原文鏈接:深入理解 Kubelet 中的 PLEG is not healthy
在 Kubernetes 社區中,PLEG is not healthy 成名已久,只要出現這個報錯,就有很大概率造成 Node 狀態變成 NotReady,社區相關的 issue 也有一大把,先列幾個給你們看看:
- https://stackoverflow.com/questions/53872739/how-to-fix-container-runtime-is-down-pleg-is-not-healthy
- https://github.com/kubernetes/kubernetes/issues/45419
- https://github.com/kubernetes/kubernetes/issues/61117
- https://github.com/kubernetes/kubernetes/issues/72533
- https://github.com/Azure/AKS/issues/102
本文我將嘗試解釋 PLEG 的作業原理,只要理解了作業原理,再遇到類似的問題就有排查思路了,
1. PLEG 是個啥?
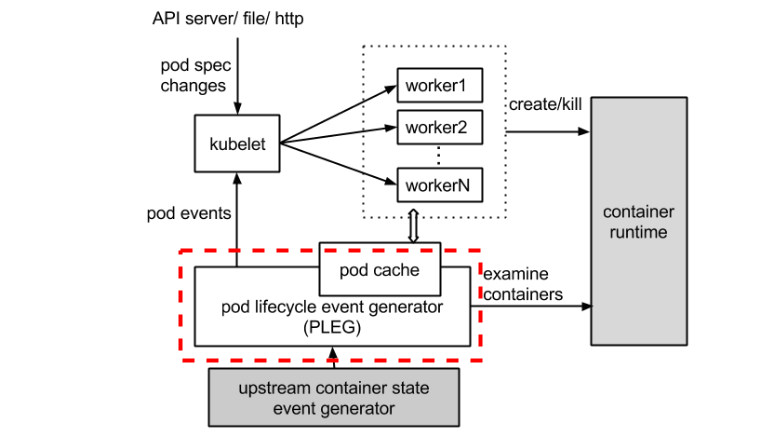
PLEG 全稱叫 Pod Lifecycle Event Generator,即 Pod 生命周期事件生成器,實際上它只是 Kubelet 中的一個模塊,主要職責就是通過每個匹配的 Pod 級別事件來調整容器運行時的狀態,并將調整的結果寫入快取,使 Pod 的快取保持最新狀態,先來聊聊 PLEG 的出現背景,
在 Kubernetes 中,每個節點上都運行著一個守護行程 Kubelet 來管理節點上的容器,調整容器的實際狀態以匹配 spec 中定義的狀態,具體來說,Kubelet 需要對兩個地方的更改做出及時的回應:
- Pod spec 中定義的狀態
- 容器運行時的狀態
對于 Pod,Kubelet 會從多個資料來源 watch Pod spec 中的變化,對于容器,Kubelet 會定期(例如,10s)輪詢容器運行時,以獲取所有容器的最新狀態,
隨著 Pod 和容器數量的增加,輪詢會產生不可忽略的開銷,并且會由于 Kubelet 的并行操作而加劇這種開銷(為每個 Pod 分配一個 goruntine,用來獲取容器的狀態),輪詢帶來的周期性大量并發請求會導致較高的 CPU 使用率峰值(即使 Pod 的定義和容器的狀態沒有發生改變),降低性能,最后容器運行時可能不堪重負,從而降低系統的可靠性,限制 Kubelet 的可擴展性,
為了降低 Pod 的管理開銷,提升 Kubelet 的性能和可擴展性,引入了 PLEG,改進了之前的作業方式:
- 減少空閑期間的不必要作業(例如 Pod 的定義和容器的狀態沒有發生更改),
- 減少獲取容器狀態的并發請求數量,
整體的作業流程如下圖所示,虛線部分是 PLEG 的作業內容,
2. PLEG is not healthy 是如何發生的?
Healthy() 函式會以 “PLEG” 的形式添加到 runtimeState 中,Kubelet 在一個同步回圈(SyncLoop() 函式)中會定期(默認是 10s)呼叫 Healthy() 函式,Healthy() 函式會檢查 relist 行程(PLEG 的關鍵任務)是否在 3 分鐘內完成,如果 relist 行程的完成時間超過了 3 分鐘,就會報告 PLEG is not healthy,
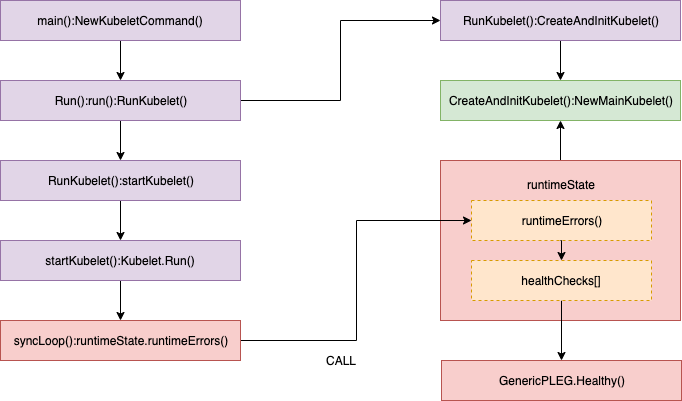
我會在流程的每一步通過源代碼解釋其相關的作業原理,源代碼基于 Kubernetes 1.11(Openshift 3.11),如果你不熟悉 Go 的語法也不用擔心,只需要看代碼中的注釋就能明白其原理,我也會在放出代碼之前先解讀一番,并從源代碼中裁剪掉不太重要的內容以提高代碼的可讀性,下面是呼叫 healthy() 函式的相關代碼:
//// pkg/kubelet/pleg/generic.go - Healthy()
// The threshold needs to be greater than the relisting period + the
// relisting time, which can vary significantly. Set a conservative
// threshold to avoid flipping between healthy and unhealthy.
