在我們自學神經網路神經網路的損失函式的時候會發現有一個思路就是交叉熵損失函式,交叉熵的概念源于資訊論,一般用來求目標與預測值之間的差距,比如說我們在人腦中有一個模型,在神經網路中還有一個模型,我們需要找到神經網路模型跟人腦模型最相近的那一個,那就需要找到一個方法需要定量的去看待兩個模型的差異,
文章目錄
- 1 交叉熵
- 1.1熵
- 1.1.1資訊量
- 1.2相對熵,kl散度
- 2 交叉熵函式的應用分析
- 2.1 交叉熵函式單分類問題應用
- 2.2交叉熵在多分類問題中的使用
- 2.3學習程序與優缺點
- 2.3.1二分類情況
- 2.3.2優缺點
- 2.3.1.2優點
- 2.3.1.3缺點
- 總結
1 交叉熵
交叉熵其實就是運用了熵的概念先把模型轉化為熵的數值然后用數值去比較模型之間的差異,
那為什么要用熵?熵是指一個模型體系的混亂程度,如果兩個模型是同一類的比如說都是高斯分布,這樣可以直接進行比較,那如果一個是高斯分布一個是泊松分布那就無法直接進行比較,同時人腦模型跟神經網路模型一樣也有混亂度,要理解交叉熵,需要先了解下面幾個概念,
1.1熵
熵在物理學跟資訊論當中都有定義當然我們看的是深度學習 我們還是運用資訊論中的概念,我們先引入資訊量
1.1.1資訊量
舉個例子比如說讓你再做一遍你小學二年級都會的十以內的加減法,你就會說都會了寫了沒用,這種情況就是資訊量很低,還有一種情況比如說馬云今天吃了個蘋果是山東煙臺產的紅富士,這個訊息你不知道但是知道了好像對于你并沒有多大的幫助這種情況也算是資訊量很低,所以看一個資訊資訊量到底大不大不是看你知道不知道還要看給你帶來多少確定性,比如說羽毛球男單比賽

現在有八支球隊進行比賽,現在中國人奪冠概率是八分之一,過兩天比賽結果出來發現中國人奪冠了,那么概率之前為八分之一不確定的事情到現在百分之一百確定了 那這個事情資訊量很高,如果說中國隊進了決賽,那這件事概率由八分之一到二分之一 ,這件事也有資訊量但沒有奪冠的資訊量高,因為這件事只是從八分之一到二分之一不是到百分之百,所以不同的資訊含有的資訊量是不一樣的,那么怎么去求資訊量呢我們定義一下:
f(x): = (資訊量)
f(中國隊贏得比賽)=f(中國隊進決賽)+f(中國隊贏得比賽)
中國隊贏得比賽資訊量等于中國隊進決賽的資訊量加上中國隊贏得比賽得資訊量相加,

我們可以得出f(1/8)=f(1/4)+f(1/2)
那么我們應該怎么寫才能自洽 這里我們可以知道1/8,1/4,1/2,都是概率,
p(中國隊奪冠)=p(中國隊進決賽)p(中國隊贏得決賽)
所以這幾個式子完全滿足才能自洽,得出
f(x1x2)=f(x1)+f(x2)
那么相乘怎么得出相加呢,所以這個f(x): = (資訊量)必須有一個log
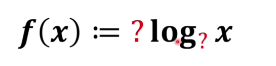
那為什么是log 因為就是定義 只要滿足體系自洽就行,作為定義本身就是賦予含義,
所以這個式子有兩個地方不清楚一個是系數另外一個是以幾為底,
我們可以想一下x自變數越小 這件事資訊量就越大 這是一個相反的關系,所以前面系數可以賦值為-1,
那么log以幾為底合適呢其實到這里自洽已經很滿足了,以幾為底都是比較隨意的,這里可以以2為底也可以以e為底,這里就以2為底得出
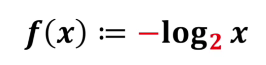
f(1/8)=f(1/4)+f(1/2)
我們可以算出中國隊奪冠資訊量為3
