目錄
- 跳表
- 使用場景
- 結構描述
- 查詢演算法
- 插入演算法
- 洗掉演算法
- 時間復雜度
- 空間復雜度
- 總結
- Redis使用跳表而不是紅黑樹?
跳表
使用場景
跳表(Skiplist )是一個特殊的鏈表,相比一般的鏈表,有更高的查找效率,可比擬二叉查找樹,
平均期望的查找、插入、洗掉時間復雜度都是O(log n),許多知名的開源軟體(庫)中的資料
結構均采用了跳表這種資料結構∶
- Redis中的有序集合zset
- LevelDB、RocksDB、HBase中Memtable
- Apache Lucene中的Term Dictionary、Posting List
結構描述
我們拿我們以前的有序鏈表相比:

我們可以很清楚的看出,有序鏈表的查詢比較慢,時間復雜度為O(n),它的洗掉和插入操作比較快,我們怎樣才能讓它的查詢的時間復雜度也變快呢?
能不能將我們的鏈表實作二分的查找,也就是longN,答案是肯定的,也就是我們下面所說的這種跳表,
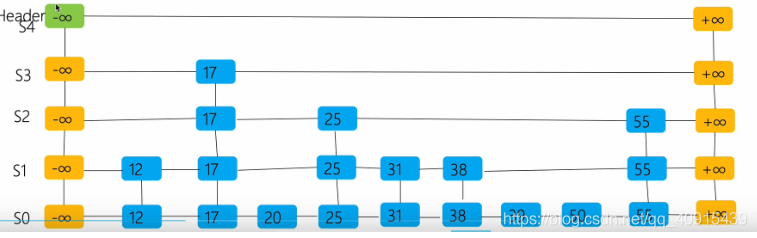
查詢演算法
跳表的查詢和我之前做過的一道題特別類似,二維陣列的查找
假設我們查詢31這個數字
- 我們的header開始,依次進行查詢,
- 31不在負無窮到17,往右邊,到達17,繼續比較,在17到正無窮之間,往下跑
- …
整個查詢程序如下所示
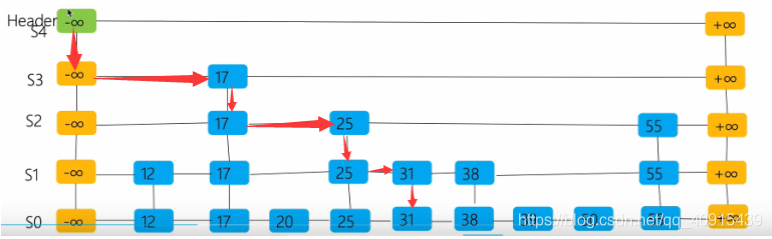
插入演算法
對于插入來說,我們比如要插入一個21的數值
- 類似查詢演算法,到達17這個點,進一步到達20這個點,然后在20的后面進行插入
- 插入完了以后,這時候要考慮索引的問題,也就是我們需要將當前這個數值向上幾層呢
- 通過一個50%的概率決定,也就是絕大多數文章講的拋硬幣(_)
洗掉演算法
對于洗掉來說,我們比如要插入一個17的數值
- 先進行查詢操作,找到這個數字
- 將其及索引進行洗掉
時間復雜度
我們知道單鏈表查詢的時間復雜度為O(n),而插入、洗掉操作需要先找到對應的位置,所以插入、洗掉的時間復雜度也是O(n),
那么,跳表的時間復雜度是多少呢?
如果按照標準的跳表來看的話,每一級索引減少k/2個元素(k為其下面一級索引的個數),那么整個跳表的高度就是(log n),
學習過平衡二叉樹的同學都知道,它的時間復雜度與樹的高度成正比,即O(log n),
所以,這里跳表的時間復雜度也是O(log n),(這里不一步步推倒了,只要記住,查詢時每次減少一半的元素的時間復雜度都是O(log n),比如二叉樹的查找、二分法查找、歸并排序、快速排序)
空間復雜度
我們還是以標準的跳表來分析,每兩個元素向上提取一個元素,那么,最后額外需要的空間就是:
n/2 + (n/2)^2 + (n/2)^3 + … + 8 + 4 + 2 = n - 2
所以,跳表的空間復雜度是O(n),
總結
-
跳表是可以實作二分查找的有序鏈表
-
每個元素插入時隨機生成它的索引的高度
-
最低層包含所有的元素
-
如果一個元素出現在level(x),那么它肯定出現在x以下的level中
-
每個索引節點包含兩個指標,一個向下,一個向右
-
跳表查詢、插入、洗掉的時間復雜度為O(log n),與平衡二叉樹接近
Redis使用跳表而不是紅黑樹?
-
插入元素
-
洗掉元素
-
查找元素
-
有序輸出所有元素
-
查找區間內所有元素
前四項紅黑樹都可以完成,且時間復雜度與跳表一致
但是,最后一項,紅黑樹就不如跳表查詢的快
在跳表中,要查找區間的元素,我們只要定位到兩個區間端點在最低層級的位置,然后按順序遍歷元素就可以了,非常高效,
而紅黑樹只能定位到端點后,再從首位置開始每次都要查找后繼節點,相對來說是比較耗時的,
跳表實作起來很容易且易讀,紅黑樹實作起來相對困難,所以Redis選擇使用跳表來實作有序集合,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/41665.html
標籤:其他