爾排序:對直接插入排序的優化,將待排序的陣列元素按下標的一定增量分組,分成多個子序列,然后對各個子序列進行直接插入排序演算法排序;然后依次縮減增量再進行排序,直到增量為1時,進行最后一次直接插入排序,排序結束,
時間復雜度是O(nlog2n),空間復雜度是O(1),非穩定排序
private void shellSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// 3for + if
for (int d = arr.length/2; d >= 1; d = d/2) {
// 增量后半截
for (int i = d; i < arr.length; i++) {
// 增量前半截
for (int j = i - d; j > -1; j -= d) {
if (arr[j] > arr[j + d]) {
// 后半截和前半截差量進行插入排序
int tmp = arr[j];
arr[j] = arr[j + d];
arr[j + d] = tmp;
}
}
}
}
}簡單選擇排序:每一趟從待排序的資料元素中選擇最小(或最大)的一個元素作為首元素,直到所有元素排完為止,例:21 48 21* 63 17,第一趟排序,21與17交換,導致21與21*的相對位置發生變化
時間復雜度是O(n2),空間復雜度是O(1),不穩定排序
private void selectSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int i = 0; i < arr.length; i++) {
// 記錄每次回圈中的最小值
int minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[minIndex] > arr[j]) {
minIndex = j;
}
}
// 最小值不是當前值,交換位置
if (minIndex != i) {
int temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
}
}冒泡排序:對相鄰的元素進行兩兩比較,順序相反則進行交換,這樣,每一趟會將最小或最大的元素“浮”到頂端,最終達到完全有序,
時間復雜度是O(n2),空間復雜度是O(1),穩定排序
private void bubbleSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
for (int i = 0; i < arr.length; i++) {
boolean flag = false;
// 每次冒最大值到陣列最后一位
for (int j = 0; j < arr.length - i -1; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = true;
}
}
// 本次回圈沒有移動位置,說明陣列已有序,退出回圈
if (!flag) {
break;
}
}
}堆排序:程序可以具體分為三步,創建堆,調整堆,堆排序,
- 創建堆,以陣列的形式將堆中所有的資料重新排序,使其成為最大堆/最小堆,
- 調整堆,調整程序需要保證堆序性質:在一個二叉堆中任意父節點大于其子節點,
- 堆排序,取出位于堆頂的第一個資料(最大堆則為最大數,最小堆則為最小數),放入輸出陣列B中【也可以是它自己】,再將剩下的堆做調整,堆的迭代/重復運算直至輸入陣列A中只剩下最后一個元素,
時間復雜度是O(n*log(n)),空間復雜度是O(1),不穩定排序
private void heapSort(int[] arr) {
for (int i = arr.length - 1; i > 0; i--) {
// 調整堆
for (int j = cur; j > 0; j--) {
if (arr[i] > arr[i/2]) {
swap(arr, i, i/2);
}
}
// 排序堆
swap(arr, i, 0);
}
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}快速排序:選擇一個基準值,一輪排序后,基準值左邊的值都比它小,右邊的值都比它大;對基準值左右兩邊的數進行相同的操作,直到基準值左右兩邊的值只有一個
時間復雜度是O(nlog n),空間復雜度是O(logn),不穩定排序
劃分程序中,最佳的基準元素選擇的方法是選擇待劃分陣列的(中位數)元素,此時,演算法在最壞情況下的時間復雜度為(不考慮所有元素均相等的情況)(O(n))
中位數
private void fastSort(int[] arr, int begin, int end) {
// 記錄每一次開始和結束位置,如果 begin >= end 遞回結束
int i = begin;
int j = end;
if (begin >= end) {
return;
}
// 選出哨兵元素【i和j】和基準元素
int base = arr[begin];
while (i < j) {
// 從右開始選擇第一個比基準小的值
while (arr[j] >= base && i < j) {
j--;
}
// 從左開始選擇第一個比基準大的值
while (arr[i] <= base && i < j) {
i++;
}
// 交換i和j的值
if (i != j) {
swap(arr, i, j);
}
}
// 當i==j時,當前值和基準值做交換,作為新一輪基準值
swap(arr, i, begin);
// 基準左邊值
fastSort(arr, begin, i - 1);
// 基準右邊值
fastSort(arr, i + 1, end);
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}歸并排序:分治法,將陣列拆分成一個個小的陣列,排序后,再合并成一個大的陣列
時間復雜度是O(nlogn)【合并的平均時間復雜度為O(n),完全二叉樹的深度為log2n】,空間復雜度是O(n),穩定排序
public void main(String[] args) {
int[] sourceArr = new int[]{9, 3, 1, 4, 2, 7, 8, 6, 5};
int[] mergeArr = new int[sourceArr.length];
mergeSort(sourceArr, mergeArr, 0, sourceArr.length - 1);
System.out.println(Arrays.toString(sourceArr));
}
private static void mergeSort(int[] sourceArr, int[] mergeArr, int low, int high) {
if (low >= high) {
return;
}
int mid = (low + high)/2;
// 拆分左邊陣列
mergeSort(sourceArr, mergeArr, low, mid);
// 拆分右邊陣列
mergeSort(sourceArr, mergeArr, mid + 1, high);
// 合并
merge(sourceArr, mergeArr, low, high, mid);
}
private static void merge(int[] sourceArr, int[] mergeArr, int low, int high, int mid) {
int i = low;
int j = mid + 1;
int k = 0;
while (i <= mid && j <= high) {
if (sourceArr[i] <= sourceArr[j]) {
mergeArr[k++] = sourceArr[i++];
} else {
mergeArr[k++] = sourceArr[j++];
}
}
// 左邊剩余元素填充進臨時陣列中
while (i <= mid) {
mergeArr[k++] = sourceArr[i++];
}
// 右邊剩余元素填充進臨時陣列中
while (j <= high) {
mergeArr[k++] = sourceArr[j++];
}
// 臨時陣列值拷貝回原陣列
k = 0;
while(low <= high){
sourceArr[low++] = mergeArr[k++];
}
}例:對基本有序的整數排序

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/400976.html
標籤:其他