目錄
- 注:本實驗的源代碼和測驗資料已經上傳到git上,鏈接如下:
- 一、實驗目的
- 二、實驗內容與設計思想
- 三、實驗使用環境
- 四、實驗步驟和除錯程序
- 4.1 通過簡單例子理解k-近鄰演算法
- 4.2 分析k-近鄰演算法在改進約會網站中的應用
- 4.2.1 題目說明
- 4.2.2 源代碼決議(運用kNN演算法求解的一般步驟決議)
- 匯入的模塊
- 1. 準備資料:從文本檔案中決議資料→file2matrix(filename)函式
- 2. 分析資料:使用Matplotlib創建散點圖→show_file2matrix()函式
- 3. 準備資料:歸一化數值→autoNorm(dataSet)函式
- 4. 測驗演算法:作為完整程式驗證分類器→datingClassTest()函式
- 5. 使用演算法:構建完整的可用體系→classifyPerson()函式
- 4.3 通過對kNN演算法的理解,自己撰寫改進約會網站主要運行代碼
- 4.4 分析k-近鄰演算法在手寫識別系統中的應用
- 4.4.1 題目說明
- 4.4.2 源代碼決議(運用kNN演算法求解的一般步驟決議)
- 匯入模塊
- 1. 準備資料:將影像轉化為測驗向量→img2vector()函式
- 2. 測驗演算法:使用k-近鄰演算法識別手寫數字→handwritingClassTest()函式
- 五、實驗小結
- 六、參考資料
注:本實驗的源代碼和測驗資料已經上傳到git上,鏈接如下:
注:Vanish/kNN_Example
一、實驗目的
- 通過簡單例子學習k-近鄰演算法的原理,
- 使用k-近鄰演算法改進約會網站,
- 使用k-近鄰演算法撰寫手寫識別系統,
二、實驗內容與設計思想
實驗內容:
-
理解k-近鄰演算法的原理,學習簡單例子,
-
通過閱讀資料中的“2.2節使用k-maean演算法改進約會網站效果”,參照代碼自己敲一遍,并通過資料中的講解,對代碼進行一步步的分析和注釋,
-
最后通過自己對k-近鄰演算法求解約會網站效果的理解,動手自己寫一遍代碼,
設計思想:
-
k-近鄰演算法對約會網站的決議的設計思想:
- 收集資料:上網查閱資料獲得的文本檔案(“datingTestSet2.txt”資料檔案)
- 準備資料:使用Python決議文本檔案
- 分析資料:使用Matplotlib畫二維擴散圖
- 訓練演算法:該步驟不適用于k-近鄰演算法
- 測驗演算法:使用上面文本檔案中的部分資料作為測驗樣本,
- 使用演算法:產生簡單的命令列運行程式,讓海倫可以通過輸入一些特征資料就可以判斷出對方是否是自己喜歡的型別,
-
k-近鄰演算法在手寫識別系統的設計思想:
- 收集資料:提供文本檔案,網上查閱資料獲得(trainingDigits檔案夾和testDigits檔案夾下的資料檔案)
- 準備資料:撰寫img2vector()函式,將影像格式轉化為分類器使用的list格式,
- 分析資料:在Python命令提示符中檢查資料,確保符合要求,
- 訓練演算法:此步驟不適用于k-近鄰演算法
- 測驗演算法:撰寫函式使用提供的部分資料集作為測驗樣本,測驗樣本與非測驗樣本的區別在于測驗樣本已經完成分類的資料,如果分類器得到的預測分類與實際類別不同,則標記為一次錯誤,
- 使用演算法:通過自己創建一個32×32陣列形式的數字影像,運用上訴演算法進行測驗數字類別,
三、實驗使用環境
- 作業系統:Microsoft Windows 10
- 編程環境:Python 3.6、pycharm
四、實驗步驟和除錯程序
4.1 通過簡單例子理解k-近鄰演算法
-
匯入的庫:
from numpy import * import operator -
k-近鄰演算法的核心--分類器函式classify()說明:
