shell編程三劍客
- grep --> egrep --> 文本過濾 查詢
- awk 文本截取
- sed 文本的替換和修改
目錄
awk
awk也可以做小數運算
awk命令簡要處理流程
awk的資料欄位變數
awk命令的基本語法
awk基本命令示例
awk用 -F 來指定分隔符separater、delimiter
awk命令的完整語法
awk命令的執行程序
awk命令的運算子
awk命令的參考shell變數
awk里的變數的傳遞問題和shell腳本的傳參問題
練習:
經典面試題
awk
- awk 是一門模式掃描和處理的語言 --> 專門進行文本截取和分析的工具
- 支持流控、正則
- gawk - pattern scanning and processing language
awk也可以做小數運算

awk命令簡要處理流程
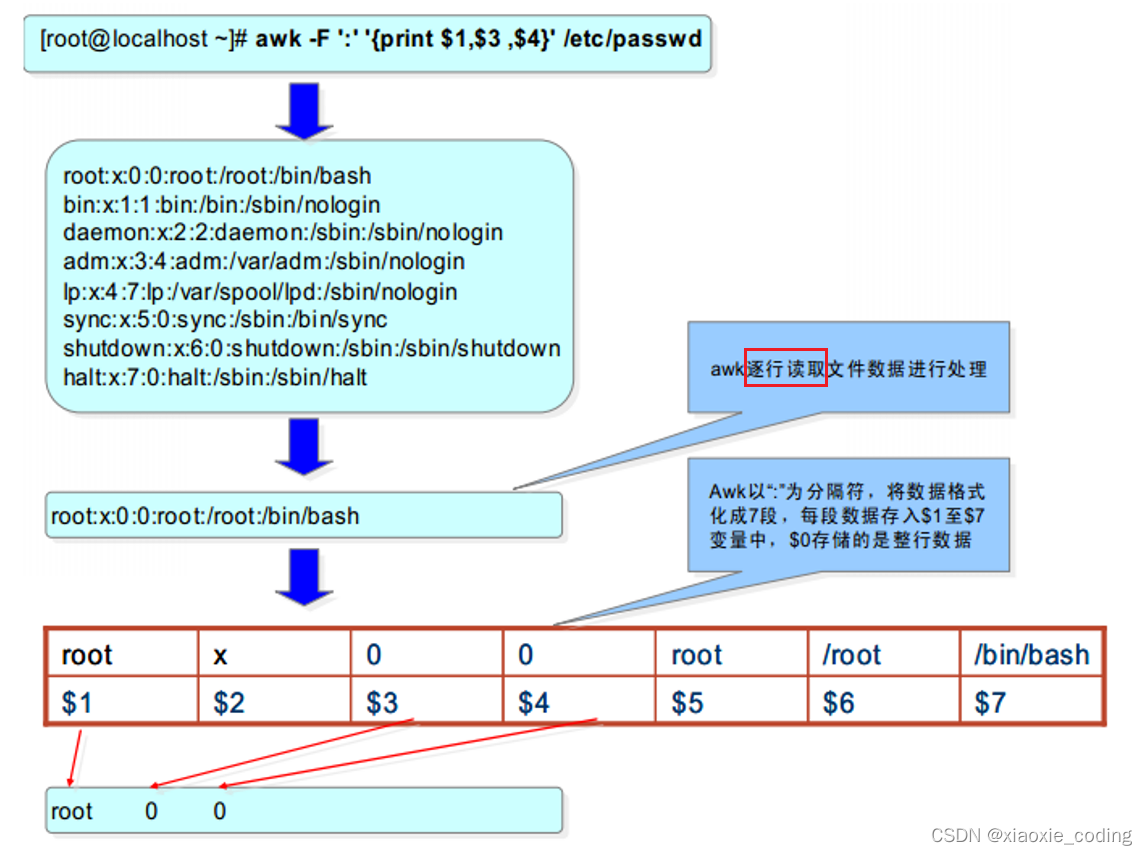
awk的資料欄位變數
- $0 表示整行文本
- $1 表示文本中第一個資料欄位
- $2 表示文本中第二個資料欄位
- $n 表示文本中第n個資料欄位
awk命令的基本語法

- awk的指令一定要用單引號引起,動作一定要用花括號括起
- 模式可以是正則運算式、條件運算式或兩種組合
- 如果模式是正則運算式要用/定界符
- 多個動作之間用;分開
- 參考自定義變數,不需要接$符號
awk基本命令示例
# 只有模式沒有動作,結果和grep一樣,顯示$0
awk '/bash/' /etc/passwd
# 只有動作沒有模式,就直接執行動作
who | awk '{print $2}'
# 以冒號為分隔符,顯示以h開頭的行的第一列和第七列
awk -F: '/^h/{print $1,$7}' /etc/passwd
# 不顯示以a或b或c開頭的行的第一列和第七列
# [^ ] 中括號里面的^表示取反,'^[^ ]'中括號外面的^表示以中括號里面的內容開頭
awk -F: '/^[^abc]/{print $1,$7}' /etc/passwd
# 以 : 或者 / 作為分隔符顯示第1列和第10列
awk -F '[:/]' '{print $1,$10}' /etc/passwd
awk用 -F 來指定分隔符separater、delimiter
- 默認的欄位分隔符是任意空白字符(空格或者TAB)
- 輸入分隔符 FS = filed separater
- 輸出分隔符 OFS = output filed separate
- [root@kafka01 yum.repos.d]# awk -F: '{print $1,$3,$5}' /etc/passwd
- 輸入分隔符是冒號 輸出分隔符默認為空格
- [root@kafka01 yum.repos.d]# awk -F: 'OFS="#"{print $1,$3,$5}' /etc/passwd
- 指定輸出符為 # 號
- , 逗號其實就是在呼叫輸出分隔符
- [root@kafka01 ~]# awk -F: 'OFS=","{print $1,$3,$5}' /etc/passwd > passwd.csv
- 方便重定向為csv檔案