relistThreshold = 3 * time.Minute
:
func (g *GenericPLEG) Healthy() (bool, error) {
relistTime := g.getRelistTime()
elapsed := g.clock.Since(relistTime)
if elapsed > relistThreshold {
return false, fmt.Errorf("pleg was last seen active %v ago; threshold is %v", elapsed, relistThreshold)
}
return true, nil
}
//// pkg/kubelet/kubelet.go - NewMainKubelet()
func NewMainKubelet(kubeCfg *kubeletconfiginternal.KubeletConfiguration, ...
:
klet.runtimeState.addHealthCheck("PLEG", klet.pleg.Healthy)
//// pkg/kubelet/kubelet.go - syncLoop()
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
:
// The resyncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
:
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
for {
if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 {
glog.Infof("skipping pod synchronization - %v", rs)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
:
}
:
}
//// pkg/kubelet/runtime.go - runtimeErrors()
func (s *runtimeState) runtimeErrors() []string {
:
for _, hc := range s.healthChecks {
if ok, err := hc.fn(); !ok {
ret = append(ret, fmt.Sprintf("%s is not healthy: %v", hc.name, err))
}
}
:
}
3. 深入解讀 relist 函式
上文提到 healthy() 函式會檢查 relist 的完成時間,但 relist 究竟是用來干嘛的呢?解釋 relist 之前,要先解釋一下 Pod 的生命周期事件,Pod 的生命周期事件是在 Pod 層面上對底層容器狀態改變的抽象,使其與底層的容器運行時無關,這樣就可以讓 Kubelet 不受底層容器運行時的影響,
type PodLifeCycleEventType string
const (
ContainerStarted PodLifeCycleEventType = "ContainerStarted"
ContainerStopped PodLifeCycleEventType = "ContainerStopped"
NetworkSetupCompleted PodLifeCycleEventType = "NetworkSetupCompleted"
NetworkFailed PodLifeCycleEventType = "NetworkFailed"
)
// PodLifecycleEvent is an event reflects the change of the pod state.
type PodLifecycleEvent struct {
// The pod ID.
ID types.UID
// The type of the event.
Type PodLifeCycleEventType
// The accompanied data which varies based on the event type.
Data interface{}
}
以 Docker 為例,在 Pod 中啟動一個 infra 容器就會在 Kubelet 中注冊一個 NetworkSetupCompleted Pod 生命周期事件,
那么 PLEG 是如何知道新啟動了一個 infra 容器呢?它會定期重新列出節點上的所有容器(例如 docker ps),并與上一次的容器串列進行對比,以此來判斷容器狀態的變化,其實這就是 relist() 函式干的事情,盡管這種方法和以前的 Kubelet 輪詢類似,但現在只有一個執行緒,就是 PLEG,現在不需要所有的執行緒并發獲取容器的狀態,只有相關的執行緒會被喚醒用來同步容器狀態,而且 relist 與容器運行時無關,也不需要外部依賴,簡直完美,
