開心一刻
一天,有個男粉絲跟我述苦
粉絲:我喜歡一個女人,那個女人也喜歡我
我:你們都是多大
粉絲:我今年23,她今年26
我:女大三,抱金磚,我覺得可以呀,年齡不是問題
粉絲:她家里不同意
我:她家里為什么不同意,嫌你條件不好,還是嫌你年齡太小
粉絲:她老公不同意
我:她老公... 你給我滾

前情回顧
對二叉樹的遍歷還不了解的,先去看看:二叉樹的遍歷 → 不用遞回,還能遍歷嗎
簡單來說,深度遍歷用 堆疊 輔助實作,廣度遍歷用 佇列 輔助實作
不管是遞回(系統堆疊)實作,還是 堆疊 + 迭代 實作,深度遍歷的額外空間復雜度都是:O(n)
那有沒有額外空間復雜度 O(1) 的方法來實作二叉樹的深度遍歷呢?(O(1) 是指常數級別,而非字面 1 的意思)
還真有:morris traversal,只是遍歷程序會破壞二叉樹的結構,所以存在恢復二叉樹結構的程序,具體實作可查看:Morris Traversal方法遍歷二叉樹(非遞回,不用堆疊,O(1)空間)
不是很好理解,大家結合二叉樹樣本結構,去逐行 debug 代碼,看看二叉樹的遍歷、結構變化,慢慢的就有感覺了
實戰案例
當我們對二叉樹的遍歷有了一定的了解之后,我們就可以嘗試解決一些二叉樹的問題了
最大寬度
從根節點開始,一層一層往下統計,最大寬度即是節點數最多的那一(些)層的節點數量,例如

最大寬度就是 3
很明顯,這是一個寬度(廣度)遍歷,那就需要用到 佇列 來輔助實作
光實作寬度遍歷還不夠,還需要統計每一層的節點數,然后找出最大寬度;那如何統計每一層的節點數?
我們可以先用哈希表記錄每個節點所處的層次,實作如下

相信大家都能看懂這個代碼,就是在寬度遍歷的基礎上,對每個節點進行層次標記
標記完之后,再遍歷 levelMap ,完成層次的個數統計?
我們知道哈希表一般是無序的,再遍歷 levelMap 進行層次的個數統計,并沒那么簡單;非要較勁,也是可以實作的,但沒比較
寬度遍歷本身就是逐層進行的,當進行到下一層時,上一層肯定全部遍歷完了,所以當遍歷下一層的時候,上一層的節點數就應該統計出來
我們來看完整代碼

簡單點來說,就是在寬度遍歷的基礎上加入了統計的邏輯,所以重點是寬度遍歷
只要能夠理解寬度遍歷,上述代碼就很容易理解
我們再延伸下,如果不用哈希表,還能實作嗎?
哈希表的作用看似是記錄每個節點所在的層次,實際就是用來判斷當前層次是否處理完,基于此我們可以改造下
用兩個節點變數( curEnd 、 nextEnd )分別記錄當前層的最后一個節點和下一層的最后一個節點;遍歷當前層的時候,移動 nextEnd
當遍歷完當前層節點( cur == curEnd ), nextEnd 剛好來到來到下一層的最后一個節點,將 nextEnd 賦值給 curEnd ( curEnd = nextEnd; ),開始下一層的遍歷與統計
如此反復,找到最大寬度;代碼如下

是不是很有意思?
我們再來延伸下,找出最大寬度的同時,找出最大寬度所在的層(可能多層),該如何實作?
這個就交給你們自己去實作了
路徑總和
LeeCode 113
給定二叉樹的根節點 root 和一個整數目標和 targetSum ,找出所有 從根節點到葉子節點 路徑總和等于給定目標和的路徑(葉子節點 是指沒有子節點的節點)
示例:
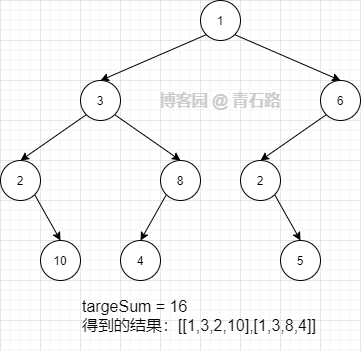
先序遍歷,找出所有路勁,過濾出路徑上節點之和等于 targetSum 的路徑
比較簡單,直接看代碼

有兩個注意點:1、為什么不直接將 curPath 添加到 allPath,而是 copy 一份之后將新的添加到 allPath;2、為什么要回溯
第 1 點,正是由于回溯,導致 curPath 中的元素會變化,如果 allPath 直接添加 curPath(allPath.add(curPath)),那么 allPath 中的元素也會隨著遞回的出堆疊而變化
所以這兩個注意點可以歸納為一點:為什么要回溯
不理解為什么要回溯的小伙伴,可以先去查查回溯的相關資料
在這里,回溯的作用是還原現場,保證我們能夠正確的找到所有路徑
折紙問題
把紙條豎著放在桌?上,然后從紙條的下邊向上?對折,壓出折痕后再展開,此時有 1 條折痕,突起的方向指向紙條的背?,這條折痕叫做“凹”折痕 ;突起的?向指向紙條正?的折痕叫做“凸”折痕
如果每次都從下邊向上方對折,對折 N 次,請從上到下列印出所有折痕的方向
我們用紙條去實操下,就會發現規律,這就是一個二叉樹的中序遍歷(嚴格來時,是滿二叉樹的中序遍歷)
很簡單,直接看代碼

這題很容易,只要你去實操折紙,找到了規律,代碼實作就是手到擒來
最低公共祖先
求同一棵二叉樹中兩個節點的最低公共祖先節點
什么是最低公共祖先,節點往上向根節點移動,兩個節點最先匯聚的節點則是這兩個節點的最低公共祖先,例如
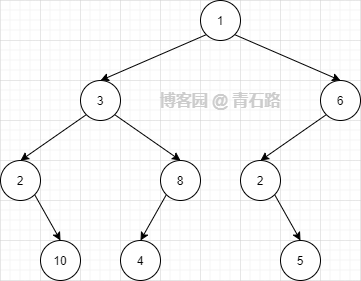
10 和 4 的最低公共祖先就是 3
簡單的做法是借助哈希表
先遍歷一次二叉樹,記錄所有節點的父節點(HashMap),然后找出其中某個節點(n1)的所有祖先節點(存放到 HashSet 中)
再從另一個節點(n2)開始,從 HashMap 中逐個找 n2 的祖先節點的同時,判斷 n2 的當前祖先節點是否在 HashSet 中
一旦找到,這直接回傳該節點,就是 n1 與 n2 的最低公共祖先
我們來看代碼

很好理解,也很好實作,就是有點費空間
還有一種方式,實作非常簡單,但卻不好理解,是前輩們反復提煉之后得到的一種解法

大家千萬不要只盯著代碼看,需要結合具體的二叉樹結構、n1與n2的關系,逐行代碼去模擬,去找感覺,來理解這種方式
這可是前輩們反復提煉之后的方法,如果你一眼就看懂了,那豈不是太過分了?
總結
1、二叉樹的遍歷是解二叉樹題的基礎,基礎一定要打牢
相信大家已從上述幾個案例中感覺到了
基礎不牢,地動山搖,你們懂的
2、舉的案例有限,目的也僅僅只是給大家找找感覺
有了一定的感覺,就可以力扣走起:二叉樹
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/403549.html
標籤:其他
下一篇:DOTween實作緩動變值動效