一.關于聚類
什么是聚類:
聚類(Clustering)是按照某個特定標準(如距離)把一個資料集分割成不同的類或簇,使得同一個簇內的資料物件的相似性盡可能大,同時不在同一個簇中的資料物件的差異性也盡可能地大,也即聚類后同一類的資料盡可能聚集到一起,不同類資料盡量分離,
什么不是聚類:
● 監督分類 – 有類標簽資訊(通常就叫做分類)
● 簡單分割 – 按姓氏的字母順序將學生分為不同的注冊組
● 查詢結果 – 分組是外部規范的結果
● 圖形磁區 – 一些相互關聯和協同作用,但領域并不相同
聚類的種類:
按照聚類方式:
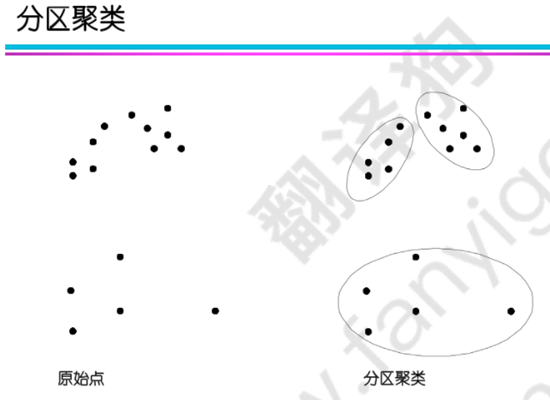
按照排他性:在排他性聚類中,點只能屬于一個聚類;在非排他性聚類中,點可能屬于多個聚類,可以表示多個類或"邊界"點,
按照模糊性:在模糊聚類中,一個點屬于每個權重在 0 到 1 之間的聚類,權重必須總和為 1,概率聚類具有相似的特點,非模糊聚類中,每個點有唯一的預測類別
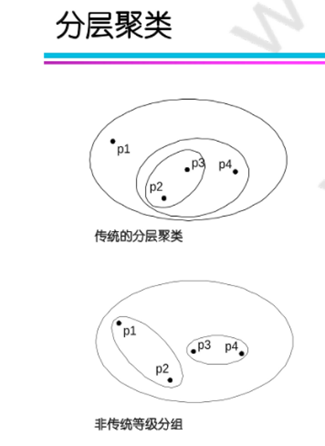
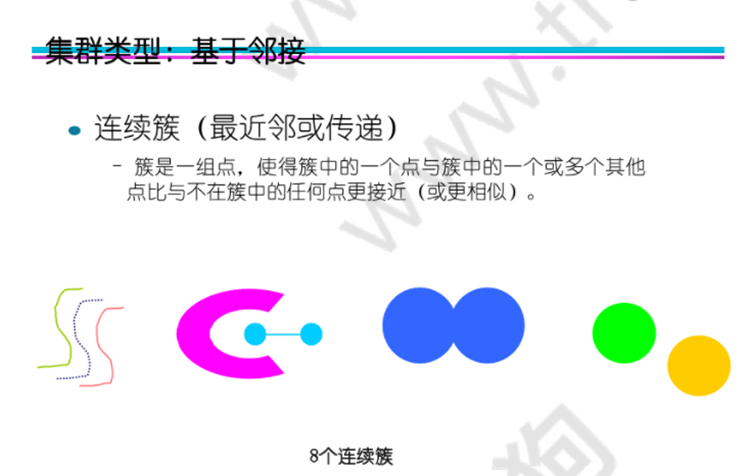
按照簇的組織方式:
基于中心的集群:簇是一組物件,使得簇中的物件比任何其他簇的中心更接近 (更相似)簇的“中心”,簇的中心通常是質心,即簇中所有點的平均值,或者是中心點,即簇中最具“代表性”的點

資料間的相似度度量:

閔可夫斯基距離就是Lp范數(p為正整數),而曼哈頓距離、歐式距離、切比雪夫距離分別對應![]()
簇間相似度度量:
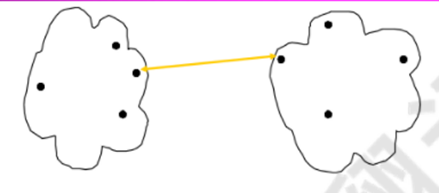
1)最小值:
2)最大值:
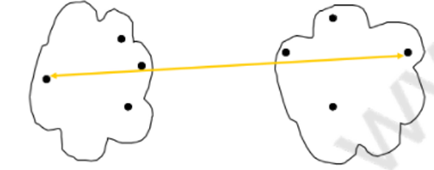
3)組平均:
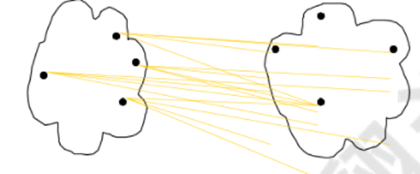
4)質心距離
5)Ward 方法:基于SSE的增加(在層次聚類中越小合并效果越好)

不太容易受到噪音和例外值的影響,偏向球狀星團
評估不同聚類方案的優劣:
最常見的度量是平方誤差總和 (SSE,Sum of Square Error),每個點距離自己所在簇的代表點(均值點)的距離之和,減少 SSE 的一種簡單方法是增加 K,集群的數量
另一種方法:方差比率

N,圖中的總點數
聚類方法的分類:
|
類別 |
包括的主要演算法 |
|
劃分方法 |
K-Means演算法(均值)、K-medoids演算法(中心點)、K-modes演算法(眾數)、k-prototypes演算法、CLARANS(基于選擇),K-Means++,bi-KMeans |
|
層次分析 |
BIRCH演算法(平衡迭代規約)、CURE演算法(點聚類)、CHAMELEON(動態模型),Agglomerative(凝聚式),Divisive(分裂式) |
|
基于密度 |
DBSCAN(基于高密度連接區域)、DENCLUE(密度分布函式)、OPTICS(物件排序識別) |
|
基于網格 |
STING(統計資訊網路)、CLIOUE(聚類高維空間)、WAVE-CLUSTER(小波變換) |
|
基于模型 |
統計學方法(比如GMM)、神經網路(比如SOM(Self Organized Maps)) |
|
其他方法 |
量子聚類,核聚類,譜聚類 |
聚類演算法之外的處理方法:

二.劃分式聚類方法
k-means:
演算法流程:
1.選擇K點作為初始質心
2.重復直到質心不變
(1)通過將所有點指定給最近的質心形成K簇
(2)重新計算每個簇的質心
初始質心通常是隨機選擇的,產生的集群因一次運行而異,大多數收斂發生在前幾次迭代中,因為通常將停止條件更改為“直到相對較少的點更改集群”
K值的選擇:

對 k = 1,2,4,8,... 運行 k-means 演算法,找到兩個值 v 和 2v,它們之間的平均直徑幾乎沒有減少,證明的 k 值位于 v/2 和 v 之間,然后在這之間使用二分搜索
處理K-means產生的空簇:選擇對 SSE 貢獻最大的點;從具有最高 SSE 的集群中選擇一個點,并入空簇,這樣下一輪空簇的中心就會移到選的點去
舉例:
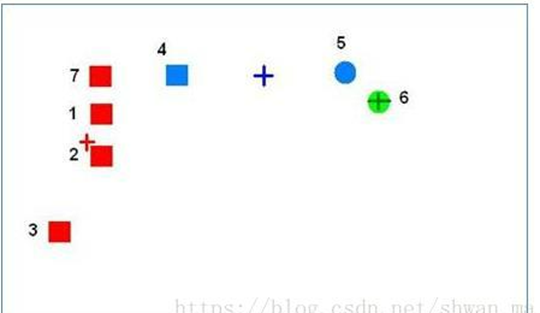
更新一輪后
增量更新中心的 K-means:在基本的 K-means 演算法中,在所有點都分配給一個質心后更新質心
另一種方法是在分配一個點后更新質心(增量方法)
– 每個分配更新零個或兩個質心
– 更高代價
– 引入順序依賴
– 永遠不會得到一個空集群
– 可以使用“權重”來改變影響
bi-k-means演算法:
初始只有一個cluster包含所有樣本點;
repeat:
從待分裂的clusters中選擇一個進行二元分裂,所選的cluster應使得SSE最小(可以每一個都分裂,選SSE的最小那個);
until 有k個cluster
k-means++演算法:
k-means++是針對k-means中初始質心點選取的優化演算法,該演算法的流程和k-means類似,改變的地方只有初始質心的選取,該部分的演算法流程如下