def classify(inX, dataSet, labels, k): """ 分類器,通過距離計算公式,來獲得最終的分類結果, :param inX: 傳入需要測驗的串列 :param dataSet: 特征集合 :param labels: 類別集合 :param k: 匹配次數 :return: 回傳訓練結果,即所屬型別 """ # 歐式距離公式:d = [(xA0 - xB0)^2 + (xA1 - xB1)^2]^0.5 dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances ** 0.5 # 獲得排序后各個值在原陣列中的索引 sortedDistIndicies = distances.argsort() classCount = {} # 選擇距離最小的k個點進行統計 for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 逆序排序,獲得票數最多的特征值 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]小結:
-
歐式距離公式:
\[d= √[(xA_0-xB_0)^2+(xA_1-xB_1)^2 ] \]
-
該公式是k-近鄰演算法的核心所在,通過計算目標點到給定資料集中的各個點的距離,并取出離目標點最近的k個點,統計這k個點所屬的型別的數量,得到數量最多的型別作為目標點的最終型別,即為
k-近鄰演算法, -
簡單點說,k-近鄰演算法采用測量不同特征值之間的距離方法進行分類,
-
-
createDataSet()函式說明:
def createDataSet(): """ 一個簡單的測驗例子, :return: """ # group是一個簡單的特征資料集 group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) # labels是上面的各個特征最終所對應的型別 labels = ['A', 'A', 'B', 'B'] # 通過classify函式來判斷[0, 0]這個特征所屬型別 print('分類器求得的最終型別是:%s' % (classify([0, 0], group, labels, 3))) if __name__ == '__main__': createDataSet()輸出:
分類器求得的最終型別是:B
小結:
- 通過createDataSet()這個函式,可以看到,要使用k-近鄰演算法,我們首先需要要有一些現成的樣本,樣本可以幫助我們找到資料的一般性規律,函式中的
group即為一份簡單樣本資料,其次這些樣本我們要知道這些樣本資料所屬的型別,函式中的labels充當的就是這個角色,最終我們可以通過classify()這個函式來判斷[0, 0]這個特征所屬的型別,
- 通過createDataSet()這個函式,可以看到,要使用k-近鄰演算法,我們首先需要要有一些現成的樣本,樣本可以幫助我們找到資料的一般性規律,函式中的
4.2 分析k-近鄰演算法在改進約會網站中的應用
4.2.1 題目說明
? 我的朋友海倫一直使用在線約會網站尋找適合自己的約會物件,盡管約會網站會推薦不同的人選,但她并不喜歡每一個人,經過一番總結,她發現曾交往過三種型別的人:
-
不喜歡的人
-
魅力一般的人
-
極具魅力的人
盡管發現了上述規律,但海倫依然無法將約會網站推薦的匹配物件歸入恰當的分類,她覺得可以在周一到周五約會那些魅力一般的人,而周末則更喜歡與那些極具魅力的人為伴,海倫希望我們的分類軟體可以更好地幫助她將匹配物件劃分到確切的分類中,此外海倫還收集了一些約會網站未曾記錄的資料資訊,她認為這些資料更有助于匹配物件的歸類,
收集的資料如下:
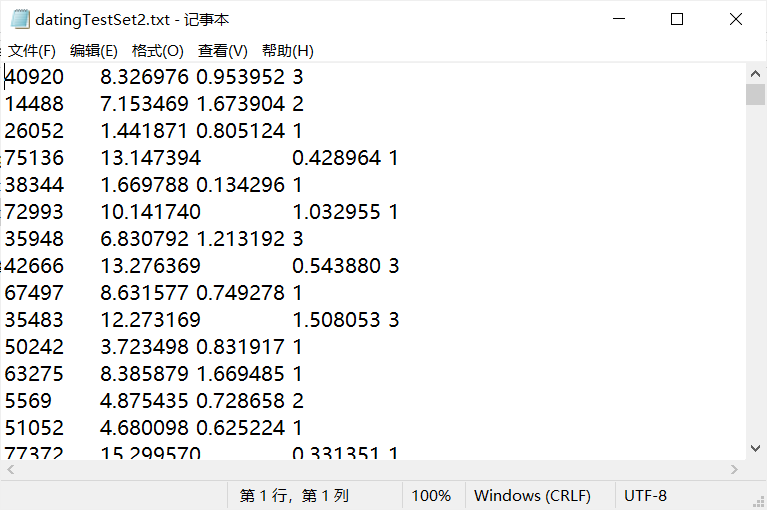
資料說明:
前三列分別表示:
-
每年獲得的飛行常客歷程數
-
玩視頻游戲所耗時間百分比
-
每周消費的冰淇淋公升數
最后一串列示:
- 1表示不喜歡的人
- 2表示魅力一般的人
- 3表示極具魅力的人
4.2.2 源代碼決議(運用kNN演算法求解的一般步驟決議)
匯入的模塊
from numpy import *
import matplotlib.pyplot as plt
import operator
1. 準備資料:從文本檔案中決議資料→file2matrix(filename)函式
def file2matrix(filename):
"""
讀取檔案中的資料,進行格式化處理,并存盤到相應的陣列中
