第三卷 第十三章 Faster R-CNNs
深度學習已經以一種有意義的方式影響了依賴機器學習的計算機視覺的幾乎所有方面, 影像分類、影像搜索引擎(也稱為基于內容的影像檢索 (CBIR)、定位和映射 (SLAM)、影像分割等等,自神經網路和深度學習的最新復興以來,都發生了變化, 物件檢測也不例外,
最流行的基于深度學習的物件檢測演算法之一是R-CNN演算法系列,R-CNN 演算法經歷了多次迭代,優于傳統的物件檢測演算法(例如,Haar級聯、HOG+線性SVM),
在本章中,我們將討論 Faster R-CNN 演算法及其組件,包括錨點、基礎網路、區域提議網路 (RPN) 和感興趣區域 (ROI) 池化, 對Faster R-CNN構建塊的討論將幫助您了解核心演算法、其作業原理以及端到端深度學習物件檢測是如何實作的,
在下一章中,我們將回顧 TensorFlow 物件檢測 API,包括如何安裝它、它是如何作業的,以及如何使用該 API 在自定義資料集上訓練您自己的 Faster R-CNN 物件檢測器,
關于Faster R-CNN 的這兩章,以及關于 Single ShotDetectors (SSD) 的以下兩章,將從自動駕駛汽車的角度重點關注物件檢測,展示如何訓練物件檢測器來定位影像和視頻流中的路牌和車輛,
1、物件檢測和深度學習
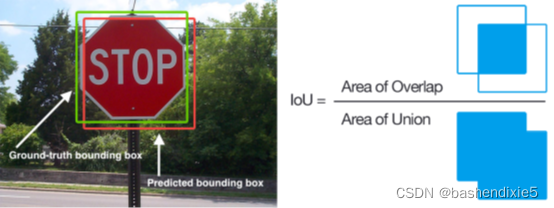
在評估物件檢測器性能時,我們使用稱為聯合相交 (IoU) 的評估指標, 但是,用于生成預測邊界框的實際演算法并不重要,
2、(Faster)R-CNN 架構
2.1 R-CNN 簡史
原始R-CNN
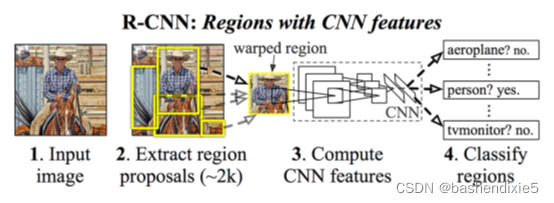
可以看到來自傳統物件檢測器(例如HOG + 線性SVM框架)的相似之處,
1、我們沒有應用詳盡的影像金字塔和滑動視窗,而是換用了更智能的選擇性搜索演算法
2、我們現在不是從每個 ROI 中提取 HOG 特征,而是提取 CNN 特征
3、我們仍在為輸入 ROI 的最終分類訓練 SVM,只是我們在 CNN 特征而不是 HOG 特征上訓練這個 SVM,
原始 R-CNN 方法的問題在于它仍然非常慢,此外,實際上并不是在學習通過深度神經網路進行定位,
Fast R-CNN
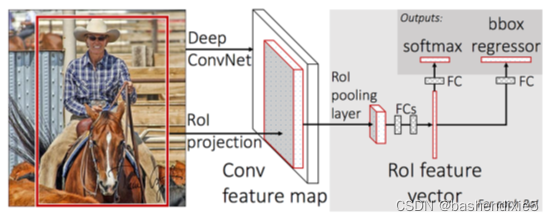
這里的主要好處是網路現在可以有效地進行端到端的訓練:
1.我們輸入一個影像和相關的真實邊界框
2.提取特征圖
3. 應用ROI pooling,得到ROI特征向量
4. 最后使用兩組全連接層獲得(1)類標簽預測和(2)每個建議的邊界框位置,
雖然網路現在是端到端可訓練的,但由于依賴于選擇性搜索(或等效)區域提議演算法,在推理(即預測)時的性能受到了極大的影響,為了使 R-CNN 架構更快,我們需要將區域提議直接合并到 R-CNN 中,