K-means 的局限性:當集群尺寸或密度不同時,集群為非球形形狀,資料包含例外值時,K-means 可能會有問題,一種解決方案是使用大量集群,找到集群的部分,最后結合在一起(提升k值后再使用人工方法)
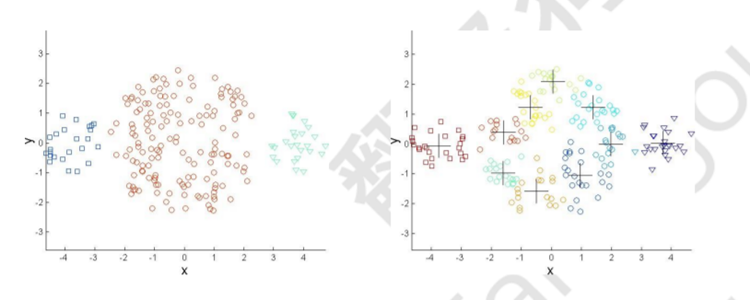
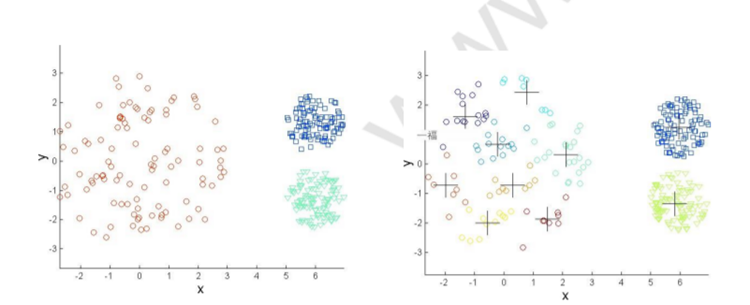
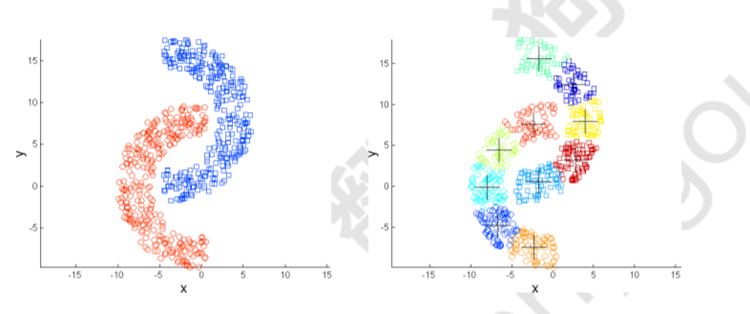
三.基于密度的聚類:
基于密度的聚類定位由低密度區域彼此分隔的高密度區域,

DBSCAN 演算法:
核心點:在半徑 Eps 內具有超過指定數量的點 (MinPts)
邊界點:點在半徑 Eps 內少于 MinPts 個點,但在核心點的鄰域(半徑EPS的圈內)內
噪聲點:既不是核心點也不是邊界點的任何點
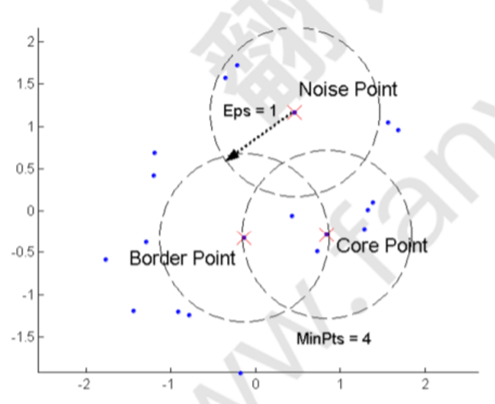

