前言
本篇主要講解內部排序的八種演算法,及其中的遞回實作以及非遞回實作方法,并對各種演算法進行性能測驗,分析出對于不同資料性質最優的排序演算法選擇方式,并詳細闡述每一種演算法的代碼設計思路,
演算法的測驗程式
使用TestOP函式對排序演算法進行測驗,
其基本原理為:1.向排序演算法中輸入相同的多的資料,
2.利用clock()函式標記排序演算法的始末時間,然后作差,
void TestOP()
{
srand(time(0));
const int N = 100000;//輸入十萬個資料進行排序
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();//記錄每一個演算法的始末時間
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
printf("InsertSort:%d\n", end1-begin1);//對始末時間作差得到演算法執行時間
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
我們可以先看一看效果:
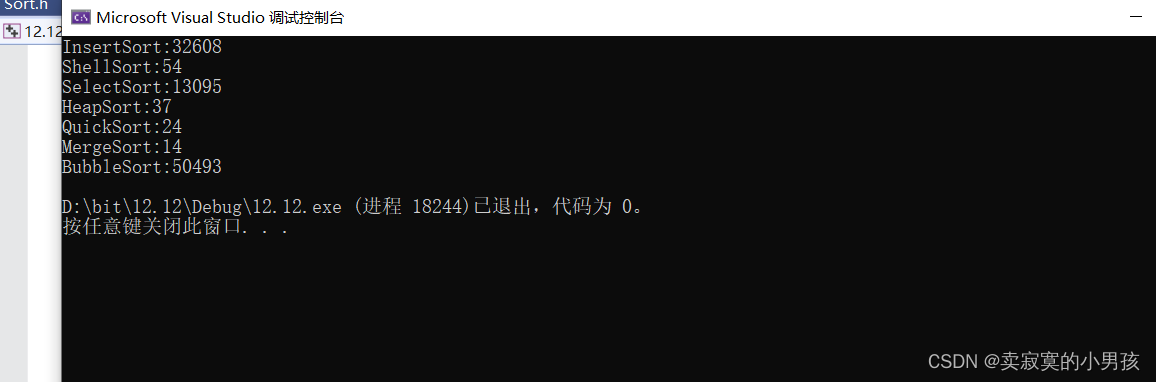
我輸入的十萬個數字進行排序,得到的結果是最優的是歸并排序,最差的是冒泡排序,
注意這里的排序演算法比較的均為比較排序演算法,在演算法設計與分析專欄中分治法那一篇文章已經證明了:在比較排序演算法中時間復雜度最低為O(nlgn),
而計數排序的復雜度可以達到O(n),但也有它的缺點和使用條件,
下面來詳細分析這幾個演算法,
以從小到大排序為例
直接插入排序
排序方式
將每次待排序的資料插入之前已經排序好的資料中,
設計思路
1.首先使用for回圈陳述句,得到待排序的資料,
2.將待排序資料與前面已經排序好的資料依次向前比較,若待排序的資料較小,則兩者交換位置,否則退出回圈,
代碼實作
void InsertSort(int* a, int n)
{
assert(a);
int i;
for (i = 0; i < n - 1; i++)//外層回圈次數
{
int end = i;
while (end >= 0)
{
int x = a[end + 1];//end+1記錄要進行插入的元素
if (x < a[end])
{
Swap(&a[end+1], &a[end]);//將end與end+1進行比較
end--;
}
else
{
break;//否則退出回圈
}
}//內層回圈的兩個截止條件
}
}
希爾排序
排序方式
希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序,
設計思路
1.一層回圈控制gap的值從n開始到1為止的變化,每次n/2,
2.一層回圈控制對于每一個gap的值,需要插入資料的個數,
3.一層回圈找到待排序的資料,(每個待排序的資料之間相差gap)
4.將待排序的資料插入到已經排好序的序列中,
代碼實作
void ShellSort(int* a, int n)
{
int gap = n;
while (gap >= 1)//gap的回圈次數
{
gap = gap / 2;
int i,j;
for (i = 0; i < gap; i++)//外層回圈次數
{
for (j = i; j < n - gap; j = j + gap)//內層回圈次數
{
int end = j;
while (end >= 0)
{
if (a[end] > a[end + gap])
{
Swap(&a[end], &a[end + gap]);
end = end - gap;//與之相差gap距離的數字進行比較