:param filename: 要讀取的檔案路徑和檔案名
:return: returnMat, classLabelVector
returnMat中存盤每行3個資料的二維陣列,三個資料分別表示:
1.每年獲得的飛行常客歷程數
2.玩視頻游戲所耗時間百分比
3.每周消費的冰淇淋公升數
classLabelVector中存盤的是檔案中每行的最后一個字串,表示所屬型別,
"""
# 分割字串,每一個tab鍵分割出一個字串
fr = open(filename)
# 將檔案中的資料以行的形式,存入到arrayOLines
arrayOLines = fr.readlines()
# 計算arrayOLines的存盤的記錄數量
numberOfLines = len(arrayOLines)
"""
給returnMat這個陣列賦值,zeros函式是默認給每個位置賦值為0
其中zeros函式中的括號中的內容表示生成一個:
行數為numberOfLines,列數為3的的二維陣列,
"""
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
# 去除一行字串的首尾空格或換行符
line = line.strip()
# 分割字串,每一個tab鍵分割出一個字串
listFromLine = line.split('\t')
"""
陣列returnMat[index, :]中:
index是陣列的索引值
冒號":"是切片符
即將后面的listFromLine[0: 3]陣列中取出三個值,加入到returnMat陣列的第index行,
"""
returnMat[index, :] = listFromLine[0: 3]
# 將檔案中的每一行的最后一個字串依次加入到classLabelVector中,
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
小結:
- 通過將文本中的資料提取出來,并格式化成想要的格式的矩陣,便于后面操作使用,通過該操作,便于后面直接通過文本檔案中決議出來的資料矩陣進行操作,節省了后面每次都要從文本匯總取資料的操作,
- 在對矩陣的操作中,我們用到了NumPy庫中的相應的函式:
zeros()函式:生成一個所有元素都是0的矩陣(俗稱多個zero加s)- 如果是一維矩陣,只要傳入一個值代表列數即可,如果是二維矩陣,則需要傳入一個串列(m, n),表示生成m行n列的矩陣,三維矩陣以此類推,
- 與之類似的NumPy函式有
ones(),表示生成全為1的矩陣,
2. 分析資料:使用Matplotlib創建散點圖→show_file2matrix()函式
def show_file2matrix():
"""
圖形化展示資料,清晰展示三個不同樣本分類區域,具有不同愛好的人其類別區域也不同
:return:
"""
Mat, Labels = file2matrix('datingTestSet2.txt')
# figure()操作時創建或者呼叫畫板,使用時遵循就近原則,所有畫圖操作是在最近一次呼叫的畫圖板上實作,
fig = plt.figure('特征關系圖')
# add_subplot()函式表示在影像在網格中顯示的位置,111表示“1×1網格數,第1個網格,(111)可以替代為(1, 1, 1)
ax = fig.add_subplot(111)
"""
scatter()函式為繪圖功能,其中:
第一個引數和第二個引數分別表示x軸和y軸的坐標,一一對應,
第三個引數表示圖中顯示的點的大小,這里×15是為了讓點更大,更清晰,
第四個引數表示圖中點的顏色,使用Labels陣列中的不同值使不同型別顯示不同顏色,
這里的x軸和y軸的值選擇的是資料集中的第1列和第2列主要原因:
三種型別在這兩種特征下區分比較明顯,
"""
ax.scatter(Mat[:, 0], Mat[:, 1], 15 * array(Labels), 15.0 * array(Labels))
plt.show() # 顯示影像
輸出影像:
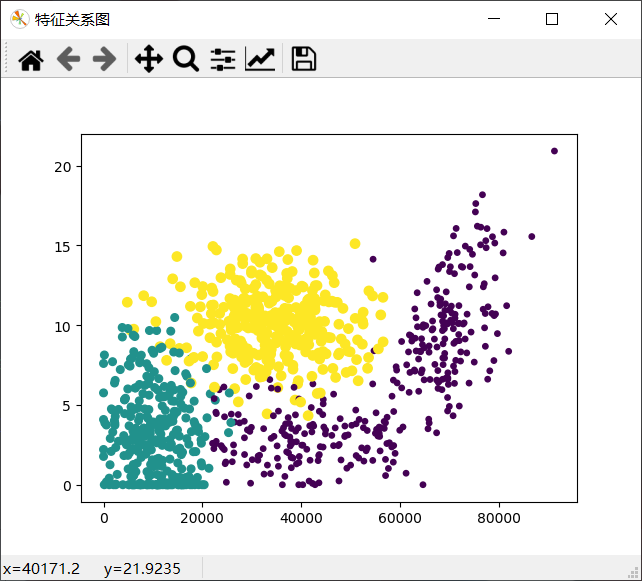
小結:
-
創建散點圖的目的是什么?