- [root@kafka01 yum.repos.d]# awk -F: '{print $1" "$3"#"$5}' /etc/passwd
- 自己加分隔符
awk命令的完整語法

awk命令的執行程序
- 先執行BEGIN{commands}陳述句塊中的陳述句
- 從檔案或 stdin 中讀取第1行,
- 查看有無模式匹配(/bash/ 找有bash的行), 若無則匹配下一行,如果每行都不匹配就執行END{}中的陳述句
- 若有則檢查該整行與pattern是否匹配, 若匹配, 則執行{}中的陳述句,若不匹配則不執行{}中的陳述句,接著讀取下一行
- 重復這個程序, 直到所有行被讀取完畢
- 執行END{commands}陳述句塊中的陳述句
- 文字太繁瑣!舉例就懂啦!
[root@kafka01 1-6]# awk -F: 'BEGIN{print "~~~start~~~"} /bash/{print $1,$3} END{print "~~~end~~~"}' /etc/passwd
~~~start~~~
root 0
~~~end~~~
[root@kafka01 1-6]# awk -F: 'BEGIN{print "~~~start~~~"} /bash$/{print $1,$3} END{print "~~~end~~~"}' /etc/passwd
~~~start~~~
root 0
~~~end~~~
[root@kafka01 1-6]# awk -F: 'BEGIN{print "~~~start~~~"} /^zabbix/{print $1,$3} END{print "~~~end~~~"}' /etc/passwd
~~~start~~~
zabbix 992
~~~end~~~pattern部分每行都執行(可以使用正則),BEGIN、END部分只執行一次
[root@kafka01 1-6]# awk 'BEGIN{i=0}{i++}END{print i}' /etc/passwd # 統計檔案行數
[root@kafka01 1-6]# awk -F: '{print $1,NR}' /etc/passwd NR可以直接顯示行號- NR:number of record 顯示行號 (常用!很方便!很重要!)
- NF:number of filed 統計一行里欄位數
# 顯示用戶名,行號和最后一個欄位
[root@kafka01 1-6]# awk -F: '{print $1,NR,$NF}' /etc/passwd
# 顯示用戶名,行號和倒數第二個欄位
[root@kafka01 1-6]# awk -F: '{print $1,NR,$(NF-1)}' /etc/passwd
# 顯示3到5行
[root@kafka01 1-6]# awk 'NR==3,NR==5{print NR,$0}' /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# 顯示行號大于2的 (只顯示df -h結果的第一列檔案系統)
[root@kafka01 1-6]# df -Th|awk 'NR>=2 {print $1}'
- $NF 取最后一個欄位
awk命令的運算子
數學運算:+,-,*,/, %,++,- -
邏輯關系符:&&, ||, !