相距 Eps 之內的任意兩個核心點都在同一個簇中,任何在核心點半徑 Eps 內的邊界點都與核心點放在同一個簇中,丟棄所有噪聲點(DBSCAN是部分聚類方法,并非所有點都被聚類)
DBSCAN 實際上需要 O(n2) 時間,只要允許聚類結果的輕微不準確,運行時間就可以顯著降低到 O(n)
想法是對于集群中的點,它們的第k最近鄰距離大致相同;噪聲點在更遠的距離處具有第k最近鄰距離;因此,繪制每個點到其第k最近鄰距離的排序距離
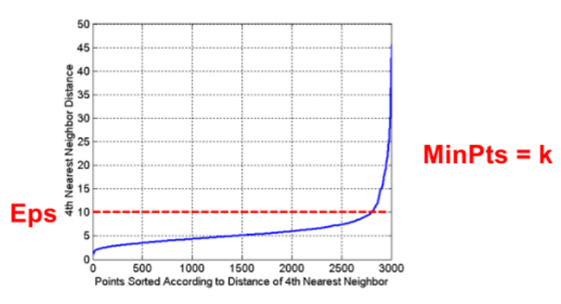
由圖:3000個點里2800個第4近鄰在10以內,因此可以設定EPS=10,MinPts=4
四.層次聚類:
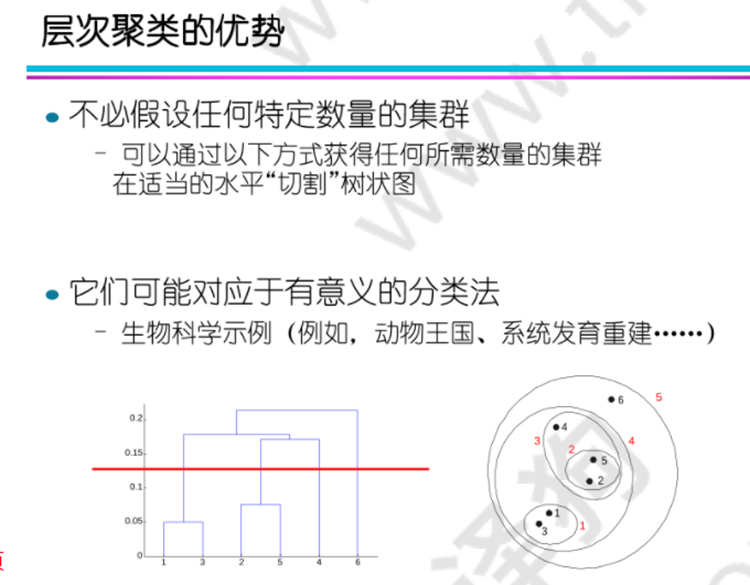
凝聚式聚類:

類似與凝聚式聚類的方法可以作為kmeans的質心初始化步驟

非歐空間不能選質心的問題:因為非歐空間無法求平均,可以用以下方法代替

可以選以上值最小的點作為集群的中心
分裂式聚類:

治愈演算法(CURE(Clustering Using Representative)):
不是通過質心來表示集群,而是使用一組代表點,
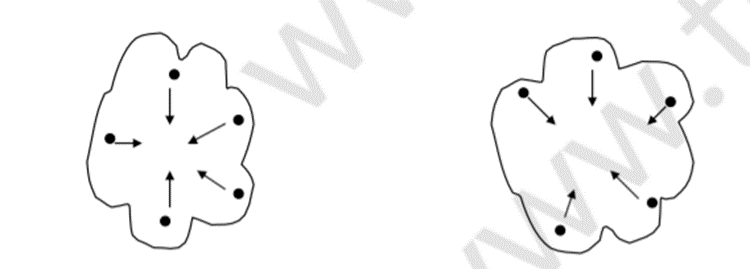
CURE 能夠更好地處理任意形狀和大小的集群,向中心收縮代表點有助于避免噪聲和例外值問題,


合并集群的同時,剔除孤立點

cure的特點:使用了采樣減少計算量;使用多個點代表集群,可以匹配那些非球形的場景,而且收縮因子的使用可以減少噪音對聚類的影響

稀疏化鄰近圖:
(從圖的角度理解聚類)