Faster R-CNN
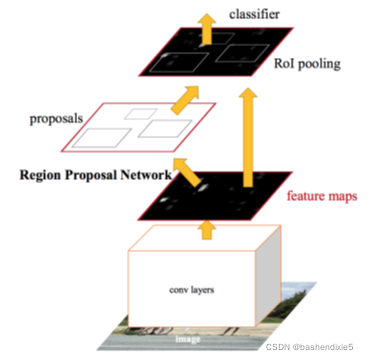
第一個組件 RPN 用于確定潛在物件可能位于影像中的哪個位置,在這一點上,我們不知道物體是什么,只是知道影像中的某個位置可能有一個物體,
建議的邊界框 ROI 基于網路的感興趣區域 (ROI) 池化模塊以及從上一步提取的特征, ROI Pooling 用于提取固定大小的特征視窗,然后將這些視窗傳遞到兩個完全連接的層(一個用于類標簽,一個用于邊界框坐標)以獲得我們的最終定位,
2.2 基礎網路
最初的Faster R-CNN論文使用VGG和ZF作為基礎網路,今天,我們通常會換入更深、更準確的基礎網路,例如ResNet,或者更小、更緊湊的網路,用于包含資源的設備,例如MobileNet,
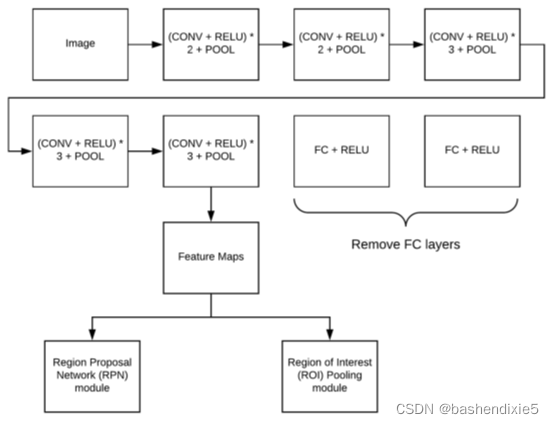
2.3 Anchors
在傳統的物件檢測中,使用(1)滑動視窗+影像金字塔的組合或(2)類似選擇性搜索的演算法來為我們的分類器生成建議,但我們的目標是開發一個端到端的物件使用包含提案模塊的深度學習檢測器,我們需要定義一種方法來生成我們的建議ROI,

首先需要在輸入影像上均勻采樣點(圖左), 在這里,我們可以看到一個 600 400 像素的輸入影像——我們用藍色圓圈標記了一個定期采樣的整數(以 16 個像素為間隔)的每個點,
下一步是在每個采樣點處創建一組錨點, 正如在最初的 Faster R-CNN 出版物中一樣,我們將在給定的采樣點周圍生成九個具有不同大小和縱橫比的錨點(它們是固定的邊界框),
如果我們在600*800張影像上使用16像素的步長(Faster R-CNN 的默認值),我們將總共獲得 1,989 個位置,
在 1,989 個位置的每個位置周圍有 9 個錨點,我們現在總共有 1989*9=17901 個邊界框位置供我們的 CNN 評估,
2.4 (Region Proposal Network)RPN

RPN 模塊簡單但功能強大,由兩個輸出組成, RPN 模塊的頂部接受卷積特征圖輸入, 然后應用3*3CONV,學習512個過濾器,這些濾波器并行饋入兩條路徑, RPN 的第一個輸出(左)是一個分數,表示 RPN 認為 ROI 是前景(值得進一步檢查)還是背景(丟棄),RPN 實際上并沒有標記 ROI——它只是試圖確定 ROI 是背景還是前景,
2.5 感興趣區域 (ROI) 池化
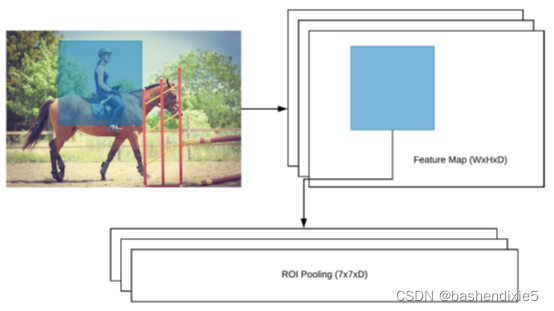
從 ROI 池化模塊獲得的最終特征向量現在可以輸入到基于區域的卷積神經網路,我們將使用它來獲得每個物件的最終邊界框坐標以及相應的類標簽,
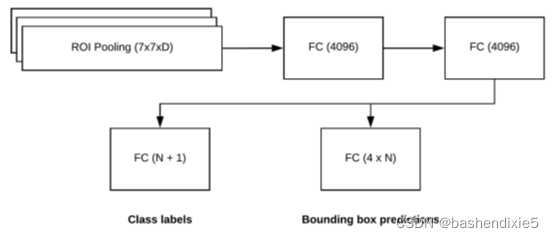
2.6 基于區域的卷積神經網路