下面我們來看一下 relist() 函式的內部實作,完整的流程如下圖所示:
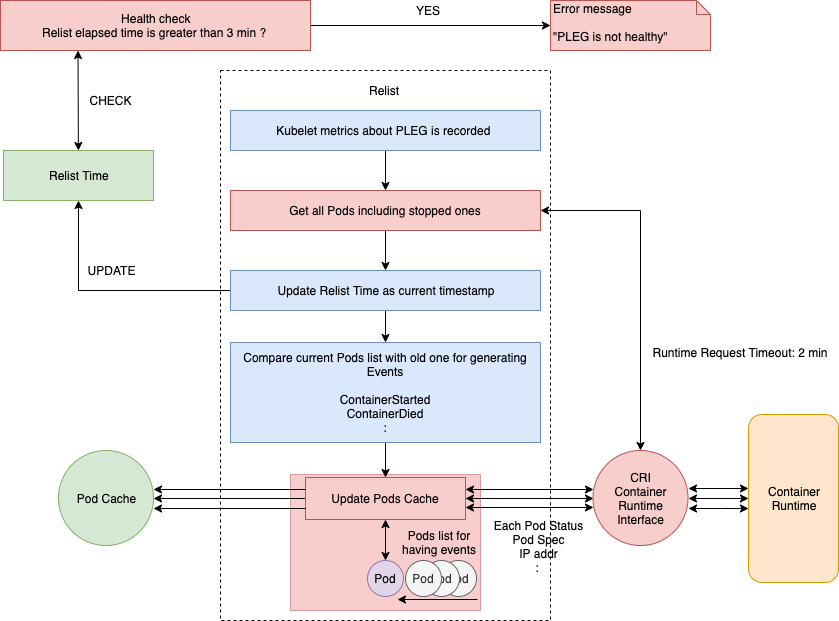
注意圖中的 RPC 呼叫部分,后文將會拎出來詳細解讀,完整的源代碼在這里,
盡管每秒鐘呼叫一次 relist,但它的完成時間仍然有可能超過 1s,因為下一次呼叫 relist 必須得等上一次 relist 執行結束,設想一下,如果容器運行時回應緩慢,或者一個周期內有大量的容器狀態發生改變,那么 relist 的完成時間將不可忽略,假設是 5s,那么下一次呼叫 relist 將要等到 6s 之后,
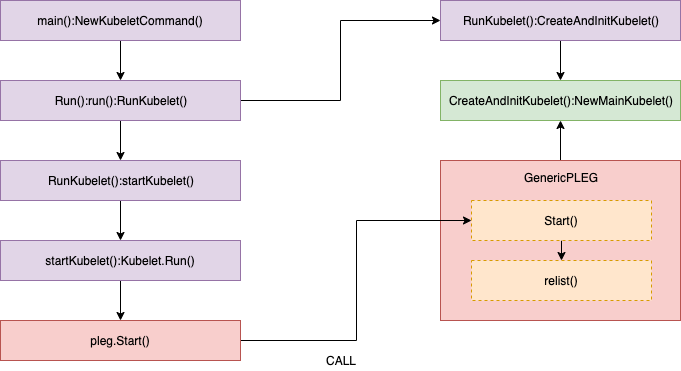
相關的源代碼如下:
//// pkg/kubelet/kubelet.go - NewMainKubelet()
// Generic PLEG relies on relisting for discovering container events.
// A longer period means that kubelet will take longer to detect container
// changes and to update pod status. On the other hand, a shorter period
// will cause more frequent relisting (e.g., container runtime operations),
// leading to higher cpu usage.
// Note that even though we set the period to 1s, the relisting itself can
// take more than 1s to finish if the container runtime responds slowly
// and/or when there are many container changes in one cycle.
plegRelistPeriod = time.Second * 1
// NewMainKubelet instantiates a new Kubelet object along with all the required internal modules.
// No initialization of Kubelet and its modules should happen here.
func NewMainKubelet(kubeCfg *kubeletconfiginternal.KubeletConfiguration, ...
:
klet.pleg = pleg.NewGenericPLEG(klet.containerRuntime, plegChannelCapacity, plegRelistPeriod, klet.podCache, clock.RealClock{})
//// pkg/kubelet/pleg/generic.go - Start()
// Start spawns a goroutine to relist periodically.
func (g *GenericPLEG) Start() {
go wait.Until(g.relist, g.relistPeriod, wait.NeverStop)
}
//// pkg/kubelet/pleg/generic.go - relist()
func (g *GenericPLEG) relist() {
... WE WILL REVIEW HERE ...
}
回到上面那幅圖,relist 函式第一步就是記錄 Kubelet 的相關指標(例如 kubelet_pleg_relist_latency_microseconds),然后通過 CRI 從容器運行時獲取當前的 Pod 串列(包括停止的 Pod),該 Pod 串列會和之前的 Pod 串列進行比較,檢查哪些狀態發生了變化,然后同時生成相關的 Pod 生命周期事件和更改后的狀態,
//// pkg/kubelet/pleg/generic.go - relist()
:
// get a current timestamp
timestamp := g.clock.Now()
// kubelet_pleg_relist_latency_microseconds for prometheus metrics
defer func() {
metrics.PLEGRelistLatency.Observe(metrics.SinceInMicroseconds(timestamp))
}()
// Get all the pods.