- && 比 || 的優先級要高
比較運算子:>,<,>=,!=,<=,==,~,!~
文本資料運算式:== (精確匹配)
~ 波浪號表示匹配后面的模式(模糊匹配)
如:
[root@kafka01 1-6]# who | awk '$2 ~ /pts/{print $1}'
[root@kafka01 1-6]# awk -F: '$3 ~ /\<...\>/ {print $1,$3}' /etc/passwd- \< 單詞的界定符 單詞以什么什么開頭
- \> 表示單詞以什么什么結尾
- . 點表示單個任意字符
[root@kafka01 1-6]# awk -F: '$3 ~ /[0-9]{3}/ {print $1,$3}' /etc/passwd
[root@kafka01 1-6]# awk -F: '$3 ~ /\<[0-9]{3}\>/ {print $1,$3}' /etc/passwd
[root@kafka01 1-6]# cat mobile_phone.txt | grep "\<feng"
VIVO OPPO 12345 feng@qq.com
[root@kafka01 1-6]# cat mobile_phone.txt | grep "mi\>"
xiaomi huawei XIAOMI HUAWEI
xiaomi dami
正則還支持
| \bwubing\b | 界定單詞,只是查找wubing單詞,包含wubing的不算 |
| \bwubing | 單詞以wubing開頭 |
| wubing\b | 單詞以wubing結尾 |
| \<wubing\> | 定界單詞,只是查找wubing單詞,包含wubing的不算 |
\babc\b等于\<abc\>
舉例(學了以上知識,要看懂以下陳述句喔)
[root@kafka01 1-6]# seq 100 | awk '$1 % 5 == 0 || $1 ~ /^1/ {print $1}'
[root@kafka01 1-6]# awk -F: ' $1 == "root" {print $1,$3}' /etc/passwd
[root@kafka01 1-6]# ps aux | awk '$2 <=10 {print $11}' PID號小于10的命令awk命令的參考shell變數
-v 引入shell變數
[root@kafka01 1-6]# name="lmy"
[root@kafka01 1-6]# echo | awk -v new_name=$name '{print new_name}'
lmy-v 常用在寫腳本中,比如我們把某個東西得到了,要通過它來截取一段文字或其他操作
[root@kafka01 1-6]# cat user.sh
read -p "please input your name:" u_name
echo |awk -v new_name=$u_name -F: '$1 == new_name {print $1,$3}' /etc/passwd
[root@kafka01 1-6]# bash user.sh
please input your name:zabbix
zabbix 992不使用-v選項,直接使用shell里的變數,需要使用雙引號,{}括號里的$符號需要轉義,舉例如下:
[root@kafka01 1-6]# abc=pcp
[root@kafka01 1-6]# awk -F: "/^$abc/{print NR,\$0}" /etc/passwd
28 pcp:x:993:988:Performance Co-Pilot:/var/lib/pcp:/sbin/nologin
[root@kafka01 1-6]# name=zabbix
[root@kafka01 1-6]# awk -F: "\$1~ /$name/ {print \$1,\$3}" /etc/passwd
zabbix 992
也可以使用單引號,將變數引起來,然后前面加一個$符號再次參考變數的值,相當于取2次值
[root@kafka01 1-6]# sg=3
[root@kafka01 1-6]# awk -F: '/root/{print $1,$'$sg'}' /etc/passwd
root 0
operator 11
總結一下:
awk里的變數的傳遞問題和shell腳本的傳參問題
可以在BEGIN部分定義,整個處理的程序都可以使用,END部分也可以使用
cat /etc/passwd|awk 'BEGIN{OFS="####";FS=":"}{print $1,$3}'往腳本里傳遞引數:
- read -p
- 位置變數
shell里的變數傳遞到awk里的問題?