為了了解給定資料的真實含義,當然我們可以通過直接瀏覽文本檔案來分析資料的含義,但顯然,干巴巴的資料看起來是非常死板的,從1000條資料中提取有效資訊時非常困難的,也是非常不友好的,所以采用圖形化的方式直觀展示資料,
-
上面圖形化得到的效果非常的清晰地標識了三個不同的樣本分類區域,具有不同愛好的人其類別區域也不同,
-
上面圖形化效果的呈現使用的x軸和y軸分別是特征中的:每年獲得的飛行常客里程數和玩視頻游戲所耗時間百分比,展示的效果較其他使用其他兩種型別的好,這里我們通過修改上面函式中的下面這一句的代碼,來看看用其他特征值呈現的效果:
ax.scatter(Mat[:, 0], Mat[:, 1], 15*array(Labels), 15.0 * array(Labels))通過修改前兩個引數來實作,
1.修改方案一:
x軸表示:玩視頻游戲所耗時間百分比,
ax.scatter(Mat[:, 1], Mat[:, 2], 15*array(Labels), 15.0 * array(Labels))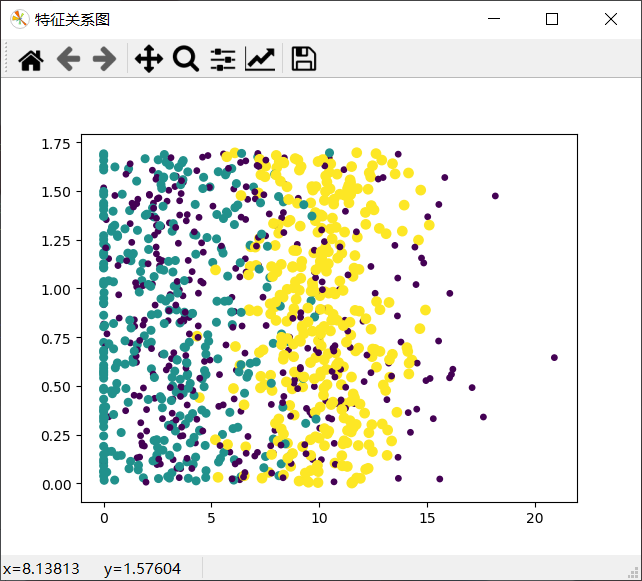
2.修改方案二:
x軸表示:每年獲得的飛行常客里程數,
y軸表示:每周消費的冰淇淋公升數,
ax.scatter(Mat[:, 0], Mat[:, 2], 15*array(Labels), 15.0 * array(Labels))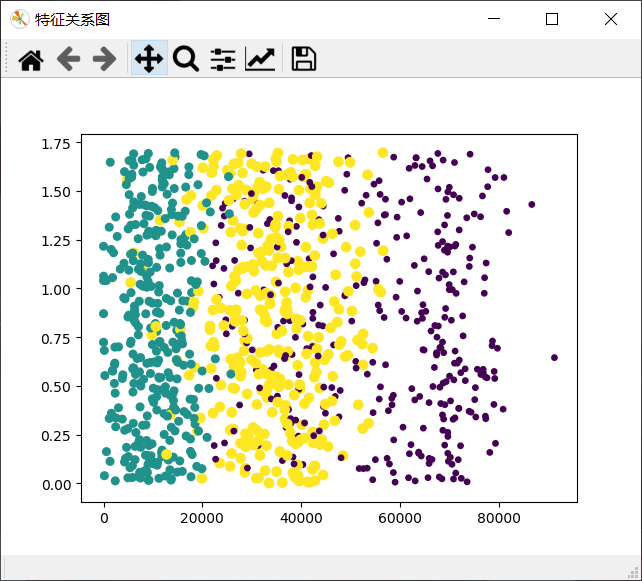
通過三個效果圖的對比可以看出,運用0,1列展示的效果最佳,可以清晰地表示三個不同樣本分類區域,
3. 準備資料:歸一化數值→autoNorm(dataSet)函式
def autoNorm(dataSet):
"""
數值歸一化,可以自動將數字特征值轉化為0到1區間的值,表示所占比例
歸一化處理的目的是:讓資料中所有特征的權重一樣,
數值歸一化公式:(特征值-min)/(max-min)
:param dataSet: 傳入上面已經格式化好的資料陣列
:return:normDataSet, ranges, minVals
normDataSet:數值歸一化后的陣列
ranges:1×3陣列,maxVals - minVals
minVals:陣列中每列選取的最小值
"""
"""
dataSet.min(0)中的引數0使得函式可以從每列中選取最小值,而不是選取當前行的最小漢字,
同理:dataSet.max(0)是從陣列的每列中選取最大值
這里獲得的minVals和maxVals都是1×3的陣列
"""
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
# 計算(max-min)的部分
ranges = maxVals - minVals
# 生成一個和dataSet同行數同列數的陣列,陣列中的資料全部填充為0
normDataSet = zeros(shape(dataSet))
"""
shape方法本身回傳的是陣列的結構,例:二維陣列:回傳的是(m, n),表示m行n列
此時shape[0]中就是m行的意思了
"""
m = dataSet.shape[0]
"""
tile函式是對資料進行格式化處理
tile(minVals, (m, 1))中的minVals表示要被格式化的陣列,
(m, 1)表示生成一個m行,每行一個minVals陣列的陣列
"""
normDataSet = dataSet - tile(minVals, (m, 1)) # 就算(特征值-min)部分
# 數值歸一化公式:(特征值-min)/(max-min)
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
小結:
-
歸一化數值的公式:
\[n = (x-min)/(max-min)(0<n<1.0) \]
-
為什么要數值歸一化?