}
else
{
break;
}
}
}
}
}
}
選擇排序
排序方式
每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾,
設計思路
1.定義首尾兩個指標分別為begin,end
2.遍歷從begin到end的資料,從中選擇最小值與begin處的資料交換,最大值與end處的資料交換,
3.begin++,end–重復上述程序,直到begin>=end,
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (end >= begin)//定義回圈次數
{
int maxi=a[end];
int mini= a[begin];
int i;
for (i = begin; i <= end; i++)//每次選擇最大最小值
{
if (a[i] < mini)
{
mini = a[i];
Swap(&a[begin], &a[i]);//最小值放在陣列首
}
if (a[i] > maxi)
{
maxi = a[i];
Swap(&a[end], &a[i]);//最大值放在陣列尾
}
}
begin++;
end--;
}
}
堆排序
排序方式
利用堆這種資料結構所設計的一種排序演算法,
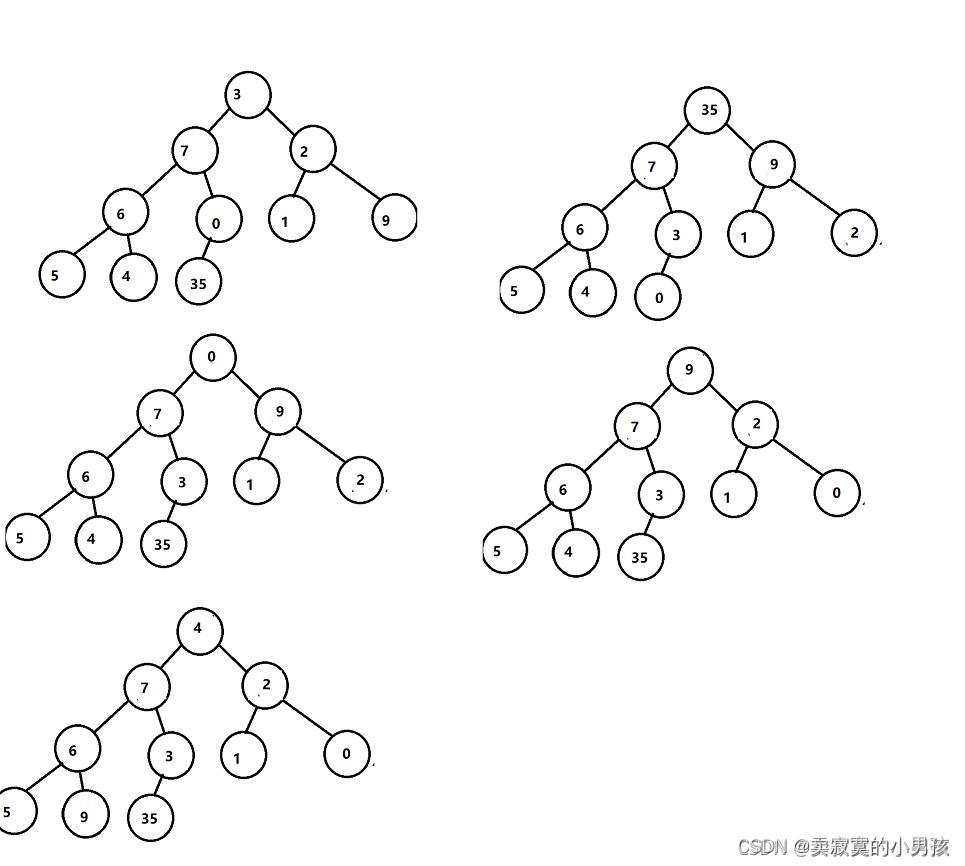
設計思路
堆排序一共分為兩步:
1.對所有有子節點或者子樹的節點進行從左向右,從上向下進行向下調整,**向下調整的本質是找出一棵最小二叉樹中節點的最大值,**所以最后調整之后建立了一個堆,堆頂點是這組數的最大值,
2.交換堆頂點與最后一個元素,在堆中對最后一個元素進行向下調整(不包含最后一個元素),【這里和洗掉時一樣的】,從而找出次大的數,
代碼實作
void Adjustdown(int * a, int n, int parent) //向下調整演算法
{
assert(a);
int child = 2 * parent + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] > a[child])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
int i;
for (i = (n - 2) / 2; i >= 0; i--)
{
Adjustdown(a, n, i);
}
for (int end = n - 1; end > 0; --end)
{
Swap(&a[end], &a[0]);
Adjustdown(a, end, 0);
}
}
冒泡排序
排序方法
它重復地走訪過要排序的元素列,依次比較兩個相鄰的元素,如果順序(如從大到小、首字母從Z到A)錯誤就把他們交換過來,走訪元素的作業是重復地進行直到沒有相鄰元素需要交換,也就是說該元素列已經排序完成, 這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端(升序或降序排列),就如同碳酸飲料中二訊訓碳的氣泡最侄訓上浮到頂端一樣,故名“冒泡排序”,
設計思路
1.一層回圈判斷要執行幾次操作(為n-1次),
2.一層回圈進行兩兩比較并交換,
當陣列已經有序時,不需要再遍歷許多次,可以定義flag變數來記錄陣列是否已經有序,有序則退出回圈,
代碼實作
void BubbleSort(int* a, int n)
{
int i, j;
for (i = 0; i < n - 1; i++)//回圈n-1次,即找到n-1個最大的數
{
int flag = 1;
for (j = 0; j < n - i - 1; j++)//對相鄰的兩個數進行比較
