目錄
0. 前言
1. 為什么可以用預訓練模型?
1.1 特征提取
1.2 模型微調
2. 加載預訓練模型
3. 特征提取
4. 訓練以及評估
4.1 訓練
4.2 loss和accuracy曲線
4.3. 在測驗集進行模型性能評估
5. 小結
0. 前言
本文(以及接下來的幾篇)介紹如何搭建一個卷積神經網路用于影像分類的深度學習問題,尤其是再訓練資料集比較小的場合,通常來說,深度學習需要大量的資料進行訓練,尤其是像在影像處理這種通常資料維度非常高的場合,但是當你沒有一個足夠大的資料集進行訓練的時候應該怎么辦呢?
解決訓練資料集太小的方法通常有兩種:
(1) 使用資料增強策略
(2) 使用預訓練模型
前面兩篇我們分別進行了在不用資料增強和用資料增強技術的條件下在一個小資料集上訓練一個小的卷積神經網路,采用資料增強可以獲得相當程度的改善,但是由于原始資料集畢竟太小,所以很難達到90%的預測準確度,
本文我們將考慮如何在(已經在大資料集上訓練過的)預訓練模型的基礎上,在小資料集上進一步訓練得到最終模型的效果,
本文中將略去資料下載和預處理,相關細節請參考前面兩篇,
深度學習筆記:在小資料集上從頭訓練卷積神經網路![]() https://blog.csdn.net/chenxy_bwave/article/details/122260520
https://blog.csdn.net/chenxy_bwave/article/details/122260520
深度學習筆記:利用資料增強在小資料集上從頭訓練卷積神經網路![]() https://blog.csdn.net/chenxy_bwave/article/details/122276708
https://blog.csdn.net/chenxy_bwave/article/details/122276708
1. 為什么可以用預訓練模型?
換句話說,為什么預訓練模型會有效?
預訓練網路(pre-trained)是指一個之前在大型資料集(通常是大規模影像分類任務)上訓練并保存好的網路模型,如果這個原始資料集足夠大且足夠通用,那么預訓練模型學到的特征的空間層次結構可以有效地作為視覺世界的通用模型,因此這些特征可用于各種不同的計算機視覺問題,即時這些新問題涉及的類別和原始問題完全不同,舉個例子,你在ImageNet(其類別主要是動物和日常用品)上訓練了一個模型,然后將這個訓練好的模型應用于某個不相干的任務,比如說在影像中識別家具,這種學到的特征在不同問題之間的可移植性,是深度學習與許多早期淺層學習方法相比的重要優勢,它使得深度學習對小資料問題也能夠做到非常有效,
使用預訓練模型有兩種方法:
(1) 特征提取: feature extraction
(2) 模型微調: fine-tuning
本文先做關于特征提取的實驗,模型微調將留到下一篇討論,
1.1 特征提取
特征提取就是使用預訓練模型學到的表示來從新樣本中提取出感興趣的特征,然后將這些特征輸入一個新的分類器,從頭開始訓練,
一個用于影像分類的卷積神經網路通常包含兩部分,第一部分是一系列卷積層和池化層,通常稱為卷積基(convolutional base, 簡記為convbase);第二部分就是最后連接的密集連接分類器,
對于卷積神經網路而言,特征提取就是用卷積基對新資料進行處理,生成新資料的特征表示,然后再基于這些所提取的特征去訓練一個新的分類器,
為什么僅重復使用卷積基呢?原因在于卷積基學到的表示更有通用性,因此更適合于重復使用,卷積神經網路的特征圖表示通用概念在影像中是否存在,無論面對什么樣的計算機視覺問題,這種特征圖都可能有用,而最后的分類器學到的表示必然是針對有模型訓練的類別,其中僅包含某個類別出現在整張影像中的概率資訊,比如說,從貓狗分類中學習到的表示資訊不太可能對于家具分類有什么幫助,但是不管是貓狗的影像還是家具的影像,都會有邊緣啊、條紋啊之類的東西,此外,密集連接層的表示不再包含物體在輸入影像中的位置資訊,它舍棄了空間概念,物體的位置資訊再卷積特征圖中有描述,如果物體位置對于問題很重重要,那么密集連接層的特征在很大程度上是無用的,
進一步,卷積神經網路中不同的卷積層所學習到的表示的通用性也是不同的,通常來說,處于模型的前級的層提取的區域的有更高通用性的特征圖(比如,邊緣,顏色,紋理等等),而靠后的卷積層提取的是更加抽象的概念(比如說‘貓耳朵’、‘狗眼睛’等等),因此,如果你的新資料與原始資料有很大的差異,那么最好只使用卷積基的前面基層來做特征提取,比如說如果你是在貓狗資料集上訓練出的模型,想要用作預訓練模型用于家具分類識別,后級卷積層所提取的整體的、抽象的特征(比如說‘貓耳朵’、‘狗眼睛’等等)對于家具分類顯然沒有什么意義,
1.2 模型微調
參見后續篇章,
2. 加載預訓練模型
在這個例子中我們將使用在ImageNet上訓練的VGG16網路的卷積基從貓狗影像資料集中提取特征,然后用于訓練一個貓狗分類器,
由于ImageNet資料集中也包含了很多貓和狗的圖片,所以可以直接使用VGG16網路進行貓狗影像資料集的影像分類其實是可以的,但是出于本文的演示目的,我們只使用VGG16的卷積基,
在keras中內置了很多卷積神經網路的經典模型(其實也就是過去不到十年的事情,但是深度學習發展過于迅速,幾年的時間已經使得當年的新模型成為今天的經典,當然在這個加速發展的世界里,成為經典意味著它的性能可能已經遠遠落后與SOTA模型,只是它的思想被傳承下去了),如下所示:
(1) Xception
(2) Inception X3
(3) ResNet50
(4) VGG16
(5) VGG19
(6) MobileNet
以下VGG16模型實體化中,將include_top置為False,意思就是剔除最頂層(即最終的密集分類層),weights指定模型初始化的權重檢查點,input_shape則指定輸入資料形狀,可以不指定,不指定的話,可以處理任意形狀的輸入,
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import utils
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
print(tf.__version__)
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
conv_base.summary()

3. 特征提取
以下我們同樣先實體化生成ImageDataGenerator物件,然后分別生成訓練集、驗證集和測驗集的資料生成器,這里我們先不考慮資料增強(step-by-step地累進式地前進有助于我們看清楚每一個技術要素所發揮的作用),然后利用以上加載的VGG16的conv_base提取這些資料集中的特征,
# Data generators
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
