初探目標檢測
- 今天開始記錄我的基于深度學習的目標檢測學習
利用Python實作IoU的計算,代碼如下:
def iou(boxA, boxB):
# 計算重合部分的上、下、左、右4個邊的值,注意最大最小函式的使用
left_max = max(boxA[0], boxB[0])
top_max = max(boxA[1], boxB[1])
right_min = min(boxA[2], boxB[2])
bottom_min = min(boxA[3], boxB[3])
# 計算重合部分的面積
inter =max(0, (right_min-left_max))* max(0, (bottom_min-top_max)
Sa = (boxA[2]-boxA[0])*(boxA[3]-boxA[1])
Sb = (boxB[2]-boxB[0])*(boxB[3]-boxB[1])
# 計算所有區域的面積并計算iou,如果是Python 2,則要增加浮點化操作
union = Sa+Sb-inter
iou = inter/union
return iou
# 對于IoU而言,我們通常會選取一個閾值,如0.5,來確定預測框是正確的還是錯誤的,
# 當兩個框的IoU大于0.5時,我們認為是一個有效的檢測,否則屬于無效的匹配,
幾種名詞解釋
-
正確檢測框TP(True Positive):預測框正確地與標簽框匹配了,兩者間的IoU大于0.5,
-
誤檢框FP(False Positive):將背景預測成了物體,通常這種框與圖中所有標簽的IoU都不會超過0.5,
-
漏檢框FN(False Negative):本來需要模型檢測出的物體,模型沒有檢測出,
-
正確背景(True Negative):本身是背景,模型也沒有檢測出來,這種情況在物體檢測中通常不需要考慮,
-
對于一個檢測器,通常使用mAP(mean Average Precision)這一指標來評價一個模型的好壞,這里的AP指的是一個類別的檢測精度,mAP則是多個類別的平均精度,評測需要每張圖片的預測值與標簽值,
-
預測值(Dets):物體類別、邊框位置的4個預測值、該物體的得分,
-
標簽值(GTs):物體類別、邊框位置的4個真值,
在預測值與標簽值的基礎上,我們首先將所有的預測框按照得分從高到低進行排序(因為得分越高的邊框其對于真實物體的概率往往越大),然后從高到低遍歷預測框,
從代碼層面詳細講述AP求解程序
- 假設當前經過標簽資料與預測資料的加載,我們得到了下面兩個變數:
- det_boxes:包含全部影像中所有類別的預測框,其中一個邊框包含了[left, top, right, bottom, score, NameofImage],
- gt_boxes:包含了全部影像中所有類別的標簽,其中一個標簽的內容為[left, top, right, bottom, 0],需要注意的是,最后一位0代表該標簽有沒有被匹配過,如果匹配過則會置為1,其他預測框再去匹配則為誤檢框,
for c in classes:
# 通過類別作為關鍵字,得到每個類別的預測、標簽及總標簽數
dects = det_boxes[c]
gt_class = gt_boxes[c]
npos = num_pos[c]
# 利用得分作為關鍵字,對預測框按照得分從高到低排序
dects = sorted(dects, key=lambda conf: conf[5], reverse=True)
# 設定兩個與預測邊框長度相同的串列,標記是True Positive還是False Positive
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 對某一個類別的預測框進行遍歷
for d in range(len(dects)):
# 將IoU默認置為最低
iouMax = sys.float_info.min
# 遍歷與預測框同一影像中的同一類別的標簽,計算IoU
if dects[d][-1] in gt_class:
for j in range(len(gt_class[dects[d][-1]])):
iou = Evaluator.iou(dects[d][:4], gt_class[dects[d][-1]][j][:4])
if iou > iouMax:
iouMax = iou
jmax = j # 記錄與預測有最大IoU的標簽
# 如果最大IoU大于閾值,并且沒有被匹配過,則賦予TP
if iouMax >= cfg['iouThreshold']:
if gt_class[dects[d][-1]][jmax][4] == 0:
TP[d] = 1
gt_class[dects[d][-1]][jmax][4] = 1 # 標記為匹配過
# 如果被匹配過,賦予FP
else:
FP[d] = 1
# 如果最大IoU沒有超過閾值,賦予FP
else:
FP[d] = 1
# 如果對應影像中沒有該類別的標簽,賦予FP
else:
FP[d] = 1
# 利用NumPy的cumsum()函式,計算累計的FP與TP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos # 得到每個點的Recall
prec = np.divide(acc_TP, (acc_FP + acc_TP)) # 得到每個點的Precision
# 利用Recall與Precision進一步計算得到AP
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(rec, prec)
部署環境
- 查了一下資料,發現首先要按照Nvidiad的顯卡驅動,并能夠顯示GPU的記憶體,使用情況等資訊,
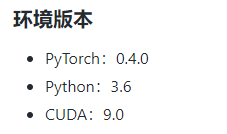
- 安裝CUDA(Compute Unified Device Architecture),CUDA是NVIDIA推出的通用并行計算架構,可以使類似于PyTorch之類的深度學習框架呼叫GPU來解決復雜的計算問題,為了實作更高效的GPU并行計算,通常我們還需要安裝cuDNN庫,cuDNN庫是由NVIDIA開發的專用于深度神經網路的GPU加速庫,這個我們首先要根據實作的代碼案例來查看版本號,然后在官網按照步驟下載即可,我的環境版本要求如下圖:
今日總結
由于是第一次接觸相關知識,像個無頭蒼蠅一樣,導致代碼只能稍微看懂一點,但是具體還是不知道如何去實作,我暫時是看《深度學習之PyTorch物體檢測實戰》,各位大佬如有更好的書籍或者路線,可以在下方評論,萬分感謝!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401494.html
標籤:其他
上一篇:多媒體技術(大計基復習資料)