- awk -v
- 或者使用雙引號
- BEGIN部分定義
- 使用單引號
練習:
1. 統計名字里包含a字母用戶的數量,輸出用戶名
awk -F: 'BEGIN{i=0} $1 ~/a/ {i++;print $1,i}END{print i}' /etc/passwd
awk -F: 'BEGIN{i=0}{if ($1 ~/a/)print$1,i++}END{print i}' /etc/passwd2. 統計/etc/passwd檔案里的使用bash的用戶的個數,并且還要顯示出來這些行
awk -F: 'BEGIN{i=0} $NF ~ /bash/{i++;print $1,i}END{print i}' /etc/passwd3. 取出ip地址
[root@kafka01 ~]# ip add| awk '/inet.*ens33/{print $2}'
[root@kafka01 ~]# ip add| awk '$NF ~ /ens33/{print $2}'
4.使用ifconfig,使用awk顯示eth0的入站流量和出站流量(位元組)
[root@kafka01 ~]# ifconfig ens33|awk 'NR==5||NR==7{print $5}'
[root@kafka01 ~]# ifconfig ens33|awk '$0 ~ /RX.*bytes|TX .*bytes/{print $5}'
統計每秒鐘ens33網卡的接受和發送資料的流量(撰寫腳本或使用watch命令)
watch -n 1 -d "ifconfig ens33|awk 'NR==5||NR==7{print $5}'"
5.使用awk命令統計以r開頭的用戶數目,顯示如下效果
[root@kafka01 ~]# cat /etc/passwd|awk -F: 'BEGIN{i=0}$1 ~ /^r/{print $1;i++}END{print i}'6. 判斷系統里哪些用戶沒有設定密碼或者密碼為空的用戶,輸出這些用戶的名字,并且統計沒有設定密碼的用戶個數,
提示:
- 密碼欄位為*、!!表示沒有設定密碼
- 密碼欄位為空說明密碼被清除
[root@kafka01 1-6awk]# awk -F: 'BENGIN{i=0}length($2)<=2{print $1,"user not set password";i++}END{print i}' /etc/shadow經典面試題
1.如果有一列數字,怎么加起來
[root@kafka01 1-6]# cat number.txt
1
2
3
4
5
[root@kafka01 1-6]# cat number.txt |awk 'BEGIN{i=0}{i+=$0}END{print i}'
15
2.檢查/var/log/secure日志檔案,如果有主機用root用戶連接服務器的ssh服務失敗次數超過10次(10次必須使用變數),就將這個IP地址加入/etc/hosts.deny檔案(或者使用iptables)拒絕其訪問,如果這個IP已經存在(已經存在在iptables鏈里了)就無需重復添加到/etc/hosts.deny檔案
[root@kafka01 1-6awk]# cat ssh_secure.sh
#!/bin/bash
# 檢查/var/log/secure日志檔案,如果有主機用root用戶連接服務器的ssh服務失敗次數超過3次(3次必須使用變數),就將這個IP使用iptables拒絕其訪問,如果這個IP已經存在iptables鏈里了,就無需重復添加
# 得到登錄失敗次數大于3的主機ip地址
failed_host=$(cat /var/log/secure |awk '$0 ~ /Failed/{print $(NF-3)}'|sort|uniq -c|awk '$1>2{print $2}')
# 得到iptables中的ssh服務攔截主機ip
exist_host=$(iptables -L INPUT -n |egrep '22\>' |awk '{print $4}')
# 將不在ssh攔截的主機添加進iptables
for i in $failed_host
do
if ! echo $exist_host|egrep $i
then
iptables -A INPUT -s $i -p tcp --dport 22 -j DROP
fi
done
需求分析:
1.這個腳本需要一直執行
2.查看/var/log/secure檔案,統計出Failed password行的ip地址,一旦這個ip地址連接的次數超過10,就將這個ip地址加入黑名單/etc/hosts.deny
3.sshd:172.16.145.128 追加到/etc/hosts.deny檔案里
#!/bin/bash
awk '$0~/Failed/{print $11}' /var/log/secure|sort|uniq -c|awk '{print $1,$2}' >sshd.txt
ip_addr=($(awk '{print $2}' sshd.txt))
ip_num=($(awk '{print $1}' sshd.txt))
for i in ${!ip_addr[@]}
do
if egrep "${ip_addr[i]}" /etc/hosts.deny &>/dev/null
then
echo "${ip_addr[i]} aready exists"
echo "${ip_addr[i]}" have access ${ip_num[i]} times
else
echo "################################"
((${ip_num[i]} >10 ))&&echo "sshd:${ip_addr[i]}" >>/etc/hosts.deny
echo "${ip_addr[i]}" have access ${ip_num[i]} times
fi
done
while true
do
IP_list=($(cat /var/log/secure|awk '{print $6,$11}'|egrep '^Failed'|sort|uniq -c|awk '{if($1>10) print $3}'))
for i in ${!IP_list[@]}
do
if cat /etc/hosts.deny|egrep "${IP_list[i]}" &>/dev/null
then
:
else
sed -i "$ a sshd:${IP_list[i]}:deny" /etc/hosts.deny
fi
done
sleep 5
done下一篇還會繼續探討awk中支持的函式和結構化陳述句!我們下篇見!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402615.html
標籤:其他