比如說有兩場比賽 日本隊跟韓國隊比賽獲勝概率都是1/2

中國隊跟韓國隊獲勝的概率分別是99/100和1/100

那么可以得出日本隊資訊量為
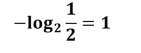
中國隊資訊量為
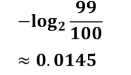
韓國隊資訊量為
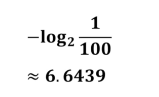
仔細想一下在這里資訊量是不能直接相加的這里是各個球隊贏球的話資訊量是這么多所以前面要乘以概率得出各個球隊隊系統貢獻量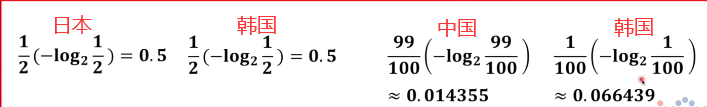
觀察上面公式子可以得出資訊量乘以占比再相加 ,就是相當于求期望然后我們可以對熵進行定義,假如說一個概率系統p
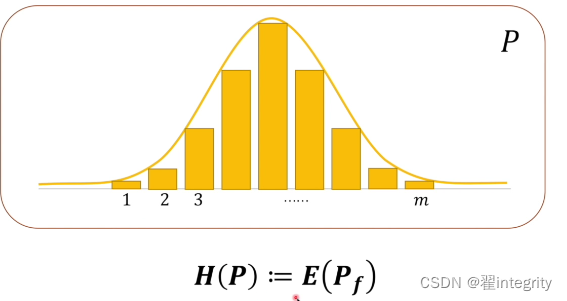
我們·可以求這個概率系統的熵 熵就是定義成對這個系統求期望
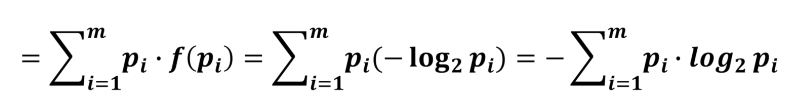
這個就是熵的定義,通過熵的定義我們可以看出這是對整體系統的衡量衡量的結果也能反映出模型的不確定程度,
1.2相對熵,kl散度
通過上面我們知道可以通過計算熵的大小來衡量不同模型混亂程度的區別 但是人腦模型的熵不太好計算那怎么辦?我們引入相對熵的概念,也叫kl散度,KL散度 = 交叉熵 - 資訊熵
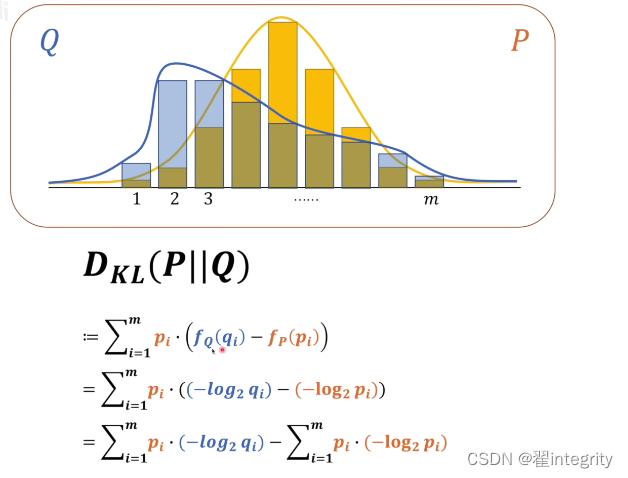
這里兩個不同系統p跟q,比較兩個系統差異性
下面就是kl散度 kl散度越小證明越接近 , p在q前代表以p為基準去考慮p跟q相差多少
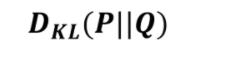
這個是q系統的資訊量減去p系統的資訊量的差值求整體期望
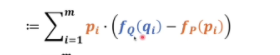
最后化簡 我們可以發現后面這個式子就是系統p的熵,在前面我們把p系統當成基準所以p的熵是恒定的
所以我們看q是不是跟p的差異比較小是要看前面部分,公式前面部分就叫交叉熵,
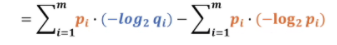
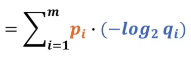
我們可以用H(p,q)來表示交叉熵函式
前面我們說kl散度越趨近于零代表模型越接近 那么我們可以發現后面p的熵肯定大于零,交叉熵的值越小kl散度越大,交叉熵的值越大kl的散度也越大,這樣就給我們判斷帶來難題,我們希望交叉熵只占一邊,這樣用它做損失函式會簡單很多,通過吉布斯不等式我們可以看出kl散度絕對是大于零的,

當q 跟p相等的時候等于零,不等的時候大于零,所以這個公式前面一定大于后面也就是說交叉熵函式值越小兩個模型越接近,
剩下的就是我們要把交叉熵應用到神經網路里面
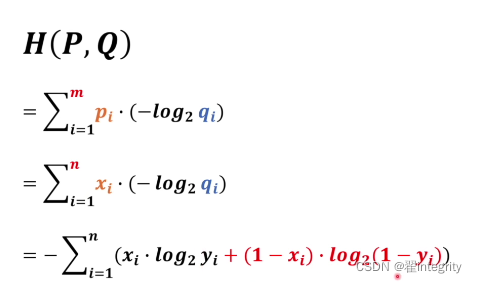
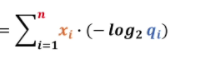
在這里面xi 有兩種情況一種是貓一種不是貓,yi 則表示有多像貓有很多情況,
交叉熵函式的n就定義為兩個不同系統當中變數更多的那一個,
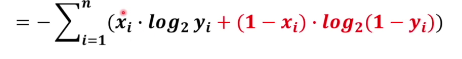