觀察文本檔案中的資料,我們可以發現,飛行常客里程數這一特征值相對于其他特征值在數值上大的多,當我們運用歐式距離公式計算的時候,該特征值的對于結果的影響遠大于其他兩個特征值(玩視頻游戲所耗時間百分比、每周消費冰激凌公升數)的影響,
而對于該問題來說,三種特征值應該同等重要,通過數值歸一化可以讓任意范圍的的特征值轉化為0到1區間的值,即可以認為是某特征值占總特征值的比例,最后所有資料的范圍都在0到1之間,即可實作特征值同等重要性,
-
NumPy相關函式決議:
-
min()函式:顧名思義就是得到最小值,但用在陣列中則計算的方式就有點不一樣了,min(0)表示從一列中的所有行中取出最小值,形成一個1×n陣列,
min(1)表示從一行中的所有列中取出最小值,形成一個n×1陣列,
-
max()函式:顧名思義取最大值,max(0)和max(1)效果同上, -
tile(array, (m,n))函式:表示生成一個m行,每列n個array陣列的矩陣, -
shape()函式:獲得陣列的行列數,例:二維陣列,回傳一個(m, n)的串列,表示m行n列,此時如果使用shape[0]回傳的就是m行,
-
4. 測驗演算法:作為完整程式驗證分類器→datingClassTest()函式
分類器函式classify():(同上面簡單例子中的分類器函式)
def classify(inX, dataSet, labels, k):
"""
分類器,訓練模塊,計算某些特征所屬型別
:param inX: 傳入需要測驗的串列
:param dataSet: 特征集合
:param labels: 類別集合
:param k: 匹配次數
:return: 回傳訓練結果,即所屬型別
"""
# 因為dataSet是一個二維陣列,(m, n)表示m行n列,shape[0]獲得m行的數量
dataSetSize = dataSet.shape[0]
"""
tile函式用于生成一個dataSetSize行數,inX列數的二維陣列
將新生成的二維陣列的每個值依次減去dataSet這個陣列中的各個值
"""
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# diffMat陣列中的各個值平方
sqDiffMat = diffMat ** 2
# .sum(axis=1)中axis為1時表示按行的方向相加;axis為0時表示按列的方向相加
sqDistances = sqDiffMat.sum(axis=1)
# 再將上面得到的各個和值分別開根號,求得兩點之間的距離
distances = sqDistances ** 0.5
"""
argsort()函式功能說明:回傳的是陣列值從小到大的索引值,
例:[3, 2, 1]這個陣列,使用argsort()函式,經歷的步驟:
1.排序:[1, 2, 3]
2.得到排序后各個值所對應的原陣列中的索引:1對應的索引值為2,2對應的索引值為1,3對應的索引值為0,
3.最后回傳的陣列為[2, 1, 0]
"""
# argsort函式回傳的是distances這個陣列中的值從小到大的索引值
sortedDistIndicies = distances.argsort()
classCount = {}
# 該for陳述句用來取出離目標資料最近的k個點
for i in range(k):
# 通過獲得的最小k個值在原來陣列中的索引值,可以從labels陣列中得到該索引下所對應的喜歡型別和程度
voteIlabel = labels[sortedDistIndicies[i]]
# 字典處理方式,get方法中voteIlabel是key值,0是當字典中不存在voteIlabel時,給它賦默認值0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 對classCount這個字典的value值進行逆序排序,使得取第一個數為最大值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 回傳字典中的最大值,即演算法計算得到的最接近的型別
return sortedClassCount[0][0]
測驗分類器函式datingClassTest():
def datingClassTest():
"""
選取10%的資料來測驗分類器的性能,即測驗分類器分析資料的錯誤率,
:return:
"""
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
# 因為normMat是一個二維陣列,(m, n)表示m行n列,shape[0]獲得m行的數量
m = normMat.shape[0]
# 取總資料的10%作為測驗資料
numTestVecs = int(m * hoRatio)
errorCount = 0.0
"""
遍歷所有測驗資料,讓測驗資料原檔案中正確的結果和分類器得到的結果進行對比,
對不正確的情況的數量進行統計,用于最后計算錯誤率,
"""
for i in range(numTestVecs):
"""
切片理解:
normMat[i, :],其中方括號中的逗號前后分別表示對行和列的切片,:前后沒有值,表示取所有列的值,整個表示取第i行所有列的值
normMat[numTestVecs: m, :],同上,整個表示取出numTestVecs行到m行的所有列的值
datingLabels[numTestVecs: m],表示取出numTestVecs列到m列的值
"""
classifierResult = classify(normMat[i, :], normMat[numTestVecs: m, :],
datingLabels[numTestVecs: m], 3)
print("%d: 分類器回傳的結果是: %d, 真正的答案是:%d" % (i,
classifierResult, datingLabels[i]))
# 當分類器得到的型別和原資料中的型別不同時,錯誤數加1
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("分類器處理約會資料集的錯誤率為: %f" % (errorCount / float(numTestVecs)))
輸出:
0: 分類器回傳的結果是: 3, 真正的答案是:3
1: 分類器回傳的結果是: 2, 真正的答案是:2
2: 分類器回傳的結果是: 1, 真正的答案是:1
... ...