{
if (a[j + 1] < a[j])
{
Swap(&a[j + 1], &a[j]);
flag = 0;
}
}
if (flag)
{
break;
}
}
}
快速排序
快速排序是最重要的排序演算法,實作它有好多種方式,我們通常使用遞回來實作它,
設計方法
1.選出一個大小適中的元素,放在陣列首元素位置,
2.選擇一種快速排序演算法,并回傳一個可遞回資料,
3.進行遞回,
選擇大小適中的元素
為了保證時間復雜度,我們不能遍歷所有的資料,然后找出中間值,所以我們取首,中,尾三個元素的中間值作為該大小適中的元素,
int GetMid(int* a, int left,int right)
{
int mid = (left+right) / 2;
if (a[left] > a[right])
{
if (a[left] < a[mid])
{
return left;
}
else if (a[right] > a[mid])
{
return right;
}
else
{
return mid;
}
}
else//left<right
{
if (a[right] < a[mid])
{
return right;
}
else if (a[mid] < a[left])
{
return left;
}
else
{
return mid;
}
}
}
選擇快速排序演算法
三種演算法各有優劣,推薦選擇第三種,
Partition1(Hoare版:初代)
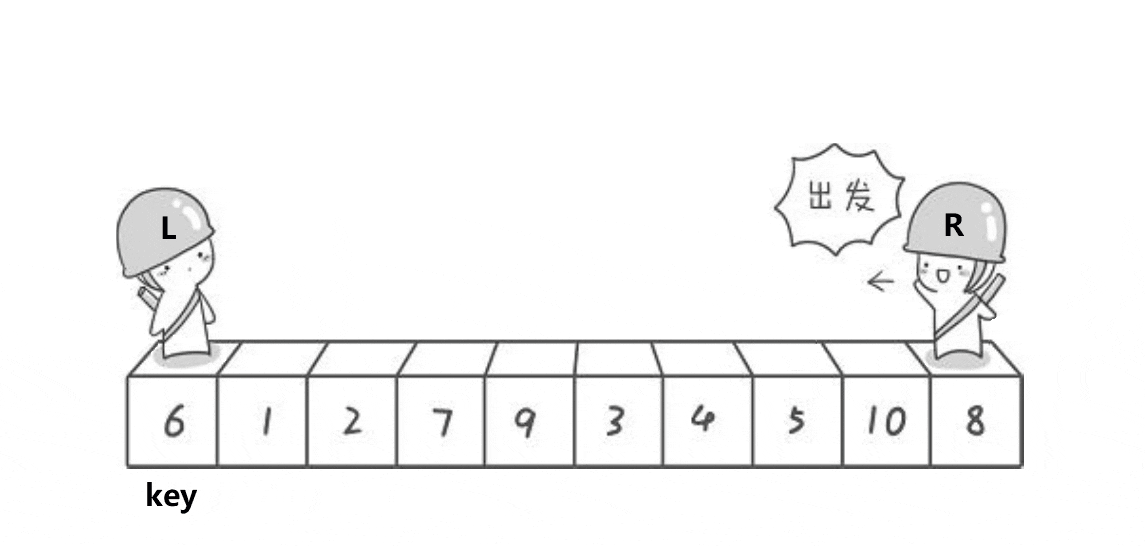
設計方法
1.首先將選擇的中間值放在陣列首元素的位置,
2.定義兩個指標left和right,分別從左向右,從右向左走,
3.當left遇到比中間值大的元素的時候停下來,當right遇到比中間值小的元素停下來,
4.交換left與right的元素,
5.當left>=right的時候停下來,將中間值(第一個元素)與left互換位置,
6.回傳新的right和right,
本質上每一次遞回都將中間值大的元素放在中間值的后面,比中間值小的元素放在中間值左邊,即找到中間值在排好序的陣列中的位置,
代碼實作
int PartSort1(int* a, int left,int right)
{
int mini = GetMid(a,left,right);
Swap(&a[mini], &a[left]);//找到中間值并放在陣列首元素的位置,
int keyi = left;
while (right > left)
{
while (left < right && a[right] >= a[keyi])
right--;
while (left < right && a[left] <= a[keyi])
left++;
Swap(&a[left], &a[right]);//交換兩者的元素
}
Swap(&a[keyi], &a[left]);//交換中間值與左指標指向的元素
return left;
}
Partition2(挖坑法)
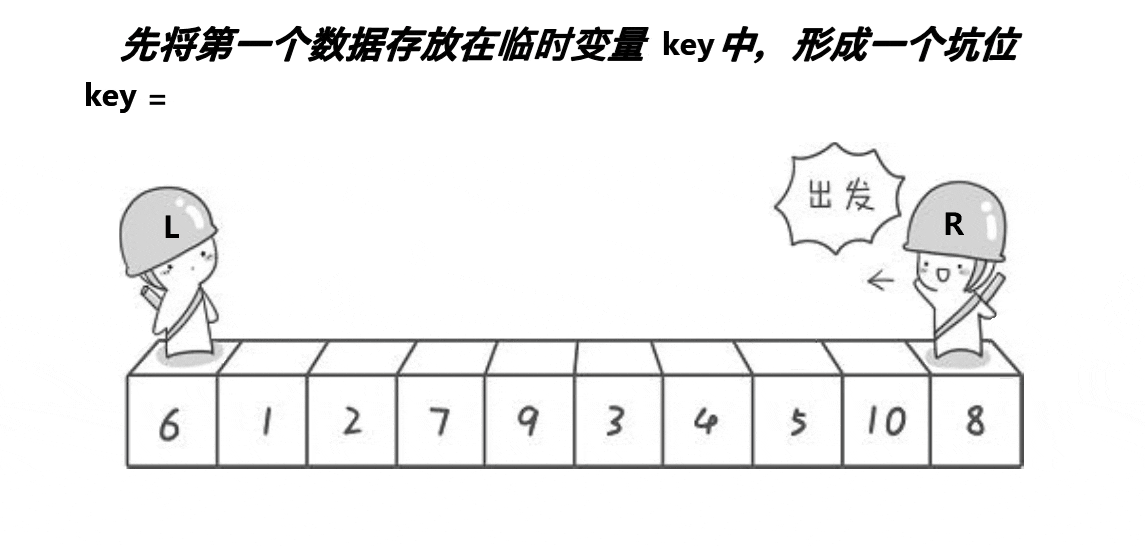
設計方法
與初代版本相似,也是定義兩個相向移動的指標,
1.將中間值與陣列中第一個元素交換位置,此時認為第一個元素空缺即形成一個坑,
2.right指標向前移動,找到比中間值小的元素填入坑內,此時right所指向的位置形成了一個坑,
3.left指標向后移動,找到比中間值大的元素填入坑內,此時left所指向的位置形成了坑,
4.重復上述程序直到left>=right,此時講中間值填入坑內,
5.回傳新的right與left進行遞回,
代碼實作