把m換成n,n就是訓練用的圖片個數,xi就是訓練用的圖片打的標簽是貓或者不是貓,yi代表的就是有多像貓所以xi要跟yi對應起來當xi等于0的時候,yi就是有多像貓,當xi等于0的時候,yi代表有多不像貓,
2 交叉熵函式的應用分析
2.1 交叉熵函式單分類問題應用
被分類物體只能歸屬于唯一一個類別;
該物體的所有類別預測概率之和為1,
二分類問題就是比如說今天小丁打王者農藥與不打王者農藥兩種選擇那么公式簡化為
*loss=–[y*log 2^a+(1- y)log2^(1-a)]
打農藥標簽值為1,不打則為0.根據小丁以往的表現今天打農藥的概率為0.7,然后事實證明今天她打農藥了那么真實值為1,
那么通過計算loss值為loss= -[1*log 2^0.7+(1- 1)*log2^(1-0.7)]**=-log 2^0.7
| 序號 | 事件 | 概率p |
|---|---|---|
| A | 小丁打王者 | 0.7 |
| B | 小丁不打王者 | 0.3 |
對應一個batch的為 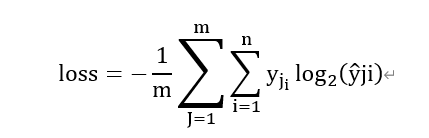
2.2交叉熵在多分類問題中的使用
多分類任務中,被分類物件可以擁有多個標簽,例如圖二的標簽為狗、貓,此時每個類別之間相互獨立,
這里的多類別是指,每一張影像樣本可以有多個類別,比如同時包含一只貓和一只狗,和單分類問題的標簽不同,多分類的標簽是n-hot,
| 豬 | 貓 | 狗 | |
|---|---|---|---|
| 標簽 | 1 | 1 | 0 |
| 概率 | 0.1 | 0.7 | 0.8 |
值得注意的是,這里的Pred不再是通過softmax計算的了,這里采用的是sigmoid,將每一個節點的輸出歸一化到[0,1]之間,所有Pred值的和也不再為1,換句話說,就是每一個Label都是獨立分布的,相互之間沒有影響,所以交叉熵在這里是單獨對每一個節點進行計算,每一個節點只有兩種可能值,所以是一個二項分布,前面說過對于二項分布這種特殊的分布,熵的計算可以進行簡化,同樣的,交叉熵的計算也可以簡化,即
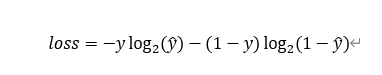
loss豬=-1log 2^0.1
loss貓=-1log2^0.7
loss狗=-1*log2^0.2
loss=loss貓+loss狗+loss豬
所以每一個batch的loss就是
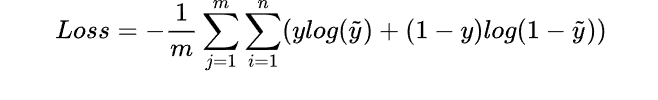
這里log是以2為底(問題不大)
式中m為當前batch中的樣本量,n為類別數,
單分類時,每張圖片的損失是一個交叉熵,交叉熵針對的是所有類別(所有類別概率和是1), 多分類時,每張圖片的損失是N個交叉熵之和(N為類別數),交叉熵針對的是單個類別(單個類別概率和是1),
2.3學習程序與優缺點
交叉熵損失函式經常用于分類問題中,特別是在神經網路做分類問題時,也經常使用交叉熵作為損失函式,此外,由于交叉熵涉及到計算每個類別的概率,所以交叉熵幾乎每次都和sigmoid(或softmax)函式一起出現,
我們用神經網路最后一層輸出的情況,來看一眼整個模型預測、獲得損失和學習的流程:
神經網路最后一層得到每個類別的得分scores(也叫logits);
該得分經過sigmoid(或softmax)函式獲得概率輸出;
模型預測的類別概率輸出與真實類別的one hot形式進行交叉熵損失函式的計算,
學習任務分為二分類和多分類情況,我們分別討論這兩種情況的學習程序,