97: 分類器回傳的結果是: 2, 真正的答案是:2
98: 分類器回傳的結果是: 1, 真正的答案是:1
99: 分類器回傳的結果是: 3, 真正的答案是:1
分類器處理約會資料集的錯誤率為: 0.050000
小結:
- 通過上面的測驗可以看到,分類器處理約會資料集的錯誤率是5.0%,是一個不錯的結果,可以通過datingClassTest的引數k,錯誤率會有一定的起伏變化,依賴于分類演算法、資料集合程式設定,分類器的輸出結果可能有很大的不同,
- 因為錯誤率較低,所以完全可以使用該程式來判斷海倫輸入的物件資訊,給出判斷的最終型別,
- 小知識:機器學習演算法一個很重要的作業就是評估演算法的正確率,通過我們已有的資料的90%作為訓練樣本來訓練分類器,而使用其余的10%資料取測驗分類器,檢測分類器的正確率,通過得到的正確率判斷該分類器是否可以真正應用到現實中,
5. 使用演算法:構建完整的可用體系→classifyPerson()函式
def classifyPerson():
"""
通過資料處理和分類器的篩選,得到相應特征下的人所屬的類別,
:return:
"""
resultList = ['不喜歡的人', '魅力一般的人', '極具魅力的人']
ffMiles = float(input("每年獲得的飛行常客歷程數:"))
percentTats = float(input("玩視頻游戲所耗時間百分比:"))
iceCream = float(input("每年消費冰淇淋公升數:"))
datingDataMat, datingLabels = file2matrix("datingTestSet2.txt")
normMat, ranges, minVals = autoNorm(datingDataMat)
# 將上面用戶輸入的資料,整合到一個陣列中
inArr = array([ffMiles, percentTats, iceCream])
# (inArr - minVals) / ranges 對inArr中的數值進行歸一化處理
classifierResult = classify((inArr - minVals) / ranges, normMat, datingLabels, 3)
print("你對這個人的印象是:", resultList[classifierResult - 1])
輸出:
每年獲得的飛行常客歷程數:40000
玩視頻游戲所耗時間百分比:8
每年消費冰淇淋公升數:0.9
你對這個人的印象是: 極具魅力的人
小結:
- 注意這里我們輸入的特征資料要進行歸一化處理,在傳入分類器中判斷型別,
4.3 通過對kNN演算法的理解,自己撰寫改進約會網站主要運行代碼
from numpy import *
import operator
__author__ = 'zjw'
def fileToMatrix(fileName):
"""
將檔案轉為相應的矩陣
:param fileName: 檔案路徑和檔案名
:return:
eigenvalueMatrix:特征值矩陣
typeMatrix:型別矩陣
"""
file = open(fileName)
lines = file.readlines()
numOfLines = len(lines)
eigenvalueMatrix = zeros((numOfLines, 3))
typeMatrix = zeros(numOfLines)
index = 0
for line in lines:
line = line.strip()
line = line.split("\t")
eigenvalueMatrix[index, 0:3] = line[0:3]
typeMatrix[index] = line[-1]
index += 1
return eigenvalueMatrix, typeMatrix
def eigenvalueNormalization(eigenvalueMatrix):
"""
特征值歸一化,使所有特征值所占權重相等,
單一特征值歸一化公式:
(特征值-min)/(max-min)
:param eigenvalueMatrix:特征矩陣
:return:
"""
# 取出每列所對應的所有行中的最大值/最小值,形成一個以為矩陣賦值給maxValues/minValues
maxValues = eigenvalueMatrix.max(0)
minValues = eigenvalueMatrix.min(0)
ranges = maxValues - minValues
numOfRows = len(eigenvalueMatrix)
# 特征值-min矩陣
eigenvalueSubMinMatrix = zeros(shape(eigenvalueMatrix))
# max-min矩陣
rangesMatrix = zeros(shape(eigenvalueMatrix))
for i in range(numOfRows):
eigenvalueSubMinMatrix[i, :] = eigenvalueMatrix[i, :] - minValues[:]
rangesMatrix[i, :] = ranges[:]
normEigenvalueMatrix = eigenvalueSubMinMatrix / rangesMatrix
return normEigenvalueMatrix, ranges, minValues
def classify(toBeJudged, normEigenvalueMatrix, typeMatrix, k):
"""
分類器,通過計算獲得帶判斷特征的型別
:param toBeJudged:待判斷的特征型別
:param normEigenvalueMatrix:歸一化特征值矩陣
:param typeMatrix:型別矩陣
:param k:k個最近型別
:return:
"""