podList, err := g.runtime.GetPods(true)
:
其中 GetPods() 函式的呼叫堆疊如下圖所示:
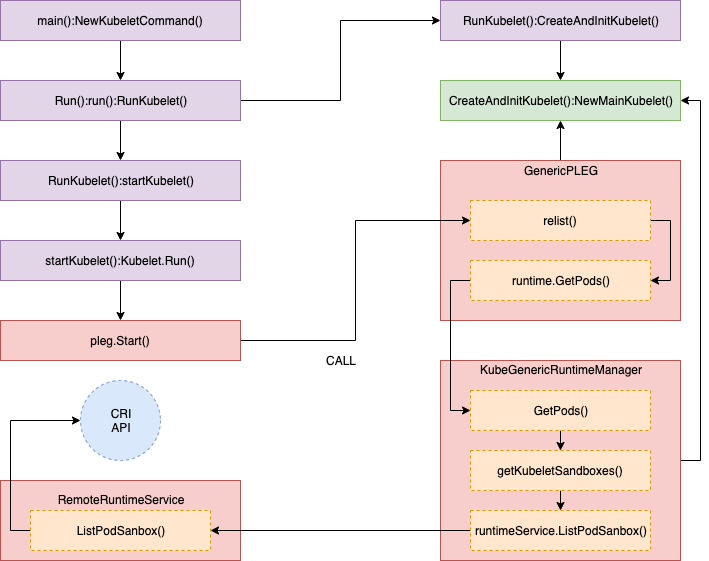
相關的源代碼如下:
//// pkg/kubelet/kuberuntime/kuberuntime_manager.go - GetPods()
// GetPods returns a list of containers grouped by pods. The boolean parameter
// specifies whether the runtime returns all containers including those already
// exited and dead containers (used for garbage collection).
func (m *kubeGenericRuntimeManager) GetPods(all bool) ([]*kubecontainer.Pod, error) {
pods := make(map[kubetypes.UID]*kubecontainer.Pod)
sandboxes, err := m.getKubeletSandboxes(all)
:
}
//// pkg/kubelet/kuberuntime/kuberuntime_sandbox.go - getKubeletSandboxes()
// getKubeletSandboxes lists all (or just the running) sandboxes managed by kubelet.
func (m *kubeGenericRuntimeManager) getKubeletSandboxes(all bool) ([]*runtimeapi.PodSandbox, error) {
:
resp, err := m.runtimeService.ListPodSandbox(filter)
:
}
//// pkg/kubelet/remote/remote_runtime.go - ListPodSandbox()
// ListPodSandbox returns a list of PodSandboxes.
func (r *RemoteRuntimeService) ListPodSandbox(filter *runtimeapi.PodSandboxFilter) ([]*runtimeapi.PodSandbox, error) {
:
resp, err := r.runtimeClient.ListPodSandbox(ctx, &runtimeapi.ListPodSandboxRequest{
:
return resp.Items, nil
}
獲取所有的 Pod 串列后,relist 的完成時間就會更新成當前的時間戳,也就是說,Healthy() 函式可以根據這個時間戳來評估 relist 是否超過了 3 分鐘,
//// pkg/kubelet/pleg/generic.go - relist()
// update as a current timestamp
g.updateRelistTime(timestamp)
將當前的 Pod 串列和上一次 relist 的 Pod 串列進行對比之后,就會針對每一個變化生成相應的 Pod 級別的事件,相關的源代碼如下:
//// pkg/kubelet/pleg/generic.go - relist()
pods := kubecontainer.Pods(podList)
g.podRecords.setCurrent(pods)
// Compare the old and the current pods, and generate events.
eventsByPodID := map[types.UID][]*PodLifecycleEvent{}
for pid := range g.podRecords {
oldPod := g.podRecords.getOld(pid)
pod := g.podRecords.getCurrent(pid)
// Get all containers in the old and the new pod.
allContainers := getContainersFromPods(oldPod, pod)
for _, container := range allContainers {
events := computeEvents(oldPod, pod, &container.ID)
for _, e := range events {
updateEvents(eventsByPodID, e)
}
}
}
其中 generateEvents() 函式(computeEvents() 函式會呼叫它)用來生成相應的 Pod 級別的事件(例如 ContainerStarted、ContainerDied 等等),然后通過 updateEvents() 函式來更新事件,
computeEvents() 函式的內容如下:
//// pkg/kubelet/pleg/generic.go - computeEvents()
func computeEvents(oldPod, newPod *kubecontainer.Pod, cid *kubecontainer.ContainerID) []*PodLifecycleEvent {
:
return generateEvents(pid, cid.ID, oldState, newState)
}
//// pkg/kubelet/pleg/generic.go - generateEvents()
func generateEvents(podID types.UID, cid string, oldState, newState plegContainerState) []*PodLifecycleEvent {
:
glog.V(4).Infof("GenericPLEG: %v/%v: %v -> %v", podID, cid, oldState, newState)
switch newState {
case plegContainerRunning:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerStarted, Data: cid}}
case plegContainerExited:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerDied, Data: cid}}
case plegContainerUnknown:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerChanged, Data: cid}}
case plegContainerNonExistent:
switch oldState {
case plegContainerExited:
// We already reported that the container died before.
return []*PodLifecycleEvent{{ID: podID, Type: ContainerRemoved, Data: cid}}
default:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerDied, Data: cid}, {ID: podID, Type: ContainerRemoved, Data: cid}}
}
default:
panic(fmt.Sprintf("unrecognized container state: %v", newState))
}
}
relist 的最后一個任務是檢查是否有與 Pod 關聯的事件,并按照下面的流程更新 podCache,
//// pkg/kubelet/pleg/generic.go - relist()
// If there are events associated with a pod, we should update the
// podCache.
for pid, events := range eventsByPodID {
pod := g.podRecords.getCurrent(pid)
if g.cacheEnabled() {
// updateCache() will inspect the pod and update the cache. If an
// error occurs during the inspection, we want PLEG to retry again
// in the next relist. To achieve this, we do not update the
// associated podRecord of the pod, so that the change will be
// detect again in the next relist.
