原文鏈接:Kubernetes 控制器的進化之旅
我是一堆 Kubernetes 控制器,
你可能會疑惑為什么是一堆,因為我不是一個人,我只是眾多控制器中的一員,你也可以把我看成是眾多控制器的集合,我的職責就是監控集群內資源的實際狀態,一旦發現其與期望的狀態不相符,就采取行動使其符合期望狀態,
想當初,Kubernetes 老大哥創造我時,只是打算讓我用控制回圈簡單維護下資源的狀態,但我后來的發展,遠遠超出了他的想象,
1. 控制回圈
所謂控制回圈就是一個用來調節系統狀態的周期性操作,在 Kubernetes 中也叫調諧回圈(Reconcile Loop),我的手下控制著很多種不同型別的資源,比如 Pod,Deployment,Service 等等,就拿 Deployment 來說吧,我的控制回圈主要分為三步:
- 從
API Server中獲取到所有屬于該 Deployment 的 Pod,然后統計一下它們的數量,即它們的實際狀態, - 檢查 Deployment 的
Replicas欄位,看看期望狀態是多少個 Pod, - 將這兩個狀態做比較,如果期望狀態的 Pod 數量比實際狀態多,就創建新 Pod,多幾個就創建幾個新的;如果期望狀態的 Pod 數量比實際狀態少,就洗掉舊 Pod,少幾個就洗掉幾個舊的,
然而好景不長,我收到了 Kubernetes 掌門人(看大門的) API Server 的抱怨:“你訪問我的次數太頻繁了,非常消耗我的資源,我連上廁所的時間都沒有了!”
我仔細一想,當前的控制回圈模式確實有這個缺陷——訪問 API Server 的次數太頻繁了,容易被老大反感,
所以我決定,找一個小弟,
2. Informer
這次我招的小弟叫 Informer,它分擔一部分我的任務,具體的做法是這樣的:由 Informer 代替我去訪問 API Server,而我不管是查狀態還是對資源進行伸縮都和 Informer 進行交接,而且 Informer 不需要每次都去訪問 API Server,它只要在初始化的時候通過 LIST API 獲取所有資源的最新狀態,然后再通過 WATCH API 去監聽這些資源狀態的變化,整個程序被稱作 ListAndWatch,
而 Informer 也不傻,它也有一個助手叫 Reflector,上面所說的 ListAndWatch 事實上是由 Reflector 一手操辦的,
這一次,API Server 的壓力大大減輕了,因為 Reflector 大部分時間都在 WATCH,并沒有通過 LIST 獲取所有狀態,這使 API Server 的壓力大大減少,我想這次掌門人應該不會再批評我了吧,