int PartSort2(int* a, int left, int right)
{
int mini = GetMid(a, left, right);
Swap(&a[mini], &a[left]);
int key = a[left];
int pivot = left;//定義起始坑的位置
while (left < right)
{
while (left < right && a[right] >= key)
{
--right;
}
a[pivot] = a[right];
pivot = right;//將右指標的元素填入坑內,同時改變坑的位置
while (left < right && a[left] <= key)
{
++left;
}
a[pivot] = a[left];
pivot = left;
}
a[pivot] = key;
return pivot;//通過坑的位置尋找新的right和left
}
Partition3(前后指標法)
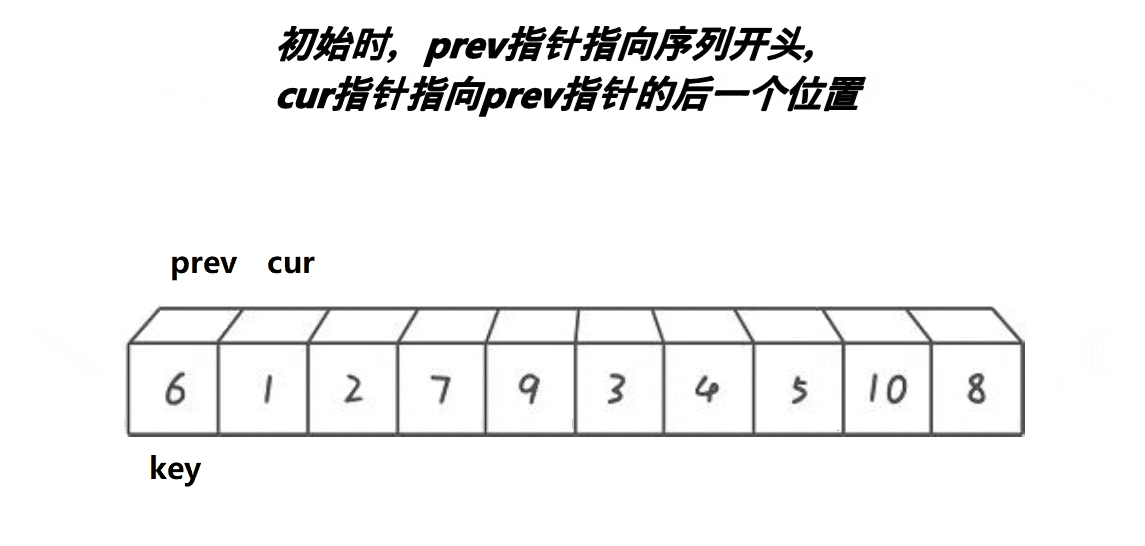
設計方法
與前兩種方法的區別是,定義的兩個指標是同向的,
1.將中間值放在陣列首元素的位置,
2.定義指標prev和cur,prev為陣列首元素的位置,cur為prev下一個元素的位置,
3.當cur位置的元素小于中間值,且prev+1!=cur時,prev++,然后交換prev與cur處的值,直到cur越界
4.交換中間值與prev處的值,
代碼實作
int PartSort3(int* a, int left, int right)
{
int mini = GetMid(a, left, right);
Swap(&a[left], &a[mini]);
int prev = left;
int cur = prev + 1;//定義cur與prev的起始位置
while (cur <= right)
{
if (a[cur] < a[left] && ++prev != cur)//當cur處的值小于中間值時,prev++,注意&&的性質
{
Swap(&a[cur], &a[prev]);//交換cur與prev處的值
}
cur++;
}
Swap(&a[prev], &a[left]);
return prev;
}
進行遞回
遞回程式的設計模式是:首先寫出遞回終止條件,然后利用遞回函式寫最后一次遞回,使用宏觀思維,
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;//遞回終止條件
}
int keyi = PartSort2(a, left, right);
//int keyi = PartSort3(a, left, right);
QuickSort(a, left, keyi-1);//將keyi之前的資料排序
QuickSort(a, keyi + 1, right);//將keyi之后的資料排序
}
歸并排序
遞回實作
設計方法
這是一個遞回的程式,需要使用遞回函式的設計方法,
1.寫出遞回的終止條件,
2.從陣列中中間的元素劃分開,進行歸并,
3.進行最后一次歸并排序,
定義四個指標分別指向要歸并陣列的首元素和尾元素,依次進行比較,挑出每次比較的最小值放在一個新的陣列中,移動首指標,最后將多余的元素一并存入陣列中,
代碼實作
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
{
return;//遞回終止條件
}
int mid = (right + left) / 2;//獲取中間值作為分隔