// TODO: If many pods changed during the same relist period,
// inspecting the pod and getting the PodStatus to update the cache
// serially may take a while. We should be aware of this and
// parallelize if needed.
if err := g.updateCache(pod, pid); err != nil {
glog.Errorf("PLEG: Ignoring events for pod %s/%s: %v", pod.Name, pod.Namespace, err)
:
}
:
}
// Update the internal storage and send out the events.
g.podRecords.update(pid)
for i := range events {
// Filter out events that are not reliable and no other components use yet.
if events[i].Type == ContainerChanged {
continue
}
g.eventChannel <- events[i]
}
}
updateCache() 將會檢查每個 Pod,并在單個回圈中依次對其進行更新,因此,如果在同一個 relist 中更改了大量的 Pod,那么 updateCache 程序將會成為瓶頸,最后,更新后的 Pod 生命周期事件將會被發送到 eventChannel,
某些遠程客戶端還會呼叫每一個 Pod 來獲取 Pod 的 spec 定義資訊,這樣一來,Pod 數量越多,延時就可能越高,因為 Pod 越多就會生成越多的事件,
updateCache() 的詳細呼叫堆疊如下圖所示,其中 GetPodStatus() 用來獲取 Pod 的 spec 定義資訊:
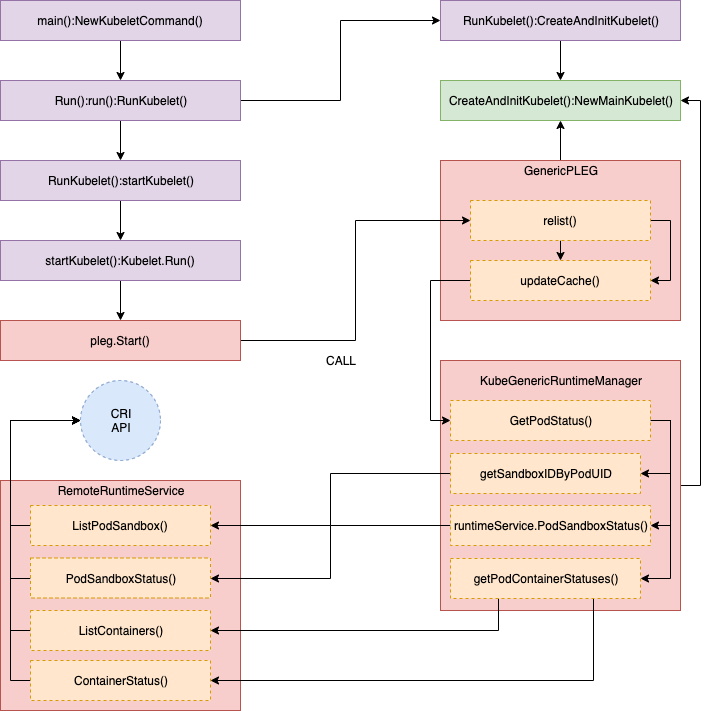
完整的代碼如下:
//// pkg/kubelet/pleg/generic.go - updateCache()
func (g *GenericPLEG) updateCache(pod *kubecontainer.Pod, pid types.UID) error {
:
timestamp := g.clock.Now()
// TODO: Consider adding a new runtime method
// GetPodStatus(pod *kubecontainer.Pod) so that Docker can avoid listing
// all containers again.
status, err := g.runtime.GetPodStatus(pod.ID, pod.Name, pod.Namespace)
:
g.cache.Set(pod.ID, status, err, timestamp)
return err
}
//// pkg/kubelet/kuberuntime/kuberuntime_manager.go - GetPodStatus()
// GetPodStatus retrieves the status of the pod, including the
// information of all containers in the pod that are visible in Runtime.
func (m *kubeGenericRuntimeManager) GetPodStatus(uid kubetypes.UID, name, namespace string) (*kubecontainer.PodStatus, error) {
podSandboxIDs, err := m.getSandboxIDByPodUID(uid, nil)
:
for idx, podSandboxID := range podSandboxIDs {
podSandboxStatus, err := m.runtimeService.PodSandboxStatus(podSandboxID)
:
}
// Get statuses of all containers visible in the pod.
containerStatuses, err := m.getPodContainerStatuses(uid, name, namespace)
:
}
//// pkg/kubelet/kuberuntime/kuberuntime_sandbox.go - getSandboxIDByPodUID()
// getPodSandboxID gets the sandbox id by podUID and returns ([]sandboxID, error).