然而沒過幾天,掌門人又找我談話了:“你的手下每次來 WATCH 我,都要 WATCH 所有兄弟的狀態,依然很消耗我的資源啊!我就納悶了,你一次搞這么多兄弟,你虎啊?”
我一想有道理啊,沒必要每次都 WATCH 所有兄弟的狀態,于是告訴 Informer:“以后再去 API Server 那里 WATCH 狀態的時候,只查 WATCH 特定資源的狀態,不要一股腦兒全 WATCH,“
Informer 再把這個決策告訴 Reflector,事情就這么愉快地決定了,
本以為這次我會得到掌門人的夸獎,可沒過幾天安穩日子,它又來找我訴苦了:“兄弟,雖然你減輕了我的精神壓力,但我的財力有限啊,如果每個控制器都招一個小弟,那我得多發多少人的工資啊,你想想辦法,”
3. SharedInformer
經過和其他控制器的討論,我們決定這么做:所有控制器聯合起來作為一個整體來分配 Informer,針對每個(受多個控制器管理的)資源招一個 Informer 小弟,我們稱之為 SharedInformer,你們可以理解為共享 Informer,因為有很多資源是受多個控制器管理的,比如 Pod 同時受 Deployment 和 StatefulSet 管理,這樣當多個控制器同時想查 Pod 的狀態時,只需要訪問一個 Informer 就行了,
但這又引來了新的問題,SharedInformer 無法同時給多個控制器提供資訊,這就需要每個控制器自己排隊和重試,
為了配合控制器更好地實作排隊和重試,SharedInformer 搞了一個 Delta FIFO Queue(增量先進先出佇列),每當資源被修改時,它的助手 Reflector 就會收到事件通知,并將對應的事件放入 Delta FIFO Queue 中,與此同時,SharedInformer 會不斷從 Delta FIFO Queue 中讀取事件,然后更新本地快取的狀態,
這還不行,SharedInformer 除了更新本地快取之外,還要想辦法將資料同步給各個控制器,為了解決這個問題,它又搞了個作業佇列(Workqueue),一旦有資源被添加、修改或洗掉,就會將相應的事件加入到作業佇列中,所有的控制器排隊進行讀取,一旦某個控制器發現這個事件與自己相關,就執行相應的操作,如果操作失敗,就將該事件放回佇列,等下次排到自己再試一次,如果操作成功,就將該事件從佇列中洗掉,(圖片來自網路)
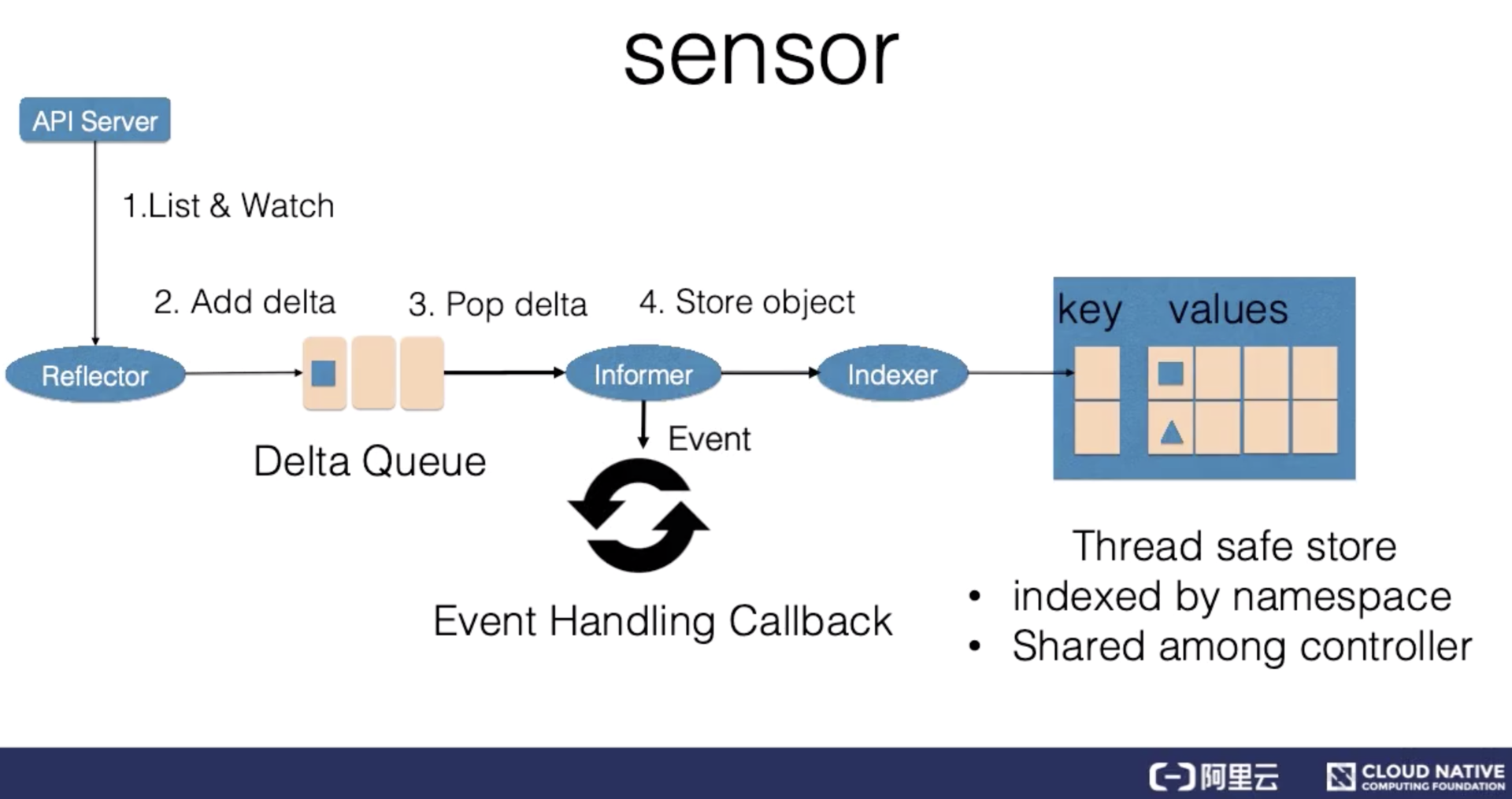
現在這個作業模式得到了大家的一致好評,雖然單個 SharedInformer 的作業量增加了,但 Informer 的數量大大減少了,老大可以把省下來的資金拿出一小部分給 SharedInformer 漲工資啊,這樣大家都很開心,