2.3.1二分類情況

如上圖所示,求導程序可分成三個子程序,即拆成三項偏導的乘積: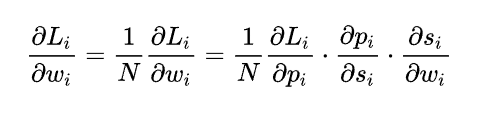
計算第一項:
pi 表示樣本i預測為正類的概率
yi為符號函式,i樣本為正類時取1 ,否則取0 ;
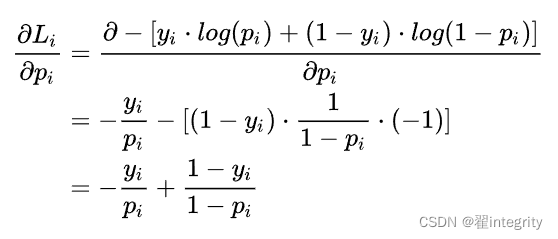
計算第二項:
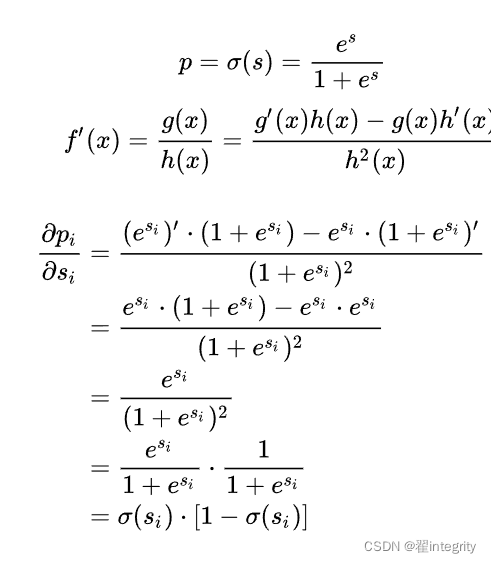
計算第三項:
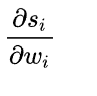
一般來說,scores是輸入的線性函式作用的結果,所以有:
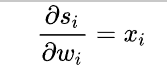
計算結果:
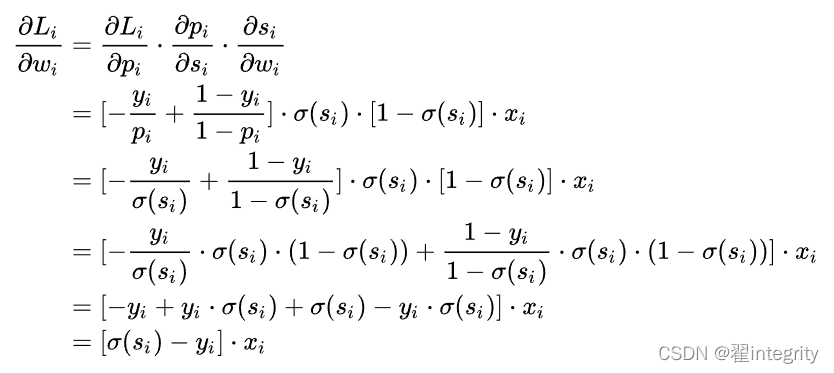
2.3.2優缺點
2.3.1.2優點
在用梯度下降法做引數更新的時候,模型學習的速度取決于兩個值:一、學習率;二、偏導值,其中,學習率是我們需要設定的超引數,所以我們重點關注偏導值,從上面的式子中,我們發現,偏導值的大小取決于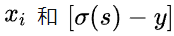
,我們重點關注后者,后者的大小值反映了我們模型的錯誤程度,該值越大,說明模型效果越差,但是該值越大同時也會使得偏導值越大,從而模型學習速度更快,所以,使用邏輯函式得到概率,并結合交叉熵當損失函式時,在模型效果差的時候學習速度比較快,在模型效果好的時候學習速度變慢,
2.3.1.3缺點
Deng [4]在2019年提出了ArcFace Loss,并在論文里說了Softmax Loss的兩個缺點:1、隨著分類數目的增大,分類層的線性變化矩陣引數也隨著增大;2、對于封閉集分類問題,學習到的特征是可分離的,但對于開放集人臉識別問題,所學特征卻沒有足夠的區分性,對于人臉識別問題,首先人臉數目(對應分類數目)是很多的,而且會不斷有新的人臉進來,不是一個封閉集分類問題,
另外,sigmoid(softmax)+cross-entropy loss 擅長于學習類間的資訊,因為它采用了類間競爭機制,它只關心對于正確標簽預測概率的準確性,忽略了其他非正確標簽的差異,導致學習到的特征比較散,基于這個問題的優化有很多,比如對softmax進行改進,如L-Softmax、SM-Softmax、AM-Softmax等,
https://www.bilibili.com/video/BV15V411W7VB?from=search&seid=776334875013814966&spm_id_from=333.337.0.0
https://blog.csdn.net/tsyccnh/article/details/79163834
https://zhuanlan.zhihu.com/p/95386061
總結
以上就是今天要講的內容,本文僅僅簡單介紹了熵,資訊量,相對熵的概念,以及應用分析希望大家多多交流共同學習!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401542.html
標籤:AI
上一篇:pandas使用insert函式將dataframe特定資料列移動到第一列實戰:Move a Column to First Position
下一篇:Birch演算法介紹