// Param state could be nil in order to get all sandboxes belonging to same pod.
func (m *kubeGenericRuntimeManager) getSandboxIDByPodUID(podUID kubetypes.UID, state *runtimeapi.PodSandboxState) ([]string, error) {
:
sandboxes, err := m.runtimeService.ListPodSandbox(filter)
:
return sandboxIDs, nil
}
//// pkg/kubelet/remote/remote_runtime.go - PodSandboxStatus()
// PodSandboxStatus returns the status of the PodSandbox.
func (r *RemoteRuntimeService) PodSandboxStatus(podSandBoxID string) (*runtimeapi.PodSandboxStatus, error) {
ctx, cancel := getContextWithTimeout(r.timeout)
defer cancel()
resp, err := r.runtimeClient.PodSandboxStatus(ctx, &runtimeapi.PodSandboxStatusRequest{
PodSandboxId: podSandBoxID,
})
:
return resp.Status, nil
}
//// pkg/kubelet/kuberuntime/kuberuntime_container.go - getPodContainerStatuses()
// getPodContainerStatuses gets all containers' statuses for the pod.
func (m *kubeGenericRuntimeManager) getPodContainerStatuses(uid kubetypes.UID, name, namespace string) ([]*kubecontainer.ContainerStatus, error) {
// Select all containers of the given pod.
containers, err := m.runtimeService.ListContainers(&runtimeapi.ContainerFilter{
LabelSelector: map[string]string{types.KubernetesPodUIDLabel: string(uid)},
})
:
// TODO: optimization: set maximum number of containers per container name to examine.
for i, c := range containers {
status, err := m.runtimeService.ContainerStatus(c.Id)
:
}
:
return statuses, nil
}
上面就是 relist() 函式的完整呼叫堆疊,我在講解的程序中結合了相關的源代碼,希望能為你提供有關 PLEG 的更多細節,為了實時了解 PLEG 的健康狀況,最好的辦法就是監控 relist,
4. 監控 relist
我們可以通過監控 Kubelet 的指標來了解 relist 的延時,relist 的呼叫周期是 1s,那么 relist 的完成時間 + 1s 就等于 kubelet_pleg_relist_interval_microseconds 指標的值,你也可以監控容器運行時每個操作的延時,這些指標在排查故障時都能提供線索,
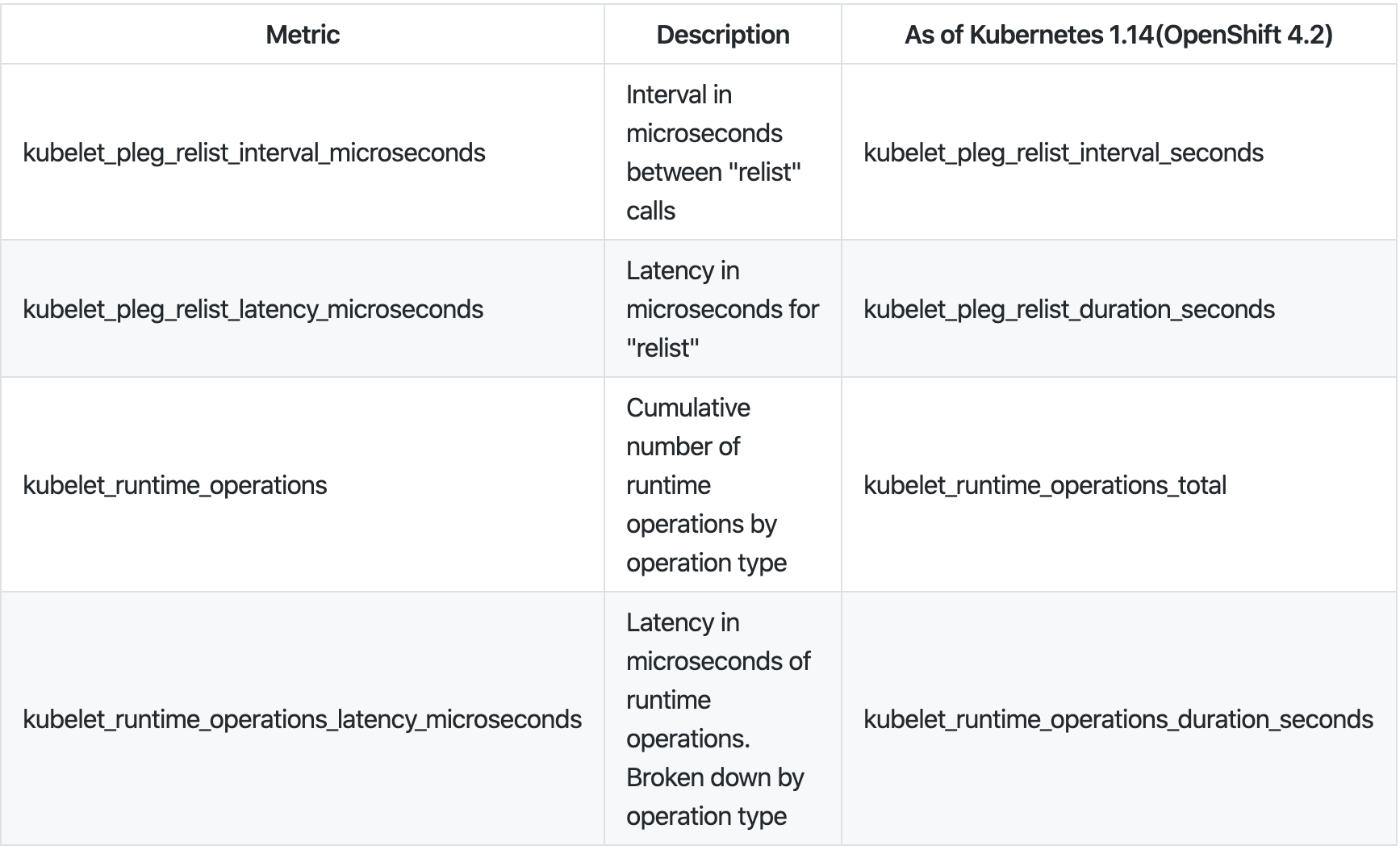
你可以在每個節點上通過訪問 URL https://127.0.0.1:10250/metrics 來獲取 Kubelet 的指標,
# HELP kubelet_pleg_relist_interval_microseconds Interval in microseconds between relisting in PLEG.
# TYPE kubelet_pleg_relist_interval_microseconds summary
kubelet_pleg_relist_interval_microseconds{quantile="0.5"} 1.054052e+06
