K均值聚類
- K均值聚類的概念
- 1.1 什么是聚類
- 1.2 K-means的原理
- 1.3 K-means的步驟
- 1.4 K-means的數學描述
- K值選擇問題
- 2.1 拍腦袋法
- 2.2 肘部法則(Elbow Method)
- 2.3 輪廓系數法
- 2.4 Canopy演算法
一.K均值聚類演算法的概念
1.1什么是聚類
監督式學習:可以由訓練資料中學到或建立一個模式,并依此模式推測新的實體,訓練資料是由輸入物件和預期輸出所輸出,
無監督式學習:只有資料沒有明確答案,即訓練資料沒有標簽,自動對輸入的資料進行分類或分群,
1.2 K-means的原理
K-means演算法又名K均值演算法,其中的K表示的是聚類為K個簇,means代表取每一個聚類中資料值的均值作為該簇的中心,或稱為質心,即用每一個類的質心對該簇進行描述,
在給定K值和K個初始類簇中心點的情況下,把每個點(亦即資料記錄)分到離其最近的類簇中心點所代表的類簇中,所有點分配完畢后,根據一個類簇內所有點重新計算該類簇的中心點(取平均值),然后再迭代的進行分配點和更新類簇中心點的步驟,直至類簇中心點的變化很小,或者達到指定的迭代次數,
1.3 K-means步驟
1.假定我們要對N個樣本觀測做聚類,要求聚為K類,首先選擇K個點作為初始中心點,
2.針對資料集中每個樣本Xi,分別計算該樣本到K個聚類中心的歐式距離,并將其分到距離最小的聚類中心所對應的類中,
3.針對每個類別Cj,重新計算它的聚類中心,n為類別Cj中包含的資料點的個數,
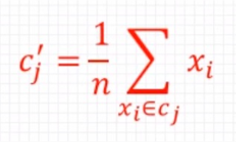
4.然后根據這個中心重復第2,3步,直到收斂(聚類中心不再改變或達到指定的迭代次數),聚類程序結束,
1.4 K-means的數學描述
二.K值選擇問題
1.拍腦袋法
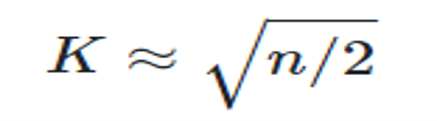
2.肘部法則(Elbow Method)
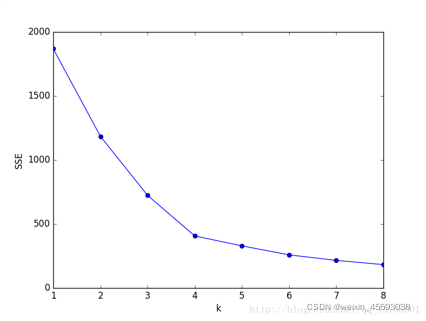
隨著聚類數K的增大,樣本劃分會更加精細,每個簇的聚合程度會逐漸提高,那么誤差平方和SSE自然會逐漸變小,并且當K小于真實聚類簇數時,由于K的增大會大幅增加每個簇的聚合程度,故SSE的下降幅度會很大,而當K到達真實聚類數時,再增加K所得到的聚合程度回報會迅速變小,所以SSE的下降和K的關系圖是一個手肘的形狀,而這個肘部對應的K值就是資料的真實聚類數,
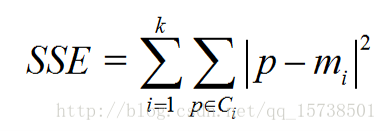
ci是第i個簇,p是Ci中的樣本點,mi是Ci的質心(Ci中所有樣本的均值),SSE是所有樣本的聚類誤差,代表了聚類效果的好壞,
2.輪廓系數法
輪廓系數是一種非常常用的聚類效果評價指標,該指標結合了內聚度和分離度兩個因素,用于評估聚類的效果,該值處于-1~+1之間,值越大,表示聚類效果越好,其具體計算程序如下:
假設已經通過聚類演算法將待分類的資料進行了聚類,并最終得到了一個簇,對于每個簇中的每個樣本點,分別計算其輪廓系數,具體的,需要對每個樣本點計算以下兩個指標:
a(i):樣本點i到與其同一個簇的其他樣本點距離的平均值,a(i)越小,說明該樣本屬于該類的可能性越大,
b(i):樣本點i到其他簇Cj中的所有樣本的平均距離的平均值bij中的最小值,b(i)=min{bi1,bi2,…}
則樣本的輪廓系數為:
而所有樣本點i的輪廓系數的平均值,即為該聚類結果總的輪廓系數S,越接近于1,聚類效果越好,
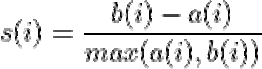
從上面的公式,不難發現若s(i)<0,說明i與其簇內元素的平均距離大于最近的其他簇,表示聚類效果不好,如果a(i)趨于0,或者b(i)足夠大,即a(i)<<b(i),那么s(i)趨近于0,說明聚類效果比較好,
3.Canopy演算法

Canopy演算法決議

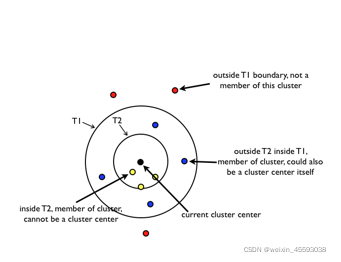
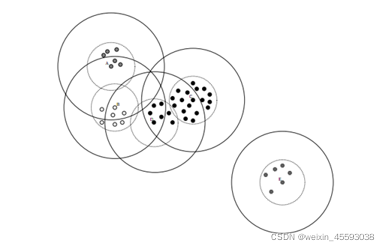
Canopy效果圖如下
三.演算法的優缺點
優點:原理比較簡單,實作也很容易,收斂速度快
聚類效果優
演算法的可解釋性強
主要調參的引數僅僅是簇族K
缺點:K值的選取不好把握
初始聚類中心的選擇較為困難
采用迭代方法,得到的結果不一定是全域最優解
對噪音和例外點比較敏感等
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402637.html
標籤:AI