變色龍演算法:
當前合并方案的局限性:層次聚類演算法中現有的合并方案本質上是靜態的
變色龍可以適應資料集特征尋找自然聚類,使用動態模型來衡量集群之間的相似性和互連性,
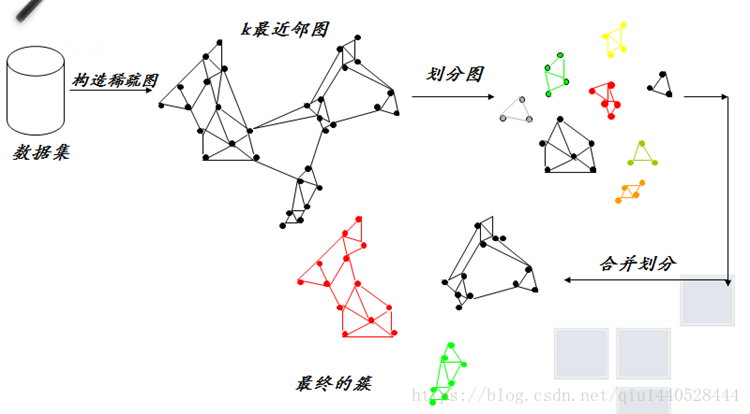
1. k-最近鄰圖Gk的構造(第一階段)
Gk圖中的每個點,表示資料集中的一個資料點,對于資料集中的每一個資料點找出它的所有k-最近鄰物件,然后分別在它們之間加帶權邊,
如何找k-最近鄰物件呢??即找離該物件最近的k個物件點,
(定義:若點ai到另一個點bi的距離值是所有資料點到bi的距離值中k個最小值之一,則稱ai是bi的k-最近鄰物件,)
若一個資料點是另一個資料點的k-最近鄰物件之一,則在這兩點之間加一條帶權邊,邊的權值表示這兩個資料點之間的相似度,即距離越大邊權值越小,則近似度越小,
2.劃分圖(第二階段)
所做的一件關鍵的事情就是形成小簇集,由零星的幾個資料點連成小簇,官方的作法是用hMetic演算法根據最小化截斷的邊的權重和來分割k-最近鄰圖,然后我網上找了一些資料,沒有確切的hMetic演算法,借鑒了網上其他人的一些辦法,于是用了一個很簡單的思路,就是給定一個點,把他離他最近的k個點連接起來,就算是最小簇了,事實證明,效果也不會太差,最近的點的換一個意思就是與其最大權重的邊,采用距離的倒數最為權重的大小,因為后面的計算,用到的會是權重而不是距離
3.
首先是2個略復雜的公式:
相對互連性RI
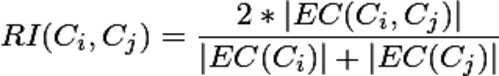
相對近似性RC
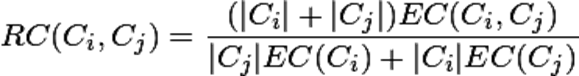
Ci,Cj表示的是i,j聚簇內的資料點的個數,EC(Ci)表示的Ci聚簇內的邊的權重和,EC(Ci,Cj)表示的是連接2個聚簇的邊的權重和,
那么合并的程序如下:
1、給定度量函式如下minMetric,
2、訪問每個簇,計算他與鄰近的每個簇的RC和RI,通過度量函式公式計算出值tempMetric,
3、找到最大的tempMetric,如果最大的tempMetric超過閾值minMetric,將簇與此值對應的簇合并
4、如果找到的最大的tempMetric沒有超過閾值,則表明此聚簇已合并完成,移除聚簇串列,加入到結果聚簇中,
5、遞回步驟2,直到待合并聚簇串列最終大小為空,
五.基于網格的聚類:
定義一組網格單元,將物件分配給單元格并計算每個單元格的密度,消除密度低于指定閾值 t 的細胞,從連續的密集細胞組形成簇,
網格單元的密度是單元中的點數除以單元的體積

子空間聚類:
去掉幾個屬性維度進行聚類
CLIQUE 演算法:基于網格和先驗的方法(如果一批點在第k維密集,那它們在k-1維也密集)
1. 找到每個屬性對應的一維空間中的所有密集區間
2. K = 2 ,重復直到沒有候選密集 k 維單元格
從密集 (k – 1) 維單元格生成所有候選密集 k 維單元格
消除密度小于閾值的細胞
K = K + 1
3. 通過對所有連續的密集單元進行聯合來查找簇,
六.基于模型的聚類
GMM:


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/403552.html
標籤:其他
上一篇:DOTween實作緩動變值動效
下一篇:Spring AOP的術語總結