numOfRows = len(normEigenvalueMatrix)
judgeMatrix = zeros(shape(normEigenvalueMatrix))
for i in range(numOfRows):
judgeMatrix[i, :] = toBeJudged[:]
squareMatrix = (normEigenvalueMatrix - judgeMatrix) ** 2
sumMatrix = squareMatrix.sum(axis=1)
distancesMatrix = sumMatrix ** 0.5
sortedDistancesMatrix = distancesMatrix.argsort()
eachOfCount = {}
for i in range(k):
index = sortedDistancesMatrix[i]
eachOfCount[typeMatrix[index]] = eachOfCount.get(typeMatrix[index], 0) + 1
sortedEachOfCount = sorted(eachOfCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedEachOfCount[0][0]
if __name__ == '__main__':
eigenvalueMatrix, typeMatrix = fileToMatrix('datingTestSet2.txt')
normEigenvalueMatrix, ranges, minValues = eigenvalueNormalization(eigenvalueMatrix)
dis = float(input("每年獲得的飛行常客歷程數:"))
per = float(input("玩視頻游戲所耗時間百分比:"))
ice = float(input("每年消費冰淇淋公升數:"))
toBeJudged = array([dis, per, ice])
normJudged = (toBeJudged - minValues) / ranges
type = classify(normJudged, normEigenvalueMatrix, typeMatrix, 3)
typeOfPeople = ['不喜歡的人', '魅力一般的人', '極具魅力的人']
print(typeOfPeople[int(type) - 1])
輸出:
每年獲得的飛行常客歷程數:40000
玩視頻游戲所耗時間百分比:8
每年消費冰淇淋公升數:0.9
極具魅力的人
小結:
- 可以看到這里得到的測驗結果和上面的測驗結果一致,在外面進行了幾組測驗也是一致的,
- 通過自己撰寫主要的演算法步驟,來生成判斷物件型別的分類器,可以實作基本的判斷約會網站物件的演算法,但是這里我省去了
分析資料和測驗資料兩個步驟,因為上面的主要程式中已經完成了這兩方面的測驗,所以這里就不再重復測驗, - 通過自己敲一遍代碼,對該演算法有了更加直觀的理解,且增強了堆NumPy庫中的一些函式使用的記憶,邊回憶邊思考的學習方式還是很有效果的,
4.4 分析k-近鄰演算法在手寫識別系統中的應用
4.4.1 題目說明
構造使用k-近鄰分類器的手寫識別系統,該系統可以識別數字0到9,需要識別的數字影像已經轉化成相同色彩和大小的影像:寬高都是32像素×32像素的黑白影像,為了方便測驗和理解,這里將影像轉化為txt檔案,用01繪圖方式構建數字影像進行測驗,數字影像實體如下:

可以看到該影像展示的一個大大的0.
而我們的手寫識別系統就是為了判斷這樣一張32×32陣串列示的數是多少,
這里將訓練資料和測驗資料分別存盤在trainingDigits和testDigits這兩個檔案夾中,具體檔案夾和影像檔案檔案名命名形式如下截圖所示:
其中,每個txt檔案中的影像都是32×32陣列形式,
4.4.2 源代碼決議(運用kNN演算法求解的一般步驟決議)
匯入模塊
from numpy import *
from os import listdir
import operator
1. 準備資料:將影像轉化為測驗向量→img2vector()函式
def img2vector(filename):
"""
將檔案中的影像(這里是一個數字二維矩陣)轉化為以為的陣列
:param filename: 檔案路徑和檔案名
:return:
"""
# 創建一個1行1024列的陣列,每個值都為0
returnVector = zeros((1, 1024))
fr = open(filename)
for i in range(32): # 遍歷行
lineStr = fr.readline() # 取出一整行的資料
for j in range(32): # 遍歷列
# 將一行的資料相接在returnVector陣列中
returnVector[0, 32 * i + j] = int(lineStr[j])
return returnVector
小結:
- 該函式通過將32×32的陣列影像轉化為一維測驗向量,以便存盤作為特征矩陣和特征集合,
- 通過讀取影像檔案的的每一行每一列,將每行連接起來的形式存盤到單一的測驗向量中并回傳,
2. 測驗演算法:使用k-近鄰演算法識別手寫數字→handwritingClassTest()函式
def handwritingClassTest():
"""
使用kNN演算法中的分類器來測驗識別手寫數字系統,
其中特征集陣列放在trainingDigits檔案夾下面,待測驗特征集資料放在testDigits檔案夾下面,
:return:
"""
# 依次存放各個影像所表示的數字
hwLabels = []
# listdir()函式是os模塊下的函式,功能是可以列出指定檔案夾下的檔案名,
trainingFileList = listdir('trainingDigits')
# 計算trainingDigits檔案夾下檔案數量
m = len(trainingFileList)