4. CRD
全民 Kubernetes 時代到了,
隨著容器及其編排技術的普及,使用 Kubernetes 的用戶大量增長,用戶已經不滿足 Kubernetes 自帶的那些資源(Pod,Node,Service)了,大家都希望能根據具體的業務創建特定的資源,并且對這些資源的狀態維護還要遵循上面所說的那一套控制回圈機制,
幸好最近掌門人做了一次升級,新增了一個插件叫 CRD(Custom Resource Definition),創建一個全新的資源實體,只需要經過以下兩步:
- 創建一個 CRD 資源(沒錯,CRD 也是一種資源型別),其中定義”自定義資源“的 API 組、API 版本和資源型別,這樣就會向 API Server 注冊該資源型別的 API,
- 指定上面定義的 API 組 和 API 版本,創建自定義資源,
當然,中間還要加入一些代碼讓 Kubernetes 認識自定義資源的各種引數,
到這一步就基本上完成了自定義資源的創建,但 Kubernetes 并不知道該資源所對應的業務邏輯,比如你的自定義資源是宿主機,那么對應的業務邏輯就是創建一臺真正的宿主機出來,那么怎樣實作它的業務邏輯呢?
5. 自定義控制器
Controller Manager 見多識廣,說:”這里的每個控制器都是我的一部分,當初創造你們是因為你們都屬于通用的控制器,大家都能用得上,而自定義資源需要根據具體的業務來實作,我們不可能知道每個用戶的具體業務是啥,自己一拍腦袋想出來的自定義資源,用戶也不一定用得上,我們可以讓用戶自己撰寫自定義控制器,你們把之前使用的控制回圈和 Informer 這些編碼模式總結一下,然后提供給用戶,讓他們按照同樣的方法撰寫自己的控制器,“
Deployment 控制器一驚,要把自己的秘密告訴別人?那別人把自己取代了咋辦?趕忙問道:”那將來我豈不是很危險,沒有存在的余地了?“
Controller Manager 趕忙解釋道:”不用擔心,雖然用戶可以撰寫自定義控制器,但無論他們玩出什么花樣,只要他們的業務跑在 Kubernetes 平臺上,就免不了要跑容器,最后還是會來求你們幫忙的,你要知道,控制器是可以層層遞進的,他們只不過是在你外面套了一層,最后還是要回到你這里,請求你幫忙控制 Pod,“
這下大家都不慌了,決定就把自定義控制器這件事情交給用戶自己去處理,將選擇權留給用戶,
6. Operator