train_dir = os.path.join('F:\DL\cats_vs_dogs_small', 'train')
test_dir = os.path.join('F:\DL\cats_vs_dogs_small', 'test')
train_datagen = ImageDataGenerator(rescale=1./255,validation_split=0.3)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='training',
shuffle=True,
seed=42
)
valid_generator = train_datagen.flow_from_directory(
directory=train_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode="binary",
subset='validation',
shuffle=True,
seed=42
)
test_generator = test_datagen.flow_from_directory(
directory=test_dir,
target_size=(180, 180),
color_mode="rgb",
batch_size=batch_size,
class_mode='binary',
shuffle=False,
seed=42
)
import numpy as np
def get_features_and_labels(dataGenerator):
all_features = []
all_labels = []
k = 0
for images, labels in dataGenerator:
features = conv_base.predict(images)
all_features.append(features)
all_labels.append(labels)
k += 1
if dataGenerator.batch_size * (k+1) > dataGenerator.n:
break
print('Totally, {0}-batches with batch_size={1}'.format(k,dataGenerator.batch_size))
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_generator)
val_features, val_labels = get_features_and_labels(valid_generator)
test_features, test_labels = get_features_and_labels(test_generator)
print(train_features.shape,train_labels.shape)
需要注意的一點是,Generator是可以永遠持續地生成資料的,而并不是說輸出完一遍資料后就退出,因此需要有一個break機制,參見以上get_features_and_lables()中的break陳述句,
4. 訓練以及評估
4.1 訓練
由于這里的訓練只涉及到最后的Dense Layer,因此訓練會非常快(相比前面兩篇中從頭訓練而言),當然,由于本模型采用了VGG16的卷積基,所以在預測階段所需要的運算量是遠遠地大于前兩篇中訓練的小型卷積網路,畢竟VGG16的卷積基雖然不用重新訓練,但是預測時是需要全部參與的運算的,
from tensorflow.keras import optimizers
inputs = keras.Input(shape=(5, 5, 512)) # This shape has to be the same as the output shape of the convbase
x = layers.Flatten()(inputs)
x = layers.Dense(256,activation='relu')(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer=optimizers.RMSprop(learning_rate=2e-5),
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_features, train_labels,
epochs=32,
validation_data=(val_features, val_labels),
callbacks=callbacks)4.2 loss和accuracy曲線
import matplotlib.pyplot as plt
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Training accuracy")
plt.plot(epochs, val_accuracy, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
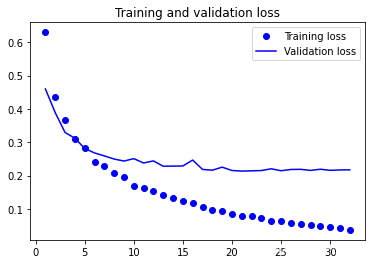
4.3. 在測驗集進行模型性能評估
print(test_features.shape,test_labels.shape)
test_model = keras.models.load_model("feature_extraction.keras")
test_loss, test_acc = test_model.evaluate(test_features,test_labels)
print(f"Test accuracy: {test_acc:.3f}")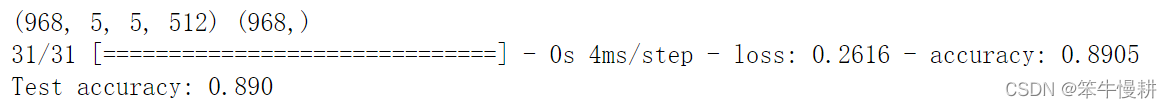
5. 小結
本文基于keras內置的VGG16做了一個基于預訓練模型的特征提取(without data augmentation)的實驗,
實驗結果表明(unsurprisingly)存在明顯的過擬合,但是相對地來看的話,在驗證集和測驗集上也分別得到了91%和89%的準確度(accuracy),而上一篇基于資料增強技術從頭開始訓練的網路只有80%出頭而已,可以說是一個巨大的進步,
接下來我們來看看,在基于預訓練模型的基礎上再加上資料增強能不能取得更好的性能呢?
Reference: Francois, Chollet: Deep Learning with Python.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402580.html
標籤:其他
上一篇:Python灰度影像彩色化
下一篇:影像處理Opencv(六)