kubelet_pleg_relist_interval_microseconds{quantile="0.9"} 1.074873e+06
kubelet_pleg_relist_interval_microseconds{quantile="0.99"} 1.126039e+06
kubelet_pleg_relist_interval_microseconds_count 5146
# HELP kubelet_pleg_relist_latency_microseconds Latency in microseconds for relisting pods in PLEG.
# TYPE kubelet_pleg_relist_latency_microseconds summary
kubelet_pleg_relist_latency_microseconds{quantile="0.5"} 53438
kubelet_pleg_relist_latency_microseconds{quantile="0.9"} 74396
kubelet_pleg_relist_latency_microseconds{quantile="0.99"} 115232
kubelet_pleg_relist_latency_microseconds_count 5106
# HELP kubelet_runtime_operations Cumulative number of runtime operations by operation type.
# TYPE kubelet_runtime_operations counter
kubelet_runtime_operations{operation_type="container_status"} 472
kubelet_runtime_operations{operation_type="create_container"} 93
kubelet_runtime_operations{operation_type="exec"} 1
kubelet_runtime_operations{operation_type="exec_sync"} 533
kubelet_runtime_operations{operation_type="image_status"} 579
kubelet_runtime_operations{operation_type="list_containers"} 10249
kubelet_runtime_operations{operation_type="list_images"} 782
kubelet_runtime_operations{operation_type="list_podsandbox"} 10154
kubelet_runtime_operations{operation_type="podsandbox_status"} 315
kubelet_runtime_operations{operation_type="pull_image"} 57
kubelet_runtime_operations{operation_type="remove_container"} 49
kubelet_runtime_operations{operation_type="run_podsandbox"} 28
kubelet_runtime_operations{operation_type="start_container"} 93
kubelet_runtime_operations{operation_type="status"} 1116
kubelet_runtime_operations{operation_type="stop_container"} 9
kubelet_runtime_operations{operation_type="stop_podsandbox"} 33
kubelet_runtime_operations{operation_type="version"} 564
# HELP kubelet_runtime_operations_latency_microseconds Latency in microseconds of runtime operations. Broken down by operation type.