用戶自從獲得了撰寫自定義控制器的權力之后,非常開心,有的用戶(CoreOS)為了方便大家控制有狀態應用,開發出了一種特定的控制器模型叫 Operator,并開始在社區內推廣,得到了大家的一致好評,不可否認,Operator 這種模式是很聰明的,它把需要特定領域知識的應用單獨寫一個 Operator 控制器,將這種應用特定的操作知識撰寫到軟體中,使其可以利用 Kubernetes 強大的抽象能力,達到正確運行和管理應用的目的,
以 ETCD Operator 為例,假如你想手動擴展一個 ETCD 集群,一般的做法是:
- 使用 ETCD 管理工具添加一個新成員,
- 為這個成員所在的節點生成對應的啟動引數,并啟動它,
而 ETCD Operator 將這些特定于 etcd 的操作手法撰寫到了它的控制回圈中,你只需要通過修改自定義資源宣告集群期望的成員數量,剩下的事情交給 Operator 就好了,(圖片來自網路)

本以為這是一個皆大歡喜的方案,但沒過多久,就有開發 Operator 的小哥來抱怨了:”我們有很多開發的小伙伴都是不懂運維那一套的,什么高可用、容災根本不懂啊,現在讓我們將運維的操作知識撰寫到軟體中,臣妾做不到啊,,“
這確實是個問題,這樣一來就把開發和運維的作業都塞到了開發手里,既懂開發又懂運維的可不多啊,為了照顧大家,還得繼續想辦法把開發和運維的作業拆分開來,
7. OAM
這時候阿里和微軟發力了,他們聯合發布了一個開放應用模型,叫 Open Application Model (OAM),這個模型就是為了解決上面提到的問題,將開發和運維的職責解耦,不同的角色履行不同的職責,并形成一個統一的規范,如下圖所示(圖片來自網路):
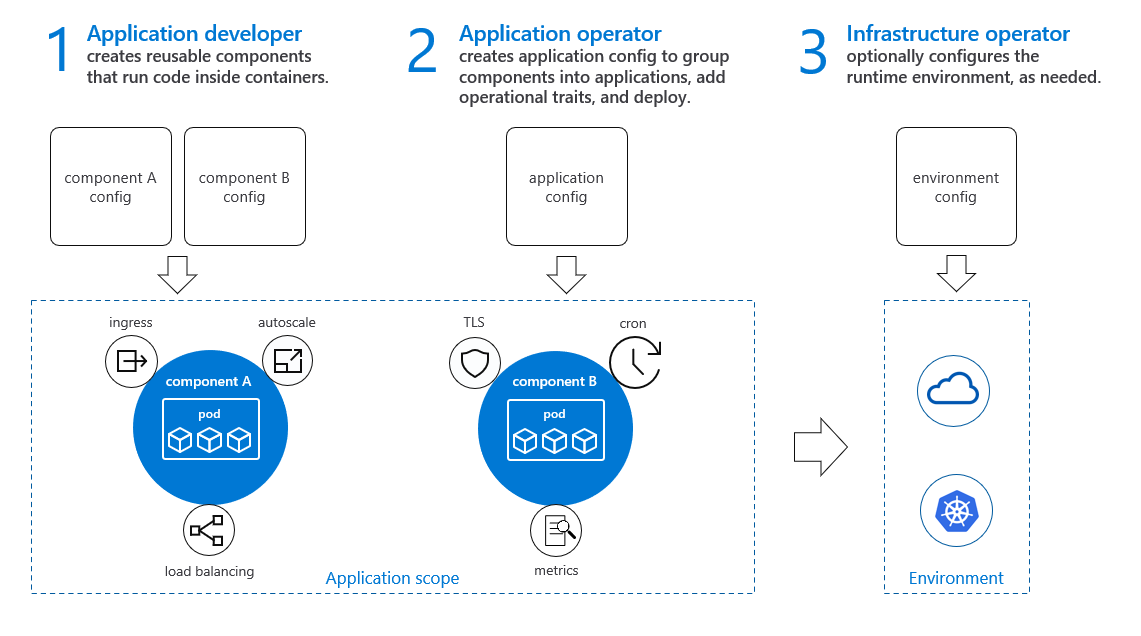
這個規范告訴我們:
- 開發人員負責描述組件的功能,如何配置組件,以及運行需要多少資源
- 運維人員負責將相關組件組合成一個應用,并配置運行時引數和運維支撐能力,比如是否需要監控,是否需要彈性伸縮,
- 基礎設施工程師負責建立和維護應用的運行時環境(如底層系統),
其中每一個團隊負責的事情都用對應的 CRD 來配置,
這樣一來,開發和運維人員的職責就被區分開來了,簡化了應用的組合和運維,它將應用的配置和運維特征(如自動伸縮、流量監控)進行解耦,然后通過建模構成一個整體,避免了 Operator 這種模型帶來的大量冗余,
自從用上了這個模型之后,運維和開發小哥表示現在他們的關系很融洽,沒事還能一起出去喝兩杯,
微信公眾號
掃一掃下面的二維碼關注微信公眾號,在公眾號中回復?加群?即可加入我們的云原生交流群,和孫宏亮、張館長、陽明等大佬一起探討云原生技術

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41237.html
標籤:其他