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);//將中間值前面資料與后面資料分別進行歸并
int begin1 = left,end1=mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];//比較后將較小值先存入tmp陣列中
}
}
if (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
if (begin2 <= end2)
{
tmp[i++] = a[begin2++];//將剩余元素存入tmp陣列中
}
int j;
for (j = left; j <= right; j++)
{
a[j] = tmp[j];//將tmo陣列中的元素拷貝到a陣列中
}
}
但是在書寫代碼的時候,一般不會傳入首尾指標位置,通常只給一個陣列大小,所以需要一個輔助代碼來幫助實作功能,用于得到right與left
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);//獲取left,right的值
free(tmp);
tmp = NULL;
}
非遞回實作
設計思路
1.定義gap表示歸并排序的每組資料數,定義一個回圈用于記錄gap的值的變化,
2.用[begin1,end1],[begin2,end2],表示兩個要進行歸并排序的組,并進行歸并排序,
3.注意邊界問題的討論,
其中begin1,end1,begin2,end2的值由gap決定,
代碼實作
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc failed");
exit(-1);
}
int gap = 1;
int i;
while (gap < n)
{
int j = 0;
for (i = 0; i < n; i += 2*gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;//找到要進行歸并的兩組資料
if (end1 > n || begin2 > n)
{
break;//當end1或者begin2越界的時候退出回圈,不需要進行歸并
}
if (end2 > n)
{
end2 = n - 1;//當end2越界的時候需要進行排序,改變end2的位置
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
if (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
if (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
for (j = i; j <= end2; j++)
{
a[j] = tmp[j];//每一次歸并排序后都更新一次a中的資料
}
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
計數排序
與前幾種比較排序不同,計數排序的復雜度可以達到O(N)
排序方法
計數排序是一個非基于比較的排序演算法,該演算法于1954年由 Harold H. Seward 提出,它的優勢在于在對一定范圍內的整數排序時,它的復雜度為Ο(n+k)(其中k是整數的范圍),快于任何比較排序演算法,
設計方法
1.找出資料中最大數max與最小數min,將最小數等價為0,將最大數等價為max-min,其他值均等價為x=x-min,
2.建立一個大小為max-min的陣列,初始化為0,遍歷原陣列的等價值,當新建陣列的下標與其等價值相等時,對該下標下的陣列內容++,
3.通過新建陣列即可得到排序,
