閉源軟體中復用開源組件檢測
組件復用型漏洞
定義:因復用含有漏洞的組件(第三方庫、開源框架等)而引入的軟體漏洞
現有檢測方法:

組件復用型漏洞的檢測
核心技術: 閉源二進制軟體的開源組件復用檢測

對于源代碼與二進制代碼間的復用檢測受到復雜的復用關系影響,即檢測復用時對簡單的復用可能有用,如zlib.dll與zlib庫,而對多層呼叫就失去了效果,
主要用到的方法如下:

因此,識別問題不僅僅時簡單的代碼相似性檢測問題,需要識別復雜關系,因此,復用檢測的作業變成了流行的代碼相似性檢測+復用關系識別:
現有作業準確率不高的原因:
- 沒有符號資訊,完全依賴于代碼特征比對
- 使用的代碼特征太少,很多代碼無法提取到有效特征
原因:代碼特征普遍受編譯優化影響大,無法使用 - 沒有考慮復雜復用情況,從而引入大量誤報漏報
解決方案:
- 補充抗編譯優化的代碼特征,并為新特征設計合理的匹配演算法和權重演算法
- 對復用型別進行劃分,針對不同型別進行針對性識別
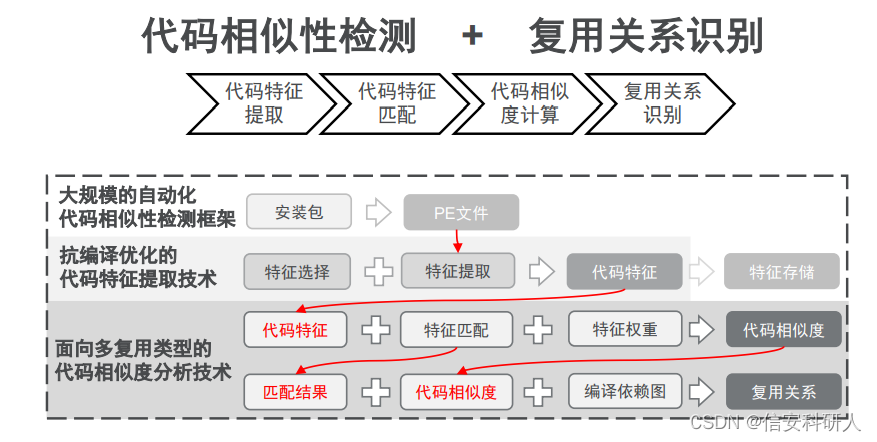
1、代碼特征選擇
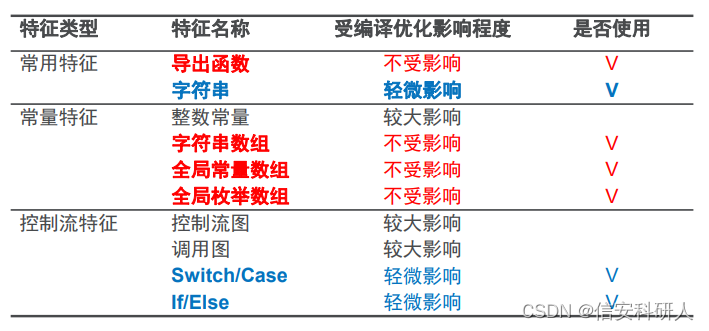
常用代碼特征與新增代碼特征評估:
2、代碼特征提取
二進制代碼特征提取方法:基于IDAPython提取匯出函式、字串、switch/case、if/else
結合編譯資訊的源代碼特征提取方法:
源代碼特征提取方法:基于clang和llvm開發特征提取工具
特征所對應代碼片段:

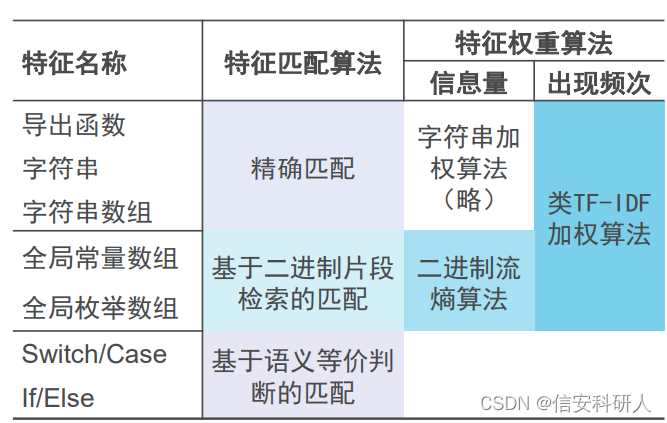
3、代碼相似度計算
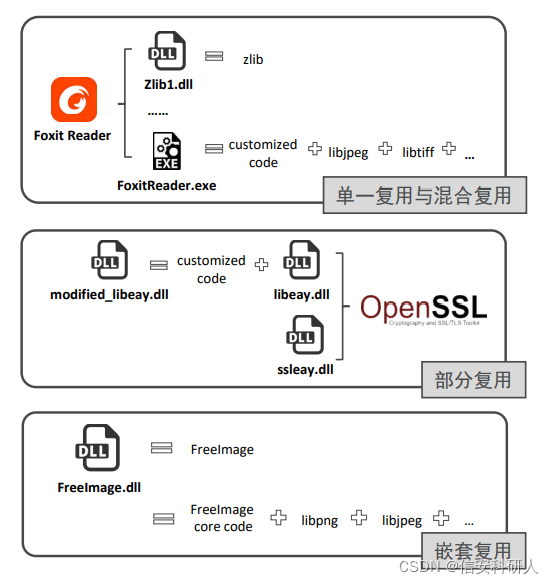
4、復用型別劃分
- 單一復用
1 bin -> 1 src
- 混合復用
1 bin -> N src
- 部分復用
N bin <- 1 src
- 嵌套復用
1 bin -> 1 src -> N src(嵌套復用是假式復用,應被去除)
閉源軟體中復用開源組件版本檢測
在檢測復用組件的基礎上,檢測復用組件的版本,因為不同版本的影響的漏洞有限
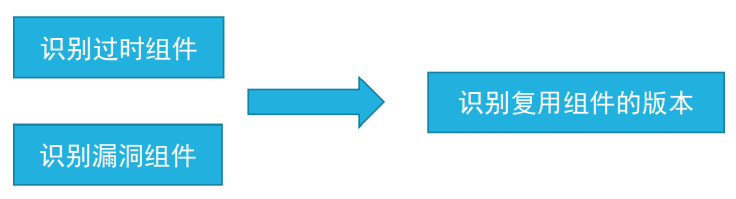
從待檢測二進制檔案中提取代碼特征,和預先準備好的從源代碼中提取的特征進行比較,現有作業如下:
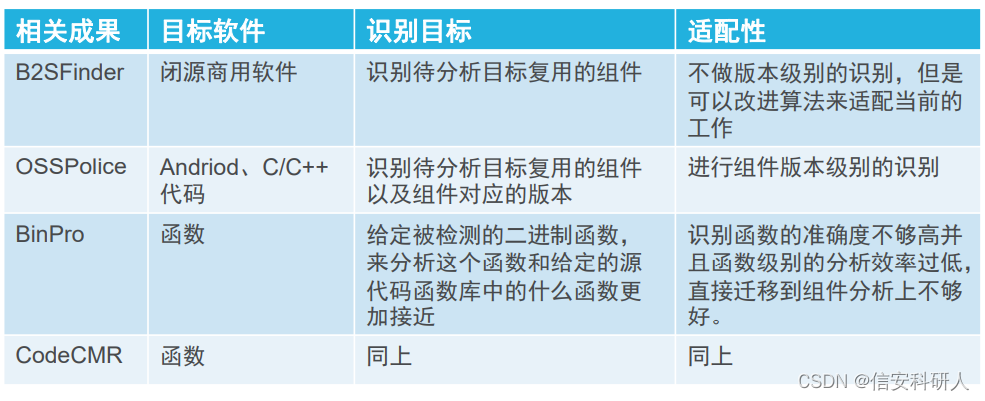
局限性:
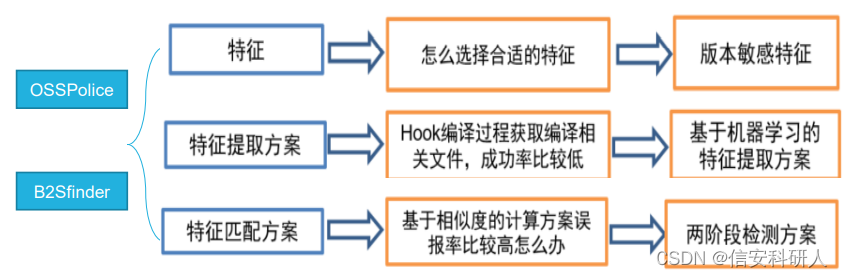
版本敏感特征選擇
選擇的核心標準:不同版本之間的區分度拉滿
全域特征:
區分度公式: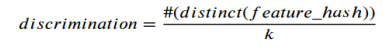
舉例如下:
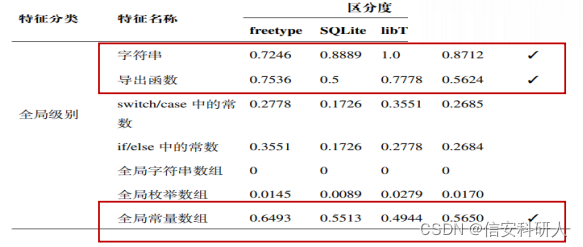
函式級別特征:

粗匹配
全域級別特征匹配方案 -> 粗匹配階段:
特征匹配方案:精準匹配——全域級別特征在編譯前后不發生變化
精匹配
函式級別特征用來定位函式,整個函式作為一個整體,所以采用基于相似度的識別方案,

具體的匹配演算法:

參考文獻
《軟體安全原理》——霍瑋
轉載請說出處:from 信安科研人

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401551.html
標籤:其他
上一篇:sql注入--時間盲注
下一篇:WEB服務器中的軟體安全