最后一個組件是基于區域的卷積神經網路,或者我們所知的 R-CNN, 該模塊有兩個目的:
1. 根據 ROI Pooling 模塊的裁剪特征圖,獲得每個邊界框位置的最終類標簽預測
2. 進一步細化邊界框預測 (x;y) 坐標以獲得更好的預測精度在實踐中,R-CNN 組件是通過兩個全連接層實作的,如圖所示, 在最左邊,我們有 R-CNN 的輸入,它們是從 ROI Pooling 模塊獲得的特征向量, 這些特征通過兩個完全連接的層(每個 4096-d),然后傳遞到最后兩個 FC 層,這將產生我們的類標簽(或背景類)以及邊界框增量值,
在訓練完整Faster R-CNN時,我們需要做出選擇,第一種選擇是訓練RPN模塊,獲得令人滿意的結果,然后繼續訓練R-CNN模塊,第二種選擇是組合四個損失函式(兩個用于RPN模塊,兩個用于R-CNN模塊)通過加權總和,然后聯合訓練所有四個,
一般情況下,通過最小化四個損失函式的加權和來端到端地聯合訓練整個網路不僅需要更少的時間,而且還可以獲得更高的準確率,
在下一章中,我們將學習如何使用 TensorFlow 物件檢測 API 來訓練我們自己的 Faster R-CNN 網路, 如果您對 Faster R-CNN 管道、RPN 和 ROI 池化模塊的更多細節感興趣,以及關于我們如何共同最小化四個損失函式的附加說明,請參考原始Faster R-CNN 出版物作為以及 TryoLabs 文章,
3、小結
在本章中,我們首先回顧了Girshick等人的Faster R-CNN 架構及其早期變體,R-CNN 架構經過了幾次迭代和改進,使用最新的 Faster R-CNN 架構,我們能夠訓練端到端的深度學習物件檢測器,
架構本身包括四個主要組件,
第一個組件是用作特征提取器的基礎網路(即 ResNet、VGGNet 等),
第二個組件是區域提議網路 (RPN),它接受一組錨點,并輸出關于它認為物件在影像中的位置的提議, 需要注意的是,RPN 不知道影像中的物件是什么,只知道給定位置存在潛在物件,
第三個組件Region of Interest Pooling 用于從每個提議區域中提取特征圖,
最后,基于區域的卷積神經網路用于 (1) 獲得提案的最終類標簽預測,以及 (2) 進一步細化提案位置以獲得更好的準確性,
鑒于R-CNN架構中的大量移動部件,手工實作整個架構是不可取的,相反,建議使用現有的實作,例如 TensorFlow Object Detection API或TryoLabs的Luminoth,
在下一章中,我們將學習如何使用TensorFlow ObjectDetection API 訓練 Faster R-CNN,以檢測和識別常見的美國街道/道路標志,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/403132.html
標籤:其他
下一篇:無法從類中列印__str__