代碼實作
void CountSort(int* a, int n)
{
int min=a[0];
int max = a[0];
int i = 0;
for (i = 0; i < n; i++)
{
if (min > a[i])
{
min = a[i];
}
if (max < a[i])
{
max = a[i];
}
}
int size = max - min + 1;
int* tmp = (int*)malloc(sizeof(int) * (size));//建立max-min大小的陣列
if (tmp == NULL)
{
printf("malloc failed\n");
exit(-1);
}
memset(tmp, 0, sizeof(int)*size);//將新陣列的內容均置為0
for (i = 0; i < n; i++)
{
tmp[a[i] - min]++;//當i=a[i]的時候對tmp中值++
}
int j = 0;
for (i = 0; i < size; i++)
{
while (tmp[i]--)
{
a[j++] = i + min;//將資料拷入a中
}
}
}
排序的時間復雜度的比較
穩定與不穩定是指,當資料相同時,假如有兩個5,在a中的順序是5在5’的前面,如果排序之后5仍然在5’的前面,那么就說明這個排序是穩定的,否則排序不穩定,
| 排序方法lonely | 平均情況little | 最好情況boy | 最壞情況write | 輔助空間 | 穩定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 穩定 |
| – | – | – | – | – | – |
| 選擇排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不穩定 |
| – | – | – | – | – | – |
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 穩定 |
| – | – | – | – | – | – |
| 希爾排序 | O(nlogn)~O(n^2) | O(n^1.3) | O(n^2) | O(1) | 不穩定 |
| – | – | – | – | – | – |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不穩定 |
| – | – | – | – | – | – |
| 歸并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 穩定 |
| – | – | – | – | – | – |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | O(logn)~O(n) | 不穩定 |
總結
排序演算法有很多,這里總結了常用的八種內部排序的演算法,其實比較排序的本質就是逐漸擴大有序數列的程序,而計數排序的復雜度取決于資料的分布情況,
在不同的情況下需要靈活使用或者結合,比如快速排序中使用了大量的遞回,時間較長,在初期可以使用其他排序演算法處理較少次遞回處理的內容,到后期再使用快速排序來處理,根據實際情況靈活結合這些排序演算法,從而達到最短時間的目的,
如果這篇文章對你有幫助別忘了三連啊,一個懂得三連的人,一定是一個高尚的人,一個純粹的人,一個有道德的人,一個脫離了低級趣味的人,一個有益于人民的人,
加油,共勉!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/401637.html
標籤:其他