python爬取基本內容
用爬蟲爬取bilibili網站排行榜游戲類的所有名稱及鏈接
匯入requests、BeautifulSoup
import requests
from bs4 import BeautifulSoup然后我們需要插入網站鏈接并且要決議網站并列印出來
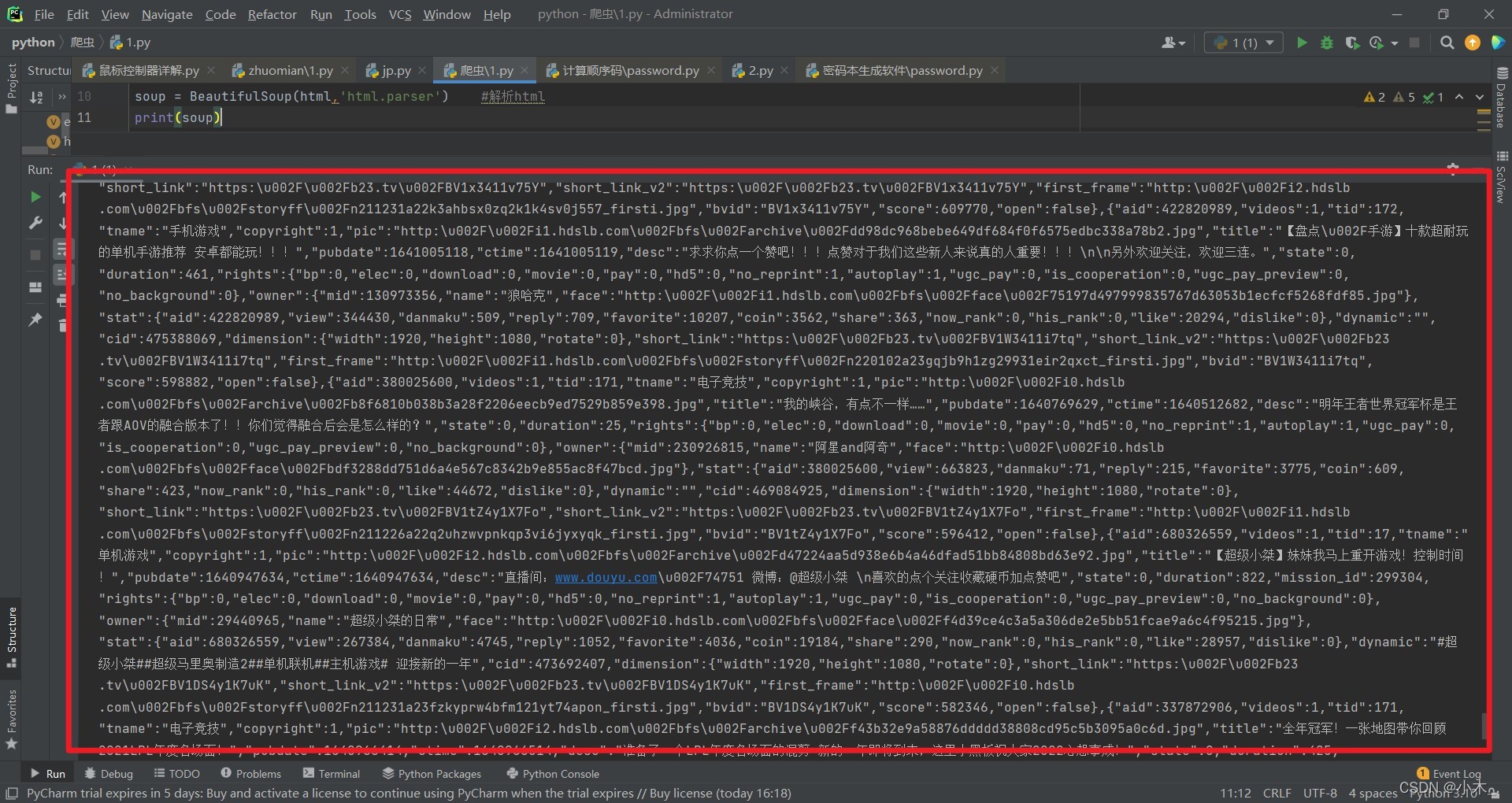
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #當前網站鏈接
html = e.content
soup = BeautifulSoup(html,'html.parser') #決議html
print(soup)我們可以看到密密麻麻的代碼函式,但不太簡潔明了,我們去優化一下
繼續插入如下代碼這個代碼是可以爬取我們想要的類,可以更簡介的簡化代碼
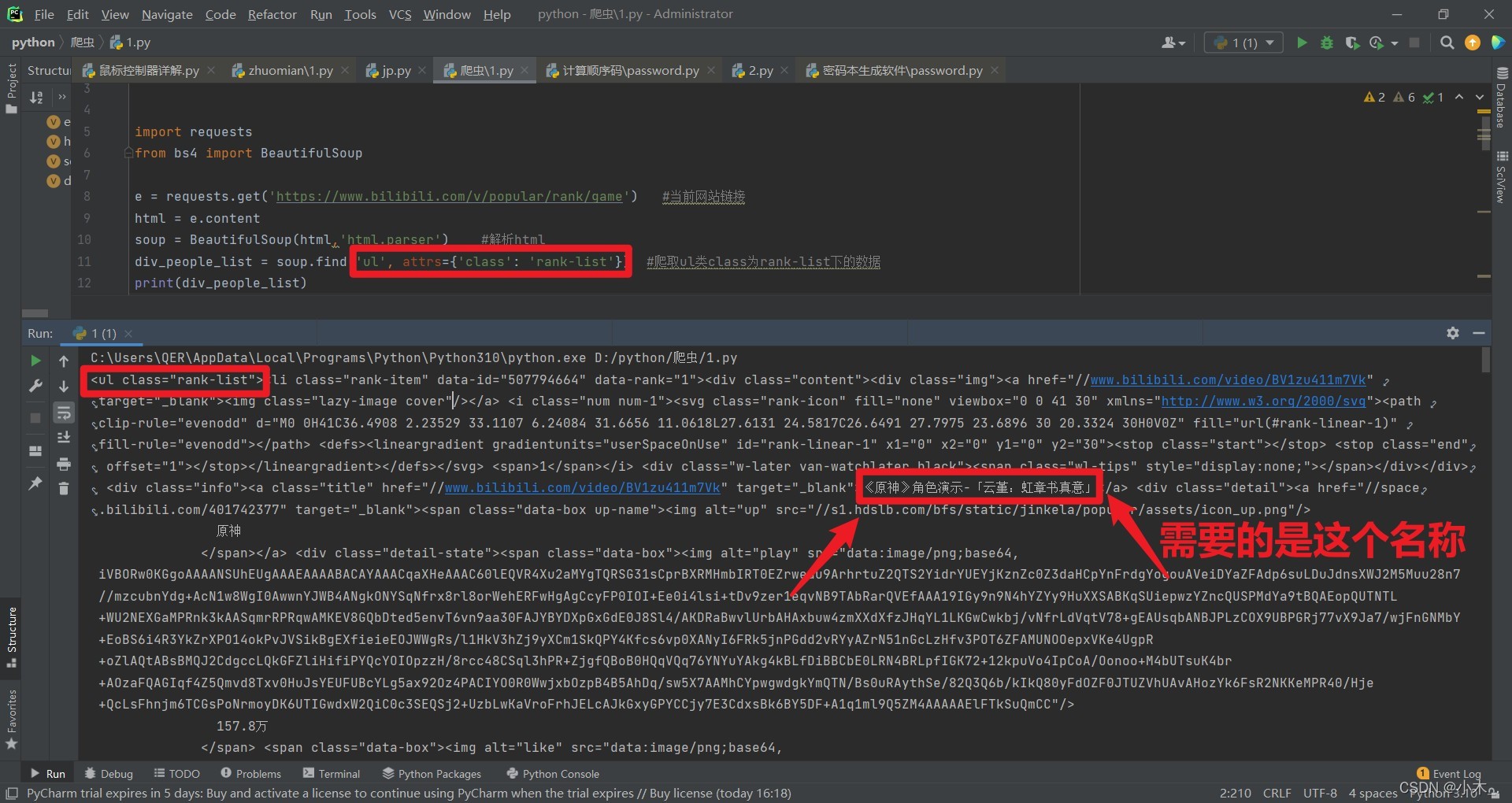