# 生成一個m行1024列的陣列,陣列中各個值為0,用來存放m個1024個特征值,
trainingMat = zeros((m, 1024))
# 遍歷所有訓練影像
for i in range(m):
# 依次獲取影像的txt檔案名
fileNameStr = trainingFileList[i]
# 通過split()函式將檔案名分成名字和txt兩部分
fileStr = fileNameStr.split('.')[0]
# 再將前綴分成數字和序號兩部分
classNumStr = int(fileStr.split('_')[0])
# 將影像表示的數字依次存入到hwLabels陣列中
hwLabels.append(classNumStr)
# 通過路徑和檔案名傳入到img2vector函式中,將相應txt中的影像轉化為陣列,并存入到trainingMat矩陣中的第i行
trainingMat[i, :] = img2vector('trainingDigits/%s' % fileNameStr)
# 初始化錯誤次數為0
errorCount = 0.0
# listdir函式列出了testDigits檔案夾下的檔案名
testFileList = listdir('testDigits')
# 計算testDigits檔案下的檔案數量
mTest = len(testFileList)
# 遍歷所有測驗影像
for i in range(mTest):
# 同上,先取出檔案名,切割檔案名取出檔案中影像的數字,
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
# 通過路徑和檔案名傳入img2vector函式中,將相應txt中的影像轉化為陣列,并存入到vectorUnderTest這個待測驗特征矩陣中
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
# 將待測驗特征矩陣,特征集矩陣,特征集對應的數字和k依次傳入到分類器中進行運算測驗,得到測驗結果的數字
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("%d:分類器回傳的數字為:%d,真正的數字是:%d" % (i+1, classifierResult, classNumStr))
# 如果測驗結果不等于真實的數字,則錯誤數量加1
if classifierResult != classNumStr:
errorCount += 1.0
print("\n 分類器篩選出來錯誤的情況有:%d次" % errorCount)
# 計算錯誤率
print("\n 分類器的錯誤率為:%f" % (errorCount / float(mTest)))
輸出:
1:分類器回傳的數字為:0,真正的數字是:0
2:分類器回傳的數字為:0,真正的數字是:0
3:分類器回傳的數字為:0,真正的數字是:0
4:分類器回傳的數字為:0,真正的數字是:0
5:分類器回傳的數字為:0,真正的數字是:0
6:分類器回傳的數字為:0,真正的數字是:0... ...
943:分類器回傳的數字為:9,真正的數字是:9
944:分類器回傳的數字為:9,真正的數字是:9
945:分類器回傳的數字為:9,真正的數字是:9
946:分類器回傳的數字為:9,真正的數字是:9分類器篩選出來錯誤的情況有:10次
分類器的錯誤率為:0.010571
注:這里運用的classify()分類器函式和上面簡單例子以及約會網站例子的函式一致,
小結:
- 通過測驗資料可以看到分類器判斷手寫數字的型別的錯誤率為1.06%,改變k值或則訓練樣本本、或則樣本數目等都會對錯誤率產生影響,而這里得到的1.06%的錯誤率是一個非常好的結果,說明該演算法可以用于進行手寫數字系統,
- 而實際上,但我執行這個測驗函式時,有一個很直觀的感受就是該演算法的執行效率并不高,因為演算法需要進行m次距離運算,每個距離運算包括了1024個維度浮點運算,總計要執行mTest次,此外還需給測驗資料和訓練資料準備大量的空間存盤,所以在時間和空間復雜度上該演算法并不是很完美,
- os模塊中的listdir()函式:用于列出相應檔案夾下的所有檔案名,
五、實驗小結
-
k-近鄰演算法:采用測量不同特征值之間的距離方法進行分類,
-
歐式距離公式:
\[d= √[(xA_0-xB_0)^2+(xA_1-xB_1)^2 ] \]
? 用于計算資料集中的各個點到目標點的距離,以便于篩選出k個最近的資料集點,
- 數值歸一化公式:
\[n = (x-min)/(max-min)(0<n<1.0) \]
? 歸一化數值可以使特征值同等重要,
-
測驗資料時,選用10%樣本資料作為測驗資料,90%樣本資料作為參照資料來測驗分類器的正確率,通過正確率判斷分類器效果是否可行,
-
繪制散點圖有助于我們更加清晰地觀察資料集之間的真實關系,
-
NumPy庫中的一些函式:
zeros()、ones()、min()、max()、shape()、tile()等,相關用法可以翻看上面的講解,
-
實驗遇見問題:
Matplotlib包匯入問題:
一開始編譯器顯示不存在這個包,
根據編譯器提示:install package matplotlib ,直接在pycharm上給安裝了,
六、參考資料
- 《機器學習實戰》 Peter Harrington (作者) 李銳 , 李鵬 , 曲亞東 , 王斌 (譯者) 第2章 k-近鄰演算法
- 【機器學習】k-近鄰演算法案例——約會網站的配對效果、手寫數字識別系統
- 資料來源:https://github.com/apachecn/data
著作權宣告:歡迎轉載=>請標注資訊來源于 Vanish丶博客園
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41270.html
標籤:其他
上一篇:Faiss向量相似性搜索