# TYPE kubelet_runtime_operations_latency_microseconds summary
kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.5"} 12117
kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.9"} 26607
kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.99"} 27598
kubelet_runtime_operations_latency_microseconds_count{operation_type="container_status"} 486
kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.5"} 29972
kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.9"} 47907
kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.99"} 80982
kubelet_runtime_operations_latency_microseconds_count{operation_type="list_containers"} 10812
kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.5"} 18053
kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.9"} 28116
kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.99"} 68748
kubelet_runtime_operations_latency_microseconds_count{operation_type="list_podsandbox"} 10712
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.5"} 4918
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.9"} 15671
kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.99"} 18398
kubelet_runtime_operations_latency_microseconds_count{operation_type="podsandbox_status"} 323
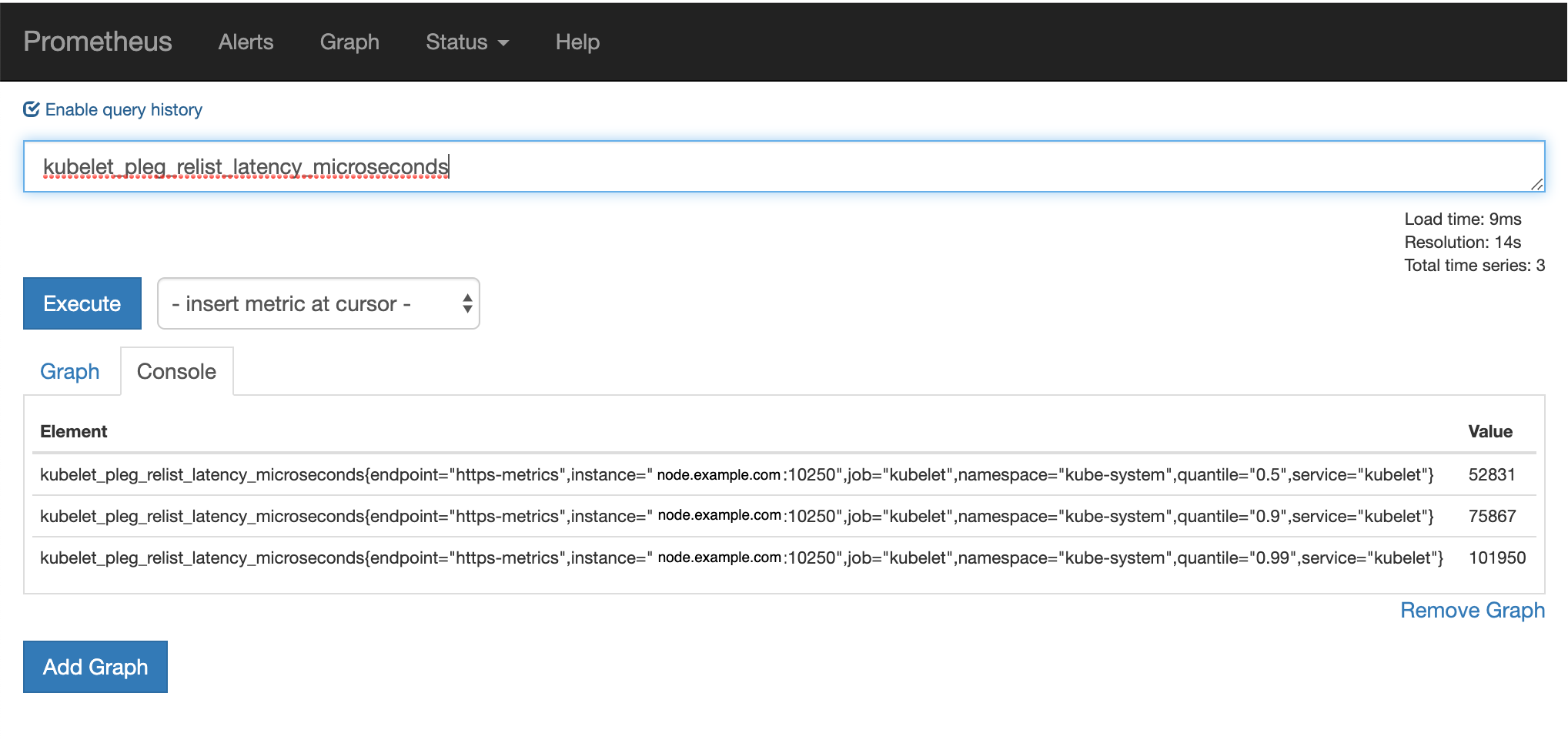
可以通過 Prometheus 對其進行監控:
5. 總結
以我的經驗,造成 PLEG is not healthy 的因素有很多,而且我相信還有更多潛在的因素我們還沒有遇到過,我只提供幾個我能想到的原因:
- RPC 呼叫程序中容器運行時回應超時(有可能是性能下降,死鎖或者出現了 bug),
- 節點上的 Pod 數量太多,導致
relist無法在 3 分鐘內完成,事件數量和延時與 Pod 數量成正比,與節點資源無關, - relist 出現了死鎖,該 bug 已在 Kubernetes 1.14 中修復,
- 獲取 Pod 的網路堆疊資訊時 CNI 出現了 bug,
6. 參考資料
- Kubelet: Pod Lifecycle Event Generator (PLEG)
- Kubelet: Runtime Pod Cache
- relist() in kubernetes/pkg/kubelet/pleg/generic.go
- Past bug about CNI — PLEG is not healthy error, node marked NotReady
微信公眾號
掃一掃下面的二維碼關注微信公眾號,在公眾號中回復?加群?即可加入我們的云原生交流群,和孫宏亮、張館長、陽明等大佬一起探討云原生技術

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41197.html
標籤:其他