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul類class為rank-list下的資料可以看到還是不夠簡介
我們繼續簡化它
繼續插入如下代碼
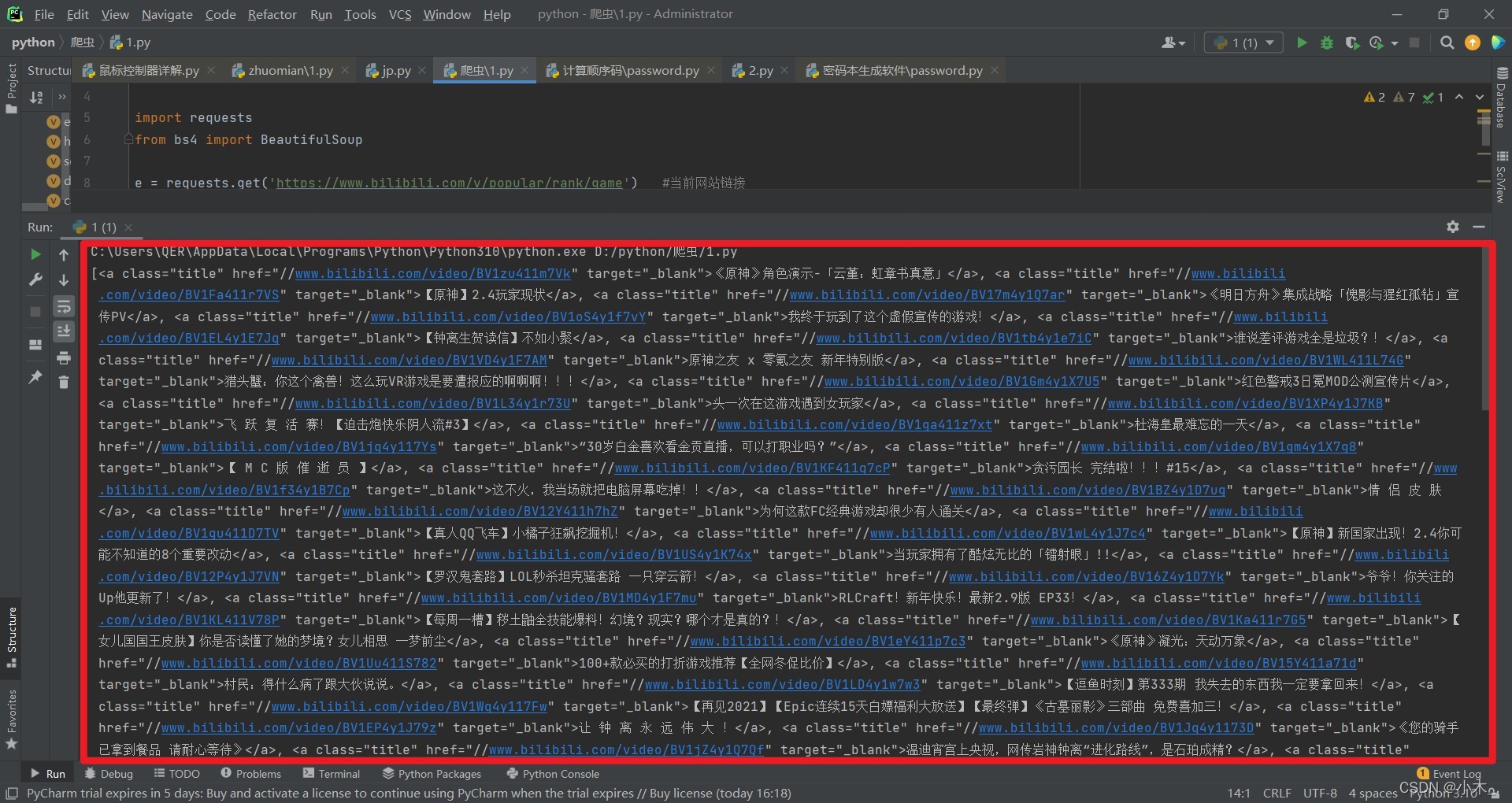
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a類class為title下的資料可以看到鏈接及主題都提取出來了,但還是有瑕疵
我們加入這行代碼挨個列印并提取標題及鏈接,由于鏈接提取出來的是//www.bilibili.com/video/BV1yZ4y1D7ef
前面沒有http:點擊進去會出現錯誤,所有我們需要在前面加入http:進行連接在一起列印
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t點擊鏈接直接觀看鏈接:'+f'http:{url}')可以看到我們的標題及連接都爬取出來了

完整代碼:
import requests
from bs4 import BeautifulSoup
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #當前網站鏈接
html = e.content
soup = BeautifulSoup(html,'html.parser') #決議html
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul類class為rank-list下的資料
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a類class為title下的資料
#挨個傳輸到t,然后列印資料
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t點擊鏈接直接觀看鏈接:'+f'http:{url}')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401489.html
標籤:其他