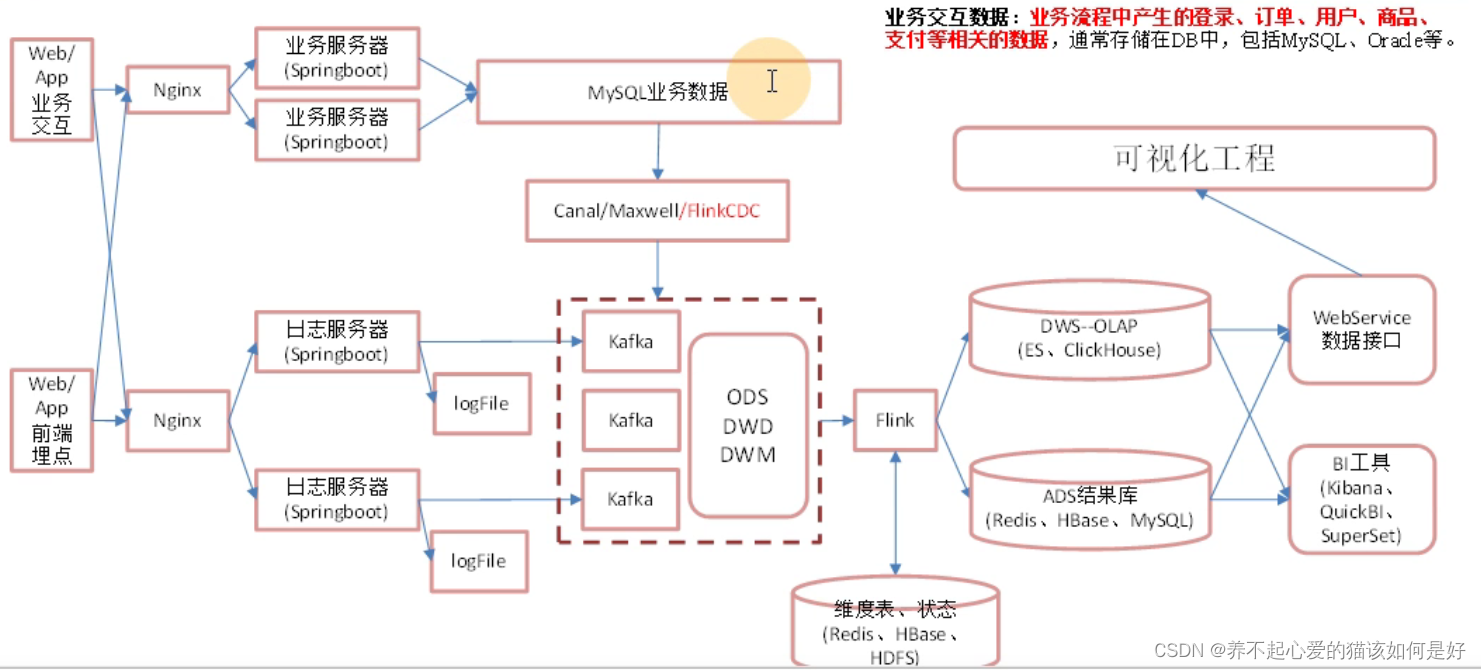
實時數倉架構圖:
離線數倉:
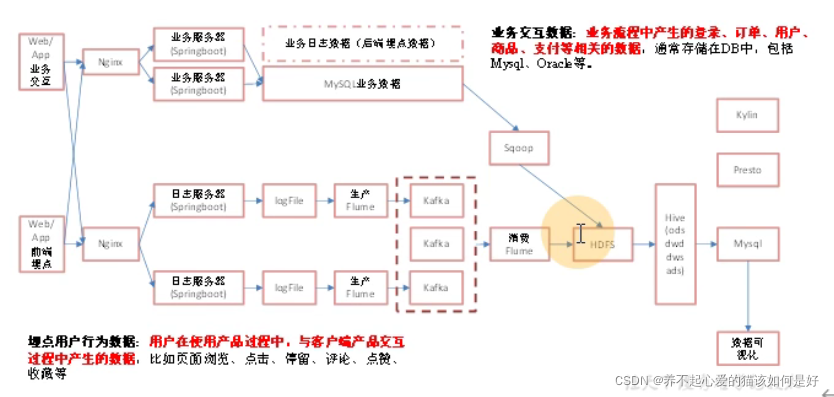
與離線數倉區別:
- MySQL業務資料采集改用FlinkCDC;FlinkCDC與Maxwell處理方式和Cannal一樣通過監控binlog方式(行級別),而Sqoop是通過MR方式處理資料,這種方式太慢
- 日志資料,離線數倉采用的是Taildir Source監控落盤的多個檔案采集資料,并通過Kafka Channel寫入Kafka,而實時架構直接將日志資料收集到Kafka,減少了磁盤IO速度也更快了,缺點就是耦合性高,日志服務器和Kafka關聯性太大,例如Kafka發生了問題會影響到日志服務器
離線架構
優點:耦合性低,穩定性高
缺點:時效性差一點
說明:
1.更追求系統的穩定性
2.耦合性低,穩定性高
3.公司未來的發展,資料量會變得很大
實時架構
優點:時效性好
缺點:耦合性高,穩定性低
實時架構
優點:時效性好
缺點:耦合性高,穩定性低
說明:
1.時效性好,使用的是Flink
2.Kafka集群高可用,掛一臺兩臺是沒有問題
3.資料量小,所有機器存在于同一個機房,傳輸沒有問題
PS:沒有最好的架構,只有合適的架構
Flink消費流程
從FlinkCDC和Kafka來的資料放入ODS,接下來需要把它們拆成明細放入DWD,像行為資料中的日志有:啟動日志、動作日志、曝光日志、錯誤日志、頁面日志和離線數倉一樣,把一張表的資料拆成五張表;從FinkCDC中來的資料也是一張表,所以ODS層只有兩個主題:行為資料一個主題,業務資料一個主題;
使用Flink將Kafka中ODS層資料進行消費,通過側輸出流進行分流,分到DWD層不同的主題里面,同時業務資料一部分需要放入Kafka中DWD層事實表里面,一部分需要放入HBase中的DIM層維度表
Flink消費DWD層資料關聯維表形成DWM層
Flink消費DWM層資料寫入ClickHouse(為什么使用ClickHouse后續會講)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/402687.html
標籤:其他